 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Noise-Adding Mechanism in Additive Differential Privacy
Sep 26, 2018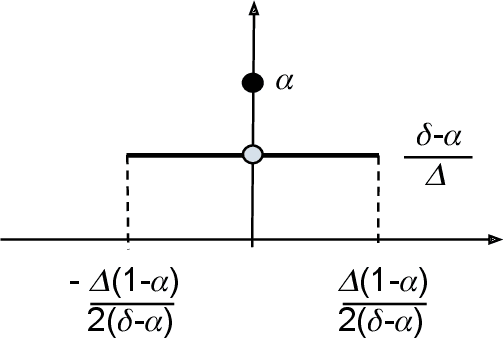

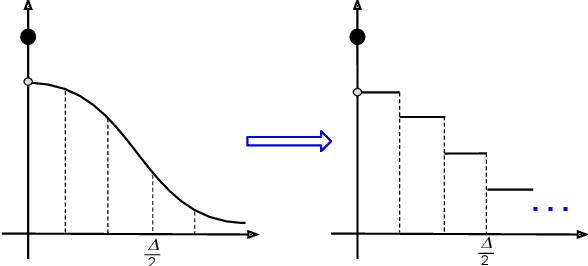
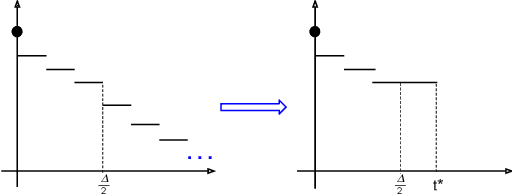
We derive the optimal $(0, \delta)$-differentially private query-output independent noise-adding mechanism for single real-valued query function under a general cost-minimization framework. Under a mild technical condition, we show that the optimal noise probability distribution is a uniform distribution with a probability mass at the origin. We explicitly derive the optimal noise distribution for general $\ell^n$ cost functions, including $\ell^1$ (for noise magnitude) and $\ell^2$ (for noise power) cost functions, and show that the probability concentration on the origin occurs when $\delta > \frac{n}{n+1}$. Our result demonstrates an improvement over the existing Gaussian mechanisms by a factor of two and three for $(0,\delta)$-differential privacy in the high privacy regime in the context of minimizing the noise magnitude and noise power, and the gain is more pronounced in the low privacy regime. Our result is consistent with the existing result for $(0,\delta)$-differential privacy in the discrete setting, and identifies a probability concentration phenomenon in the continuous setting.
Now Playing: Continuous low-power music recognition
Nov 29, 2017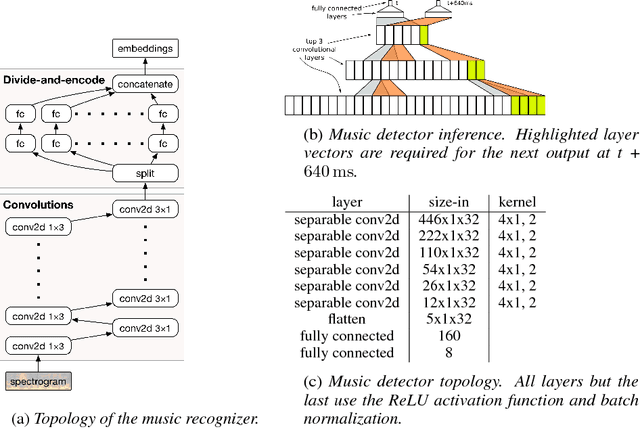
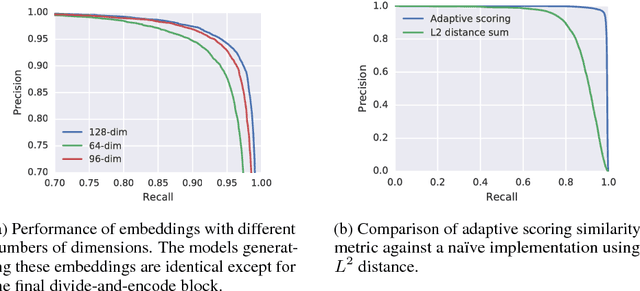
Existing music recognition applications require a connection to a server that performs the actual recognition. In this paper we present a low-power music recognizer that runs entirely on a mobile device and automatically recognizes music without user interaction. To reduce battery consumption, a small music detector runs continuously on the mobile device's DSP chip and wakes up the main application processor only when it is confident that music is present. Once woken, the recognizer on the application processor is provided with a few seconds of audio which is fingerprinted and compared to the stored fingerprints in the on-device fingerprint database of tens of thousands of songs. Our presented system, Now Playing, has a daily battery usage of less than 1% on average, respects user privacy by running entirely on-device and can passively recognize a wide range of music.
Predicting Complete 3D Models of Indoor Scenes
Aug 18, 2017
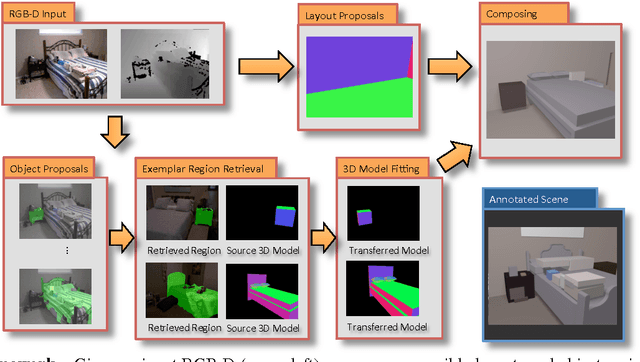


One major goal of vision is to infer physical models of objects, surfaces, and their layout from sensors. In this paper, we aim to interpret indoor scenes from one RGBD image. Our representation encodes the layout of walls, which must conform to a Manhattan structure but is otherwise flexible, and the layout and extent of objects, modeled with CAD-like 3D shapes. We represent both the visible and occluded portions of the scene, producing a complete 3D parse. Such a scene interpretation is useful for robotics and visual reasoning, but difficult to produce due to the well-known challenge of segmentation, the high degree of occlusion, and the diversity of objects in indoor scene. We take a data-driven approach, generating sets of potential object regions, matching to regions in training images, and transferring and aligning associated 3D models while encouraging fit to observations and overall consistency. We demonstrate encouraging results on the NYU v2 dataset and highlight a variety of interesting directions for future work.
Stochastic Generative Hashing
Aug 12, 2017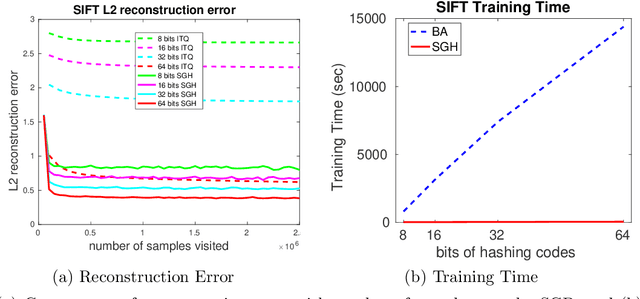
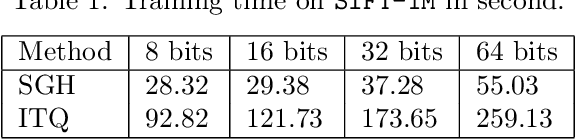
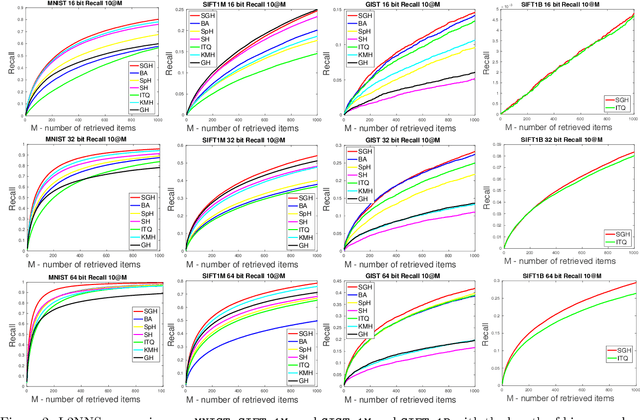

Learning-based binary hashing has become a powerful paradigm for fast search and retrieval in massive databases. However, due to the requirement of discrete outputs for the hash functions, learning such functions is known to be very challenging. In addition, the objective functions adopted by existing hashing techniques are mostly chosen heuristically. In this paper, we propose a novel generative approach to learn hash functions through Minimum Description Length principle such that the learned hash codes maximally compress the dataset and can also be used to regenerate the inputs. We also develop an efficient learning algorithm based on the stochastic distributional gradient, which avoids the notorious difficulty caused by binary output constraints, to jointly optimize the parameters of the hash function and the associated generative model. Extensive experiments on a variety of large-scale datasets show that the proposed method achieves better retrieval results than the existing state-of-the-art methods.
Efficient Natural Language Response Suggestion for Smart Reply
May 01, 2017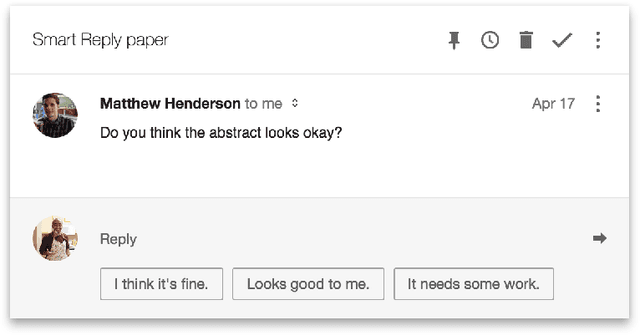

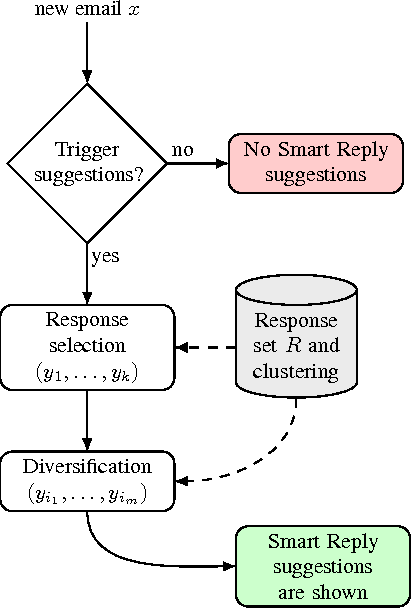
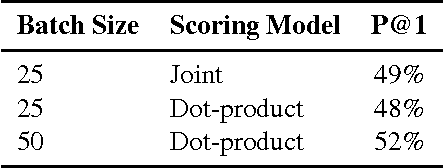
This paper presents a computationally efficient machine-learned method for natural language response suggestion. Feed-forward neural networks using n-gram embedding features encode messages into vectors which are optimized to give message-response pairs a high dot-product value. An optimized search finds response suggestions. The method is evaluated in a large-scale commercial e-mail application, Inbox by Gmail. Compared to a sequence-to-sequence approach, the new system achieves the same quality at a small fraction of the computational requirements and latency.
Quantization based Fast Inner Product Search
Sep 04, 2015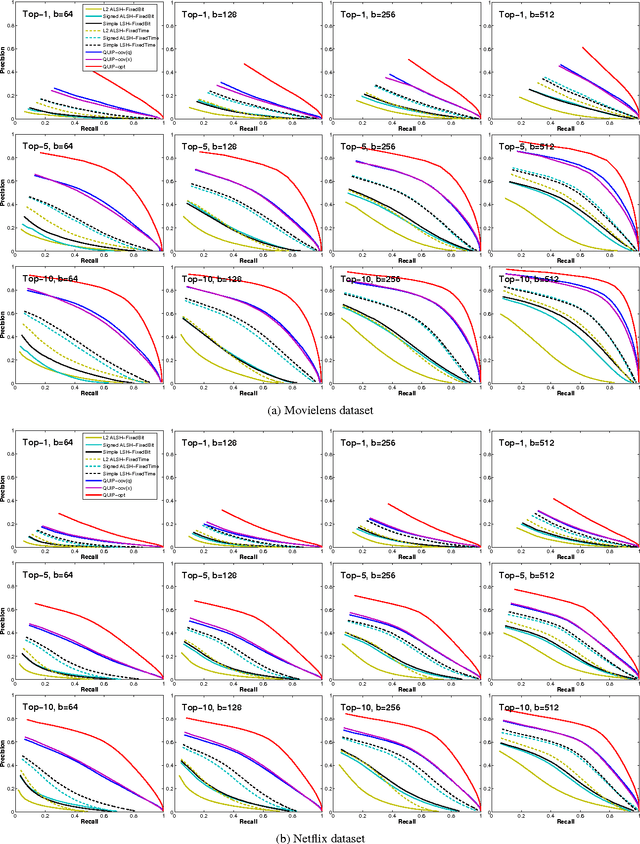
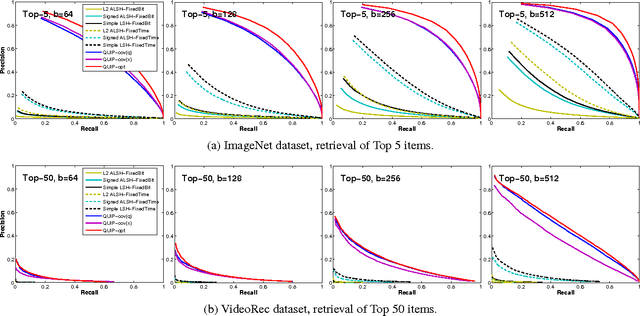
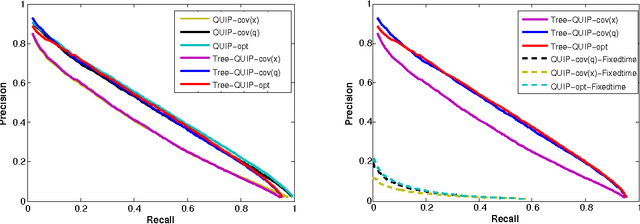
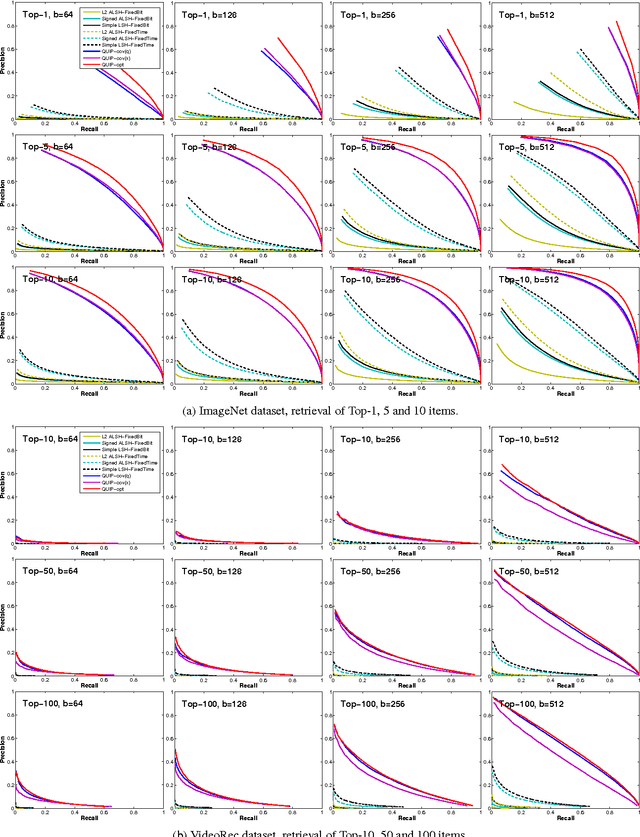
We propose a quantization based approach for fast approximate Maximum Inner Product Search (MIPS). Each database vector is quantized in multiple subspaces via a set of codebooks, learned directly by minimizing the inner product quantization error. Then, the inner product of a query to a database vector is approximated as the sum of inner products with the subspace quantizers. Different from recently proposed LSH approaches to MIPS, the database vectors and queries do not need to be augmented in a higher dimensional feature space. We also provide a theoretical analysis of the proposed approach, consisting of the concentration results under mild assumptions. Furthermore, if a small sample of example queries is given at the training time, we propose a modified codebook learning procedure which further improves the accuracy. Experimental results on a variety of datasets including those arising from deep neural networks show that the proposed approach significantly outperforms the existing state-of-the-art.
Multi-scale Orderless Pooling of Deep Convolutional Activation Features
Sep 08, 2014



Deep convolutional neural networks (CNN) have shown their promise as a universal representation for recognition. However, global CNN activations lack geometric invariance, which limits their robustness for classification and matching of highly variable scenes. To improve the invariance of CNN activations without degrading their discriminative power, this paper presents a simple but effective scheme called multi-scale orderless pooling (MOP-CNN). This scheme extracts CNN activations for local patches at multiple scale levels, performs orderless VLAD pooling of these activations at each level separately, and concatenates the result. The resulting MOP-CNN representation can be used as a generic feature for either supervised or unsupervised recognition tasks, from image classification to instance-level retrieval; it consistently outperforms global CNN activations without requiring any joint training of prediction layers for a particular target dataset. In absolute terms, it achieves state-of-the-art results on the challenging SUN397 and MIT Indoor Scenes classification datasets, and competitive results on ILSVRC2012/2013 classification and INRIA Holidays retrieval datasets.