 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable-length Neural Interlingua Representations for Zero-shot Neural Machine Translation
May 17, 2023



The language-independency of encoded representations within multilingual neural machine translation (MNMT) models is crucial for their generalization ability on zero-shot translation. Neural interlingua representations have been shown as an effective method for achieving this. However, fixed-length neural interlingua representations introduced in previous work can limit its flexibility and representation ability. In this study, we introduce a novel method to enhance neural interlingua representations by making their length variable, thereby overcoming the constraint of fixed-length neural interlingua representations. Our empirical results on zero-shot translation on OPUS, IWSLT, and Europarl datasets demonstrate stable model convergence and superior zero-shot translation results compared to fixed-length neural interlingua representations. However, our analysis reveals the suboptimal efficacy of our approach in translating from certain source languages, wherein we pinpoint the defective model component in our proposed method.
Exploring the Impact of Layer Normalization for Zero-shot Neural Machine Translation
May 16, 2023This paper studies the impact of layer normalization (LayerNorm) on zero-shot translation (ZST). Recent efforts for ZST often utilize the Transformer architecture as the backbone, with LayerNorm at the input of layers (PreNorm) set as the default. However, Xu et al. (2019) has revealed that PreNorm carries the risk of overfitting the training data. Based on this, we hypothesize that PreNorm may overfit supervised directions and thus have low generalizability for ZST. Through experiments on OPUS, IWSLT, and Europarl datasets for 54 ZST directions, we demonstrate that the original Transformer setting of LayerNorm after residual connections (PostNorm) consistently outperforms PreNorm by up to 12.3 BLEU points. We then study the performance disparities by analyzing the differences in off-target rates and structural variations between PreNorm and PostNorm. This study highlights the need for careful consideration of the LayerNorm setting for ZST.
SuperDialseg: A Large-scale Dataset for Supervised Dialogue Segmentation
May 15, 2023



Dialogue segmentation is a crucial task for dialogue systems allowing a better understanding of conversational texts. Despite recent progress in unsupervised dialogue segmentation methods, their performances are limited by the lack of explicit supervised signals for training. Furthermore, the precise definition of segmentation points in conversations still remains as a challenging problem, increasing the difficulty of collecting manual annotations. In this paper, we provide a feasible definition of dialogue segmentation points with the help of document-grounded dialogues and release a large-scale supervised dataset called SuperDialseg, containing 9K dialogues based on two prevalent document-grounded dialogue corpora, and also inherit their useful dialogue-related annotations. Moreover, we propose two models to exploit the dialogue characteristics, achieving state-of-the-art performance on SuperDialseg and showing good generalization ability on the out-of-domain datasets. Additionally, we provide a benchmark including 20 models across four categories for the dialogue segmentation task with several proper evaluation metrics. Based on the analysis of the empirical studies, we also provide some insights for the task of dialogue segmentation. We believe our work is an important step forward in the field of dialogue segmentation.
Comprehensive Solution Program Centric Pretraining for Table-and-Text Hybrid Numerical Reasoning
May 12, 2023



Numerical reasoning over table-and-text hybrid passages, such as financial reports, poses significant challenges and has numerous potential applications. Noise and irrelevant variables in the model input have been a hindrance to its performance. Additionally, coarse-grained supervision of the whole solution program has impeded the model's ability to learn the underlying numerical reasoning process. In this paper, we propose three pretraining tasks that operate at both the whole program and sub-program level: Variable Integrity Ranking, which guides the model to focus on useful variables; Variable Operator Prediction, which decomposes the supervision into fine-grained single operator prediction; and Variable Keyphrase Masking, which encourages the model to identify key evidence that sub-programs are derived from. Experimental results demonstrate the effectiveness of our proposed methods, surpassing transformer-based model baselines.
GPT-RE: In-context Learning for Relation Extraction using Large Language Models
May 03, 2023



In spite of the potential for ground-breaking achievements offered by large language models (LLMs) (e.g., GPT-3), they still lag significantly behind fully-supervised baselines (e.g., fine-tuned BERT) in relation extraction (RE). This is due to the two major shortcomings of LLMs in RE: (1) low relevance regarding entity and relation in retrieved demonstrations for in-context learning; and (2) the strong inclination to wrongly classify NULL examples into other pre-defined labels. In this paper, we propose GPT-RE to bridge the gap between LLMs and fully-supervised baselines. GPT-RE successfully addresses the aforementioned issues by (1) incorporating task-specific entity representations in demonstration retrieval; and (2) enriching the demonstrations with gold label-induced reasoning logic. We evaluate GPT-RE on four widely-used RE datasets, and observe that GPT-RE achieves improvements over not only existing GPT-3 baselines, but also fully-supervised baselines. Specifically, GPT-RE achieves SOTA performances on the Semeval and SciERC datasets, and competitive performances on the TACRED and ACE05 datasets.
Textual Enhanced Contrastive Learning for Solving Math Word Problems
Nov 29, 2022



Solving math word problems is the task that analyses the relation of quantities and requires an accurate understanding of contextual natural language information. Recent studies show that current models rely on shallow heuristics to predict solutions and could be easily misled by small textual perturbations. To address this problem, we propose a Textual Enhanced Contrastive Learning framework, which enforces the models to distinguish semantically similar examples while holding different mathematical logic. We adopt a self-supervised manner strategy to enrich examples with subtle textual variance by textual reordering or problem re-construction. We then retrieve the hardest to differentiate samples from both equation and textual perspectives and guide the model to learn their representations. Experimental results show that our method achieves state-of-the-art on both widely used benchmark datasets and also exquisitely designed challenge datasets in English and Chinese. \footnote{Our code and data is available at \url{https://github.com/yiyunya/Textual_CL_MWP}
ComSearch: Equation Searching with Combinatorial Strategy for Solving Math Word Problems with Weak Supervision
Oct 13, 2022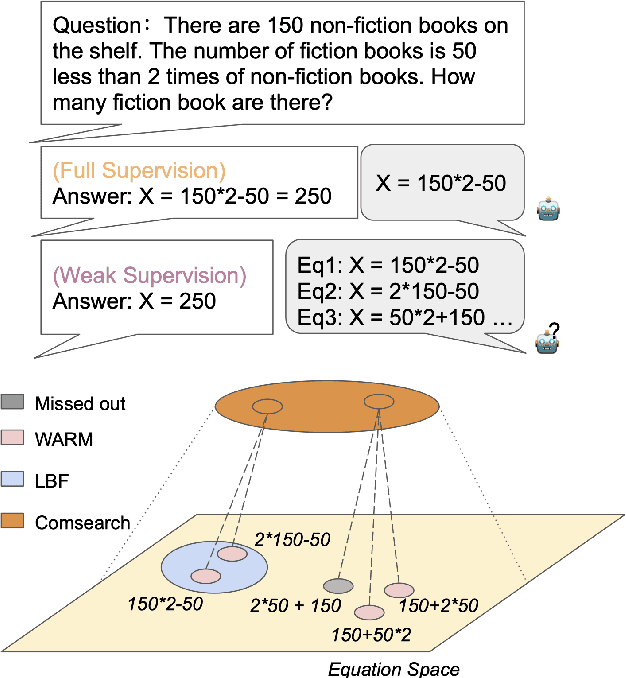

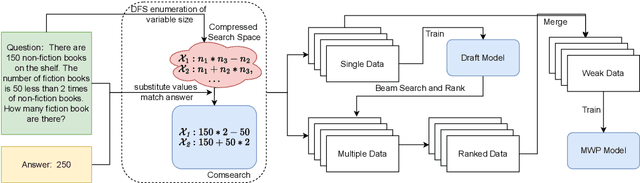

Previous studies have introduced a weakly-supervised paradigm for solving math word problems requiring only the answer value annotation. While these methods search for correct value equation candidates as pseudo labels, they search among a narrow sub-space of the enormous equation space. To address this problem, we propose a novel search algorithm with combinatorial strategy \textbf{ComSearch}, which can compress the search space by excluding mathematically equivalent equations. The compression allows the searching algorithm to enumerate all possible equations and obtain high-quality data. We investigate the noise in the pseudo labels that hold wrong mathematical logic, which we refer to as the \textit{false-matching} problem, and propose a ranking model to denoise the pseudo labels. Our approach holds a flexible framework to utilize two existing supervised math word problem solvers to train pseudo labels, and both achieve state-of-the-art performance in the weak supervision task.
Seeking Diverse Reasoning Logic: Controlled Equation Expression Generation for Solving Math Word Problems
Sep 21, 2022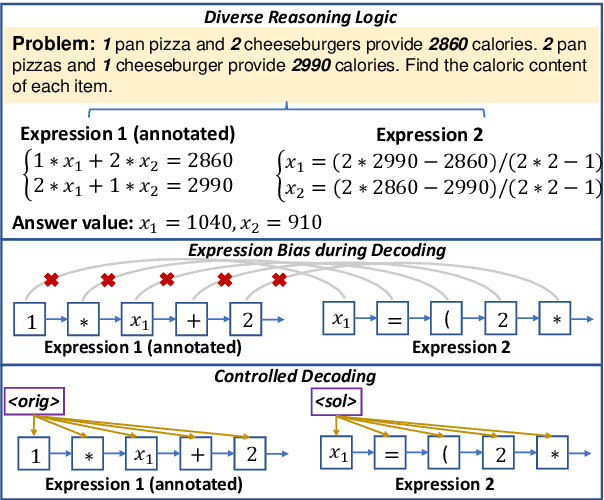
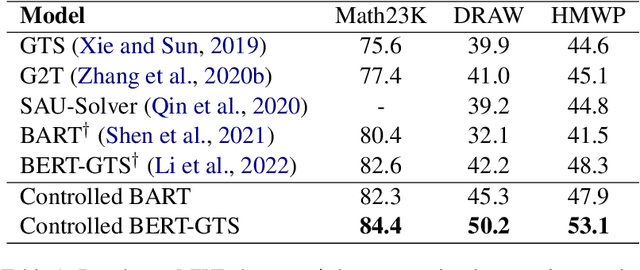
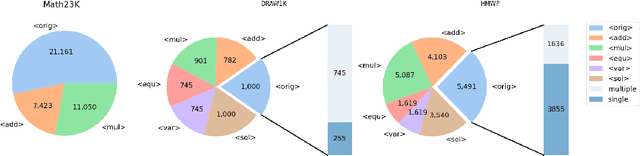
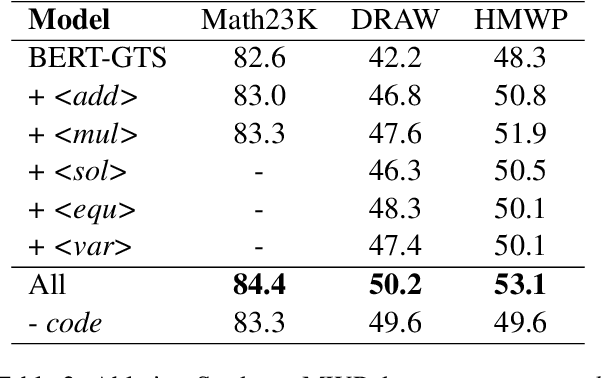
To solve Math Word Problems, human students leverage diverse reasoning logic that reaches different possible equation solutions. However, the mainstream sequence-to-sequence approach of automatic solvers aims to decode a fixed solution equation supervised by human annotation. In this paper, we propose a controlled equation generation solver by leveraging a set of control codes to guide the model to consider certain reasoning logic and decode the corresponding equations expressions transformed from the human reference. The empirical results suggest that our method universally improves the performance on single-unknown (Math23K) and multiple-unknown (DRAW1K, HMWP) benchmarks, with substantial improvements up to 13.2% accuracy on the challenging multiple-unknown datasets.
EMS: Efficient and Effective Massively Multilingual Sentence Representation Learning
May 31, 2022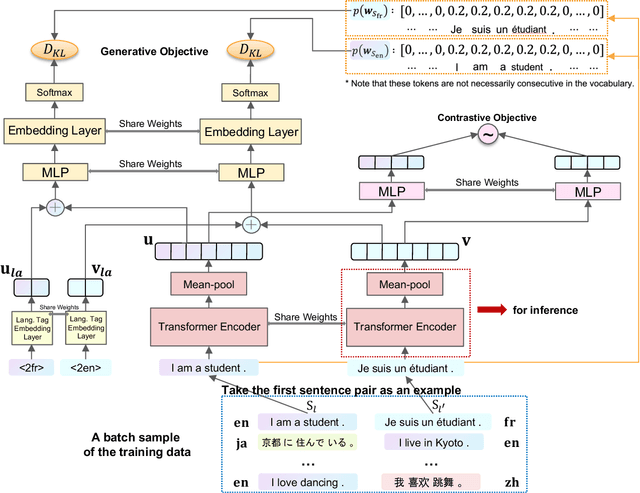



Massively multilingual sentence representation models, e.g., LASER, SBERT-distill, and LaBSE, help significantly improve cross-lingual downstream tasks. However, multiple training procedures, the use of a large amount of data, or inefficient model architectures result in heavy computation to train a new model according to our preferred languages and domains. To resolve this issue, we introduce efficient and effective massively multilingual sentence representation learning (EMS), using cross-lingual sentence reconstruction (XTR) and sentence-level contrastive learning as training objectives. Compared with related studies, the proposed model can be efficiently trained using significantly fewer parallel sentences and GPU computation resources without depending on large-scale pre-trained models. Empirical results show that the proposed model significantly yields better or comparable results with regard to bi-text mining, zero-shot cross-lingual genre classification, and sentiment classification. Ablative analyses demonstrate the effectiveness of each component of the proposed model. We release the codes for model training and the EMS pre-trained model, which supports 62 languages (https://github.com/Mao-KU/EMS).
Relation Extraction with Weighted Contrastive Pre-training on Distant Supervision
May 18, 2022

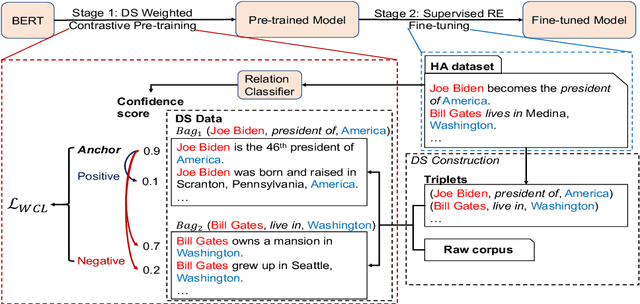
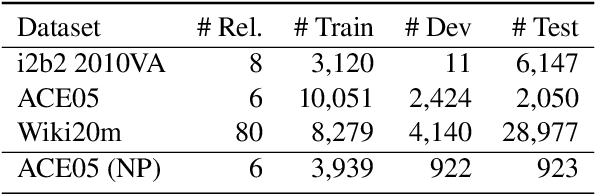
Contrastive pre-training on distant supervision has shown remarkable effectiveness for improving supervised relation extraction tasks. However, the existing methods ignore the intrinsic noise of distant supervision during the pre-training stage. In this paper, we propose a weighted contrastive learning method by leveraging the supervised data to estimate the reliability of pre-training instances and explicitly reduce the effect of noise. Experimental results on three supervised datasets demonstrate the advantages of our proposed weighted contrastive learning approach, compared to two state-of-the-art non-weighted baselines.