 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimally-Weighted Estimators of the Maximum Mean Discrepancy for Likelihood-Free Inference
Jan 30, 2023



Likelihood-free inference methods typically make use of a distance between simulated and real data. A common example is the maximum mean discrepancy (MMD), which has previously been used for approximate Bayesian computation, minimum distance estimation, generalised Bayesian inference, and within the nonparametric learning framework. The MMD is commonly estimated at a root-$m$ rate, where $m$ is the number of simulated samples. This can lead to significant computational challenges since a large $m$ is required to obtain an accurate estimate, which is crucial for parameter estimation. In this paper, we propose a novel estimator for the MMD with significantly improved sample complexity. The estimator is particularly well suited for computationally expensive smooth simulators with low- to mid-dimensional inputs. This claim is supported through both theoretical results and an extensive simulation study on benchmark simulators.
Differentiable User Models
Nov 29, 2022Probabilistic user modeling is essential for building collaborative AI systems within probabilistic frameworks. However, modern advanced user models, often designed as cognitive behavior simulators, are computationally prohibitive for interactive use in cooperative AI assistants. In this extended abstract, we address this problem by introducing widely-applicable differentiable surrogates for bypassing this computational bottleneck; the surrogates enable using modern behavioral models with online computational cost which is independent of their original computational cost. We show experimentally that modeling capabilities comparable to likelihood-free inference methods are achievable, with over eight orders of magnitude reduction in computational time. Finally, we demonstrate how AI-assistants can computationally feasibly use cognitive models in a previously studied menu-search task.
DPVIm: Differentially Private Variational Inference Improved
Oct 28, 2022



Differentially private (DP) release of multidimensional statistics typically considers an aggregate sensitivity, e.g. the vector norm of a high-dimensional vector. However, different dimensions of that vector might have widely different magnitudes and therefore DP perturbation disproportionately affects the signal across dimensions. We observe this problem in the gradient release of the DP-SGD algorithm when using it for variational inference (VI), where it manifests in poor convergence as well as high variance in outputs for certain variational parameters, and make the following contributions: (i) We mathematically isolate the cause for the difference in magnitudes between gradient parts corresponding to different variational parameters. Using this as prior knowledge we establish a link between the gradients of the variational parameters, and propose an efficient while simple fix for the problem to obtain a less noisy gradient estimator, which we call $\textit{aligned}$ gradients. This approach allows us to obtain the updates for the covariance parameter of a Gaussian posterior approximation without a privacy cost. We compare this to alternative approaches for scaling the gradients using analytically derived preconditioning, e.g. natural gradients. (ii) We suggest using iterate averaging over the DP parameter traces recovered during the training, to reduce the DP-induced noise in parameter estimates at no additional cost in privacy. Finally, (iii) to accurately capture the additional uncertainty DP introduces to the model parameters, we infer the DP-induced noise from the parameter traces and include that in the learned posteriors to make them $\textit{noise aware}$. We demonstrate the efficacy of our proposed improvements through various experiments on real data.
Multi-Fidelity Bayesian Optimization with Unreliable Information Sources
Oct 25, 2022Bayesian optimization (BO) is a powerful framework for optimizing black-box, expensive-to-evaluate functions. Over the past decade, many algorithms have been proposed to integrate cheaper, lower-fidelity approximations of the objective function into the optimization process, with the goal of converging towards the global optimum at a reduced cost. This task is generally referred to as multi-fidelity Bayesian optimization (MFBO). However, MFBO algorithms can lead to higher optimization costs than their vanilla BO counterparts, especially when the low-fidelity sources are poor approximations of the objective function, therefore defeating their purpose. To address this issue, we propose rMFBO (robust MFBO), a methodology to make any GP-based MFBO scheme robust to the addition of unreliable information sources. rMFBO comes with a theoretical guarantee that its performance can be bound to its vanilla BO analog, with high controllable probability. We demonstrate the effectiveness of the proposed methodology on a number of numerical benchmarks, outperforming earlier MFBO methods on unreliable sources. We expect rMFBO to be particularly useful to reliably include human experts with varying knowledge within BO processes.
Modular Flows: Differential Molecular Generation
Oct 13, 2022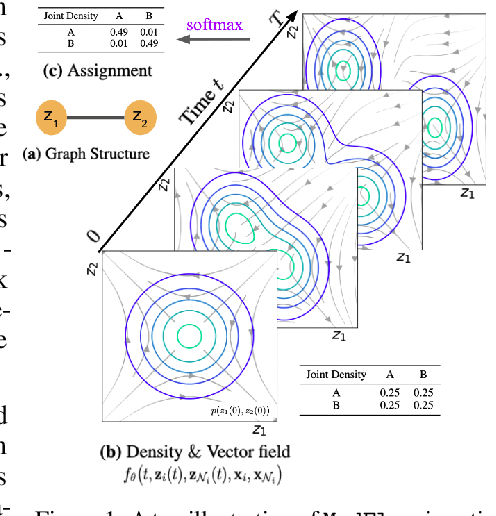

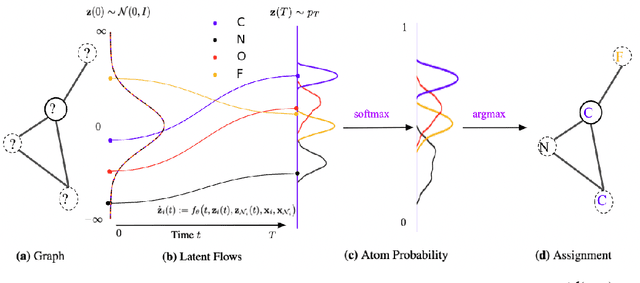

Generating new molecules is fundamental to advancing critical applications such as drug discovery and material synthesis. Flows can generate molecules effectively by inverting the encoding process, however, existing flow models either require artifactual dequantization or specific node/edge orderings, lack desiderata such as permutation invariance, or induce discrepancy between the encoding and the decoding steps that necessitates post hoc validity correction. We circumvent these issues with novel continuous normalizing E(3)-equivariant flows, based on a system of node ODEs coupled as a graph PDE, that repeatedly reconcile locally toward globally aligned densities. Our models can be cast as message-passing temporal networks, and result in superlative performance on the tasks of density estimation and molecular generation. In particular, our generated samples achieve state-of-the-art on both the standard QM9 and ZINC250K benchmarks.
Provably expressive temporal graph networks
Sep 29, 2022
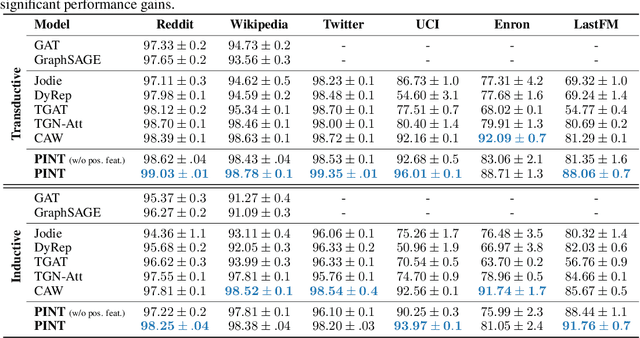


Temporal graph networks (TGNs) have gained prominence as models for embedding dynamic interactions, but little is known about their theoretical underpinnings. We establish fundamental results about the representational power and limits of the two main categories of TGNs: those that aggregate temporal walks (WA-TGNs), and those that augment local message passing with recurrent memory modules (MP-TGNs). Specifically, novel constructions reveal the inadequacy of MP-TGNs and WA-TGNs, proving that neither category subsumes the other. We extend the 1-WL (Weisfeiler-Leman) test to temporal graphs, and show that the most powerful MP-TGNs should use injective updates, as in this case they become as expressive as the temporal WL. Also, we show that sufficiently deep MP-TGNs cannot benefit from memory, and MP/WA-TGNs fail to compute graph properties such as girth. These theoretical insights lead us to PINT -- a novel architecture that leverages injective temporal message passing and relative positional features. Importantly, PINT is provably more expressive than both MP-TGNs and WA-TGNs. PINT significantly outperforms existing TGNs on several real-world benchmarks.
Bayesian Optimization Augmented with Actively Elicited Expert Knowledge
Aug 18, 2022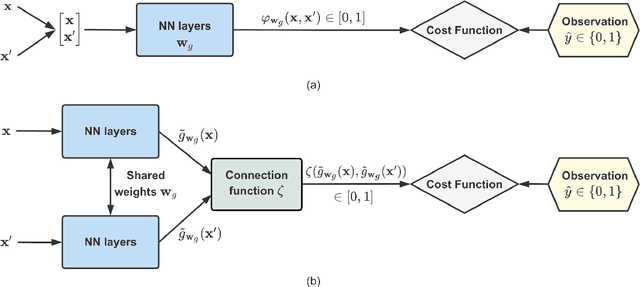
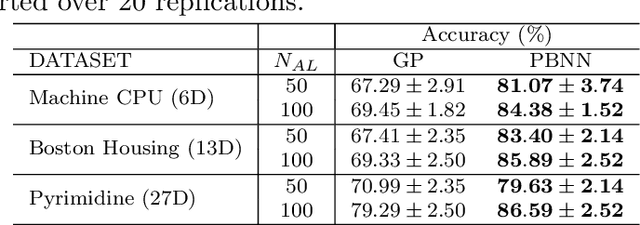
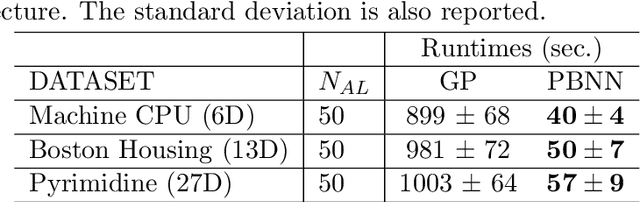
Bayesian optimization (BO) is a well-established method to optimize black-box functions whose direct evaluations are costly. In this paper, we tackle the problem of incorporating expert knowledge into BO, with the goal of further accelerating the optimization, which has received very little attention so far. We design a multi-task learning architecture for this task, with the goal of jointly eliciting the expert knowledge and minimizing the objective function. In particular, this allows for the expert knowledge to be transferred into the BO task. We introduce a specific architecture based on Siamese neural networks to handle the knowledge elicitation from pairwise queries. Experiments on various benchmark functions with both simulated and actual human experts show that the proposed method significantly speeds up BO even when the expert knowledge is biased compared to the objective function.
Human-in-the-Loop Large-Scale Predictive Maintenance of Workstations
Jun 23, 2022
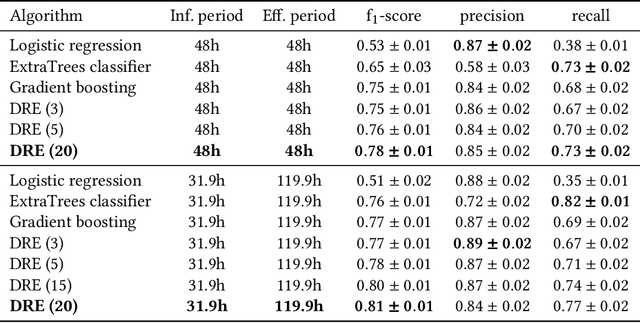
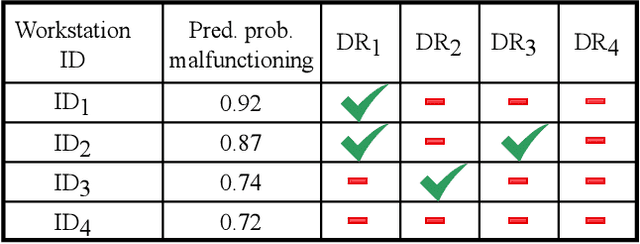

Predictive maintenance (PdM) is the task of scheduling maintenance operations based on a statistical analysis of the system's condition. We propose a human-in-the-loop PdM approach in which a machine learning system predicts future problems in sets of workstations (computers, laptops, and servers). Our system interacts with domain experts to improve predictions and elicit their knowledge. In our approach, domain experts are included in the loop not only as providers of correct labels, as in traditional active learning, but as a source of explicit decision rule feedback. The system is automated and designed to be easily extended to novel domains, such as maintaining workstations of several organizations. In addition, we develop a simulator for reproducible experiments in a controlled environment and deploy the system in a large-scale case of real-life workstations PdM with thousands of workstations for dozens of companies.
Tackling covariate shift with node-based Bayesian neural networks
Jun 06, 2022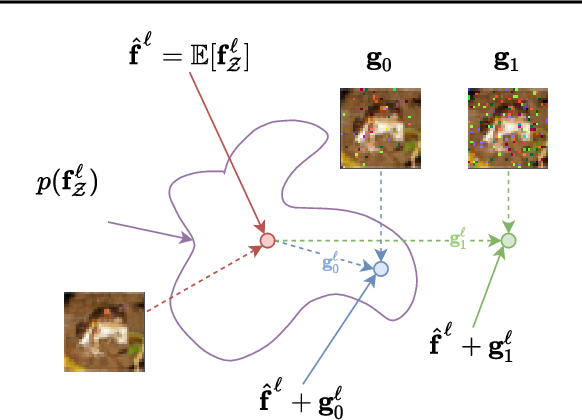

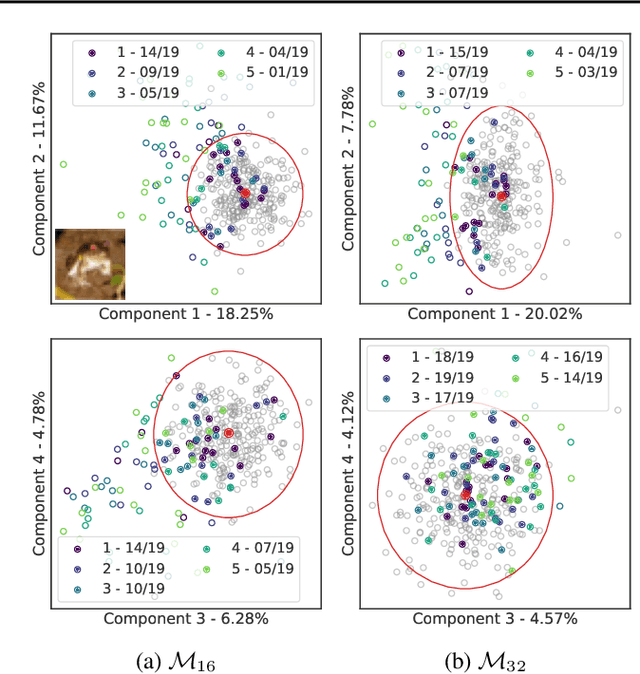
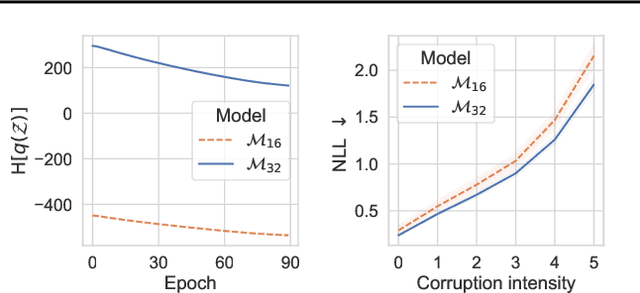
Bayesian neural networks (BNNs) promise improved generalization under covariate shift by providing principled probabilistic representations of epistemic uncertainty. However, weight-based BNNs often struggle with high computational complexity of large-scale architectures and datasets. Node-based BNNs have recently been introduced as scalable alternatives, which induce epistemic uncertainty by multiplying each hidden node with latent random variables, while learning a point-estimate of the weights. In this paper, we interpret these latent noise variables as implicit representations of simple and domain-agnostic data perturbations during training, producing BNNs that perform well under covariate shift due to input corruptions. We observe that the diversity of the implicit corruptions depends on the entropy of the latent variables, and propose a straightforward approach to increase the entropy of these variables during training. We evaluate the method on out-of-distribution image classification benchmarks, and show improved uncertainty estimation of node-based BNNs under covariate shift due to input perturbations. As a side effect, the method also provides robustness against noisy training labels.
Noise-Aware Statistical Inference with Differentially Private Synthetic Data
May 28, 2022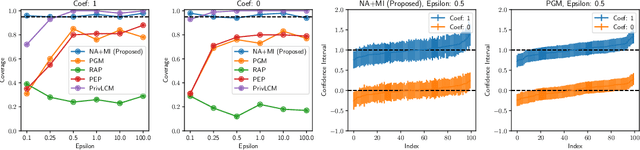
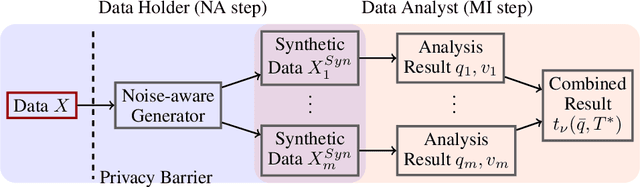
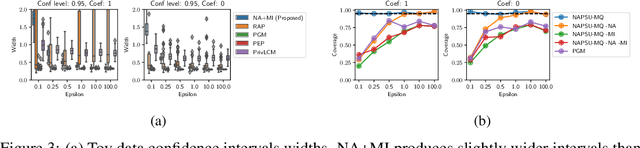
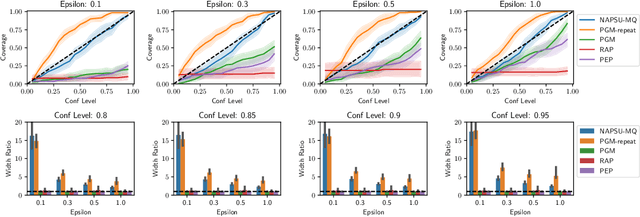
While generation of synthetic data under differential privacy (DP) has received a lot of attention in the data privacy community, analysis of synthetic data has received much less. Existing work has shown that simply analysing DP synthetic data as if it were real does not produce valid inferences of population-level quantities. For example, confidence intervals become too narrow, which we demonstrate with a simple experiment. We tackle this problem by combining synthetic data analysis techniques from the field of multiple imputation, and synthetic data generation using noise-aware Bayesian modeling into a pipeline NA+MI that allows computing accurate uncertainty estimates for population-level quantities from DP synthetic data. To implement NA+MI for discrete data generation from marginal queries, we develop a novel noise-aware synthetic data generation algorithm NAPSU-MQ using the principle of maximum entropy. Our experiments demonstrate that the pipeline is able to produce accurate confidence intervals from DP synthetic data. The intervals become wider with tighter privacy to accurately capture the additional uncertainty stemming from DP noise.