 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoGaIN: Poisson-Gaussian Image Noise Modeling from Paired Samples
Oct 10, 2022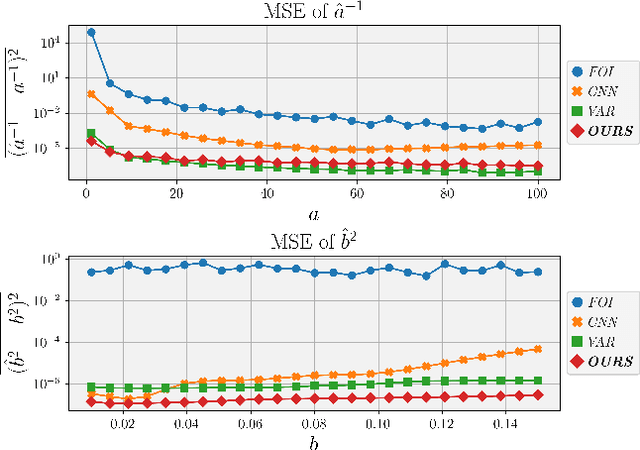
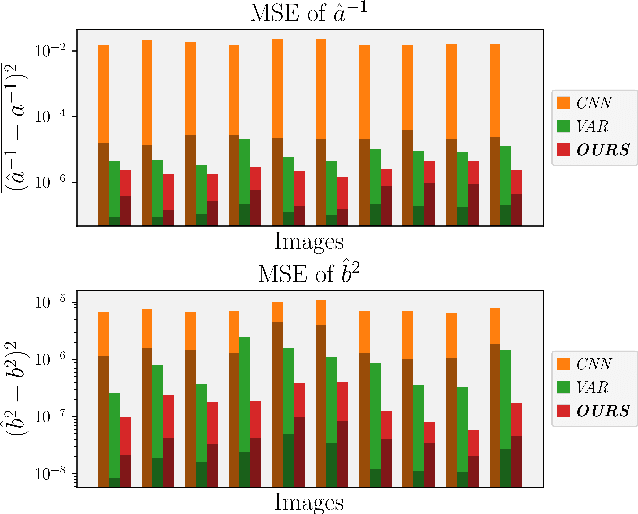
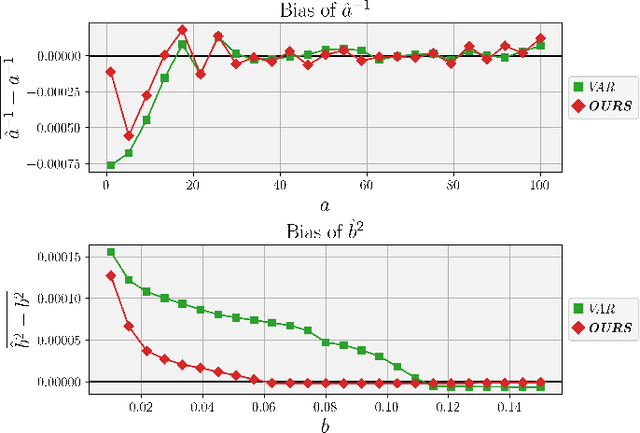
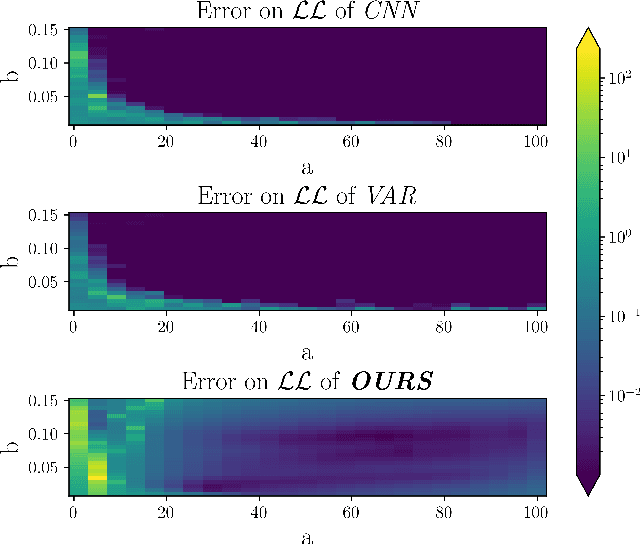
Image noise can often be accurately fitted to a Poisson-Gaussian distribution. However, estimating the distribution parameters from only a noisy image is a challenging task. Here, we study the case when paired noisy and noise-free samples are available. No method is currently available to exploit the noise-free information, which holds the promise of achieving more accurate estimates. To fill this gap, we derive a novel, cumulant-based, approach for Poisson-Gaussian noise modeling from paired image samples. We show its improved performance over different baselines with special emphasis on MSE, effect of outliers, image dependence and bias, and additionally derive the log-likelihood function for further insight and discuss real-world applicability.
DSR: Towards Drone Image Super-Resolution
Aug 25, 2022
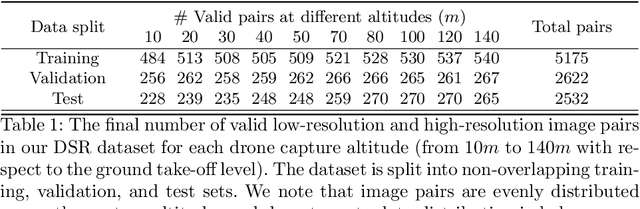

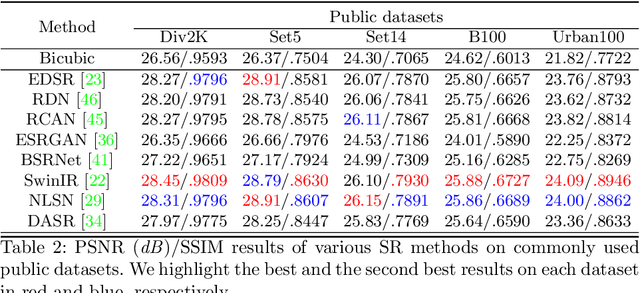
Despite achieving remarkable progress in recent years, single-image super-resolution methods are developed with several limitations. Specifically, they are trained on fixed content domains with certain degradations (whether synthetic or real). The priors they learn are prone to overfitting the training configuration. Therefore, the generalization to novel domains such as drone top view data, and across altitudes, is currently unknown. Nonetheless, pairing drones with proper image super-resolution is of great value. It would enable drones to fly higher covering larger fields of view, while maintaining a high image quality. To answer these questions and pave the way towards drone image super-resolution, we explore this application with particular focus on the single-image case. We propose a novel drone image dataset, with scenes captured at low and high resolutions, and across a span of altitudes. Our results show that off-the-shelf state-of-the-art networks witness a significant drop in performance on this different domain. We additionally show that simple fine-tuning, and incorporating altitude awareness into the network's architecture, both improve the reconstruction performance.
Fast Adversarial Training with Adaptive Step Size
Jun 06, 2022
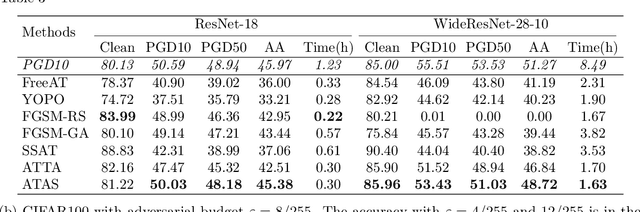
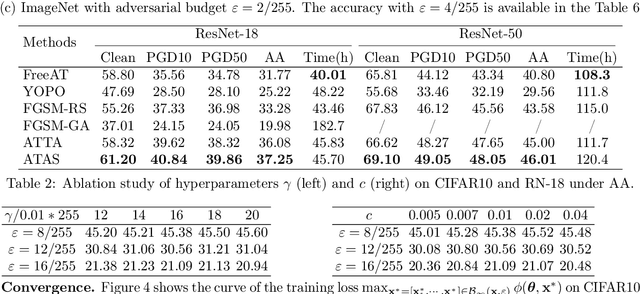
While adversarial training and its variants have shown to be the most effective algorithms to defend against adversarial attacks, their extremely slow training process makes it hard to scale to large datasets like ImageNet. The key idea of recent works to accelerate adversarial training is to substitute multi-step attacks (e.g., PGD) with single-step attacks (e.g., FGSM). However, these single-step methods suffer from catastrophic overfitting, where the accuracy against PGD attack suddenly drops to nearly 0% during training, destroying the robustness of the networks. In this work, we study the phenomenon from the perspective of training instances. We show that catastrophic overfitting is instance-dependent and fitting instances with larger gradient norm is more likely to cause catastrophic overfitting. Based on our findings, we propose a simple but effective method, Adversarial Training with Adaptive Step size (ATAS). ATAS learns an instancewise adaptive step size that is inversely proportional to its gradient norm. The theoretical analysis shows that ATAS converges faster than the commonly adopted non-adaptive counterparts. Empirically, ATAS consistently mitigates catastrophic overfitting and achieves higher robust accuracy on CIFAR10, CIFAR100 and ImageNet when evaluated on various adversarial budgets.
MulT: An End-to-End Multitask Learning Transformer
May 17, 2022
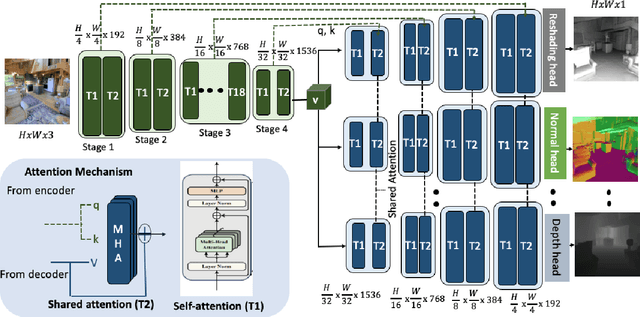
We propose an end-to-end Multitask Learning Transformer framework, named MulT, to simultaneously learn multiple high-level vision tasks, including depth estimation, semantic segmentation, reshading, surface normal estimation, 2D keypoint detection, and edge detection. Based on the Swin transformer model, our framework encodes the input image into a shared representation and makes predictions for each vision task using task-specific transformer-based decoder heads. At the heart of our approach is a shared attention mechanism modeling the dependencies across the tasks. We evaluate our model on several multitask benchmarks, showing that our MulT framework outperforms both the state-of-the art multitask convolutional neural network models and all the respective single task transformer models. Our experiments further highlight the benefits of sharing attention across all the tasks, and demonstrate that our MulT model is robust and generalizes well to new domains. Our project website is at https://ivrl.github.io/MulT/.
Leverage Your Local and Global Representations: A New Self-Supervised Learning Strategy
Apr 13, 2022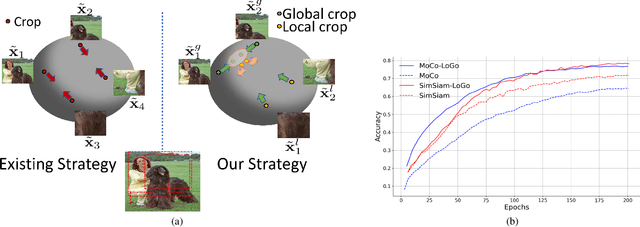
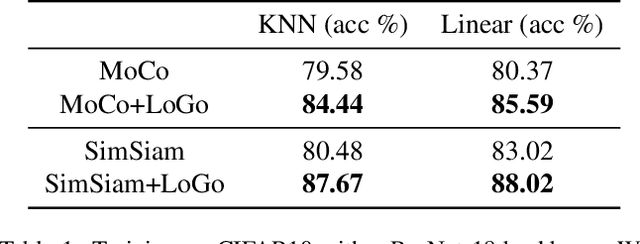
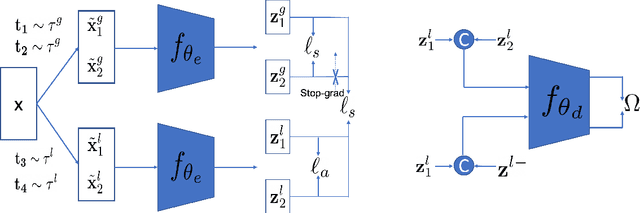
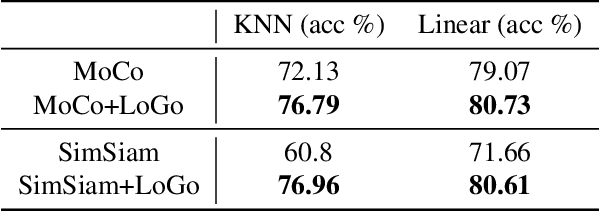
Self-supervised learning (SSL) methods aim to learn view-invariant representations by maximizing the similarity between the features extracted from different crops of the same image regardless of cropping size and content. In essence, this strategy ignores the fact that two crops may truly contain different image information, e.g., background and small objects, and thus tends to restrain the diversity of the learned representations. In this work, we address this issue by introducing a new self-supervised learning strategy, LoGo, that explicitly reasons about Local and Global crops. To achieve view invariance, LoGo encourages similarity between global crops from the same image, as well as between a global and a local crop. However, to correctly encode the fact that the content of smaller crops may differ entirely, LoGo promotes two local crops to have dissimilar representations, while being close to global crops. Our LoGo strategy can easily be applied to existing SSL methods. Our extensive experiments on a variety of datasets and using different self-supervised learning frameworks validate its superiority over existing approaches. Noticeably, we achieve better results than supervised models on transfer learning when using only 1/10 of the data.
RC-MVSNet: Unsupervised Multi-View Stereo with Neural Rendering
Mar 14, 2022
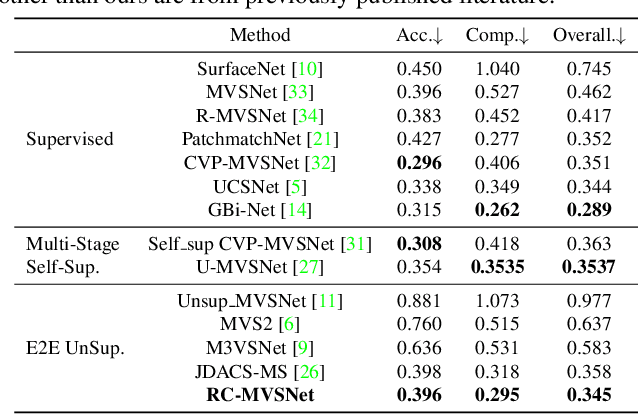
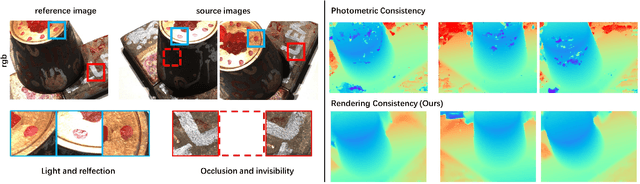
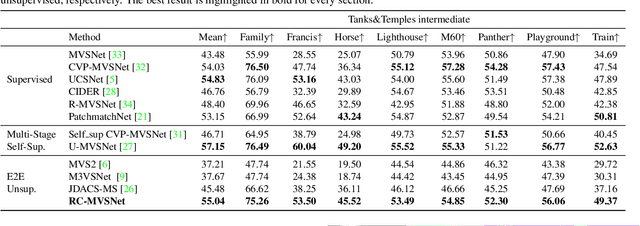
Finding accurate correspondences among different views is the Achilles' heel of unsupervised Multi-View Stereo (MVS). Existing methods are built upon the assumption that corresponding pixels share similar photometric features. However, multi-view images in real scenarios observe non-Lambertian surfaces and experience occlusions. In this work, we propose a novel approach with neural rendering (RC-MVSNet) to solve such ambiguity issues of correspondences among views. Specifically, we impose a depth rendering consistency loss to constrain the geometry features close to the object surface to alleviate occlusions. Concurrently, we introduce a reference view synthesis loss to generate consistent supervision, even for non-Lambertian surfaces. Extensive experiments on DTU and Tanks\&Temples benchmarks demonstrate that our RC-MVSNet approach achieves state-of-the-art performance over unsupervised MVS frameworks and competitive performance to many supervised methods.The trained models and code will be released at https://github.com/Boese0601/RC-MVSNet.
Robust Binary Models by Pruning Randomly-initialized Networks
Feb 03, 2022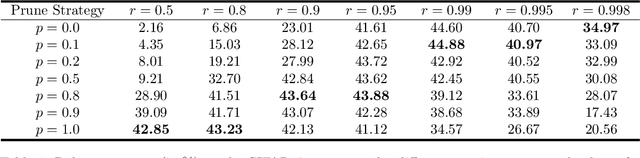
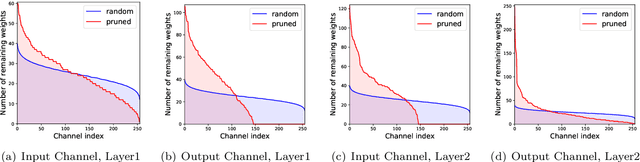

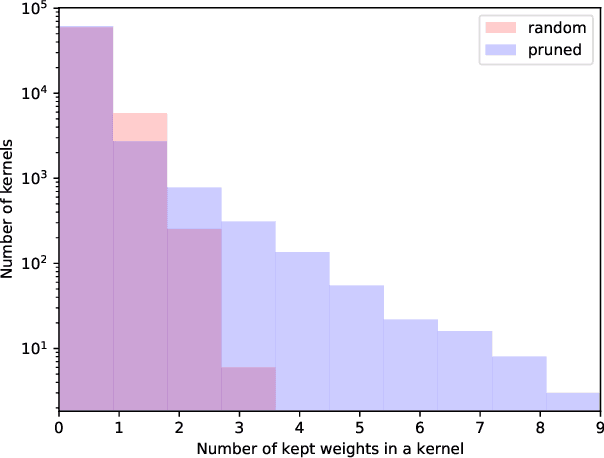
We propose ways to obtain robust models against adversarial attacks from randomly-initialized binary networks. Unlike adversarial training, which learns the model parameters, we in contrast learn the structure of the robust model by pruning a randomly-initialized binary network. Our method confirms the strong lottery ticket hypothesis in the presence of adversarial attacks. Compared to the results obtained in a non-adversarial setting, we in addition improve the performance and compression of the model by 1) using an adaptive pruning strategy for different layers, and 2) using a different initialization scheme such that all model parameters are initialized either to +1 or -1. Our extensive experiments demonstrate that our approach performs not only better than the state-of-the art for robust binary networks; it also achieves comparable or even better performance than full-precision network training methods.
Image Denoising with Control over Deep Network Hallucination
Jan 02, 2022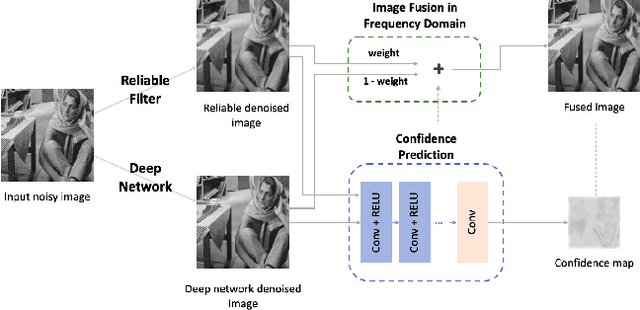
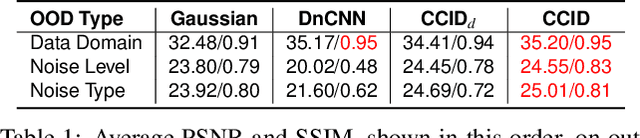

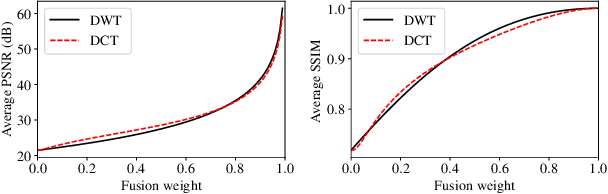
Deep image denoisers achieve state-of-the-art results but with a hidden cost. As witnessed in recent literature, these deep networks are capable of overfitting their training distributions, causing inaccurate hallucinations to be added to the output and generalizing poorly to varying data. For better control and interpretability over a deep denoiser, we propose a novel framework exploiting a denoising network. We call it controllable confidence-based image denoising (CCID). In this framework, we exploit the outputs of a deep denoising network alongside an image convolved with a reliable filter. Such a filter can be a simple convolution kernel which does not risk adding hallucinated information. We propose to fuse the two components with a frequency-domain approach that takes into account the reliability of the deep network outputs. With our framework, the user can control the fusion of the two components in the frequency domain. We also provide a user-friendly map estimating spatially the confidence in the output that potentially contains network hallucination. Results show that our CCID not only provides more interpretability and control, but can even outperform both the quantitative performance of the deep denoiser and that of the reliable filter, especially when the test data diverge from the training data.
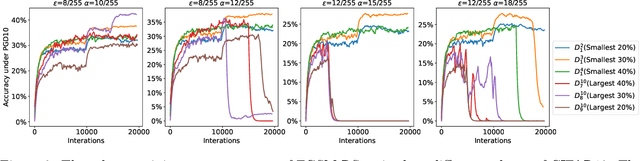
On the Impact of Hard Adversarial Instances on Overfitting in Adversarial Training
Dec 14, 2021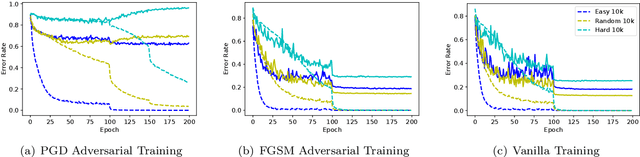

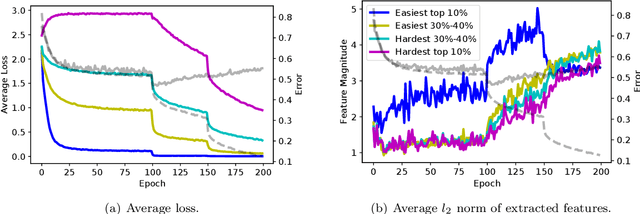
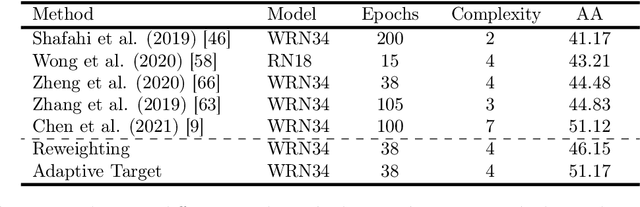
Adversarial training is a popular method to robustify models against adversarial attacks. However, it exhibits much more severe overfitting than training on clean inputs. In this work, we investigate this phenomenon from the perspective of training instances, i.e., training input-target pairs. Based on a quantitative metric measuring instances' difficulty, we analyze the model's behavior on training instances of different difficulty levels. This lets us show that the decay in generalization performance of adversarial training is a result of the model's attempt to fit hard adversarial instances. We theoretically verify our observations for both linear and general nonlinear models, proving that models trained on hard instances have worse generalization performance than ones trained on easy instances. Furthermore, we prove that the difference in the generalization gap between models trained by instances of different difficulty levels increases with the size of the adversarial budget. Finally, we conduct case studies on methods mitigating adversarial overfitting in several scenarios. Our analysis shows that methods successfully mitigating adversarial overfitting all avoid fitting hard adversarial instances, while ones fitting hard adversarial instances do not achieve true robustness.
Optimizing Latent Space Directions For GAN-based Local Image Editing
Nov 24, 2021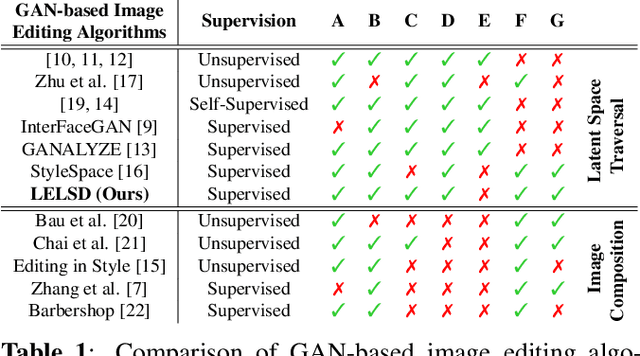
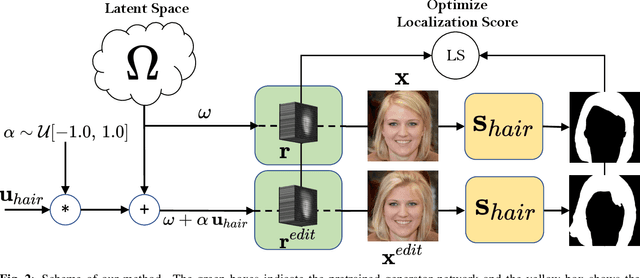


Generative Adversarial Network (GAN) based localized image editing can suffer ambiguity between semantic attributes. We thus present a novel objective function to evaluate the locality of an image edit. By introducing the supervision from a pre-trained segmentation network and optimizing the objective function, our framework, called Locally Effective Latent Space Direction (LELSD), is applicable to any dataset and GAN architecture. Our method is also computationally fast and exhibits a high extent of disentanglement, which allows users to interactively perform a sequence of edits on an image. Our experiments on both GAN-generated and real images qualitatively demonstrate the high quality and advantages of our method.