 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROMPT WAYWARDNESS: The Curious Case of Discretized Interpretation of Continuous Prompts
Dec 15, 2021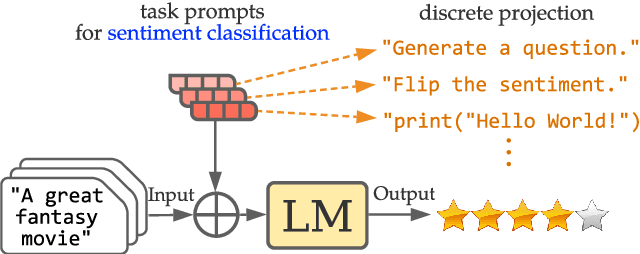
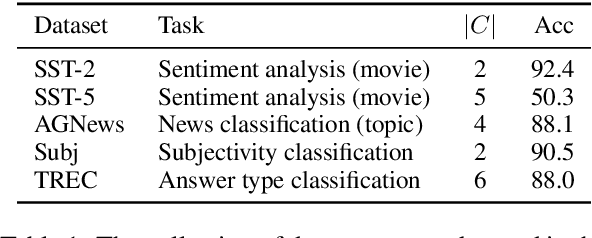
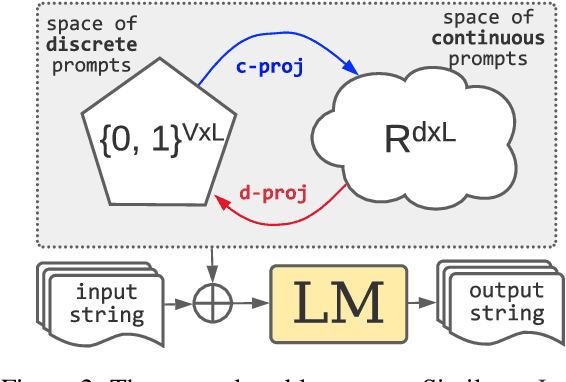
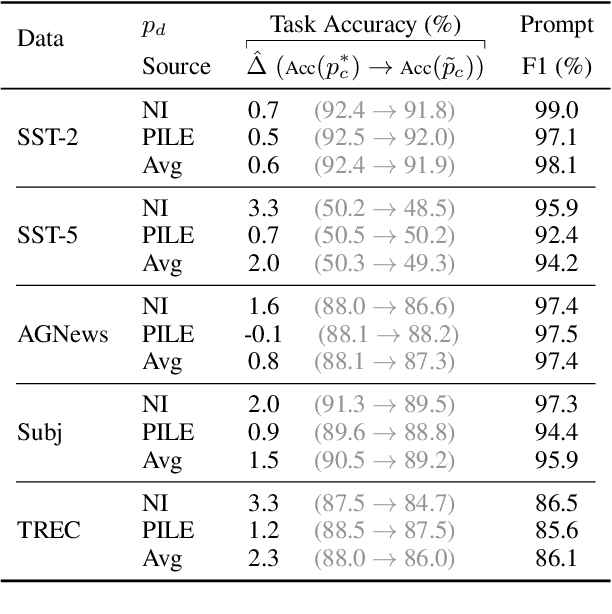
Fine-tuning continuous prompts for target tasks has recently emerged as a compact alternative to full model fine-tuning. Motivated by these promising results, we investigate the feasibility of extracting a discrete (textual) interpretation of continuous prompts that is faithful to the problem they solve. In practice, we observe a "wayward" behavior between the task solved by continuous prompts and their nearest neighbor discrete projections: We can find continuous prompts that solve a task while being projected to an arbitrary text (e.g., definition of a different or even a contradictory task), while being within a very small (2%) margin of the best continuous prompt of the same size for the task. We provide intuitions behind this odd and surprising behavior, as well as extensive empirical analyses quantifying the effect of various parameters. For instance, for larger model sizes we observe higher waywardness, i.e, we can find prompts that more closely map to any arbitrary text with a smaller drop in accuracy. These findings have important implications relating to the difficulty of faithfully interpreting continuous prompts and their generalization across models and tasks, providing guidance for future progress in prompting language models.
Entity-Based Knowledge Conflicts in Question Answering
Sep 10, 2021

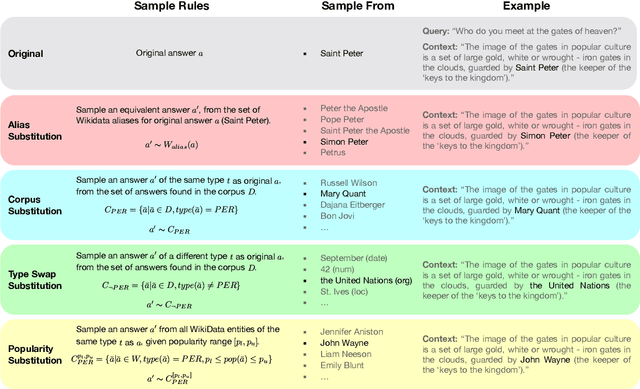
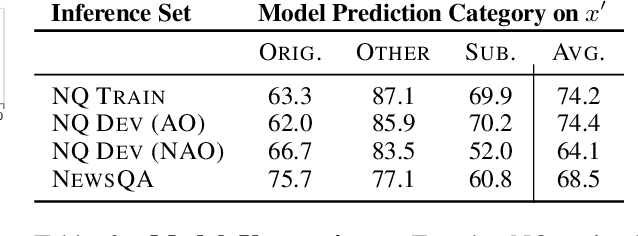
Knowledge-dependent tasks typically use two sources of knowledge: parametric, learned at training time, and contextual, given as a passage at inference time. To understand how models use these sources together, we formalize the problem of knowledge conflicts, where the contextual information contradicts the learned information. Analyzing the behaviour of popular models, we measure their over-reliance on memorized information (the cause of hallucinations), and uncover important factors that exacerbate this behaviour. Lastly, we propose a simple method to mitigate over-reliance on parametric knowledge, which minimizes hallucination, and improves out-of-distribution generalization by 4%-7%. Our findings demonstrate the importance for practitioners to evaluate model tendency to hallucinate rather than read, and show that our mitigation strategy encourages generalization to evolving information (i.e., time-dependent queries). To encourage these practices, we have released our framework for generating knowledge conflicts.
Modular Framework for Visuomotor Language Grounding
Sep 05, 2021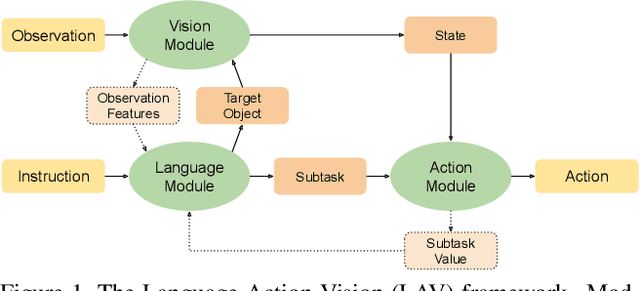
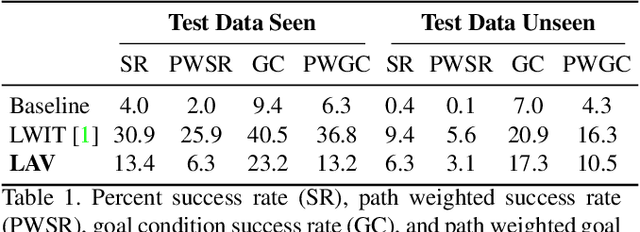
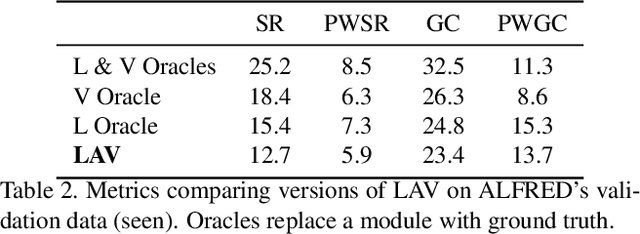
Natural language instruction following tasks serve as a valuable test-bed for grounded language and robotics research. However, data collection for these tasks is expensive and end-to-end approaches suffer from data inefficiency. We propose the structuring of language, acting, and visual tasks into separate modules that can be trained independently. Using a Language, Action, and Vision (LAV) framework removes the dependence of action and vision modules on instruction following datasets, making them more efficient to train. We also present a preliminary evaluation of LAV on the ALFRED task for visual and interactive instruction following.
Enforcing Consistency in Weakly Supervised Semantic Parsing
Jul 13, 2021
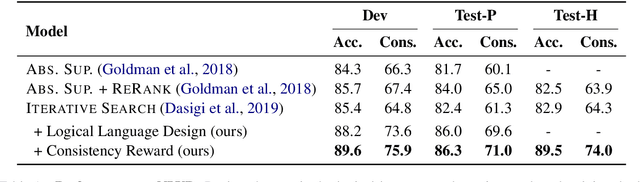

The predominant challenge in weakly supervised semantic parsing is that of spurious programs that evaluate to correct answers for the wrong reasons. Prior work uses elaborate search strategies to mitigate the prevalence of spurious programs; however, they typically consider only one input at a time. In this work we explore the use of consistency between the output programs for related inputs to reduce the impact of spurious programs. We bias the program search (and thus the model's training signal) towards programs that map the same phrase in related inputs to the same sub-parts in their respective programs. Additionally, we study the importance of designing logical formalisms that facilitate this kind of consAistency-based training. We find that a more consistent formalism leads to improved model performance even without consistency-based training. When combined together, these two insights lead to a 10% absolute improvement over the best prior result on the Natural Language Visual Reasoning dataset.
Combining Feature and Instance Attribution to Detect Artifacts
Jul 01, 2021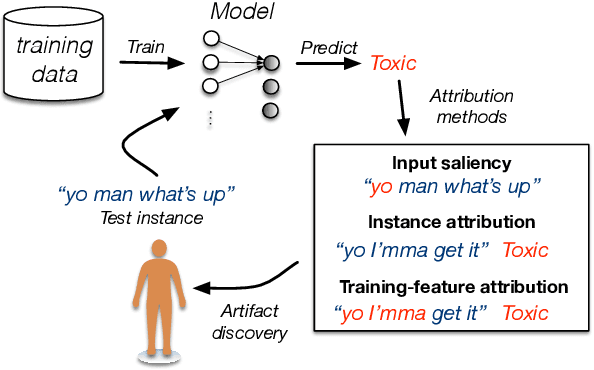

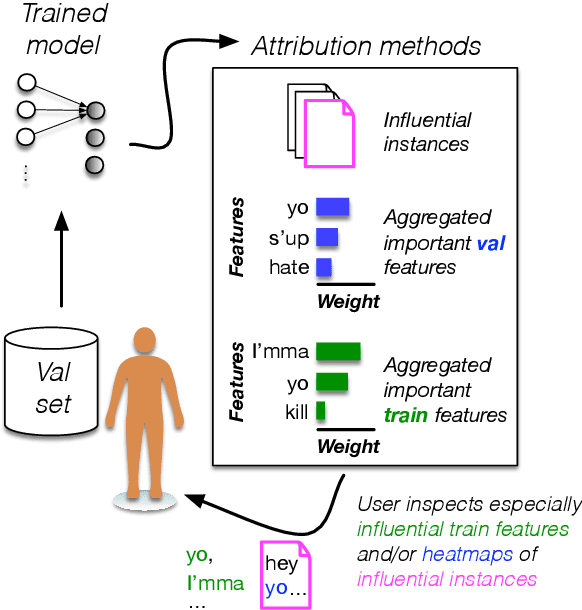
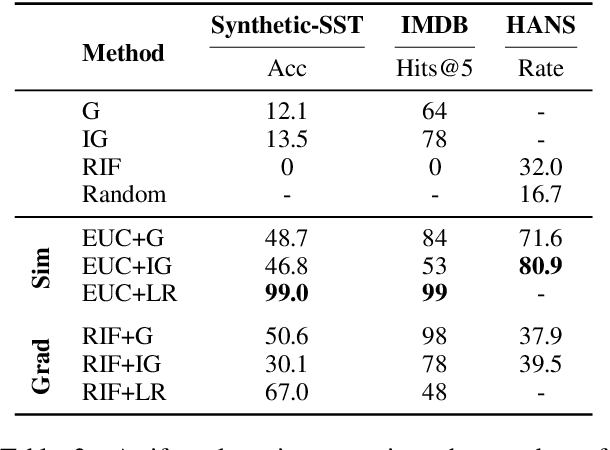
Training the large deep neural networks that dominate NLP requires large datasets. Many of these are collected automatically or via crowdsourcing, and may exhibit systematic biases or annotation artifacts. By the latter, we mean correlations between inputs and outputs that are spurious, insofar as they do not represent a generally held causal relationship between features and classes; models that exploit such correlations may appear to perform a given task well, but fail on out of sample data. In this paper we propose methods to facilitate identification of training data artifacts, using new hybrid approaches that combine saliency maps (which highlight important input features) with instance attribution methods (which retrieve training samples influential to a given prediction). We show that this proposed training-feature attribution approach can be used to uncover artifacts in training data, and use it to identify previously unreported artifacts in a few standard NLP datasets. We execute a small user study to evaluate whether these methods are useful to NLP researchers in practice, with promising results. We make code for all methods and experiments in this paper available.
Cutting Down on Prompts and Parameters: Simple Few-Shot Learning with Language Models
Jul 01, 2021
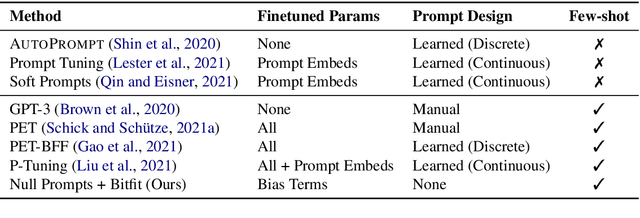
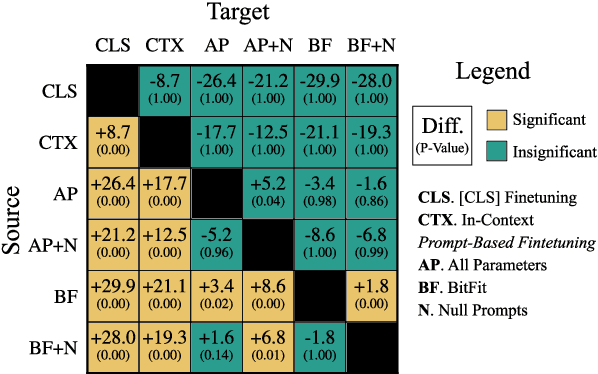
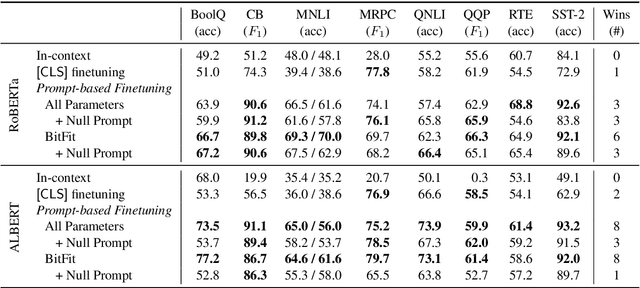
Prompting language models (LMs) with training examples and task descriptions has been seen as critical to recent successes in few-shot learning. In this work, we show that finetuning LMs in the few-shot setting can considerably reduce the need for prompt engineering. In fact, one can use null prompts, prompts that contain neither task-specific templates nor training examples, and achieve competitive accuracy to manually-tuned prompts across a wide range of tasks. While finetuning LMs does introduce new parameters for each downstream task, we show that this memory overhead can be substantially reduced: finetuning only the bias terms can achieve comparable or better accuracy than standard finetuning while only updating 0.1% of the parameters. All in all, we recommend finetuning LMs for few-shot learning as it is more accurate, robust to different prompts, and can be made nearly as efficient as using frozen LMs.
Feature Attributions and Counterfactual Explanations Can Be Manipulated
Jun 25, 2021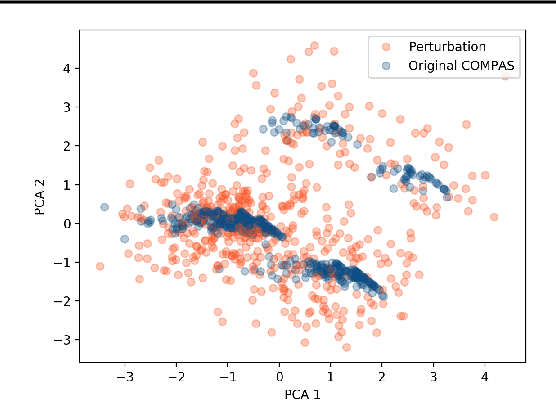
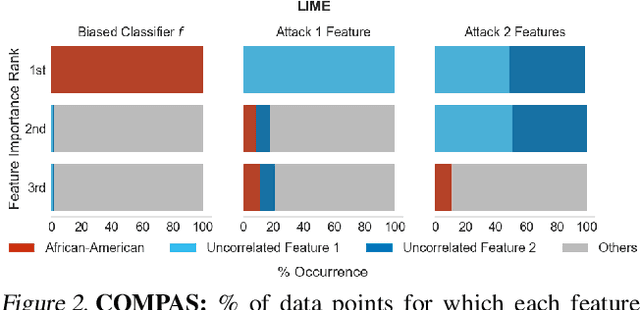
As machine learning models are increasingly used in critical decision-making settings (e.g., healthcare, finance), there has been a growing emphasis on developing methods to explain model predictions. Such \textit{explanations} are used to understand and establish trust in models and are vital components in machine learning pipelines. Though explanations are a critical piece in these systems, there is little understanding about how they are vulnerable to manipulation by adversaries. In this paper, we discuss how two broad classes of explanations are vulnerable to manipulation. We demonstrate how adversaries can design biased models that manipulate model agnostic feature attribution methods (e.g., LIME \& SHAP) and counterfactual explanations that hill-climb during the counterfactual search (e.g., Wachter's Algorithm \& DiCE) into \textit{concealing} the model's biases. These vulnerabilities allow an adversary to deploy a biased model, yet explanations will not reveal this bias, thereby deceiving stakeholders into trusting the model. We evaluate the manipulations on real world data sets, including COMPAS and Communities \& Crime, and find explanations can be manipulated in practice.
Evaluating Entity Disambiguation and the Role of Popularity in Retrieval-Based NLP
Jun 12, 2021
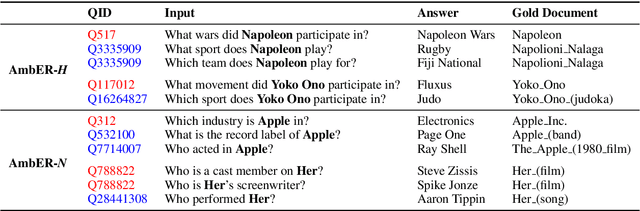
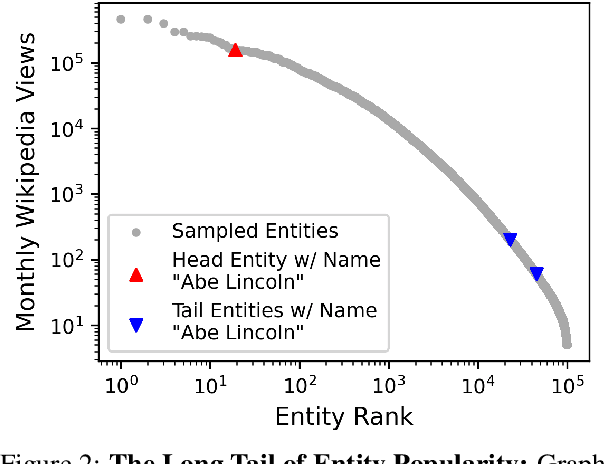

Retrieval is a core component for open-domain NLP tasks. In open-domain tasks, multiple entities can share a name, making disambiguation an inherent yet under-explored problem. We propose an evaluation benchmark for assessing the entity disambiguation capabilities of these retrievers, which we call Ambiguous Entity Retrieval (AmbER) sets. We define an AmbER set as a collection of entities that share a name along with queries about those entities. By covering the set of entities for polysemous names, AmbER sets act as a challenging test of entity disambiguation. We create AmbER sets for three popular open-domain tasks: fact checking, slot filling, and question answering, and evaluate a diverse set of retrievers. We find that the retrievers exhibit popularity bias, significantly under-performing on rarer entities that share a name, e.g., they are twice as likely to retrieve erroneous documents on queries for the less popular entity under the same name. These experiments on AmbER sets show their utility as an evaluation tool and highlight the weaknesses of popular retrieval systems.
Counterfactual Explanations Can Be Manipulated
Jun 04, 2021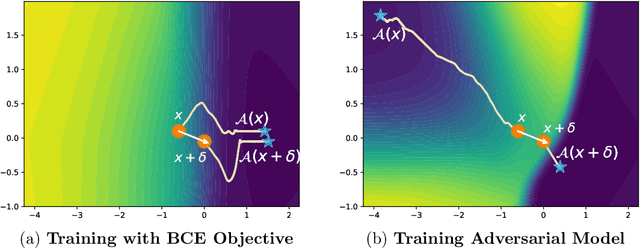
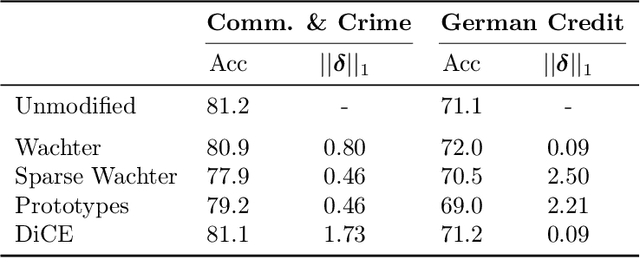
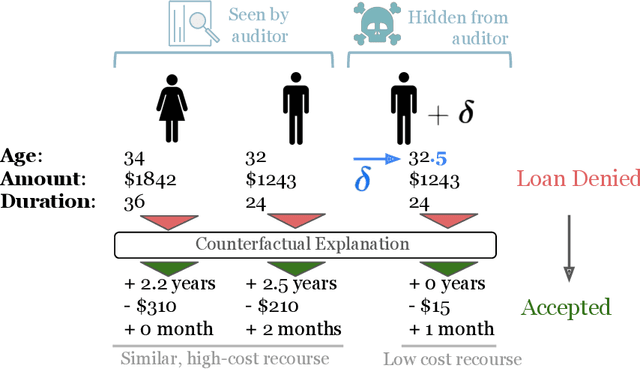
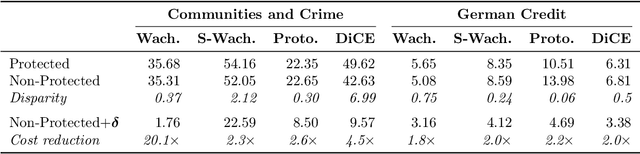
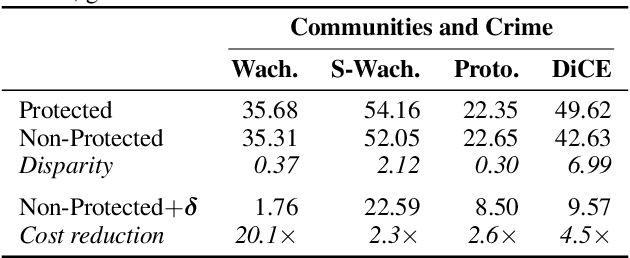
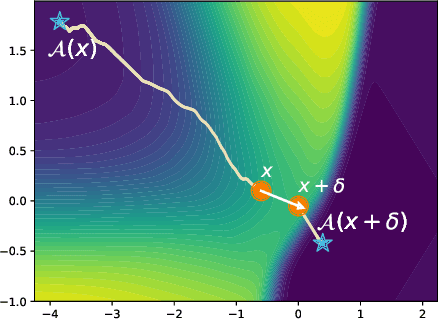
Counterfactual explanations are emerging as an attractive option for providing recourse to individuals adversely impacted by algorithmic decisions. As they are deployed in critical applications (e.g. law enforcement, financial lending), it becomes important to ensure that we clearly understand the vulnerabilities of these methods and find ways to address them. However, there is little understanding of the vulnerabilities and shortcomings of counterfactual explanations. In this work, we introduce the first framework that describes the vulnerabilities of counterfactual explanations and shows how they can be manipulated. More specifically, we show counterfactual explanations may converge to drastically different counterfactuals under a small perturbation indicating they are not robust. Leveraging this insight, we introduce a novel objective to train seemingly fair models where counterfactual explanations find much lower cost recourse under a slight perturbation. We describe how these models can unfairly provide low-cost recourse for specific subgroups in the data while appearing fair to auditors. We perform experiments on loan and violent crime prediction data sets where certain subgroups achieve up to 20x lower cost recourse under the perturbation. These results raise concerns regarding the dependability of current counterfactual explanation techniques, which we hope will inspire investigations in robust counterfactual explanations.
Generative Context Pair Selection for Multi-hop Question Answering
Apr 18, 2021

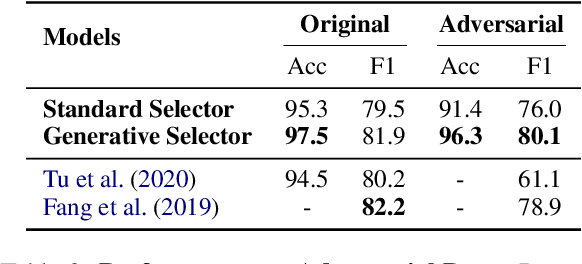

Compositional reasoning tasks like multi-hop question answering, require making latent decisions to get the final answer, given a question. However, crowdsourced datasets often capture only a slice of the underlying task distribution, which can induce unanticipated biases in models performing compositional reasoning. Furthermore, discriminatively trained models exploit such biases to get a better held-out performance, without learning the right way to reason, as they do not necessitate paying attention to the question representation (conditioning variable) in its entirety, to estimate the answer likelihood. In this work, we propose a generative context selection model for multi-hop question answering that reasons about how the given question could have been generated given a context pair. While being comparable to the state-of-the-art answering performance, our proposed generative passage selection model has a better performance (4.9% higher than baseline) on adversarial held-out set which tests robustness of model's multi-hop reasoning capabilities.