 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Dataset Distillation: Hard Truths about Soft Labels
Apr 20, 2026Despite the perceived success of large-scale dataset distillation (DD) methods, recent evidence finds that simple random image baselines perform on-par with state-of-theart DD methods like SRe2L due to the use of soft labels during downstream model training. This is in contrast with the findings in coreset literature, where high-quality coresets consistently outperform random subsets in the hardlabel (HL) setting. To understand this discrepancy, we perform a detailed scalability analysis to examine the role of data quality under different label regimes, ranging from abundant soft labels (termed as SL+KD regime) to fixed soft labels (SL) and hard labels (HL). Our analysis reveals that high-quality coresets fail to convincingly outperform the random baseline in both SL and SL+KD regimes. In the SL+KD setting, performance further approaches nearoptimal levels relative to the full dataset, regardless of subset size or quality, for a given compute budget. This performance saturation calls into question the widespread practice of using soft labels for model evaluation, where unlike the HL setting, subset quality has negligible influence. A subsequent systematic evaluation of five large-scale and four small-scale DD methods in the HL setting reveals that only RDED reliably outperforms random baselines on ImageNet-1K, but can still lag behind strong coreset methods due to its over-reliance on easy sample patches. Based on this, we introduce CAD-Prune, a compute-aware pruning metric that efficiently identifies samples of optimal difficulty for a given compute budget, and use it to develop CA2D, a compute-aligned DD method, outperforming current DD methods on ImageNet-1K at various IPC settings. Together, our findings uncover many insights into current DD research and establish useful tools to advance dataefficient learning for both coresets and DD.
Exploring Compositionality in Vision Transformers using Wavelet Representations
Dec 30, 2025While insights into the workings of the transformer model have largely emerged by analysing their behaviour on language tasks, this work investigates the representations learnt by the Vision Transformer (ViT) encoder through the lens of compositionality. We introduce a framework, analogous to prior work on measuring compositionality in representation learning, to test for compositionality in the ViT encoder. Crucial to drawing this analogy is the Discrete Wavelet Transform (DWT), which is a simple yet effective tool for obtaining input-dependent primitives in the vision setting. By examining the ability of composed representations to reproduce original image representations, we empirically test the extent to which compositionality is respected in the representation space. Our findings show that primitives from a one-level DWT decomposition produce encoder representations that approximately compose in latent space, offering a new perspective on how ViTs structure information.
DiRe: Diversity-promoting Regularization for Dataset Condensation
Dec 15, 2025In Dataset Condensation, the goal is to synthesize a small dataset that replicates the training utility of a large original dataset. Existing condensation methods synthesize datasets with significant redundancy, so there is a dire need to reduce redundancy and improve the diversity of the synthesized datasets. To tackle this, we propose an intuitive Diversity Regularizer (DiRe) composed of cosine similarity and Euclidean distance, which can be applied off-the-shelf to various state-of-the-art condensation methods. Through extensive experiments, we demonstrate that the addition of our regularizer improves state-of-the-art condensation methods on various benchmark datasets from CIFAR-10 to ImageNet-1K with respect to generalization and diversity metrics.
DermaCon-IN: A Multi-concept Annotated Dermatological Image Dataset of Indian Skin Disorders for Clinical AI Research
Jun 06, 2025Artificial intelligence is poised to augment dermatological care by enabling scalable image-based diagnostics. Yet, the development of robust and equitable models remains hindered by datasets that fail to capture the clinical and demographic complexity of real-world practice. This complexity stems from region-specific disease distributions, wide variation in skin tones, and the underrepresentation of outpatient scenarios from non-Western populations. We introduce DermaCon-IN, a prospectively curated dermatology dataset comprising over 5,450 clinical images from approximately 3,000 patients across outpatient clinics in South India. Each image is annotated by board-certified dermatologists with over 240 distinct diagnoses, structured under a hierarchical, etiology-based taxonomy adapted from Rook's classification. The dataset captures a wide spectrum of dermatologic conditions and tonal variation commonly seen in Indian outpatient care. We benchmark a range of architectures including convolutional models (ResNet, DenseNet, EfficientNet), transformer-based models (ViT, MaxViT, Swin), and Concept Bottleneck Models to establish baseline performance and explore how anatomical and concept-level cues may be integrated. These results are intended to guide future efforts toward interpretable and clinically realistic models. DermaCon-IN provides a scalable and representative foundation for advancing dermatology AI in real-world settings.
Lost in Context: The Influence of Context on Feature Attribution Methods for Object Recognition
Nov 05, 2024



Contextual information plays a critical role in object recognition models within computer vision, where changes in context can significantly affect accuracy, underscoring models' dependence on contextual cues. This study investigates how context manipulation influences both model accuracy and feature attribution, providing insights into the reliance of object recognition models on contextual information as understood through the lens of feature attribution methods. We employ a range of feature attribution techniques to decipher the reliance of deep neural networks on context in object recognition tasks. Using the ImageNet-9 and our curated ImageNet-CS datasets, we conduct experiments to evaluate the impact of contextual variations, analyzed through feature attribution methods. Our findings reveal several key insights: (a) Correctly classified images predominantly emphasize object volume attribution over context volume attribution. (b) The dependence on context remains relatively stable across different context modifications, irrespective of classification accuracy. (c) Context change exerts a more pronounced effect on model performance than Context perturbations. (d) Surprisingly, context attribution in `no-information' scenarios is non-trivial. Our research moves beyond traditional methods by assessing the implications of broad-level modifications on object recognition, either in the object or its context.
Learning to Retain while Acquiring: Combating Distribution-Shift in Adversarial Data-Free Knowledge Distillation
Feb 28, 2023Data-free Knowledge Distillation (DFKD) has gained popularity recently, with the fundamental idea of carrying out knowledge transfer from a Teacher neural network to a Student neural network in the absence of training data. However, in the Adversarial DFKD framework, the student network's accuracy, suffers due to the non-stationary distribution of the pseudo-samples under multiple generator updates. To this end, at every generator update, we aim to maintain the student's performance on previously encountered examples while acquiring knowledge from samples of the current distribution. Thus, we propose a meta-learning inspired framework by treating the task of Knowledge-Acquisition (learning from newly generated samples) and Knowledge-Retention (retaining knowledge on previously met samples) as meta-train and meta-test, respectively. Hence, we dub our method as Learning to Retain while Acquiring. Moreover, we identify an implicit aligning factor between the Knowledge-Retention and Knowledge-Acquisition tasks indicating that the proposed student update strategy enforces a common gradient direction for both tasks, alleviating interference between the two objectives. Finally, we support our hypothesis by exhibiting extensive evaluation and comparison of our method with prior arts on multiple datasets.
Class Balancing GAN with a Classifier in the Loop
Jun 17, 2021
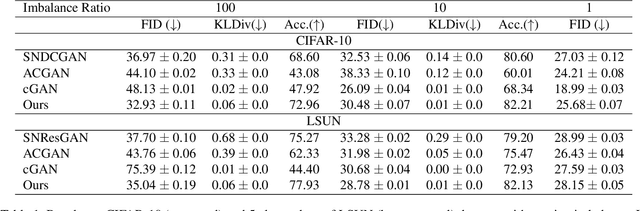
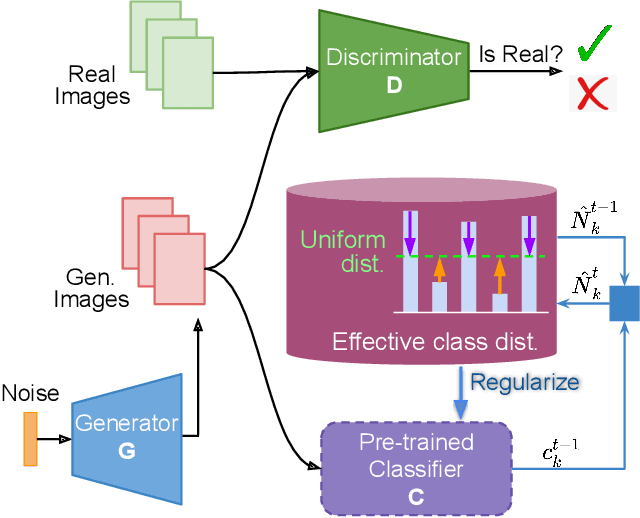

Generative Adversarial Networks (GANs) have swiftly evolved to imitate increasingly complex image distributions. However, majority of the developments focus on performance of GANs on balanced datasets. We find that the existing GANs and their training regimes which work well on balanced datasets fail to be effective in case of imbalanced (i.e. long-tailed) datasets. In this work we introduce a novel theoretically motivated Class Balancing regularizer for training GANs. Our regularizer makes use of the knowledge from a pre-trained classifier to ensure balanced learning of all the classes in the dataset. This is achieved via modelling the effective class frequency based on the exponential forgetting observed in neural networks and encouraging the GAN to focus on underrepresented classes. We demonstrate the utility of our regularizer in learning representations for long-tailed distributions via achieving better performance than existing approaches over multiple datasets. Specifically, when applied to an unconditional GAN, it improves the FID from $13.03$ to $9.01$ on the long-tailed iNaturalist-$2019$ dataset.
Data Impressions: Mining Deep Models to Extract Samples for Data-free Applications
Jan 15, 2021
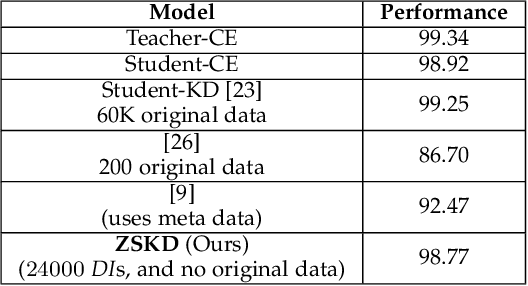

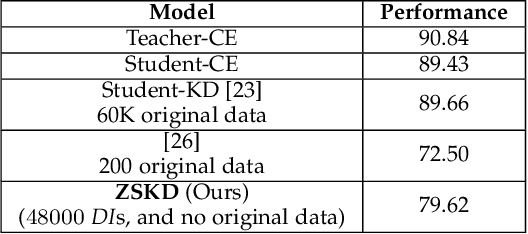
Pretrained deep models hold their learnt knowledge in the form of the model parameters. These parameters act as memory for the trained models and help them generalize well on unseen data. However, in absence of training data, the utility of a trained model is merely limited to either inference or better initialization towards a target task. In this paper, we go further and extract synthetic data by leveraging the learnt model parameters. We dub them "Data Impressions", which act as proxy to the training data and can be used to realize a variety of tasks. These are useful in scenarios where only the pretrained models are available and the training data is not shared (e.g., due to privacy or sensitivity concerns). We show the applicability of data impressions in solving several computer vision tasks such as unsupervised domain adaptation, continual learning as well as knowledge distillation. We also study the adversarial robustness of the lightweight models trained via knowledge distillation using these data impressions. Further, we demonstrate the efficacy of data impressions in generating UAPs with better fooling rates. Extensive experiments performed on several benchmark datasets demonstrate competitive performance achieved using data impressions in absence of the original training data.
Effectiveness of Arbitrary Transfer Sets for Data-free Knowledge Distillation
Nov 18, 2020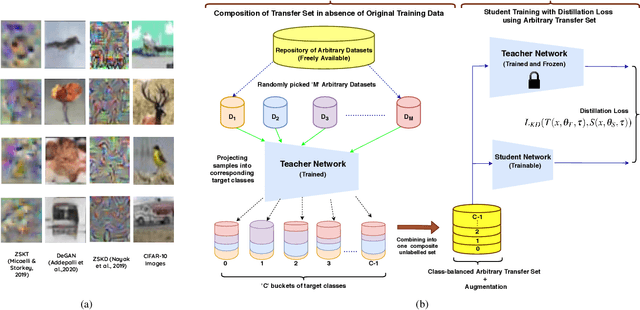
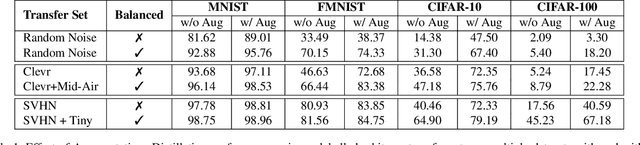
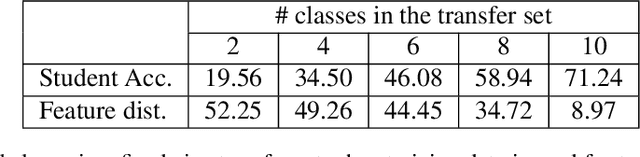
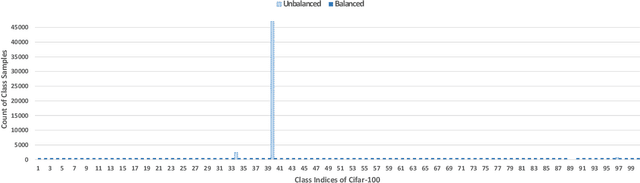
Knowledge Distillation is an effective method to transfer the learning across deep neural networks. Typically, the dataset originally used for training the Teacher model is chosen as the "Transfer Set" to conduct the knowledge transfer to the Student. However, this original training data may not always be freely available due to privacy or sensitivity concerns. In such scenarios, existing approaches either iteratively compose a synthetic set representative of the original training dataset, one sample at a time or learn a generative model to compose such a transfer set. However, both these approaches involve complex optimization (GAN training or several backpropagation steps to synthesize one sample) and are often computationally expensive. In this paper, as a simple alternative, we investigate the effectiveness of "arbitrary transfer sets" such as random noise, publicly available synthetic, and natural datasets, all of which are completely unrelated to the original training dataset in terms of their visual or semantic contents. Through extensive experiments on multiple benchmark datasets such as MNIST, FMNIST, CIFAR-10 and CIFAR-100, we discover and validate surprising effectiveness of using arbitrary data to conduct knowledge distillation when this dataset is "target-class balanced". We believe that this important observation can potentially lead to designing baselines for the data-free knowledge distillation task.
Dataset Condensation with Gradient Matching
Jun 10, 2020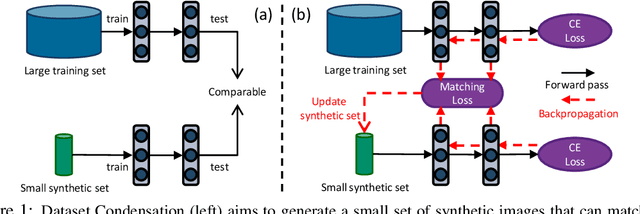
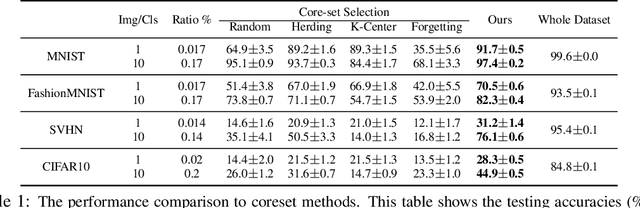
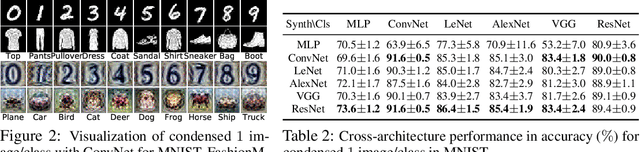
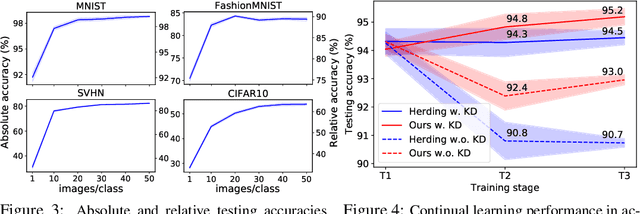
Efficient training of deep neural networks is an increasingly important problem in the era of sophisticated architectures and large-scale datasets. This paper proposes a training set synthesis technique, called Dataset Condensation, that learns to produce a small set of informative samples for training deep neural networks from scratch in a small fraction of the required computational cost on the original data while achieving comparable results. We rigorously evaluate its performance in several computer vision benchmarks and show that it significantly outperforms the state-of-the-art methods. Finally we show promising applications of our method in continual learning and domain adaptation.