 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIRS-Bench: a Suite of Tasks for Frontier AI Research Science Agents
Feb 09, 2026LLM agents hold significant promise for advancing scientific research. To accelerate this progress, we introduce AIRS-Bench (the AI Research Science Benchmark), a suite of 20 tasks sourced from state-of-the-art machine learning papers. These tasks span diverse domains, including language modeling, mathematics, bioinformatics, and time series forecasting. AIRS-Bench tasks assess agentic capabilities over the full research lifecycle -- including idea generation, experiment analysis and iterative refinement -- without providing baseline code. The AIRS-Bench task format is versatile, enabling easy integration of new tasks and rigorous comparison across different agentic frameworks. We establish baselines using frontier models paired with both sequential and parallel scaffolds. Our results show that agents exceed human SOTA in four tasks but fail to match it in sixteen others. Even when agents surpass human benchmarks, they do not reach the theoretical performance ceiling for the underlying tasks. These findings indicate that AIRS-Bench is far from saturated and offers substantial room for improvement. We open-source the AIRS-Bench task definitions and evaluation code to catalyze further development in autonomous scientific research.
Using Deep Learning-based Features Extracted from CT scans to Predict Outcomes in COVID-19 Patients
May 10, 2022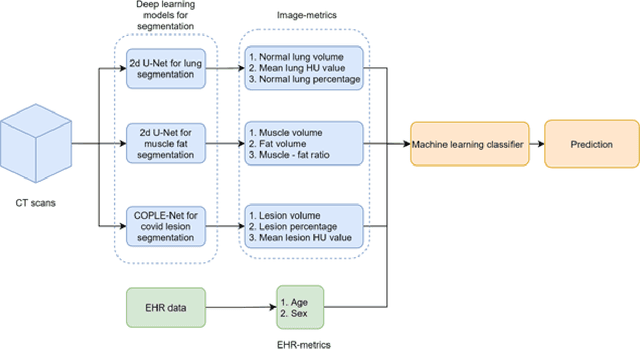

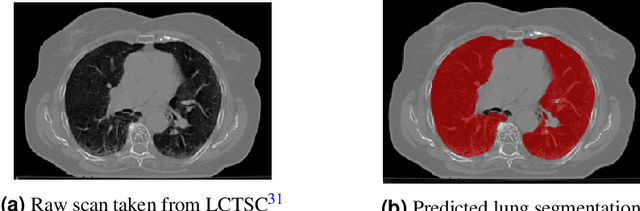
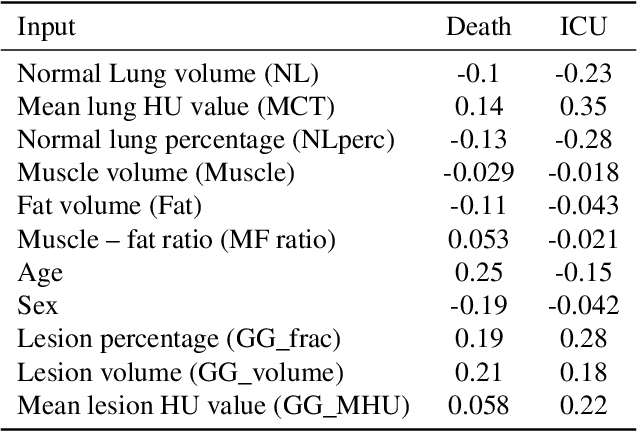
The COVID-19 pandemic has had a considerable impact on day-to-day life. Tackling the disease by providing the necessary resources to the affected is of paramount importance. However, estimation of the required resources is not a trivial task given the number of factors which determine the requirement. This issue can be addressed by predicting the probability that an infected patient requires Intensive Care Unit (ICU) support and the importance of each of the factors that influence it. Moreover, to assist the doctors in determining the patients at high risk of fatality, the probability of death is also calculated. For determining both the patient outcomes (ICU admission and death), a novel methodology is proposed by combining multi-modal features, extracted from Computed Tomography (CT) scans and Electronic Health Record (EHR) data. Deep learning models are leveraged to extract quantitative features from CT scans. These features combined with those directly read from the EHR database are fed into machine learning models to eventually output the probabilities of patient outcomes. This work demonstrates both the ability to apply a broad set of deep learning methods for general quantification of Chest CT scans and the ability to link these quantitative metrics to patient outcomes. The effectiveness of the proposed method is shown by testing it on an internally curated dataset, achieving a mean area under Receiver operating characteristic curve (AUC) of 0.77 on ICU admission prediction and a mean AUC of 0.73 on death prediction using the best performing classifiers.