 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Audio-Visual Separation of Dynamic Sound Sources
Feb 02, 2022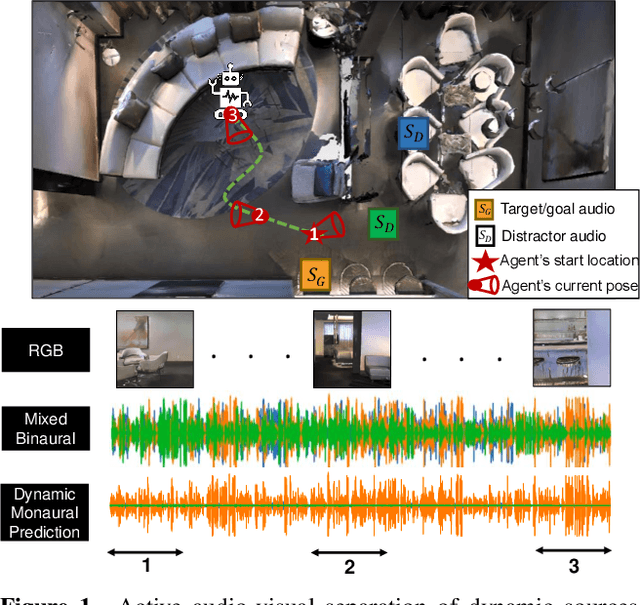
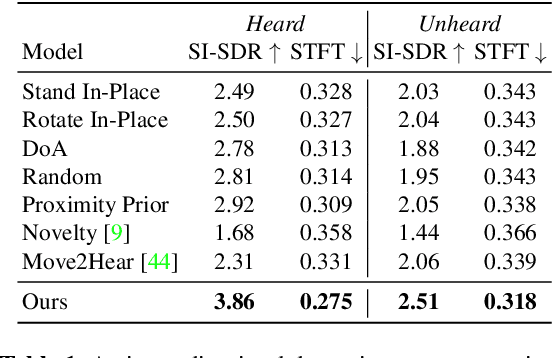
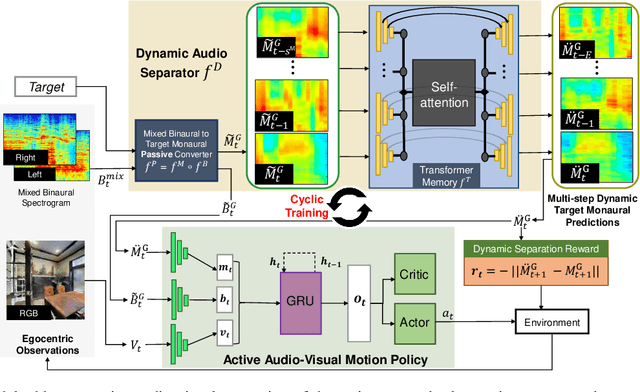
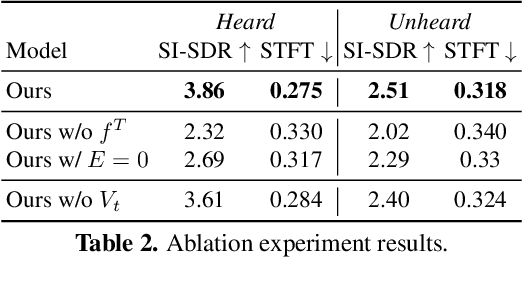
We explore active audio-visual separation for dynamic sound sources, where an embodied agent moves intelligently in a 3D environment to continuously isolate the time-varying audio stream being emitted by an object of interest. The agent hears a mixed stream of multiple time-varying audio sources (e.g., multiple people conversing and a band playing music at a noisy party). Given a limited time budget, it needs to extract the target sound using egocentric audio-visual observations. We propose a reinforcement learning agent equipped with a novel transformer memory that learns motion policies to control its camera and microphone to recover the dynamic target audio, improving its own estimates for past timesteps via self-attention. Using highly realistic acoustic SoundSpaces simulations in real-world scanned Matterport3D environments, we show that our model is able to learn efficient behavior to carry out continuous separation of a time-varying audio target. Project: https://vision.cs.utexas.edu/projects/active-av-dynamic-separation/.
Move2Hear: Active Audio-Visual Source Separation
May 15, 2021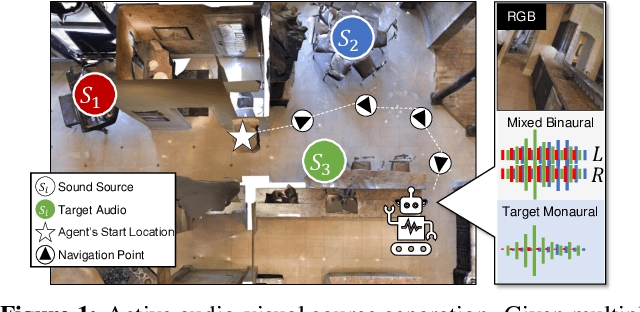
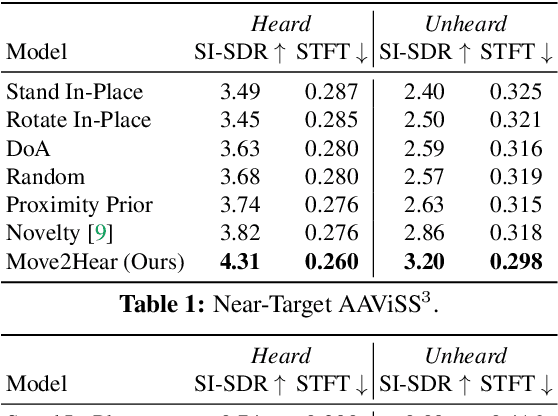
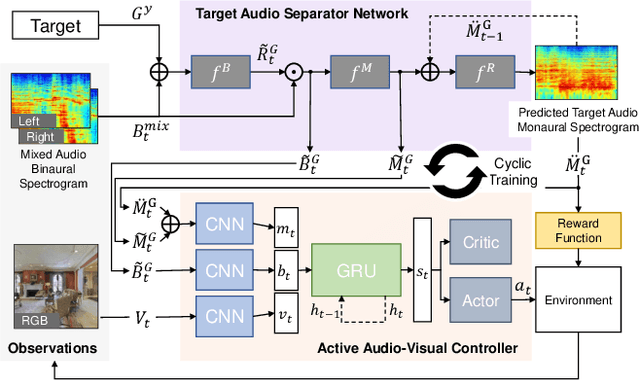
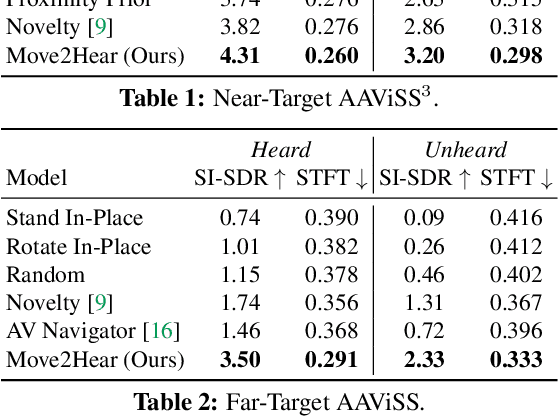
We introduce the active audio-visual source separation problem, where an agent must move intelligently in order to better isolate the sounds coming from an object of interest in its environment. The agent hears multiple audio sources simultaneously (e.g., a person speaking down the hall in a noisy household) and must use its eyes and ears to automatically separate out the sounds originating from the target object within a limited time budget. Towards this goal, we introduce a reinforcement learning approach that trains movement policies controlling the agent's camera and microphone placement over time, guided by the improvement in predicted audio separation quality. We demonstrate our approach in scenarios motivated by both augmented reality (system is already co-located with the target object) and mobile robotics (agent begins arbitrarily far from the target object). Using state-of-the-art realistic audio-visual simulations in 3D environments, we demonstrate our model's ability to find minimal movement sequences with maximal payoff for audio source separation. Project: http://vision.cs.utexas.edu/projects/move2hear.
Model Agnostic Answer Reranking System for Adversarial Question Answering
Feb 05, 2021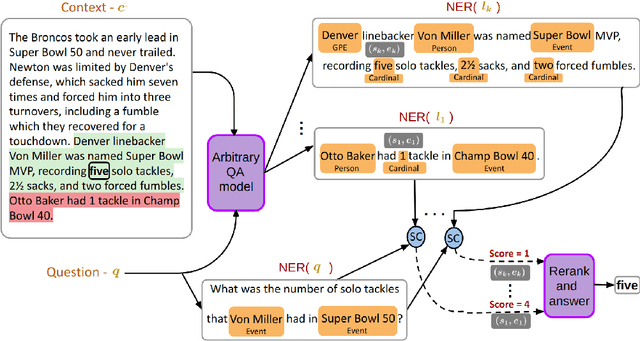

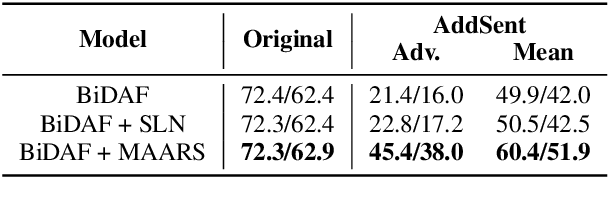

While numerous methods have been proposed as defenses against adversarial examples in question answering (QA), these techniques are often model specific, require retraining of the model, and give only marginal improvements in performance over vanilla models. In this work, we present a simple model-agnostic approach to this problem that can be applied directly to any QA model without any retraining. Our method employs an explicit answer candidate reranking mechanism that scores candidate answers on the basis of their content overlap with the question before making the final prediction. Combined with a strong base QAmodel, our method outperforms state-of-the-art defense techniques, calling into question how well these techniques are actually doing and strong these adversarial testbeds are.
Audio-Visual Waypoints for Navigation
Aug 21, 2020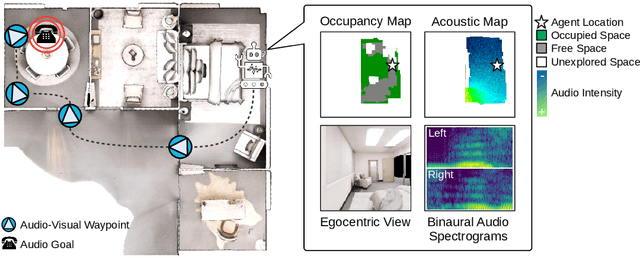
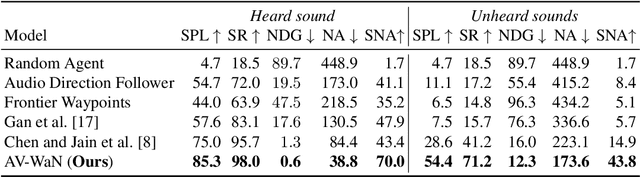
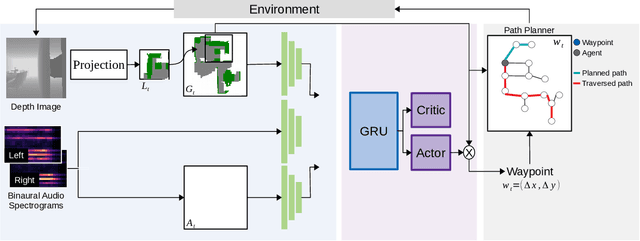
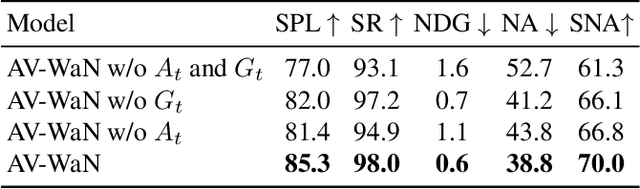
In audio-visual navigation, an agent intelligently travels through a complex, unmapped 3D environment using both sights and sounds to find a sound source (e.g., a phone ringing in another room). Existing models learn to act at a fixed granularity of agent motion and rely on simple recurrent aggregations of the audio observations. We introduce a reinforcement learning approach to audio-visual navigation with two key novel elements 1) audio-visual waypoints that are dynamically set and learned end-to-end within the navigation policy, and 2) an acoustic memory that provides a structured, spatially grounded record of what the agent has heard as it moves. Both new ideas capitalize on the synergy of audio and visual data for revealing the geometry of an unmapped space. We demonstrate our approach on the challenging Replica environments of real-world 3D scenes. Our model improves the state of the art by a substantial margin, and our experiments reveal that learning the links between sights, sounds, and space is essential for audio-visual navigation.
Open Set Recognition Through Deep Neural Network Uncertainty: Does Out-of-Distribution Detection Require Generative Classifiers?
Aug 26, 2019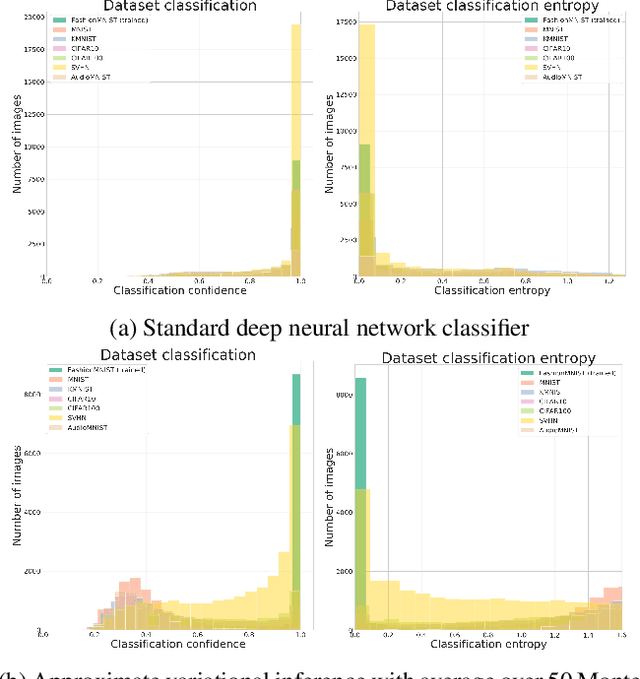
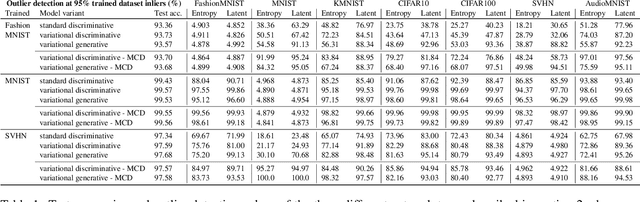
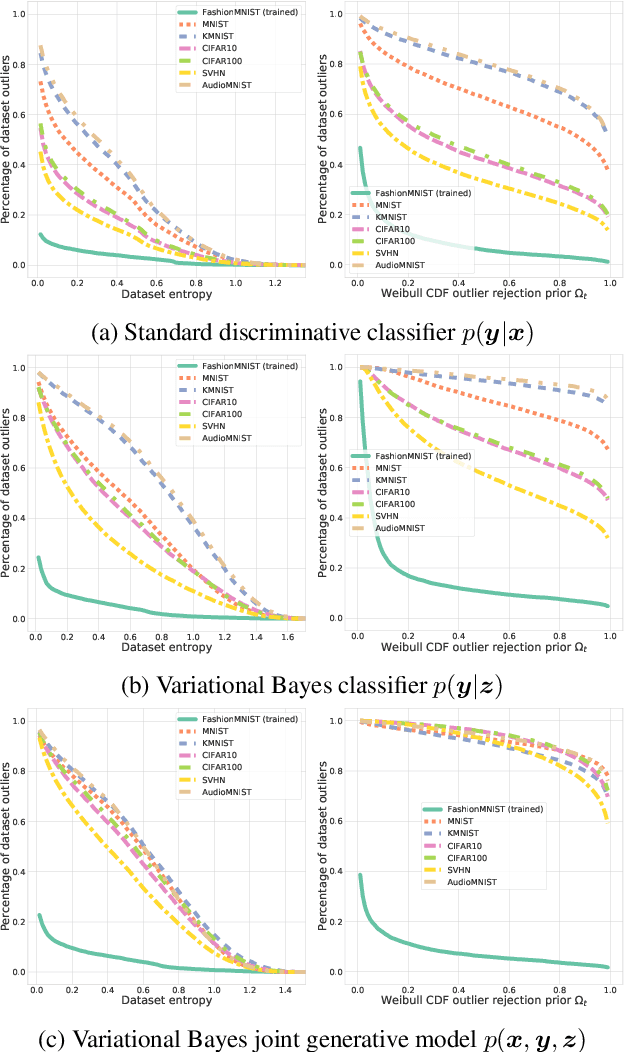
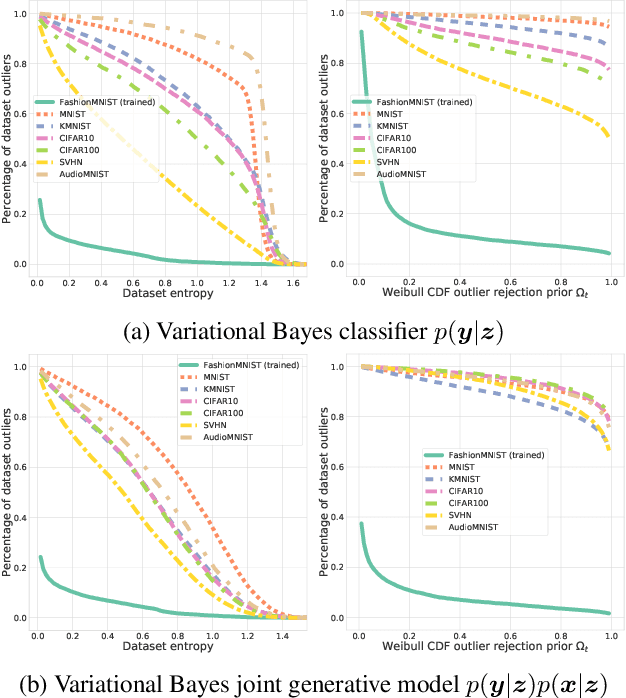
We present an analysis of predictive uncertainty based out-of-distribution detection for different approaches to estimate various models' epistemic uncertainty and contrast it with extreme value theory based open set recognition. While the former alone does not seem to be enough to overcome this challenge, we demonstrate that uncertainty goes hand in hand with the latter method. This seems to be particularly reflected in a generative model approach, where we show that posterior based open set recognition outperforms discriminative models and predictive uncertainty based outlier rejection, raising the question of whether classifiers need to be generative in order to know what they have not seen.
Unified Probabilistic Deep Continual Learning through Generative Replay and Open Set Recognition
May 28, 2019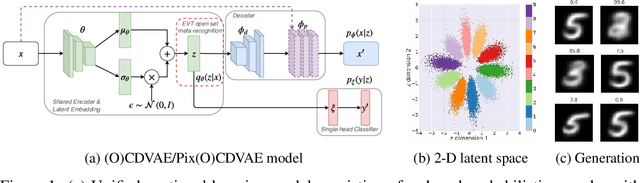
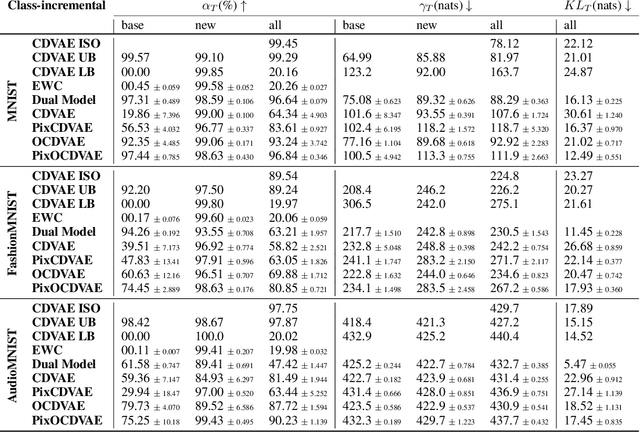
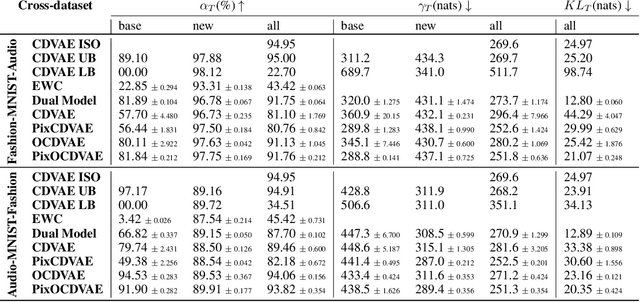
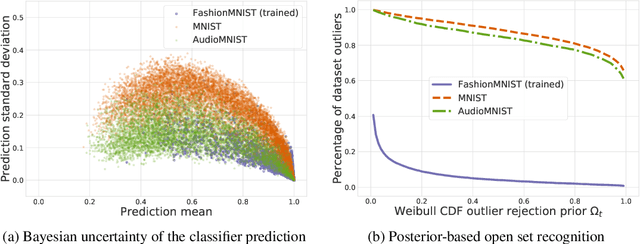
We introduce a unified probabilistic approach for deep continual learning based on variational Bayesian inference with open set recognition. Our model combines a probabilistic encoder with a generative model and a generative linear classifier that get shared across tasks. The open set recognition bounds the approximate posterior by fitting regions of high density on the basis of correctly classified data points and balances open-space risk with recognition errors. Catastrophic inference for both generative models is significantly alleviated through generative replay, where the open set recognition is used to sample from high density areas of the class specific posterior and reject statistical outliers. Our approach naturally allows for forward and backward transfer while maintaining past knowledge without the necessity of storing old data, regularization or inferring task labels. We demonstrate compelling results in the challenging scenario of incrementally expanding the single-head classifier for both class incremental visual and audio classification tasks, as well as incremental learning of datasets across modalities.
Meta-learning Convolutional Neural Architectures for Multi-target Concrete Defect Classification with the COncrete DEfect BRidge IMage Dataset
Apr 02, 2019
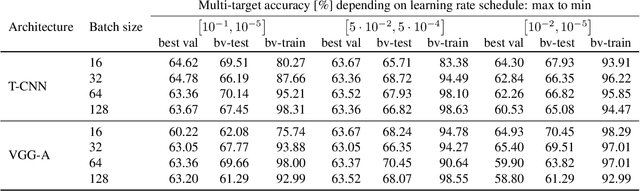
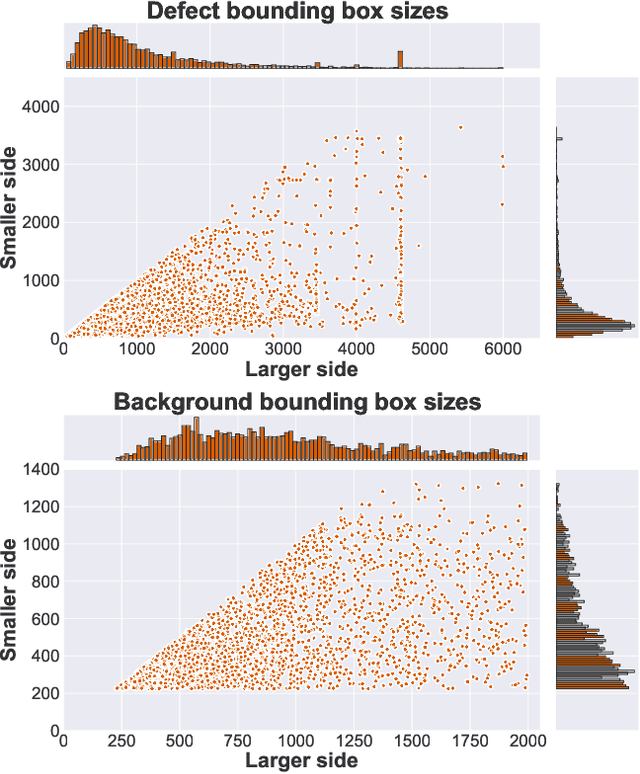
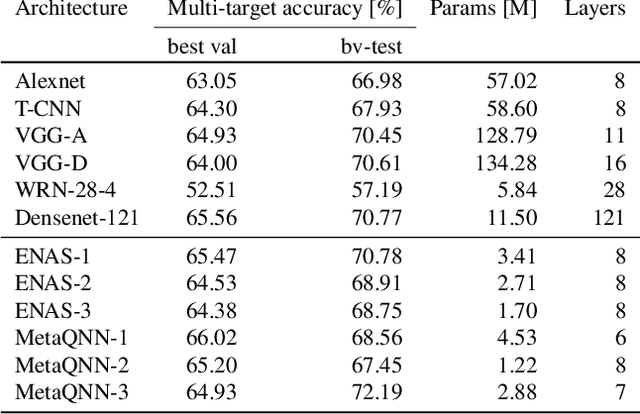
Recognition of defects in concrete infrastructure, especially in bridges, is a costly and time consuming crucial first step in the assessment of the structural integrity. Large variation in appearance of the concrete material, changing illumination and weather conditions, a variety of possible surface markings as well as the possibility for different types of defects to overlap, make it a challenging real-world task. In this work we introduce the novel COncrete DEfect BRidge IMage dataset (CODEBRIM) for multi-target classification of five commonly appearing concrete defects. We investigate and compare two reinforcement learning based meta-learning approaches, MetaQNN and efficient neural architecture search, to find suitable convolutional neural network architectures for this challenging multi-class multi-target task. We show that learned architectures have fewer overall parameters in addition to yielding better multi-target accuracy in comparison to popular neural architectures from the literature evaluated in the context of our application.
Rethinking Layer-wise Feature Amounts in Convolutional Neural Network Architectures
Dec 14, 2018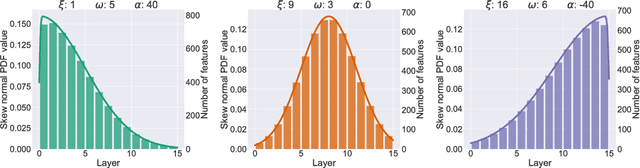
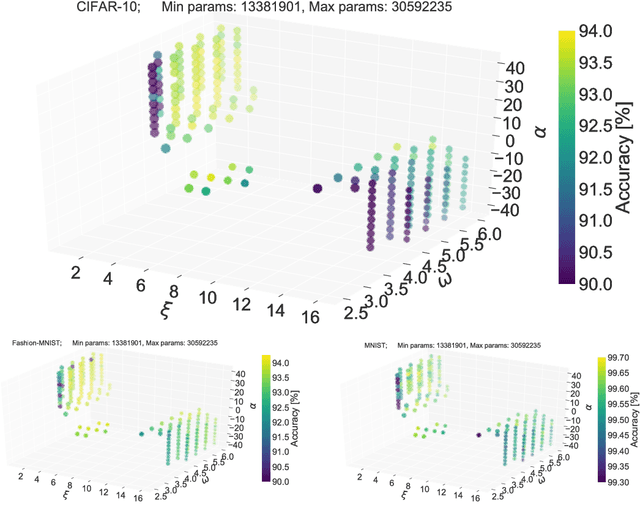
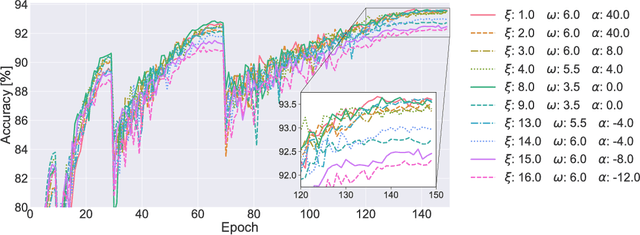
We characterize convolutional neural networks with respect to the relative amount of features per layer. Using a skew normal distribution as a parametrized framework, we investigate the common assumption of monotonously increasing feature-counts with higher layers of architecture designs. Our evaluation on models with VGG-type layers on the MNIST, Fashion-MNIST and CIFAR-10 image classification benchmarks provides evidence that motivates rethinking of our common assumption: architectures that favor larger early layers seem to yield better accuracy.
Handwritten Digit Recognition by Elastic Matching
Jul 24, 2018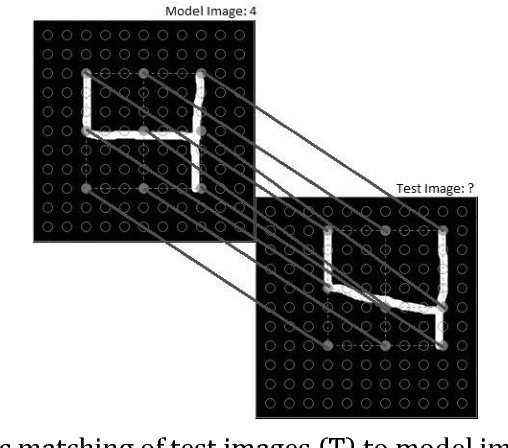
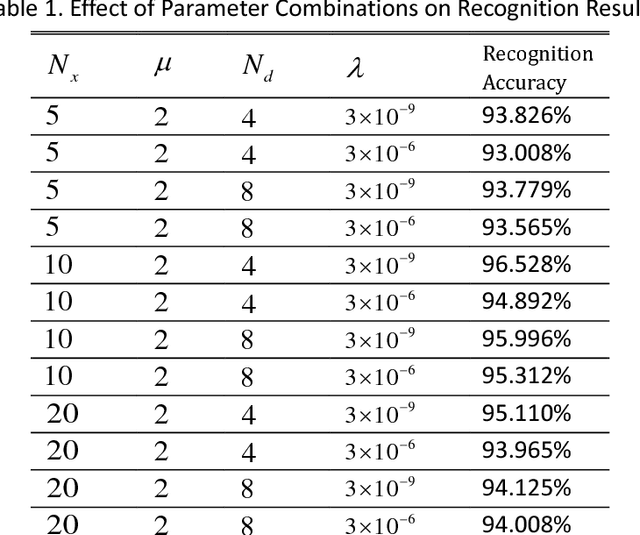
A simple model of MNIST handwritten digit recognition is presented here. The model is an adaptation of a previous theory of face recognition. It realizes translation and rotation invariance in a principled way instead of being based on extensive learning from large masses of sample data. The presented recognition rates fall short of other publications, but due to its inspectability and conceptual and numerical simplicity, our system commends itself as a basis for further development.