 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural-Logarithm-Rectified Activation Function in Convolutional Neural Networks
Aug 25, 2019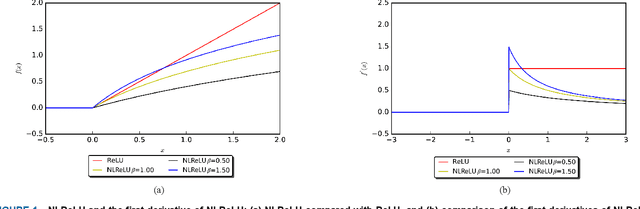
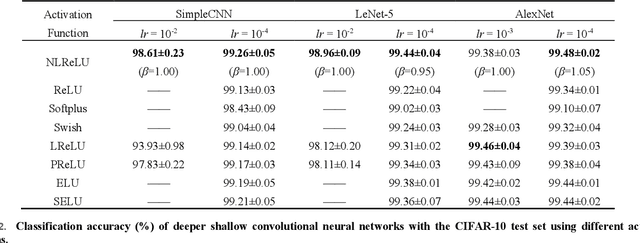
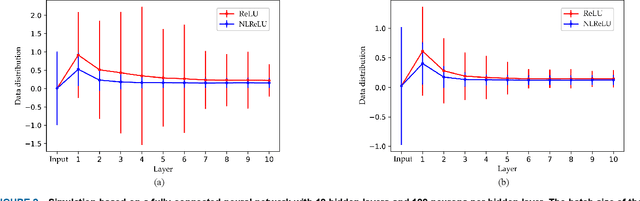
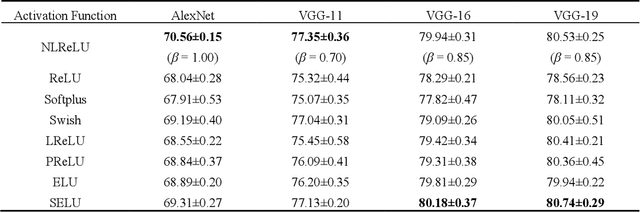
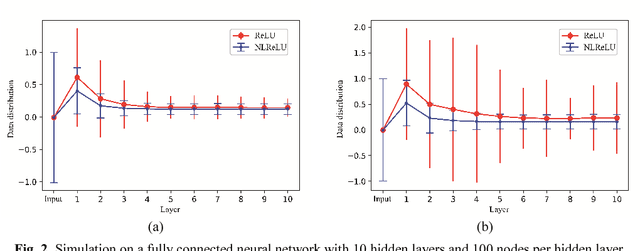
Activation functions play a key role in providing remarkable performance in deep neural networks, and the rectified linear unit (ReLU) is one of the most widely used activation functions. Various new activation functions and improvements on ReLU have been proposed, but each carry performance drawbacks. In this paper, we propose an improved activation function, which we name the natural-logarithm-rectified linear unit (NLReLU). This activation function uses the parametric natural logarithmic transform to improve ReLU and is simply defined as. NLReLU not only retains the sparse activation characteristic of ReLU, but it also alleviates the "dying ReLU" and vanishing gradient problems to some extent. It also reduces the bias shift effect and heteroscedasticity of neuron data distributions among network layers in order to accelerate the learning process. The proposed method was verified across ten convolutional neural networks with different depths for two essential datasets. Experiments illustrate that convolutional neural networks with NLReLU exhibit higher accuracy than those with ReLU, and that NLReLU is comparable to other well-known activation functions. NLReLU provides 0.16% and 2.04% higher classification accuracy on average compared to ReLU when used in shallow convolutional neural networks with the MNIST and CIFAR-10 datasets, respectively. The average accuracy of deep convolutional neural networks with NLReLU is 1.35% higher on average with the CIFAR-10 dataset.
A Sensitivity Analysis of Attention-Gated Convolutional Neural Networks for Sentence Classification
Aug 25, 2019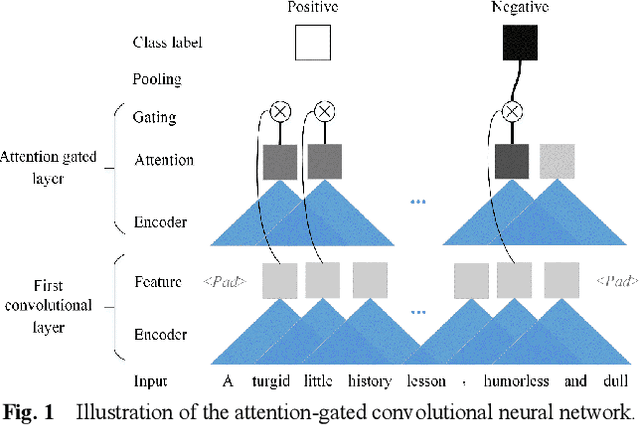
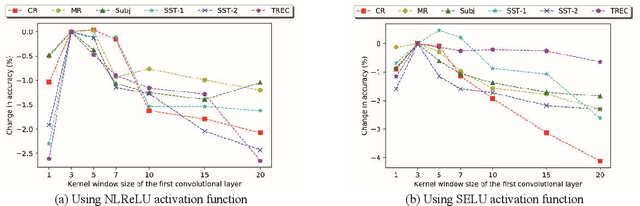

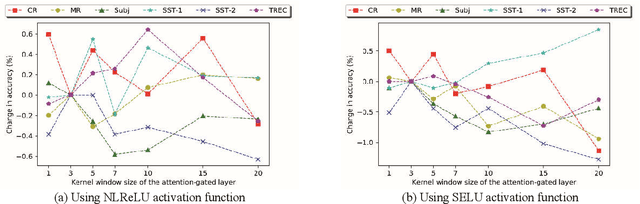
Recently, Attention-Gated Convolutional Neural Networks (AGCNNs) perform well on several essential sentence classification tasks and show robust performance in practical applications. However, AGCNNs are required to set many hyperparameters, and it is not known how sensitive the model's performance changes with them. In this paper, we conduct a sensitivity analysis on the effect of different hyperparameters s of AGCNNs, e.g., the kernel window size and the number of feature maps. Also, we investigate the effect of different combinations of hyperparameters settings on the model's performance to analyze to what extent different parameters settings contribute to AGCNNs' performance. Meanwhile, we draw practical advice from a wide range of empirical results. Through the sensitivity analysis experiment, we improve the hyperparameters settings of AGCNNs. Experiments show that our proposals achieve an average of 0.81% and 0.67% improvements on AGCNN-NLReLU-rand and AGCNN-SELU-rand, respectively; and an average of 0.47% and 0.45% improvements on AGCNN-NLReLU-static and AGCNN-SELU-static, respectively.
An Attention-Gated Convolutional Neural Network for Sentence Classification
Aug 28, 2018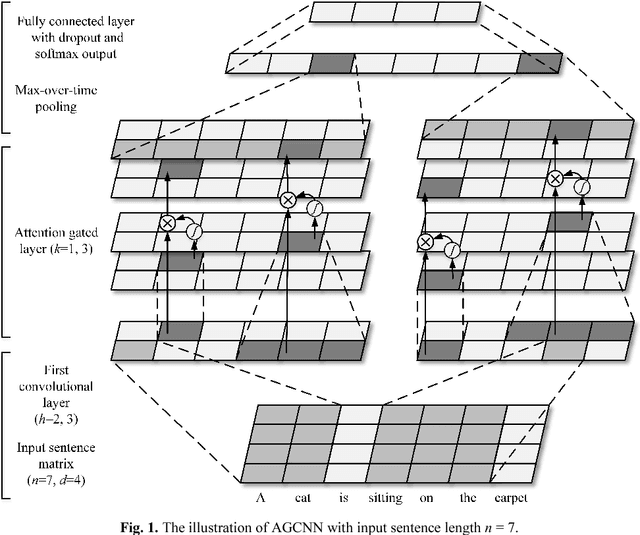
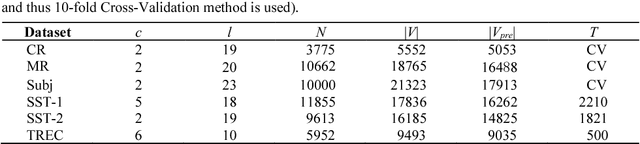

The classification task of sentences is very challenging because of the limited contextual information that sentences contain. In this paper, we propose an Attention Gated Convolutional Neural Network (AGCNN) for sentence classification, which generates attention weights from the feature's context windows of different sizes by using specialized convolution encoders, to enhance the influence of critical features in predicting the sentence's category. Experimental results demonstrate that our model could achieve a general accuracy improvement highest up to 3.1% (compared with standard CNN models), and gain competitive results over the strong baseline methods on four out of the six tasks. Besides, we propose an activation function named Natural Logarithm rescaled Rectified Linear Unit (NLReLU). Experimental results show that NLReLU could outperform ReLU and performs comparably to other well-known activation functions on AGCNN.