 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHitting Time Isomorphism for Multi-Stage Planning with Foundation Policies
May 07, 2026We present a new operator-theoretic representation learning framework for offline reinforcement learning that recovers the directed temporal geometry of a controlled Markov process from hitting time observations. While prior art often produces symmetric distances or fails to satisfy the triangle inequality, our framework learns a Hilbert-space displacement geometry where expected hitting times are realized as linear functionals of latent displacements. We prove that this representation exists under latent linear closure and is uniquely identifiable up to a bounded linear isomorphism. For finite-dimensional implementations, we show that global hitting-time error is bounded by one-step transition error amplified by the environment's transient spectral radius. Furthermore, we provide finite-sample guarantees accounting for approximation, statistical complexity, and trajectory-label mismatch. Derived from this theory, we curate Isomorphic Embedding Learning (IEL) as a new goal-agnostic foundation policy learning algorithm that anchors a HILP-style consistency objective with explicit hitting-time regression to ensure that the learned geometry reflects actual decision-time progress. This asymmetric and compositional structure enables robust graph-based multi-stage planning for long-horizon navigation. Our experiments demonstrate that IEL improves the state of the art of learning foundation policy policies from offline maze locomotion data. Our code can be found on https://github.com/MagnusBoock/IEL
A Measure-Theoretic Finite-Sample Theory for Adaptive-Data Fitted Q-Iteration
May 07, 2026While reinforcement learning (RL) promises to revolutionize the control of complex nonlinear robotic systems, a profound gap persists between the heuristic success of model-free off-policy deep RL and the underlying theory, which remains largely confined to tabular or linearizable settings. We identify the cause of this gap as an emergent isolation of three traditions: (i) measure-theoretic MDP foundations on general spaces limit their analysis to exact dynamic programming and ignore all error sources of a learning process; (ii) deterministic error propagation analysis addresses the approximation error via concentrability coefficients without a finite-sample analysis of the estimation error; and (iii) PAC generalization bounds characterize the estimation errors of simplified topologies. We bridge these traditions with a unified theoretical framework for fitted Q-iteration (FQI) on general measurable Borel spaces. Our main result provides a finite-sample, adaptive-data performance bound by chaining measure-theoretic probability with Bellman-operator contraction in Banach spaces. We prove that sequential Rademacher complexity controls Bellman-regression generalization under policy-dependent data collection. We further extend this analysis to provide the first cumulative, pathwise online regret guarantee for FQI in continuous spaces. These results lay the necessary foundations for the formal analysis of many modern deep RL algorithms.
Distributional Active Inference
Jan 28, 2026Optimal control of complex environments with robotic systems faces two complementary and intertwined challenges: efficient organization of sensory state information and far-sighted action planning. Because the reinforcement learning framework addresses only the latter, it tends to deliver sample-inefficient solutions. Active inference is the state-of-the-art process theory that explains how biological brains handle this dual problem. However, its applications to artificial intelligence have thus far been limited to extensions of existing model-based approaches. We present a formal abstraction of reinforcement learning algorithms that spans model-based, distributional, and model-free approaches. This abstraction seamlessly integrates active inference into the distributional reinforcement learning framework, making its performance advantages accessible without transition dynamics modeling.
SHARPIE: A Modular Framework for Reinforcement Learning and Human-AI Interaction Experiments
Jan 31, 2025


Reinforcement learning (RL) offers a general approach for modeling and training AI agents, including human-AI interaction scenarios. In this paper, we propose SHARPIE (Shared Human-AI Reinforcement Learning Platform for Interactive Experiments) to address the need for a generic framework to support experiments with RL agents and humans. Its modular design consists of a versatile wrapper for RL environments and algorithm libraries, a participant-facing web interface, logging utilities, deployment on popular cloud and participant recruitment platforms. It empowers researchers to study a wide variety of research questions related to the interaction between humans and RL agents, including those related to interactive reward specification and learning, learning from human feedback, action delegation, preference elicitation, user-modeling, and human-AI teaming. The platform is based on a generic interface for human-RL interactions that aims to standardize the field of study on RL in human contexts.
On the Complexity of Learning to Cooperate with Populations of Socially Rational Agents
Jun 29, 2024
Artificially intelligent agents deployed in the real-world will require the ability to reliably \textit{cooperate} with humans (as well as other, heterogeneous AI agents). To provide formal guarantees of successful cooperation, we must make some assumptions about how partner agents could plausibly behave. Any realistic set of assumptions must account for the fact that other agents may be just as adaptable as our agent is. In this work, we consider the problem of cooperating with a \textit{population} of agents in a finitely-repeated, two player general-sum matrix game with private utilities. Two natural assumptions in such settings are that: 1) all agents in the population are individually rational learners, and 2) when any two members of the population are paired together, with high-probability they will achieve at least the same utility as they would under some Pareto efficient equilibrium strategy. Our results first show that these assumptions alone are insufficient to ensure \textit{zero-shot} cooperation with members of the target population. We therefore consider the problem of \textit{learning} a strategy for cooperating with such a population using prior observations its members interacting with one another. We provide upper and lower bounds on the number of samples needed to learn an effective cooperation strategy. Most importantly, we show that these bounds can be much stronger than those arising from a "naive'' reduction of the problem to one of imitation learning.
Inverse Concave-Utility Reinforcement Learning is Inverse Game Theory
May 29, 2024

We consider inverse reinforcement learning problems with concave utilities. Concave Utility Reinforcement Learning (CURL) is a generalisation of the standard RL objective, which employs a concave function of the state occupancy measure, rather than a linear function. CURL has garnered recent attention for its ability to represent instances of many important applications including the standard RL such as imitation learning, pure exploration, constrained MDPs, offline RL, human-regularized RL, and others. Inverse reinforcement learning is a powerful paradigm that focuses on recovering an unknown reward function that can rationalize the observed behaviour of an agent. There has been recent theoretical advances in inverse RL where the problem is formulated as identifying the set of feasible reward functions. However, inverse RL for CURL problems has not been considered previously. In this paper we show that most of the standard IRL results do not apply to CURL in general, since CURL invalidates the classical Bellman equations. This calls for a new theoretical framework for the inverse CURL problem. Using a recent equivalence result between CURL and Mean-field Games, we propose a new definition for the feasible rewards for I-CURL by proving that this problem is equivalent to an inverse game theory problem in a subclass of mean-field games. We present initial query and sample complexity results for the I-CURL problem under assumptions such as Lipschitz-continuity. Finally, we outline future directions and applications in human--AI collaboration enabled by our results.
Towards a Unifying Model of Rationality in Multiagent Systems
May 29, 2023Multiagent systems deployed in the real world need to cooperate with other agents (including humans) nearly as effectively as these agents cooperate with one another. To design such AI, and provide guarantees of its effectiveness, we need to clearly specify what types of agents our AI must be able to cooperate with. In this work we propose a generic model of socially intelligent agents, which are individually rational learners that are also able to cooperate with one another (in the sense that their joint behavior is Pareto efficient). We define rationality in terms of the regret incurred by each agent over its lifetime, and show how we can construct socially intelligent agents for different forms of regret. We then discuss the implications of this model for the development of "robust" MAS that can cooperate with a wide variety of socially intelligent agents.
Uncoupled Learning of Differential Stackelberg Equilibria with Commitments
Feb 07, 2023A natural solution concept for many multiagent settings is the Stackelberg equilibrium, under which a ``leader'' agent selects a strategy that maximizes its own payoff assuming the ``follower'' chooses their best response to this strategy. Recent work has presented asymmetric learning updates that can be shown to converge to the \textit{differential} Stackelberg equilibria of two-player differentiable games. These updates are ``coupled'' in the sense that the leader requires some information about the follower's payoff function. Such coupled learning rules cannot be applied to \textit{ad hoc} interactive learning settings, and can be computationally impractical even in centralized training settings where the follower's payoffs are known. In this work, we present an ``uncoupled'' learning process under which each player's learning update only depends on their observations of the other's behavior. We prove that this process converges to a local Stackelberg equilibrium under similar conditions as previous coupled methods. We conclude with a discussion of the potential applications of our approach to human--AI cooperation and multi-agent reinforcement learning.
Differentiable User Models
Nov 29, 2022Probabilistic user modeling is essential for building collaborative AI systems within probabilistic frameworks. However, modern advanced user models, often designed as cognitive behavior simulators, are computationally prohibitive for interactive use in cooperative AI assistants. In this extended abstract, we address this problem by introducing widely-applicable differentiable surrogates for bypassing this computational bottleneck; the surrogates enable using modern behavioral models with online computational cost which is independent of their original computational cost. We show experimentally that modeling capabilities comparable to likelihood-free inference methods are achievable, with over eight orders of magnitude reduction in computational time. Finally, we demonstrate how AI-assistants can computationally feasibly use cognitive models in a previously studied menu-search task.
Distributed Influence-Augmented Local Simulators for Parallel MARL in Large Networked Systems
Jul 01, 2022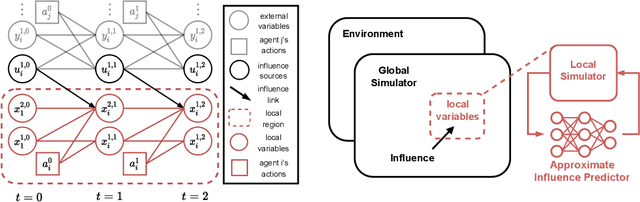
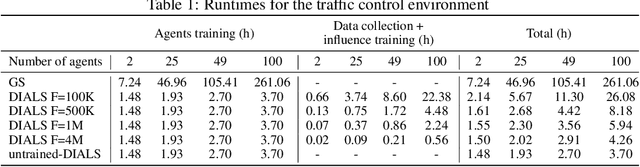
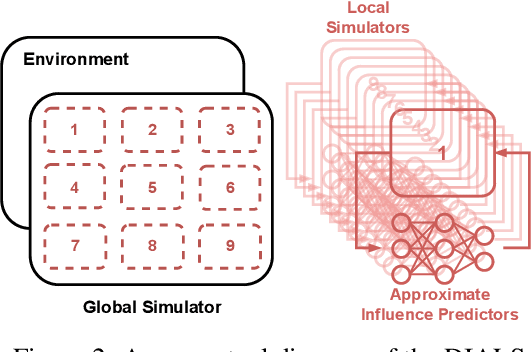
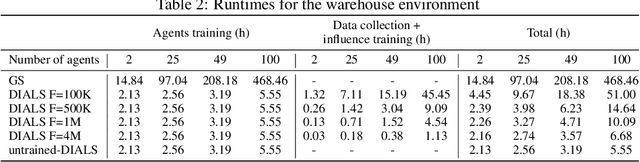
Due to its high sample complexity, simulation is, as of today, critical for the successful application of reinforcement learning. Many real-world problems, however, exhibit overly complex dynamics, which makes their full-scale simulation computationally slow. In this paper, we show how to decompose large networked systems of many agents into multiple local components such that we can build separate simulators that run independently and in parallel. To monitor the influence that the different local components exert on one another, each of these simulators is equipped with a learned model that is periodically trained on real trajectories. Our empirical results reveal that distributing the simulation among different processes not only makes it possible to train large multi-agent systems in just a few hours but also helps mitigate the negative effects of simultaneous learning.