 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping
Feb 15, 2020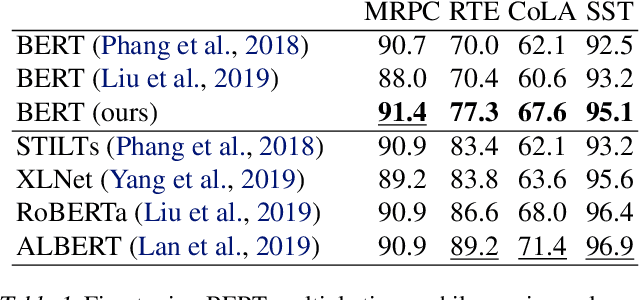
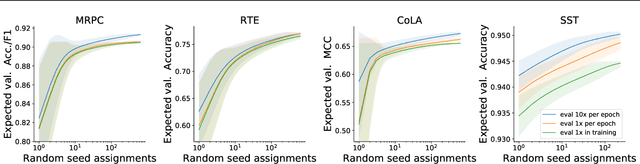
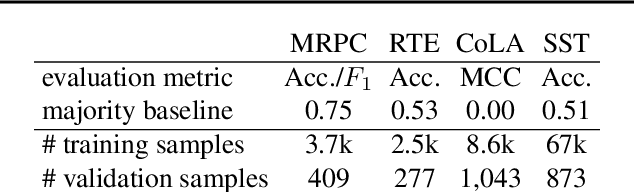
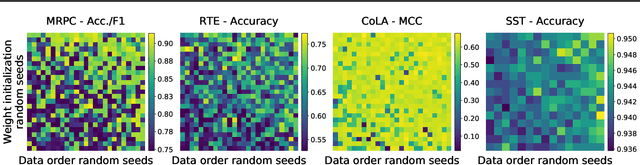
Fine-tuning pretrained contextual word embedding models to supervised downstream tasks has become commonplace in natural language processing. This process, however, is often brittle: even with the same hyperparameter values, distinct random seeds can lead to substantially different results. To better understand this phenomenon, we experiment with four datasets from the GLUE benchmark, fine-tuning BERT hundreds of times on each while varying only the random seeds. We find substantial performance increases compared to previously reported results, and we quantify how the performance of the best-found model varies as a function of the number of fine-tuning trials. Further, we examine two factors influenced by the choice of random seed: weight initialization and training data order. We find that both contribute comparably to the variance of out-of-sample performance, and that some weight initializations perform well across all tasks explored. On small datasets, we observe that many fine-tuning trials diverge part of the way through training, and we offer best practices for practitioners to stop training less promising runs early. We publicly release all of our experimental data, including training and validation scores for 2,100 trials, to encourage further analysis of training dynamics during fine-tuning.
Fair Correlation Clustering
Feb 10, 2020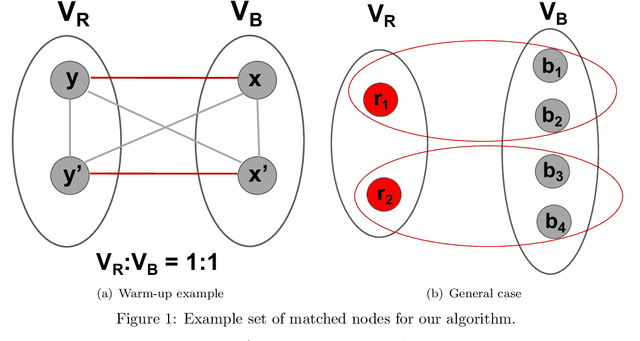


In this paper we study the problem of correlation clustering under fairness constraints. In the classic correlation clustering problem, we are given a complete graph where each edge is labeled positive or negative. The goal is to obtain a clustering of the vertices that minimizes disagreements -- the number of negative edges trapped inside a cluster plus positive edges between different clusters. We consider two variations of fairness constraint for the problem of correlation clustering where each node has a color, and the goal is to form clusters that do not over-represent vertices of any color. The first variant aims to generate clusters with minimum disagreements, where the distribution of a feature (e.g. gender) in each cluster is same as the global distribution. For the case of two colors when the desired ratio of the number of colors in each cluster is $1:p$, we get $\mathcal{O}(p^2)$-approximation algorithm. Our algorithm could be extended to the case of multiple colors. We prove this problem is NP-hard. The second variant considers relative upper and lower bounds on the number of nodes of any color in a cluster. The goal is to avoid violating upper and lower bounds corresponding to each color in each cluster while minimizing the total number of disagreements. Along with our theoretical results, we show the effectiveness of our algorithm to generate fair clusters by empirical evaluation on real world data sets.
Knowledge Enhanced Contextual Word Representations
Sep 09, 2019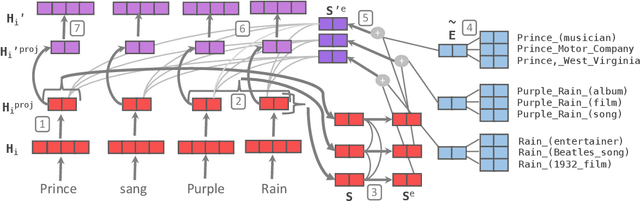
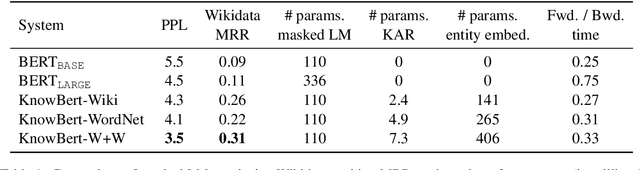
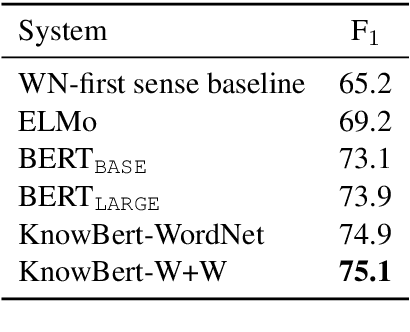
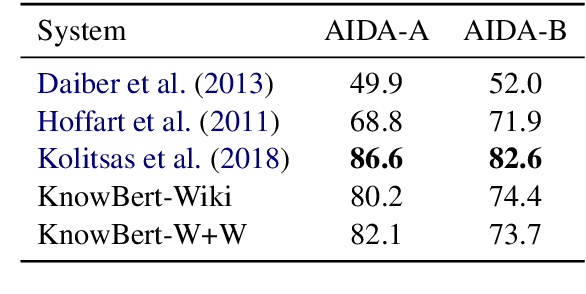
Contextual word representations, typically trained on unstructured, unlabeled text, do not contain any explicit grounding to real world entities and are often unable to remember facts about those entities. We propose a general method to embed multiple knowledge bases (KBs) into large scale models, and thereby enhance their representations with structured, human-curated knowledge. For each KB, we first use an integrated entity linker to retrieve relevant entity embeddings, then update contextual word representations via a form of word-to-entity attention. In contrast to previous approaches, the entity linkers and self-supervised language modeling objective are jointly trained end-to-end in a multitask setting that combines a small amount of entity linking supervision with a large amount of raw text. After integrating WordNet and a subset of Wikipedia into BERT, the knowledge enhanced BERT (KnowBert) demonstrates improved perplexity, ability to recall facts as measured in a probing task and downstream performance on relationship extraction, entity typing, and word sense disambiguation. KnowBert's runtime is comparable to BERT's and it scales to large KBs.
RNN Architecture Learning with Sparse Regularization
Sep 06, 2019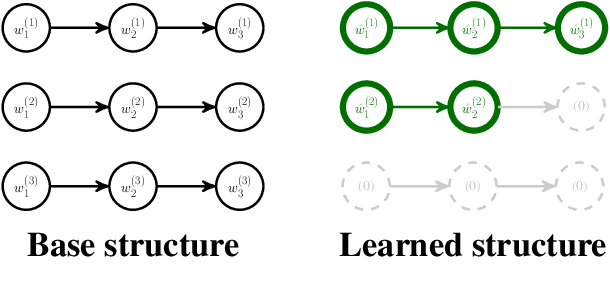
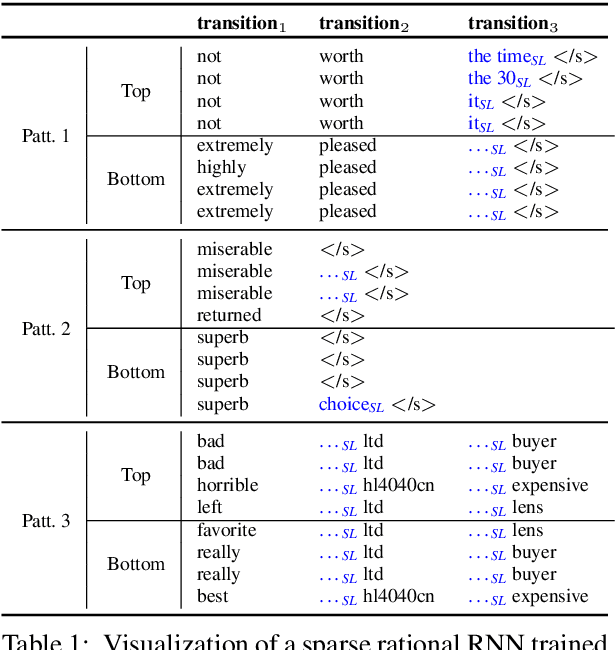
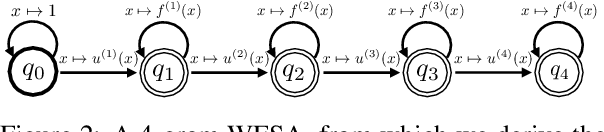
Neural models for NLP typically use large numbers of parameters to reach state-of-the-art performance, which can lead to excessive memory usage and increased runtime. We present a structure learning method for learning sparse, parameter-efficient NLP models. Our method applies group lasso to rational RNNs (Peng et al., 2018), a family of models that is closely connected to weighted finite-state automata (WFSAs). We take advantage of rational RNNs' natural grouping of the weights, so the group lasso penalty directly removes WFSA states, substantially reducing the number of parameters in the model. Our experiments on a number of sentiment analysis datasets, using both GloVe and BERT embeddings, show that our approach learns neural structures which have fewer parameters without sacrificing performance relative to parameter-rich baselines. Our method also highlights the interpretable properties of rational RNNs. We show that sparsifying such models makes them easier to visualize, and we present models that rely exclusively on as few as three WFSAs after pruning more than 90% of the weights. We publicly release our code.
Show Your Work: Improved Reporting of Experimental Results
Sep 06, 2019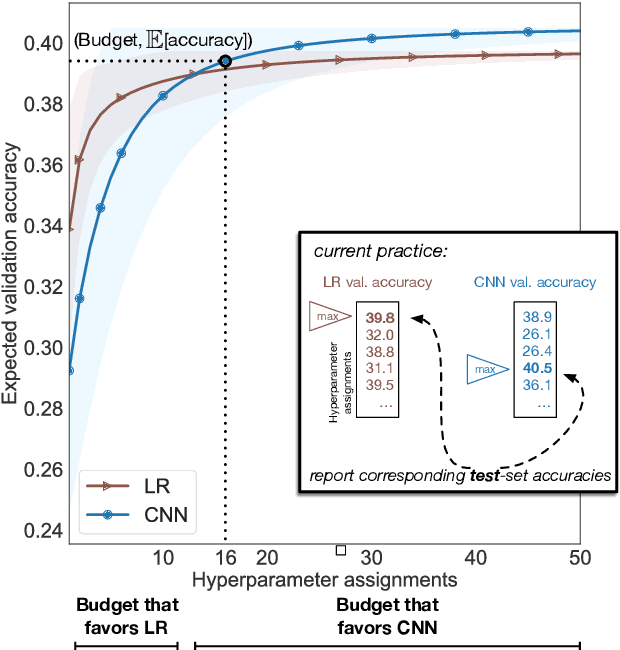
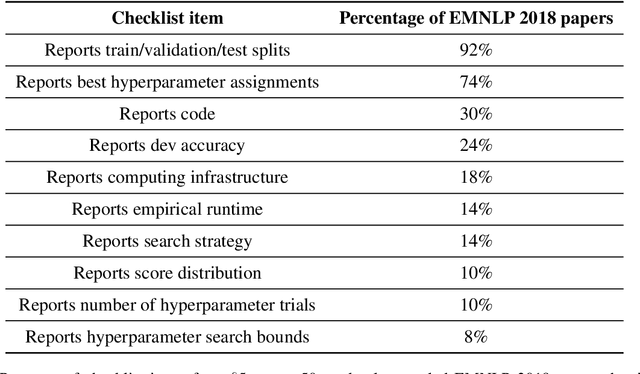
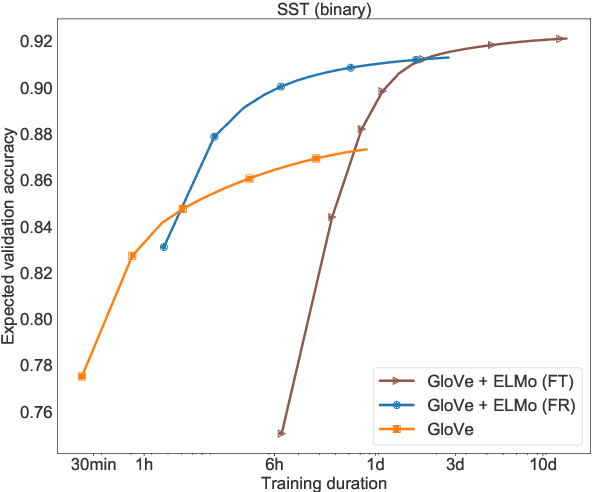
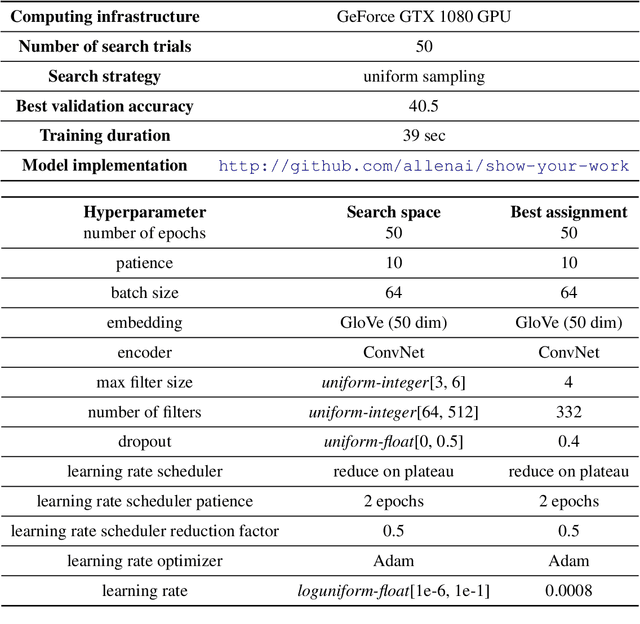
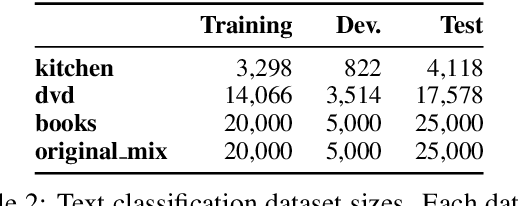
Research in natural language processing proceeds, in part, by demonstrating that new models achieve superior performance (e.g., accuracy) on held-out test data, compared to previous results. In this paper, we demonstrate that test-set performance scores alone are insufficient for drawing accurate conclusions about which model performs best. We argue for reporting additional details, especially performance on validation data obtained during model development. We present a novel technique for doing so: expected validation performance of the best-found model as a function of computation budget (i.e., the number of hyperparameter search trials or the overall training time). Using our approach, we find multiple recent model comparisons where authors would have reached a different conclusion if they had used more (or less) computation. Our approach also allows us to estimate the amount of computation required to obtain a given accuracy; applying it to several recently published results yields massive variation across papers, from hours to weeks. We conclude with a set of best practices for reporting experimental results which allow for robust future comparisons, and provide code to allow researchers to use our technique.
PaLM: A Hybrid Parser and Language Model
Sep 04, 2019
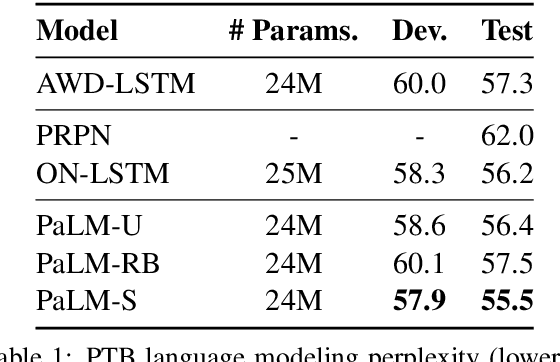
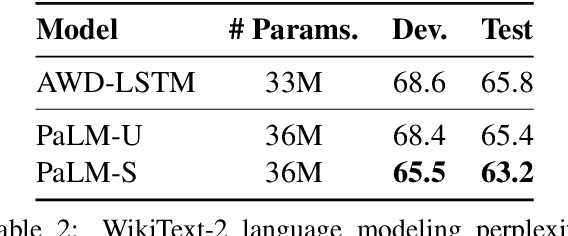
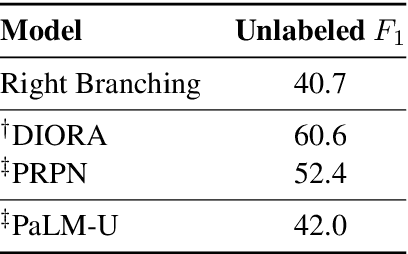
We present PaLM, a hybrid parser and neural language model. Building on an RNN language model, PaLM adds an attention layer over text spans in the left context. An unsupervised constituency parser can be derived from its attention weights, using a greedy decoding algorithm. We evaluate PaLM on language modeling, and empirically show that it outperforms strong baselines. If syntactic annotations are available, the attention component can be trained in a supervised manner, providing syntactically-informed representations of the context, and further improving language modeling performance.
Green AI
Aug 13, 2019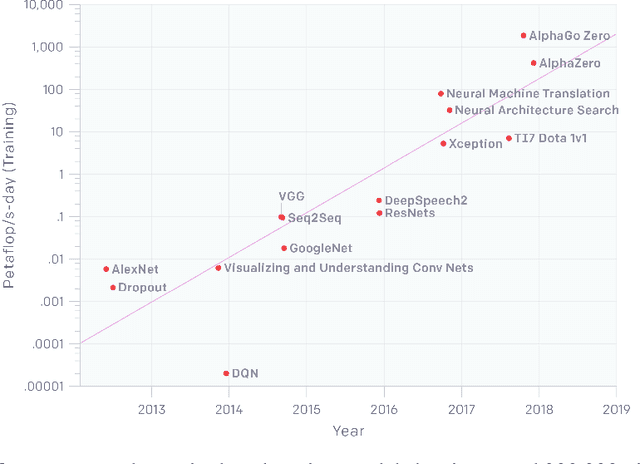
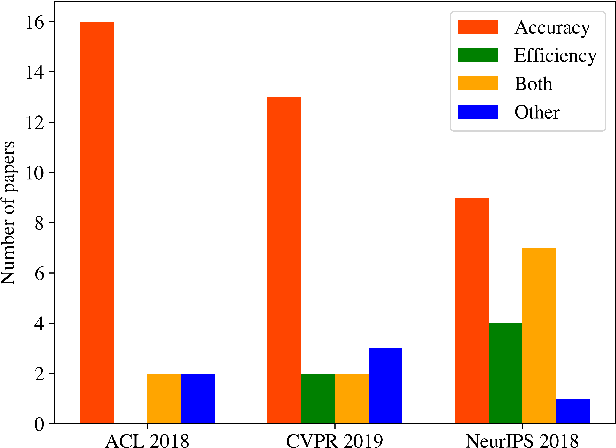
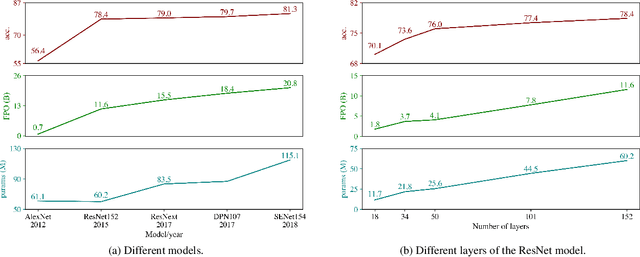
The computations required for deep learning research have been doubling every few months, resulting in an estimated 300,000x increase from 2012 to 2018 [2]. These computations have a surprisingly large carbon footprint [38]. Ironically, deep learning was inspired by the human brain, which is remarkably energy efficient. Moreover, the financial cost of the computations can make it difficult for academics, students, and researchers, in particular those from emerging economies, to engage in deep learning research. This position paper advocates a practical solution by making efficiency an evaluation criterion for research alongside accuracy and related measures. In addition, we propose reporting the financial cost or "price tag" of developing, training, and running models to provide baselines for the investigation of increasingly efficient methods. Our goal is to make AI both greener and more inclusive---enabling any inspired undergraduate with a laptop to write high-quality research papers. Green AI is an emerging focus at the Allen Institute for AI.
Inoculation by Fine-Tuning: A Method for Analyzing Challenge Datasets
Apr 26, 2019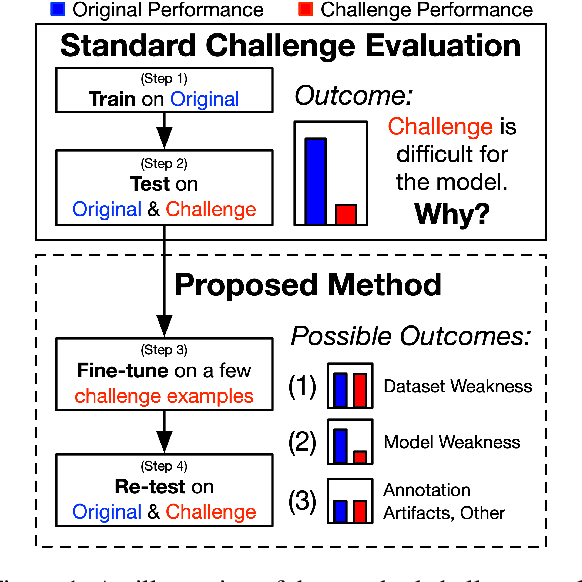

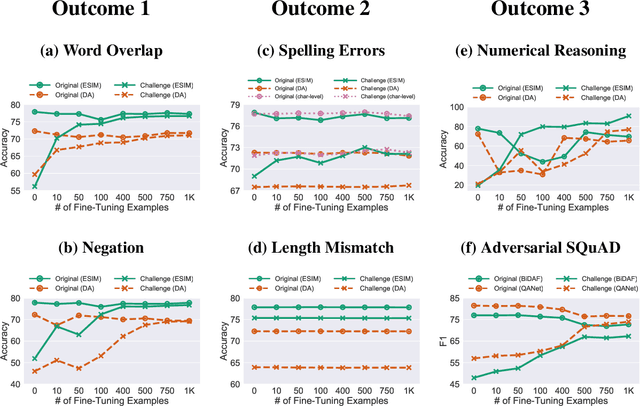
Several datasets have recently been constructed to expose brittleness in models trained on existing benchmarks. While model performance on these challenge datasets is significantly lower compared to the original benchmark, it is unclear what particular weaknesses they reveal. For example, a challenge dataset may be difficult because it targets phenomena that current models cannot capture, or because it simply exploits blind spots in a model's specific training set. We introduce inoculation by fine-tuning, a new analysis method for studying challenge datasets by exposing models (the metaphorical patient) to a small amount of data from the challenge dataset (a metaphorical pathogen) and assessing how well they can adapt. We apply our method to analyze the NLI "stress tests" (Naik et al., 2018) and the Adversarial SQuAD dataset (Jia and Liang, 2017). We show that after slight exposure, some of these datasets are no longer challenging, while others remain difficult. Our results indicate that failures on challenge datasets may lead to very different conclusions about models, training datasets, and the challenge datasets themselves.
Rational Recurrences
Aug 28, 2018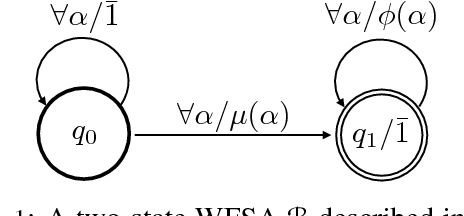

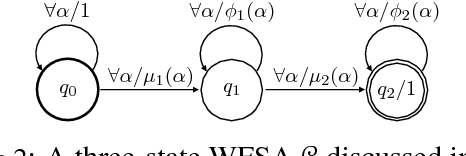

Despite the tremendous empirical success of neural models in natural language processing, many of them lack the strong intuitions that accompany classical machine learning approaches. Recently, connections have been shown between convolutional neural networks (CNNs) and weighted finite state automata (WFSAs), leading to new interpretations and insights. In this work, we show that some recurrent neural networks also share this connection to WFSAs. We characterize this connection formally, defining rational recurrences to be recurrent hidden state update functions that can be written as the Forward calculation of a finite set of WFSAs. We show that several recent neural models use rational recurrences. Our analysis provides a fresh view of these models and facilitates devising new neural architectures that draw inspiration from WFSAs. We present one such model, which performs better than two recent baselines on language modeling and text classification. Our results demonstrate that transferring intuitions from classical models like WFSAs can be an effective approach to designing and understanding neural models.
SWAG: A Large-Scale Adversarial Dataset for Grounded Commonsense Inference
Aug 16, 2018
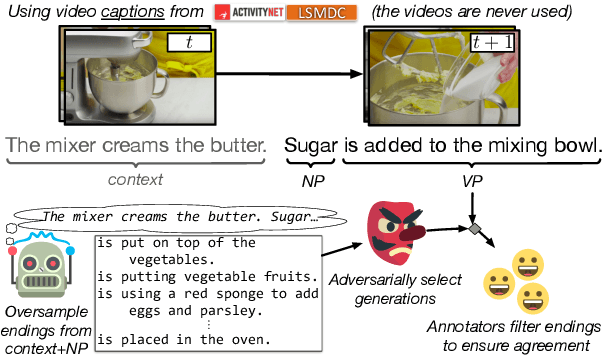
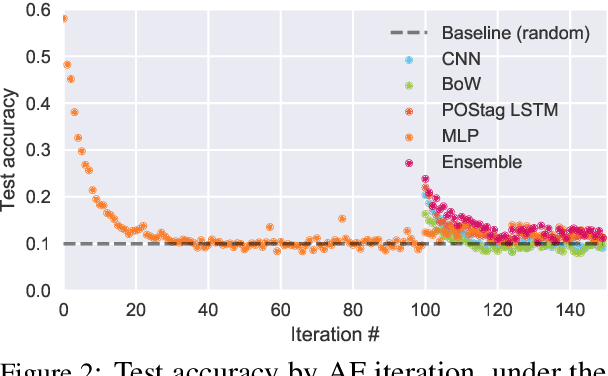
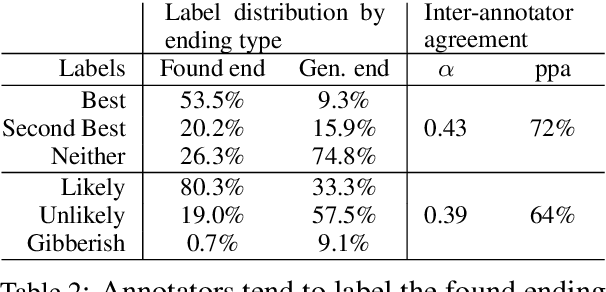
Given a partial description like "she opened the hood of the car," humans can reason about the situation and anticipate what might come next ("then, she examined the engine"). In this paper, we introduce the task of grounded commonsense inference, unifying natural language inference and commonsense reasoning. We present SWAG, a new dataset with 113k multiple choice questions about a rich spectrum of grounded situations. To address the recurring challenges of the annotation artifacts and human biases found in many existing datasets, we propose Adversarial Filtering (AF), a novel procedure that constructs a de-biased dataset by iteratively training an ensemble of stylistic classifiers, and using them to filter the data. To account for the aggressive adversarial filtering, we use state-of-the-art language models to massively oversample a diverse set of potential counterfactuals. Empirical results demonstrate that while humans can solve the resulting inference problems with high accuracy (88%), various competitive models struggle on our task. We provide comprehensive analysis that indicates significant opportunities for future research.