 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePASS-GLM: polynomial approximate sufficient statistics for scalable Bayesian GLM inference
Nov 13, 2017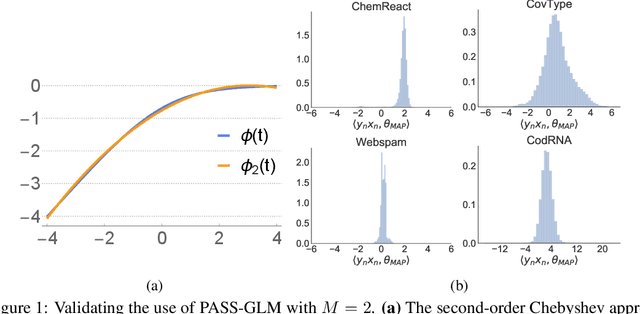
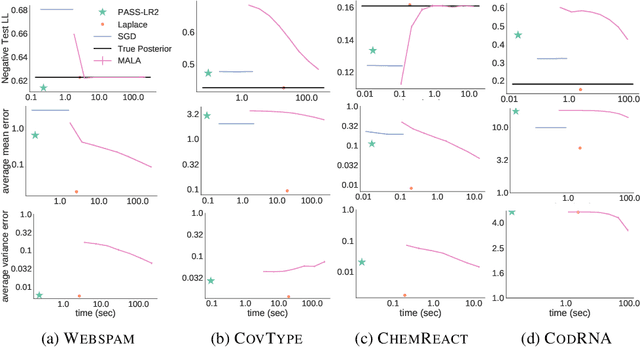
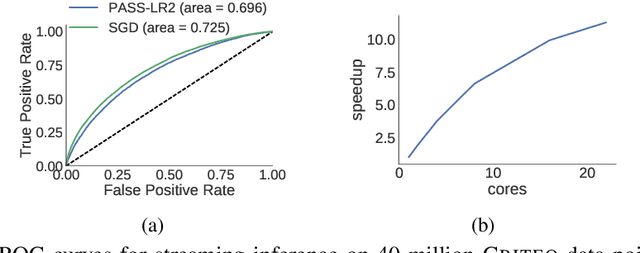
Generalized linear models (GLMs) -- such as logistic regression, Poisson regression, and robust regression -- provide interpretable models for diverse data types. Probabilistic approaches, particularly Bayesian ones, allow coherent estimates of uncertainty, incorporation of prior information, and sharing of power across experiments via hierarchical models. In practice, however, the approximate Bayesian methods necessary for inference have either failed to scale to large data sets or failed to provide theoretical guarantees on the quality of inference. We propose a new approach based on constructing polynomial approximate sufficient statistics for GLMs (PASS-GLM). We demonstrate that our method admits a simple algorithm as well as trivial streaming and distributed extensions that do not compound error across computations. We provide theoretical guarantees on the quality of point (MAP) estimates, the approximate posterior, and posterior mean and uncertainty estimates. We validate our approach empirically in the case of logistic regression using a quadratic approximation and show competitive performance with stochastic gradient descent, MCMC, and the Laplace approximation in terms of speed and multiple measures of accuracy -- including on an advertising data set with 40 million data points and 20,000 covariates.
Composing graphical models with neural networks for structured representations and fast inference
Jul 07, 2017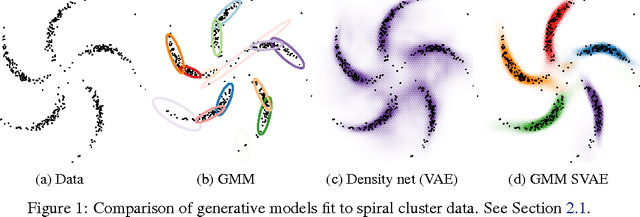
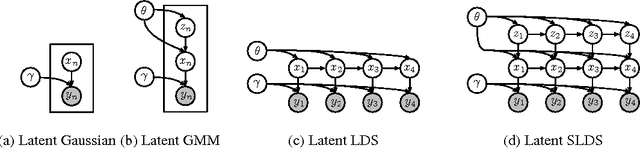
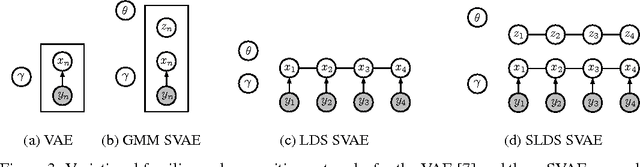
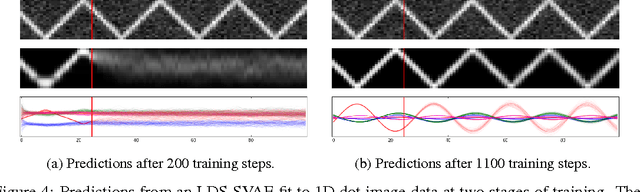
We propose a general modeling and inference framework that composes probabilistic graphical models with deep learning methods and combines their respective strengths. Our model family augments graphical structure in latent variables with neural network observation models. For inference, we extend variational autoencoders to use graphical model approximating distributions with recognition networks that output conjugate potentials. All components of these models are learned simultaneously with a single objective, giving a scalable algorithm that leverages stochastic variational inference, natural gradients, graphical model message passing, and the reparameterization trick. We illustrate this framework with several example models and an application to mouse behavioral phenotyping.
Reducing Reparameterization Gradient Variance
May 22, 2017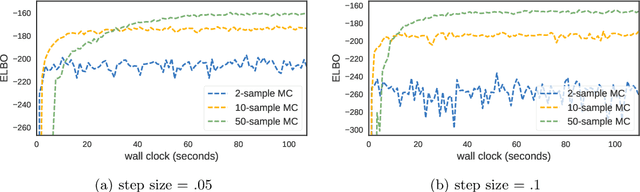
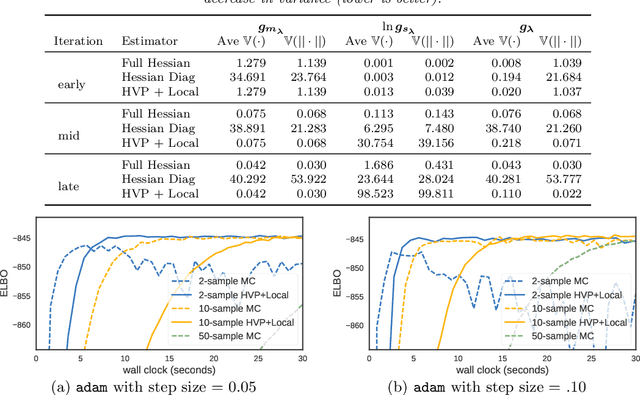

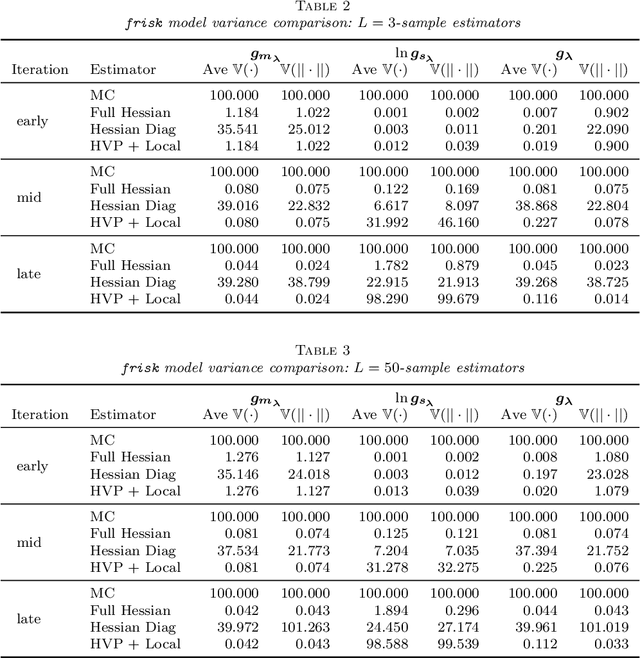
Optimization with noisy gradients has become ubiquitous in statistics and machine learning. Reparameterization gradients, or gradient estimates computed via the "reparameterization trick," represent a class of noisy gradients often used in Monte Carlo variational inference (MCVI). However, when these gradient estimators are too noisy, the optimization procedure can be slow or fail to converge. One way to reduce noise is to use more samples for the gradient estimate, but this can be computationally expensive. Instead, we view the noisy gradient as a random variable, and form an inexpensive approximation of the generating procedure for the gradient sample. This approximation has high correlation with the noisy gradient by construction, making it a useful control variate for variance reduction. We demonstrate our approach on non-conjugate multi-level hierarchical models and a Bayesian neural net where we observed gradient variance reductions of multiple orders of magnitude (20-2,000x).
Multimodal Prediction and Personalization of Photo Edits with Deep Generative Models
Apr 17, 2017

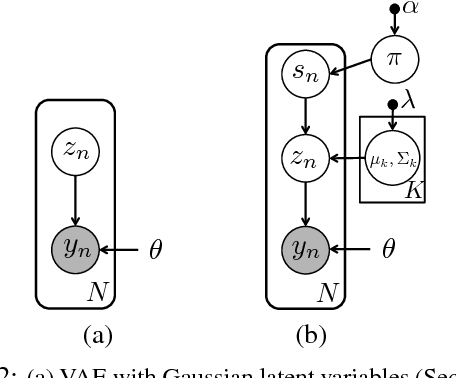
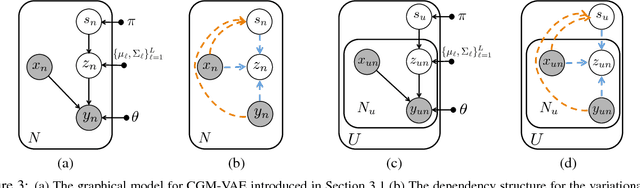
Professional-grade software applications are powerful but complicated$-$expert users can achieve impressive results, but novices often struggle to complete even basic tasks. Photo editing is a prime example: after loading a photo, the user is confronted with an array of cryptic sliders like "clarity", "temp", and "highlights". An automatically generated suggestion could help, but there is no single "correct" edit for a given image$-$different experts may make very different aesthetic decisions when faced with the same image, and a single expert may make different choices depending on the intended use of the image (or on a whim). We therefore want a system that can propose multiple diverse, high-quality edits while also learning from and adapting to a user's aesthetic preferences. In this work, we develop a statistical model that meets these objectives. Our model builds on recent advances in neural network generative modeling and scalable inference, and uses hierarchical structure to learn editing patterns across many diverse users. Empirically, we find that our model outperforms other approaches on this challenging multimodal prediction task.
Variational Boosting: Iteratively Refining Posterior Approximations
Feb 19, 2017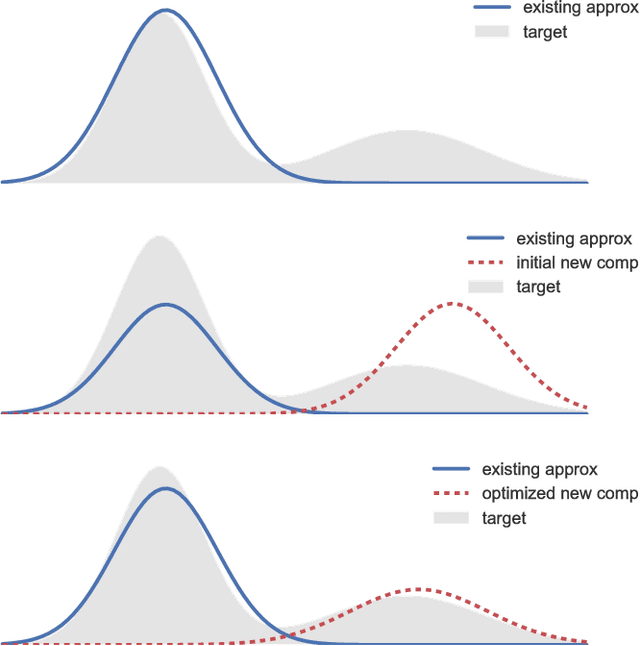
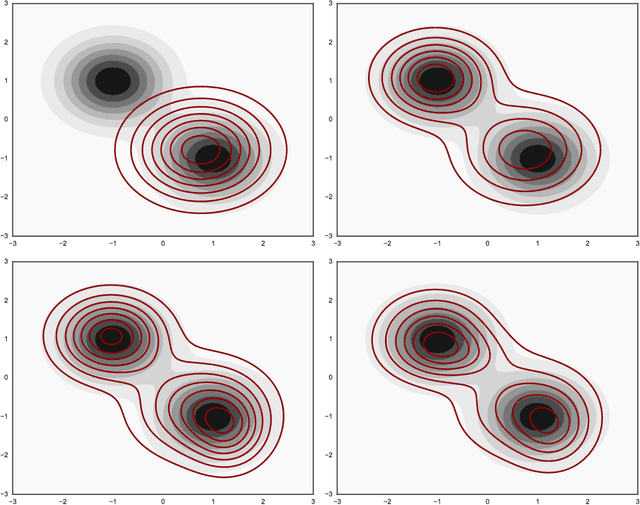
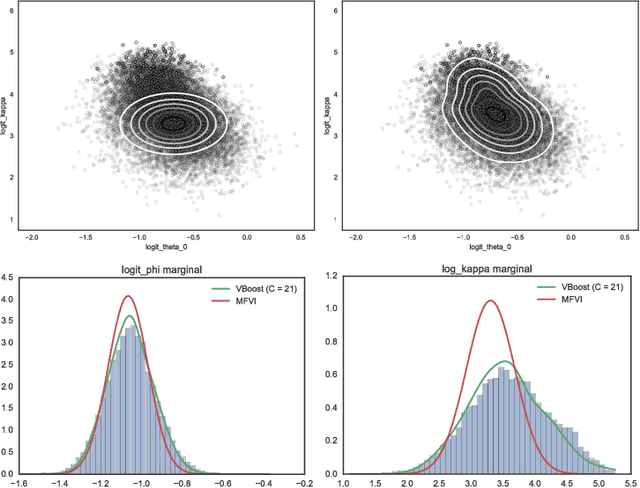
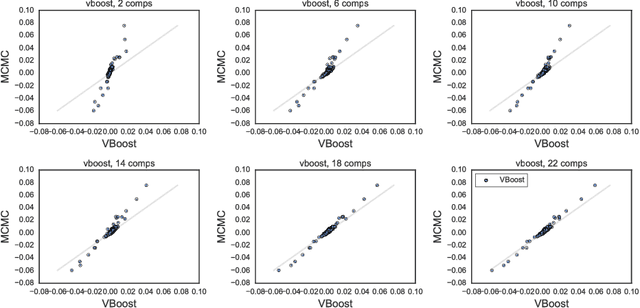
We propose a black-box variational inference method to approximate intractable distributions with an increasingly rich approximating class. Our method, termed variational boosting, iteratively refines an existing variational approximation by solving a sequence of optimization problems, allowing the practitioner to trade computation time for accuracy. We show how to expand the variational approximating class by incorporating additional covariance structure and by introducing new components to form a mixture. We apply variational boosting to synthetic and real statistical models, and show that resulting posterior inferences compare favorably to existing posterior approximation algorithms in both accuracy and efficiency.
Recurrent switching linear dynamical systems
Oct 26, 2016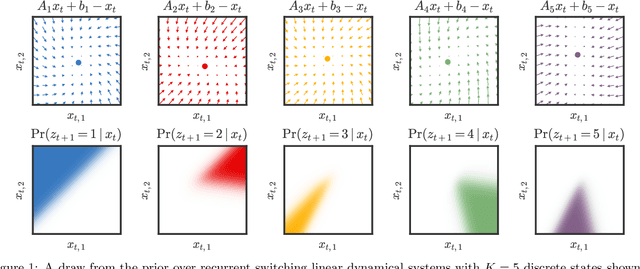
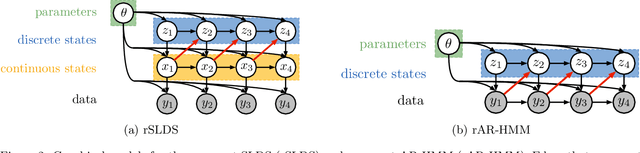
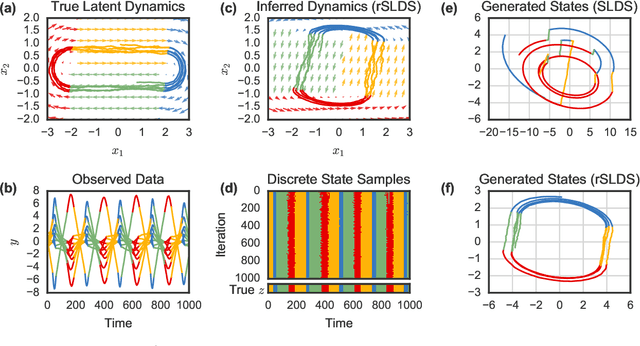
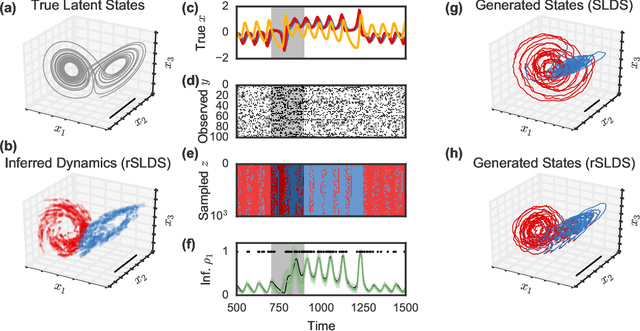
Many natural systems, such as neurons firing in the brain or basketball teams traversing a court, give rise to time series data with complex, nonlinear dynamics. We can gain insight into these systems by decomposing the data into segments that are each explained by simpler dynamic units. Building on switching linear dynamical systems (SLDS), we present a new model class that not only discovers these dynamical units, but also explains how their switching behavior depends on observations or continuous latent states. These "recurrent" switching linear dynamical systems provide further insight by discovering the conditions under which each unit is deployed, something that traditional SLDS models fail to do. We leverage recent algorithmic advances in approximate inference to make Bayesian inference in these models easy, fast, and scalable.
Bayesian latent structure discovery from multi-neuron recordings
Oct 26, 2016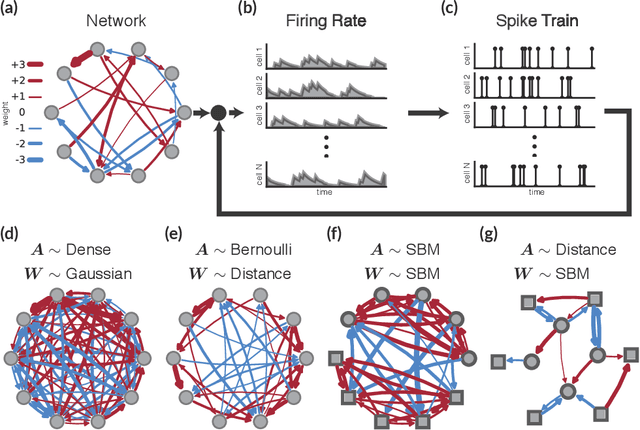

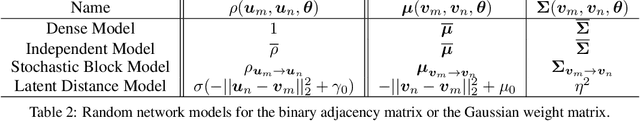
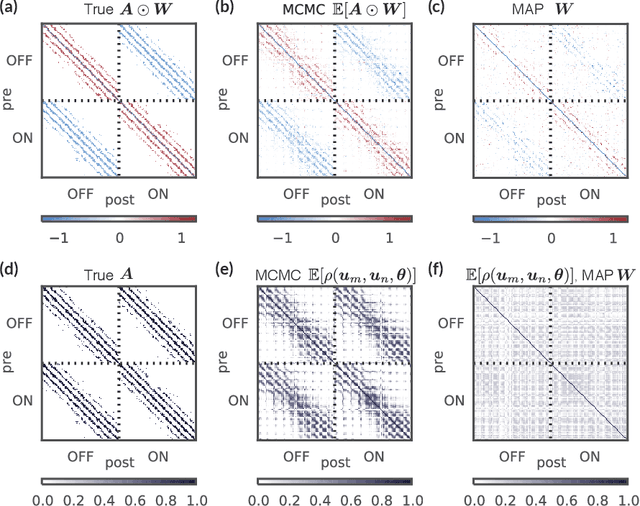
Neural circuits contain heterogeneous groups of neurons that differ in type, location, connectivity, and basic response properties. However, traditional methods for dimensionality reduction and clustering are ill-suited to recovering the structure underlying the organization of neural circuits. In particular, they do not take advantage of the rich temporal dependencies in multi-neuron recordings and fail to account for the noise in neural spike trains. Here we describe new tools for inferring latent structure from simultaneously recorded spike train data using a hierarchical extension of a multi-neuron point process model commonly known as the generalized linear model (GLM). Our approach combines the GLM with flexible graph-theoretic priors governing the relationship between latent features and neural connectivity patterns. Fully Bayesian inference via P\'olya-gamma augmentation of the resulting model allows us to classify neurons and infer latent dimensions of circuit organization from correlated spike trains. We demonstrate the effectiveness of our method with applications to synthetic data and multi-neuron recordings in primate retina, revealing latent patterns of neural types and locations from spike trains alone.
A General Framework for Constrained Bayesian Optimization using Information-based Search
Sep 04, 2016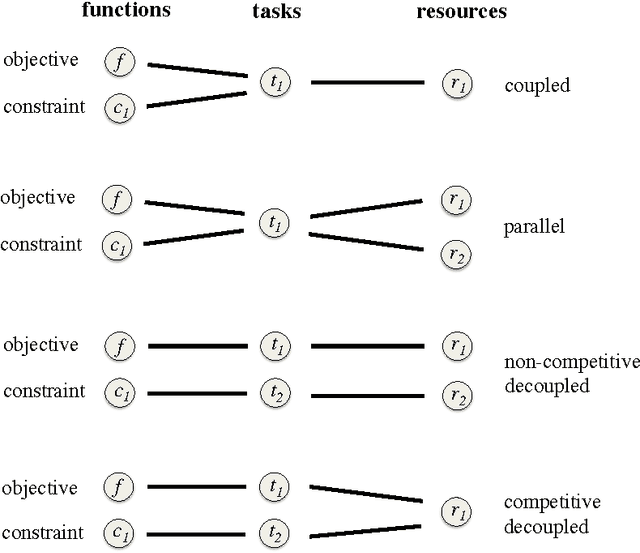
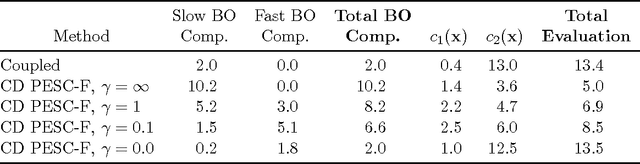
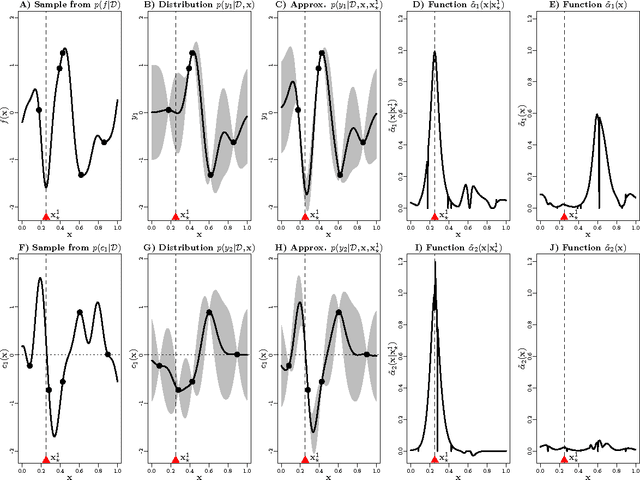
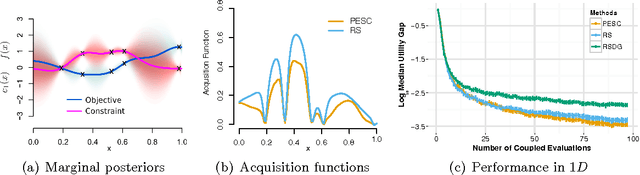
We present an information-theoretic framework for solving global black-box optimization problems that also have black-box constraints. Of particular interest to us is to efficiently solve problems with decoupled constraints, in which subsets of the objective and constraint functions may be evaluated independently. For example, when the objective is evaluated on a CPU and the constraints are evaluated independently on a GPU. These problems require an acquisition function that can be separated into the contributions of the individual function evaluations. We develop one such acquisition function and call it Predictive Entropy Search with Constraints (PESC). PESC is an approximation to the expected information gain criterion and it compares favorably to alternative approaches based on improvement in several synthetic and real-world problems. In addition to this, we consider problems with a mix of functions that are fast and slow to evaluate. These problems require balancing the amount of time spent in the meta-computation of PESC and in the actual evaluation of the target objective. We take a bounded rationality approach and develop partial update for PESC which trades off accuracy against speed. We then propose a method for adaptively switching between the partial and full updates for PESC. This allows us to interpolate between versions of PESC that are efficient in terms of function evaluations and those that are efficient in terms of wall-clock time. Overall, we demonstrate that PESC is an effective algorithm that provides a promising direction towards a unified solution for constrained Bayesian optimization.
Avoiding pathologies in very deep networks
Jul 08, 2016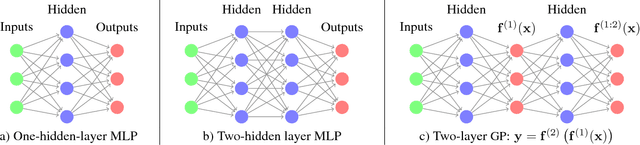
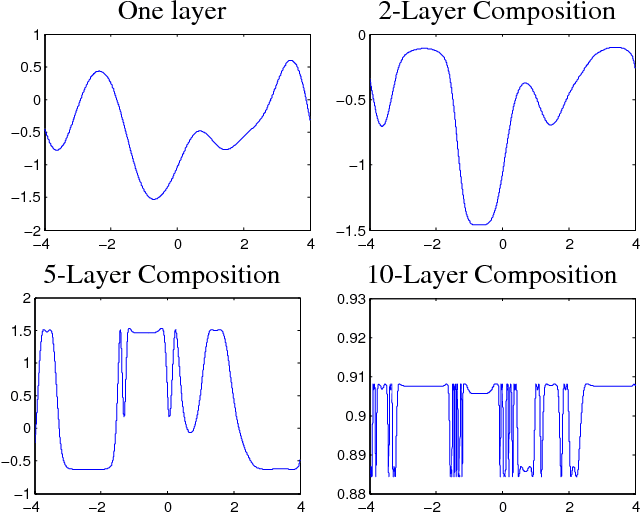
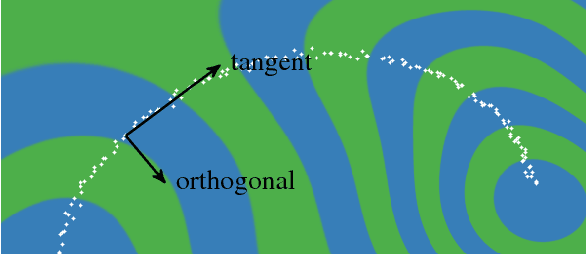
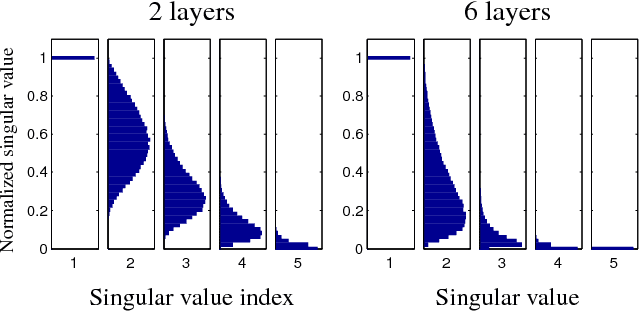
Choosing appropriate architectures and regularization strategies for deep networks is crucial to good predictive performance. To shed light on this problem, we analyze the analogous problem of constructing useful priors on compositions of functions. Specifically, we study the deep Gaussian process, a type of infinitely-wide, deep neural network. We show that in standard architectures, the representational capacity of the network tends to capture fewer degrees of freedom as the number of layers increases, retaining only a single degree of freedom in the limit. We propose an alternate network architecture which does not suffer from this pathology. We also examine deep covariance functions, obtained by composing infinitely many feature transforms. Lastly, we characterize the class of models obtained by performing dropout on Gaussian processes.
Clustering with a Reject Option: Interactive Clustering as Bayesian Prior Elicitation
Jun 19, 2016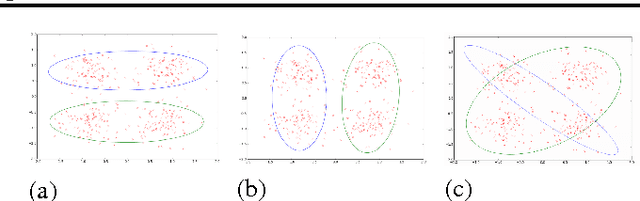
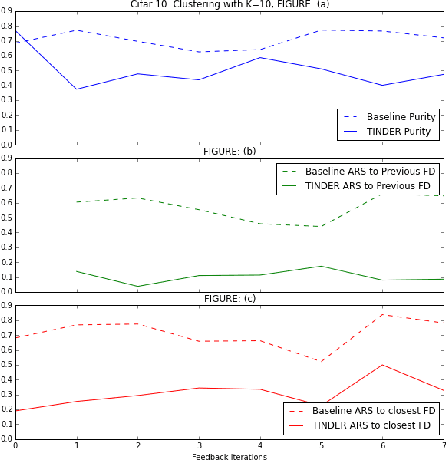

A good clustering can help a data analyst to explore and understand a data set, but what constitutes a good clustering may depend on domain-specific and application-specific criteria. These criteria can be difficult to formalize, even when it is easy for an analyst to know a good clustering when they see one. We present a new approach to interactive clustering for data exploration called TINDER, based on a particularly simple feedback mechanism, in which an analyst can reject a given clustering and request a new one, which is chosen to be different from the previous clustering while fitting the data well. We formalize this interaction in a Bayesian framework as a method for prior elicitation, in which each different clustering is produced by a prior distribution that is modified to discourage previously rejected clusterings. We show that TINDER successfully produces a diverse set of clusterings, each of equivalent quality, that are much more diverse than would be obtained by randomized restarts.