 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA surprisal--duration trade-off across and within the world's languages
Sep 30, 2021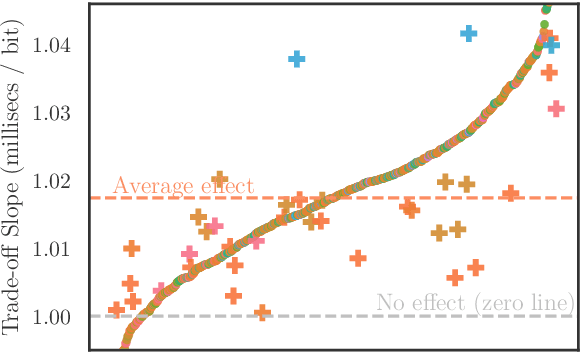
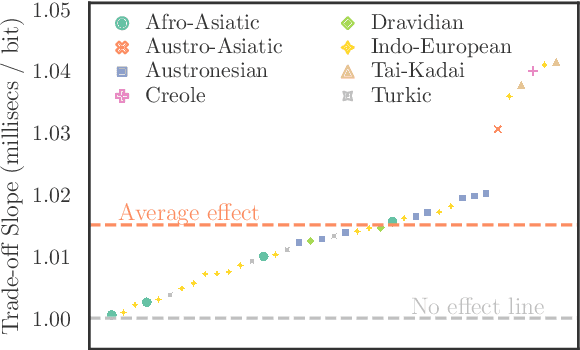
While there exist scores of natural languages, each with its unique features and idiosyncrasies, they all share a unifying theme: enabling human communication. We may thus reasonably predict that human cognition shapes how these languages evolve and are used. Assuming that the capacity to process information is roughly constant across human populations, we expect a surprisal--duration trade-off to arise both across and within languages. We analyse this trade-off using a corpus of 600 languages and, after controlling for several potential confounds, we find strong supporting evidence in both settings. Specifically, we find that, on average, phones are produced faster in languages where they are less surprising, and vice versa. Further, we confirm that more surprising phones are longer, on average, in 319 languages out of the 600. We thus conclude that there is strong evidence of a surprisal--duration trade-off in operation, both across and within the world's languages.
On Homophony and Rényi Entropy
Sep 28, 2021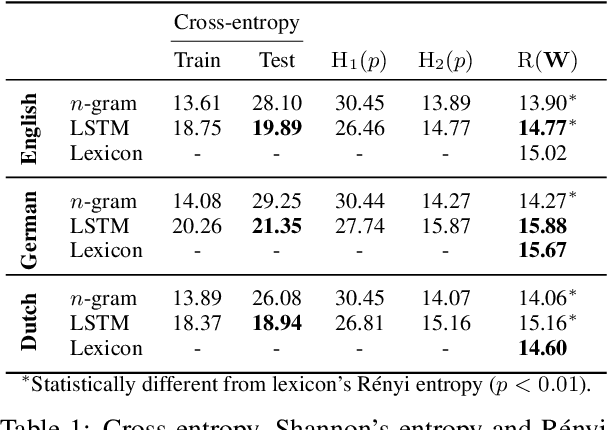
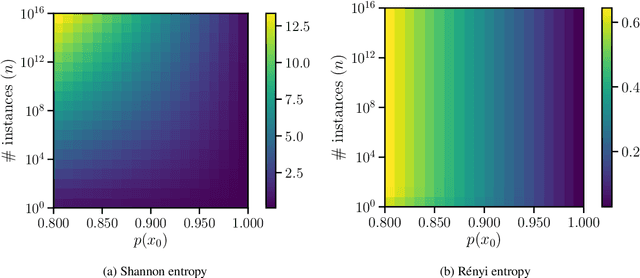
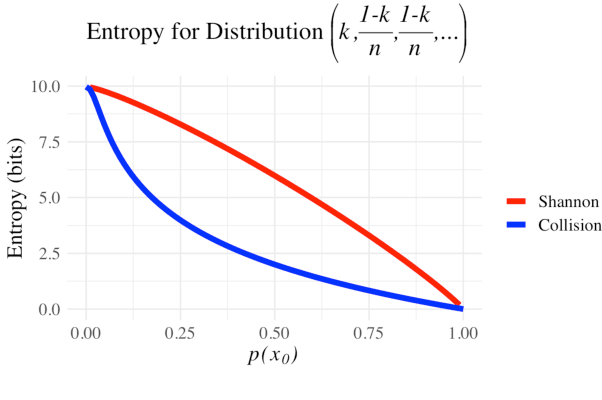
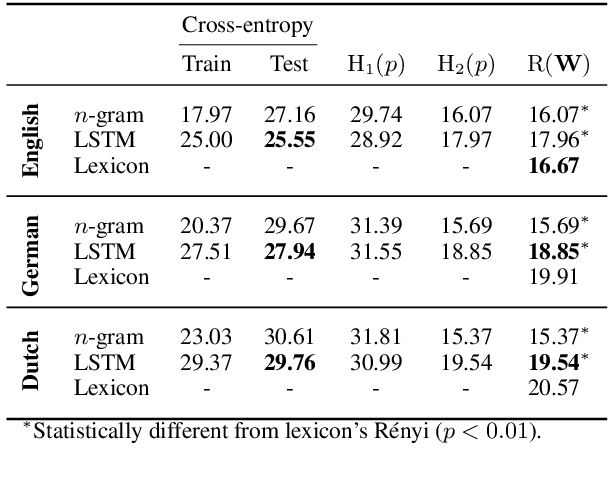
Homophony's widespread presence in natural languages is a controversial topic. Recent theories of language optimality have tried to justify its prevalence, despite its negative effects on cognitive processing time; e.g., Piantadosi et al. (2012) argued homophony enables the reuse of efficient wordforms and is thus beneficial for languages. This hypothesis has recently been challenged by Trott and Bergen (2020), who posit that good wordforms are more often homophonous simply because they are more phonotactically probable. In this paper, we join in on the debate. We first propose a new information-theoretic quantification of a language's homophony: the sample R\'enyi entropy. Then, we use this quantification to revisit Trott and Bergen's claims. While their point is theoretically sound, a specific methodological issue in their experiments raises doubts about their results. After addressing this issue, we find no clear pressure either towards or against homophony -- a much more nuanced result than either Piantadosi et al.'s or Trott and Bergen's findings.
Classifying Dyads for Militarized Conflict Analysis
Sep 27, 2021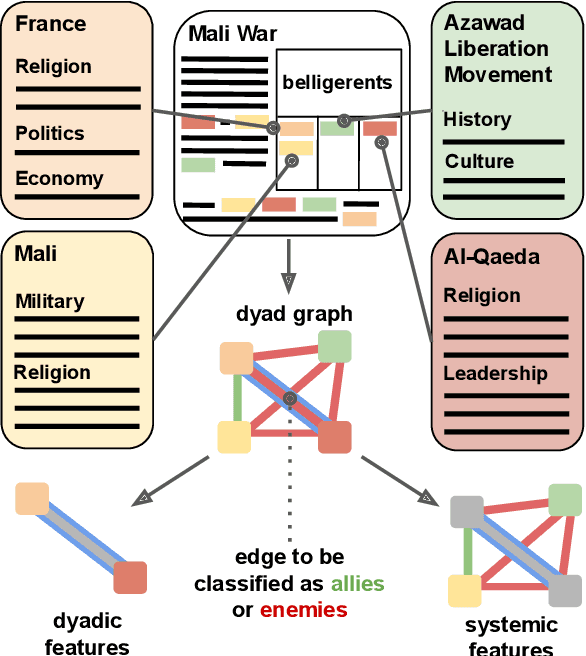
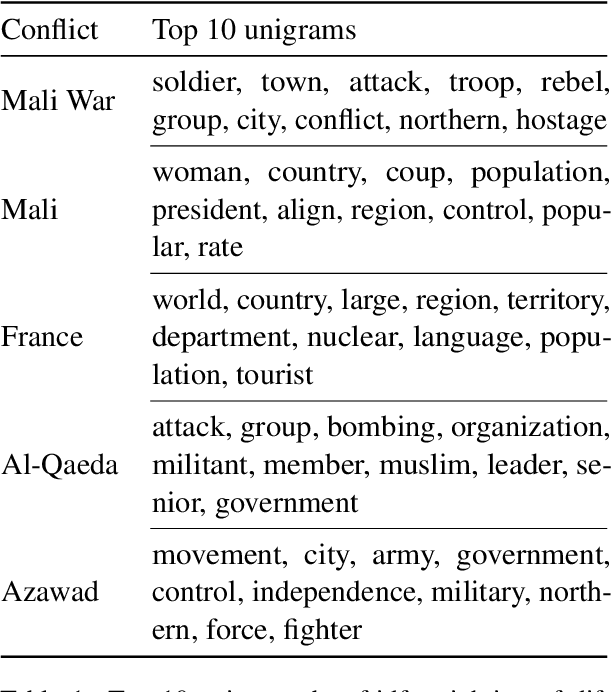
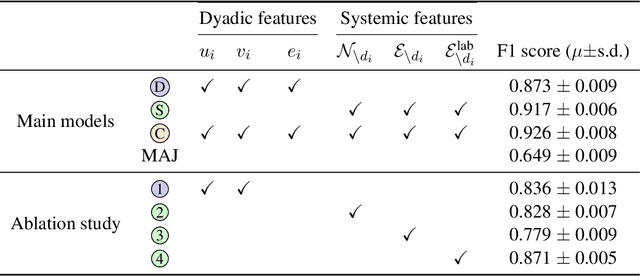

Understanding the origins of militarized conflict is a complex, yet important undertaking. Existing research seeks to build this understanding by considering bi-lateral relationships between entity pairs (dyadic causes) and multi-lateral relationships among multiple entities (systemic causes). The aim of this work is to compare these two causes in terms of how they correlate with conflict between two entities. We do this by devising a set of textual and graph-based features which represent each of the causes. The features are extracted from Wikipedia and modeled as a large graph. Nodes in this graph represent entities connected by labeled edges representing ally or enemy-relationships. This allows casting the problem as an edge classification task, which we term dyad classification. We propose and evaluate classifiers to determine if a particular pair of entities are allies or enemies. Our results suggest that our systemic features might be slightly better correlates of conflict. Further, we find that Wikipedia articles of allies are semantically more similar than enemies.
Revisiting the Uniform Information Density Hypothesis
Sep 23, 2021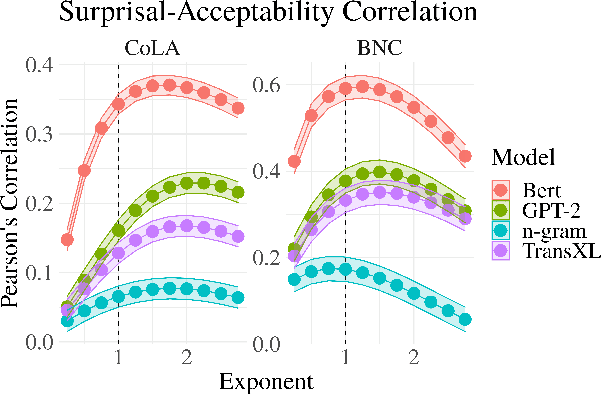
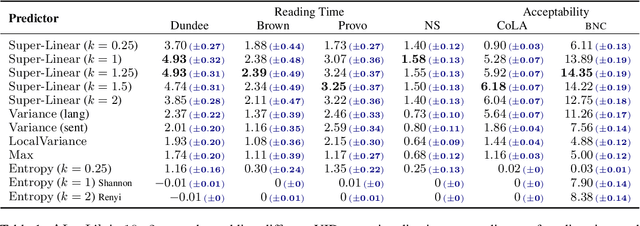
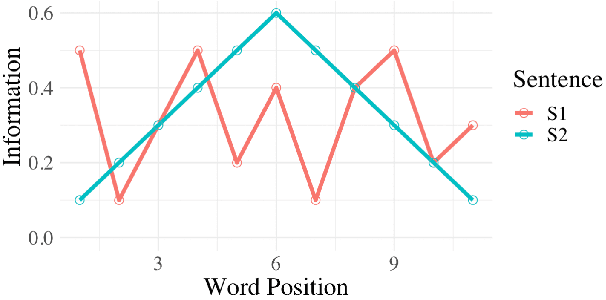
The uniform information density (UID) hypothesis posits a preference among language users for utterances structured such that information is distributed uniformly across a signal. While its implications on language production have been well explored, the hypothesis potentially makes predictions about language comprehension and linguistic acceptability as well. Further, it is unclear how uniformity in a linguistic signal -- or lack thereof -- should be measured, and over which linguistic unit, e.g., the sentence or language level, this uniformity should hold. Here we investigate these facets of the UID hypothesis using reading time and acceptability data. While our reading time results are generally consistent with previous work, they are also consistent with a weakly super-linear effect of surprisal, which would be compatible with UID's predictions. For acceptability judgments, we find clearer evidence that non-uniformity in information density is predictive of lower acceptability. We then explore multiple operationalizations of UID, motivated by different interpretations of the original hypothesis, and analyze the scope over which the pressure towards uniformity is exerted. The explanatory power of a subset of the proposed operationalizations suggests that the strongest trend may be a regression towards a mean surprisal across the language, rather than the phrase, sentence, or document -- a finding that supports a typical interpretation of UID, namely that it is the byproduct of language users maximizing the use of a (hypothetical) communication channel.
Conditional Poisson Stochastic Beam Search
Sep 22, 2021Beam search is the default decoding strategy for many sequence generation tasks in NLP. The set of approximate K-best items returned by the algorithm is a useful summary of the distribution for many applications; however, the candidates typically exhibit high overlap and may give a highly biased estimate for expectations under our model. These problems can be addressed by instead using stochastic decoding strategies. In this work, we propose a new method for turning beam search into a stochastic process: Conditional Poisson stochastic beam search. Rather than taking the maximizing set at each iteration, we sample K candidates without replacement according to the conditional Poisson sampling design. We view this as a more natural alternative to Kool et. al. 2019's stochastic beam search (SBS). Furthermore, we show how samples generated under the CPSBS design can be used to build consistent estimators and sample diverse sets from sequence models. In our experiments, we observe CPSBS produces lower variance and more efficient estimators than SBS, even showing improvements in high entropy settings.
A Plug-and-Play Method for Controlled Text Generation
Sep 20, 2021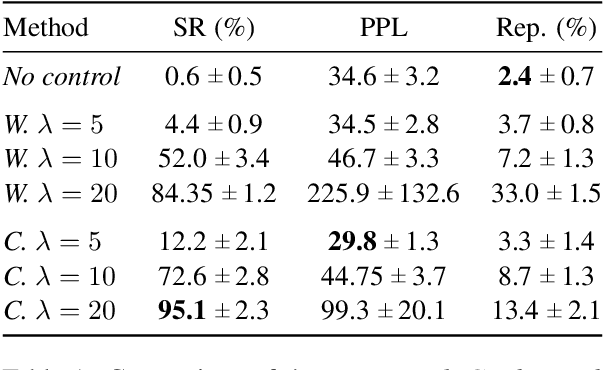
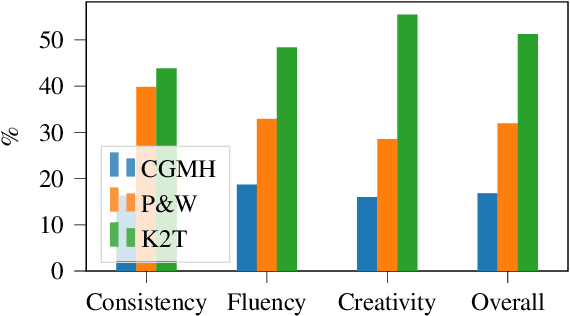
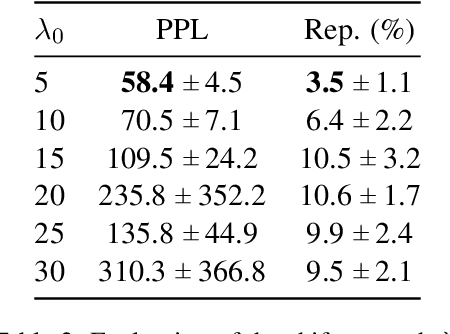
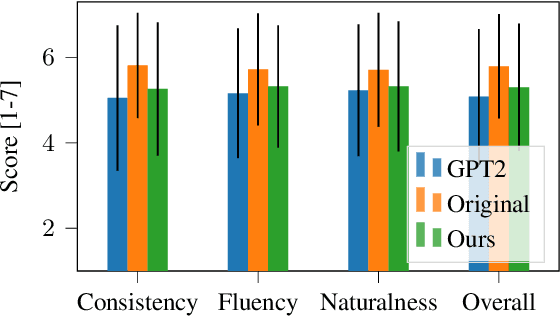
Large pre-trained language models have repeatedly shown their ability to produce fluent text. Yet even when starting from a prompt, generation can continue in many plausible directions. Current decoding methods with the goal of controlling generation, e.g., to ensure specific words are included, either require additional models or fine-tuning, or work poorly when the task at hand is semantically unconstrained, e.g., story generation. In this work, we present a plug-and-play decoding method for controlled language generation that is so simple and intuitive, it can be described in a single sentence: given a topic or keyword, we add a shift to the probability distribution over our vocabulary towards semantically similar words. We show how annealing this distribution can be used to impose hard constraints on language generation, something no other plug-and-play method is currently able to do with SOTA language generators. Despite the simplicity of this approach, we see it works incredibly well in practice: decoding from GPT-2 leads to diverse and fluent sentences while guaranteeing the appearance of given guide words. We perform two user studies, revealing that (1) our method outperforms competing methods in human evaluations; and (2) forcing the guide words to appear in the generated text has no impact on the fluency of the generated text.
Searching for More Efficient Dynamic Programs
Sep 14, 2021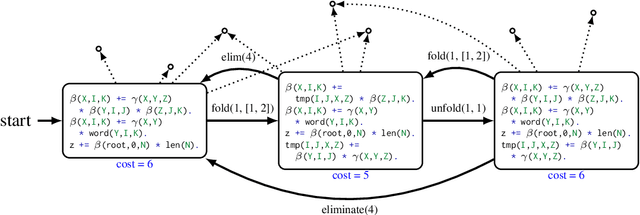
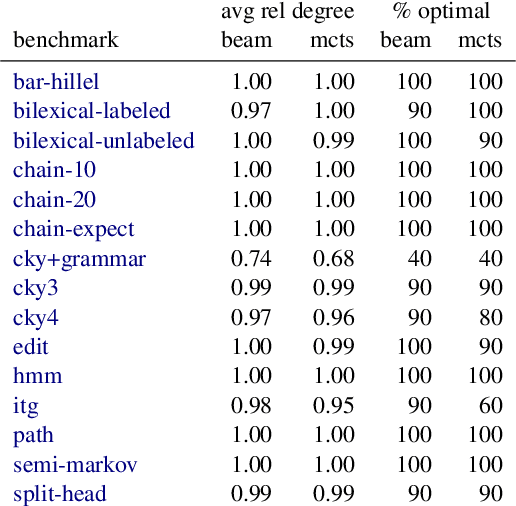

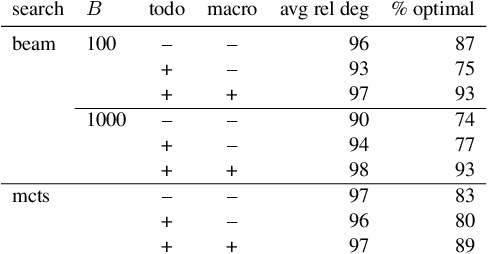
Computational models of human language often involve combinatorial problems. For instance, a probabilistic parser may marginalize over exponentially many trees to make predictions. Algorithms for such problems often employ dynamic programming and are not always unique. Finding one with optimal asymptotic runtime can be unintuitive, time-consuming, and error-prone. Our work aims to automate this laborious process. Given an initial correct declarative program, we search for a sequence of semantics-preserving transformations to improve its running time as much as possible. To this end, we describe a set of program transformations, a simple metric for assessing the efficiency of a transformed program, and a heuristic search procedure to improve this metric. We show that in practice, automated search -- like the mental search performed by human programmers -- can find substantial improvements to the initial program. Empirically, we show that many common speed-ups described in the NLP literature could have been discovered automatically by our system.
Efficient Sampling of Dependency Structures
Sep 14, 2021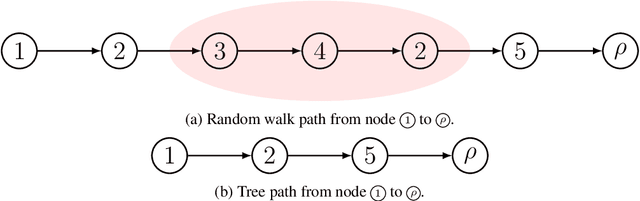



Probabilistic distributions over spanning trees in directed graphs are a fundamental model of dependency structure in natural language processing, syntactic dependency trees. In NLP, dependency trees often have an additional root constraint: only one edge may emanate from the root. However, no sampling algorithm has been presented in the literature to account for this additional constraint. In this paper, we adapt two spanning tree sampling algorithms to faithfully sample dependency trees from a graph subject to the root constraint. Wilson (1996)'s sampling algorithm has a running time of $\mathcal{O}(H)$ where $H$ is the mean hitting time of the graph. Colbourn (1996)'s sampling algorithm has a running time of $\mathcal{O}(N^3)$, which is often greater than the mean hitting time of a directed graph. Additionally, we build upon Colbourn's algorithm and present a novel extension that can sample $K$ trees without replacement in $\mathcal{O}(K N^3 + K^2 N)$ time. To the best of our knowledge, no algorithm has been given for sampling spanning trees without replacement from a directed graph.
A Bayesian Framework for Information-Theoretic Probing
Sep 08, 2021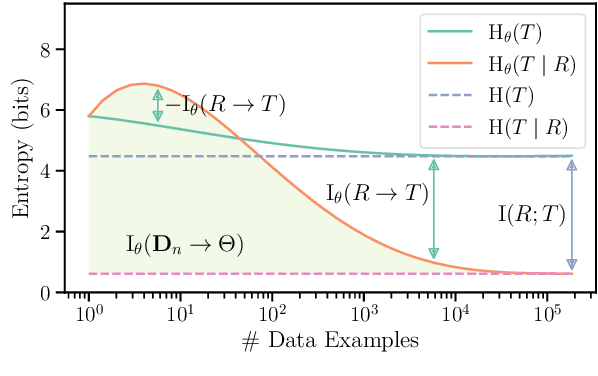
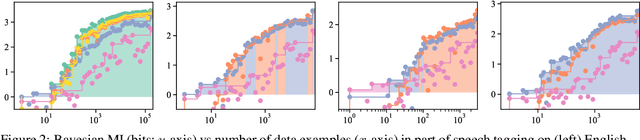
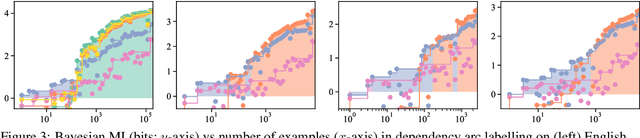
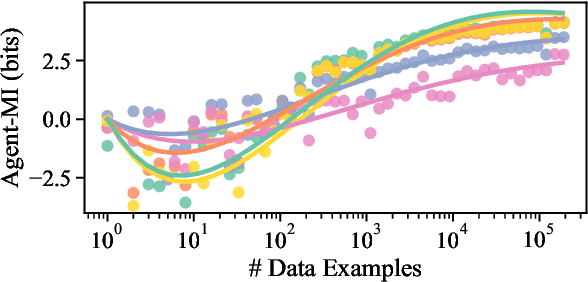
Pimentel et al. (2020) recently analysed probing from an information-theoretic perspective. They argue that probing should be seen as approximating a mutual information. This led to the rather unintuitive conclusion that representations encode exactly the same information about a target task as the original sentences. The mutual information, however, assumes the true probability distribution of a pair of random variables is known, leading to unintuitive results in settings where it is not. This paper proposes a new framework to measure what we term Bayesian mutual information, which analyses information from the perspective of Bayesian agents -- allowing for more intuitive findings in scenarios with finite data. For instance, under Bayesian MI we have that data can add information, processing can help, and information can hurt, which makes it more intuitive for machine learning applications. Finally, we apply our framework to probing where we believe Bayesian mutual information naturally operationalises ease of extraction by explicitly limiting the available background knowledge to solve a task.
Differentiable Subset Pruning of Transformer Heads
Aug 22, 2021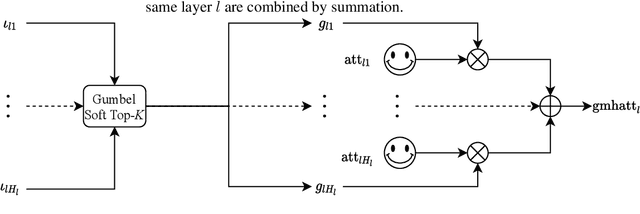
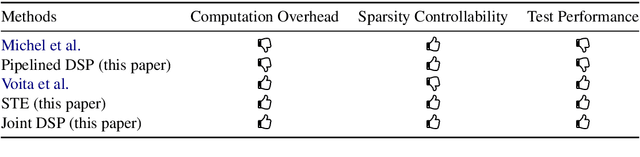
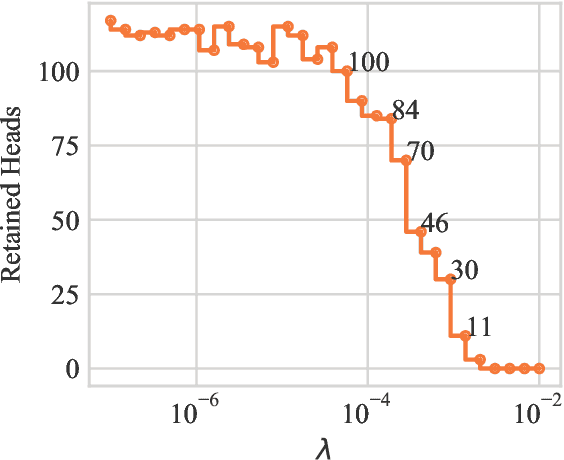
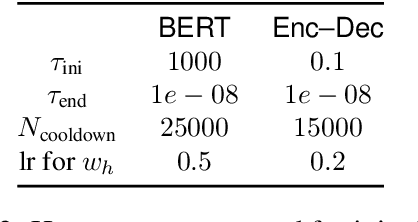
Multi-head attention, a collection of several attention mechanisms that independently attend to different parts of the input, is the key ingredient in the Transformer. Recent work has shown, however, that a large proportion of the heads in a Transformer's multi-head attention mechanism can be safely pruned away without significantly harming the performance of the model; such pruning leads to models that are noticeably smaller and faster in practice. Our work introduces a new head pruning technique that we term differentiable subset pruning. Intuitively, our method learns per-head importance variables and then enforces a user-specified hard constraint on the number of unpruned heads. The importance variables are learned via stochastic gradient descent. We conduct experiments on natural language inference and machine translation; we show that differentiable subset pruning performs comparably or better than previous works while offering precise control of the sparsity level.