 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Social Welfare While Preserving Autonomy via a Pareto Mediator
Jun 07, 2021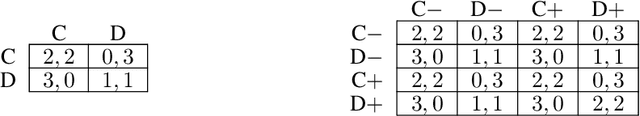
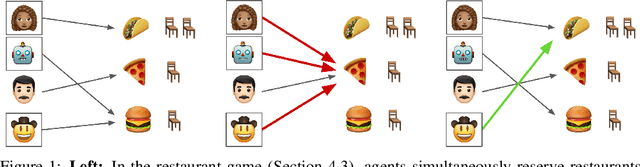
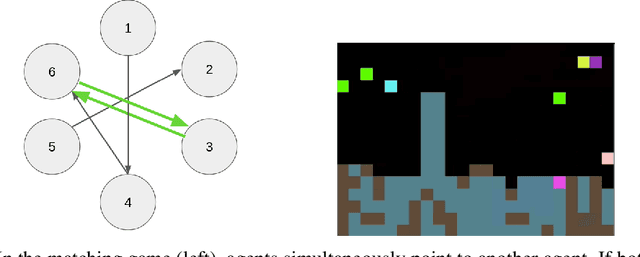

Machine learning algorithms often make decisions on behalf of agents with varied and sometimes conflicting interests. In domains where agents can choose to take their own action or delegate their action to a central mediator, an open question is how mediators should take actions on behalf of delegating agents. The main existing approach uses delegating agents to punish non-delegating agents in an attempt to get all agents to delegate, which tends to be costly for all. We introduce a Pareto Mediator which aims to improve outcomes for delegating agents without making any of them worse off. Our experiments in random normal form games, a restaurant recommendation game, and a reinforcement learning sequential social dilemma show that the Pareto Mediator greatly increases social welfare. Also, even when the Pareto Mediator is based on an incorrect model of agent utility, performance gracefully degrades to the pre-intervention level, due to the individual autonomy preserved by the voluntary mediator.
XDO: A Double Oracle Algorithm for Extensive-Form Games
Mar 11, 2021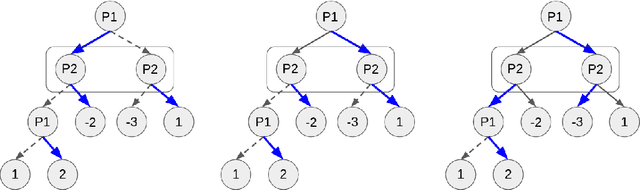
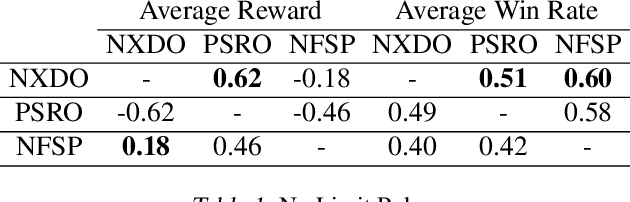

Policy Space Response Oracles (PSRO) is a deep reinforcement learning algorithm for two-player zero-sum games that has empirically found approximate Nash equilibria in large games. Although PSRO is guaranteed to converge to a Nash equilibrium, it may take an exponential number of iterations as the number of infostates grows. We propose Extensive-Form Double Oracle (XDO), an extensive-form double oracle algorithm that is guaranteed to converge to an approximate Nash equilibrium linearly in the number of infostates. Unlike PSRO, which mixes best responses at the root of the game, XDO mixes best responses at every infostate. We also introduce Neural XDO (NXDO), where the best response is learned through deep RL. In tabular experiments on Leduc poker, we find that XDO achieves an approximate Nash equilibrium in a number of iterations 1-2 orders of magnitude smaller than PSRO. In experiments on a modified Leduc poker game, we show that tabular XDO achieves over 11x lower exploitability than CFR and over 82x lower exploitability than PSRO and XFP in the same amount of time. We also show that NXDO beats PSRO and is competitive with NFSP on a large no-limit poker game.
A* Search Without Expansions: Learning Heuristic Functions with Deep Q-Networks
Feb 08, 2021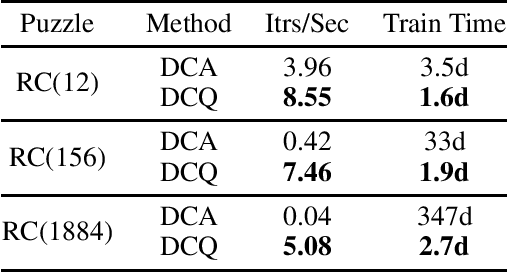
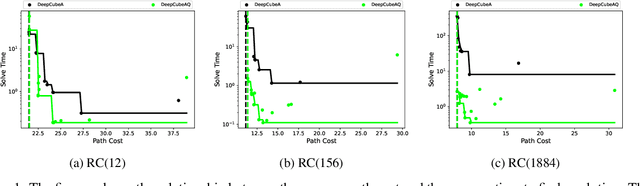
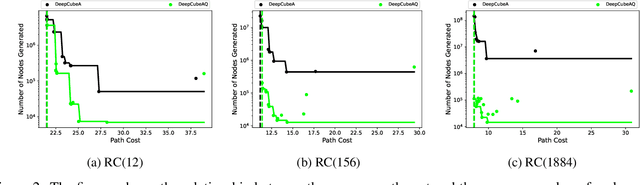

A* search is an informed search algorithm that uses a heuristic function to guide the order in which nodes are expanded. Since the computation required to expand a node and compute the heuristic values for all of its generated children grows linearly with the size of the action space, A* search can become impractical for problems with large action spaces. This computational burden becomes even more apparent when heuristic functions are learned by general, but computationally expensive, deep neural networks. To address this problem, we introduce DeepCubeAQ, a deep reinforcement learning and search algorithm that builds on the DeepCubeA algorithm and deep Q-networks. DeepCubeAQ learns a heuristic function that, with a single forward pass through a deep neural network, computes the sum of the transition cost and the heuristic value of all of the children of a node without explicitly generating any of the children, eliminating the need for node expansions. DeepCubeAQ then uses a novel variant of A* search, called AQ* search, that uses the deep Q-network to guide search. We use DeepCubeAQ to solve the Rubik's cube when formulated with a large action space that includes 1872 meta-actions and show that this 157-fold increase in the size of the action space incurs less than a 4-fold increase in computation time when performing AQ* search and that AQ* search is orders of magnitude faster than A* search.
Pipeline PSRO: A Scalable Approach for Finding Approximate Nash Equilibria in Large Games
Jun 15, 2020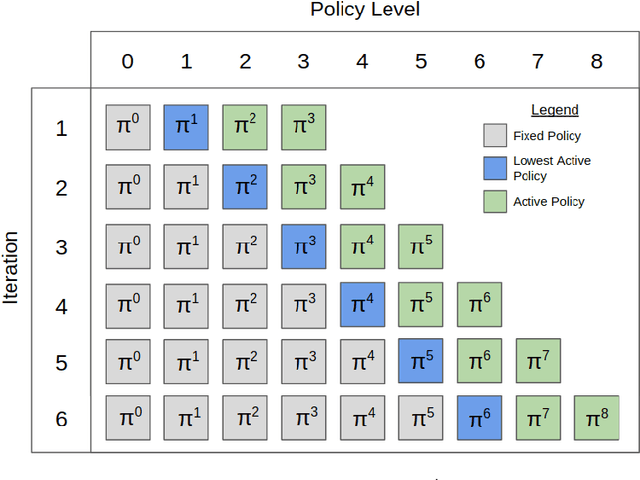
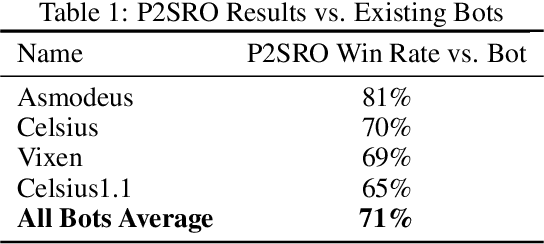
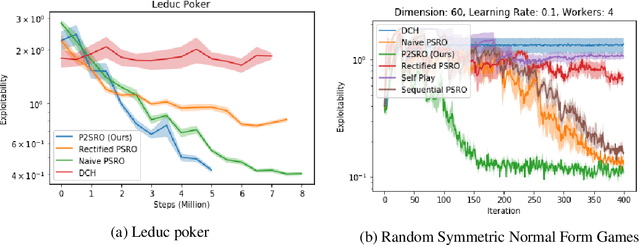
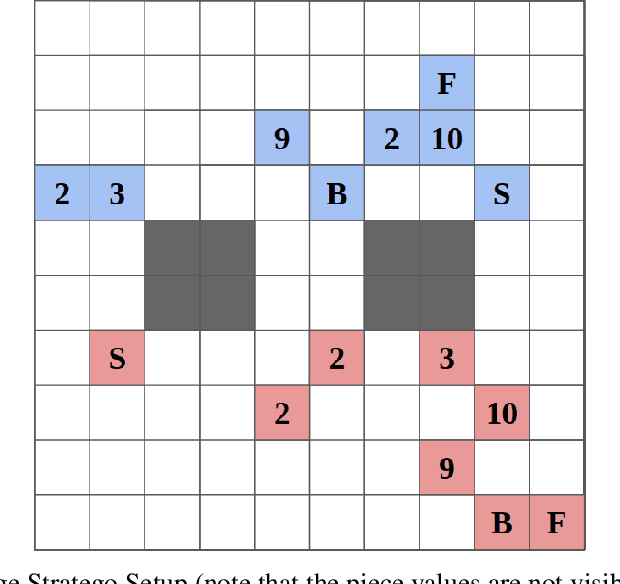
Finding approximate Nash equilibria in zero-sum imperfect-information games is challenging when the number of information states is large. Policy Space Response Oracles (PSRO) is a deep reinforcement learning algorithm grounded in game theory that is guaranteed to converge to an approximate Nash equilibrium. However, PSRO requires training a reinforcement learning policy at each iteration, making it too slow for large games. We show through counterexamples and experiments that DCH and Rectified PSRO, two existing approaches to scaling up PSRO, fail to converge even in small games. We introduce Pipeline PSRO (P2SRO), the first scalable general method for finding approximate Nash equilibria in large zero-sum imperfect-information games. P2SRO is able to parallelize PSRO with convergence guarantees by maintaining a hierarchical pipeline of reinforcement learning workers, each training against the policies generated by lower levels in the hierarchy. We show that unlike existing methods, P2SRO converges to an approximate Nash equilibrium, and does so faster as the number of parallel workers increases, across a variety of imperfect information games. We also introduce an open-source environment for Barrage Stratego, a variant of Stratego with an approximate game tree complexity of $10^{50}$. P2SRO is able to achieve state-of-the-art performance on Barrage Stratego and beats all existing bots.
Hierarchical Variational Imitation Learning of Control Programs
Dec 29, 2019
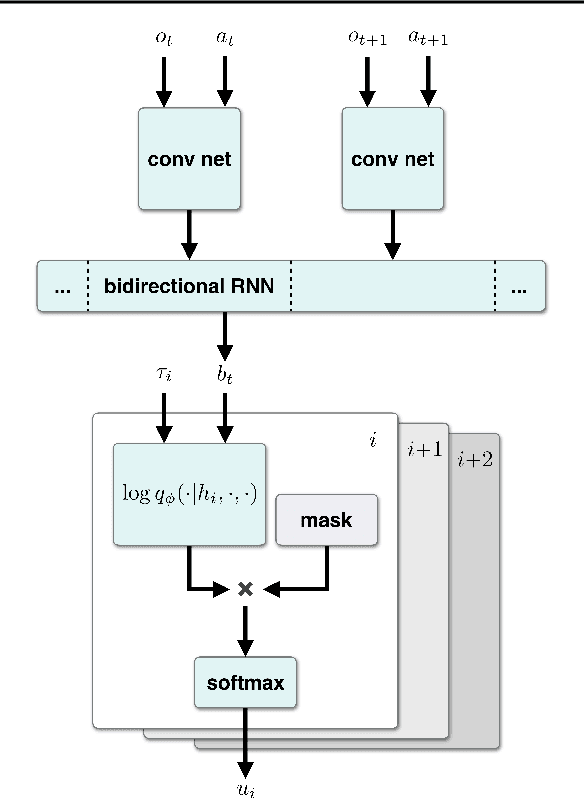
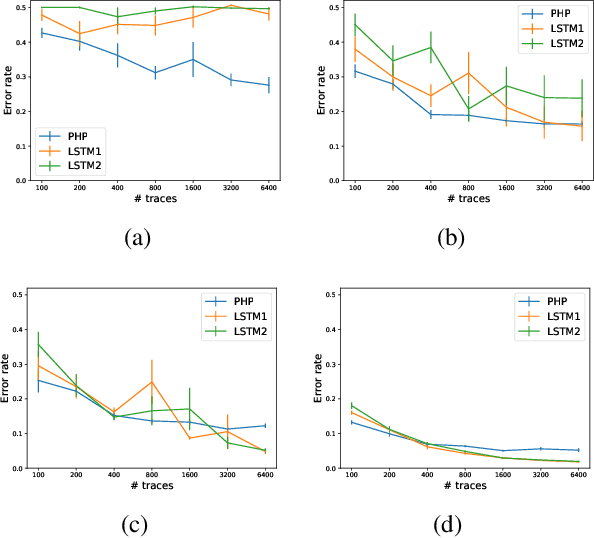
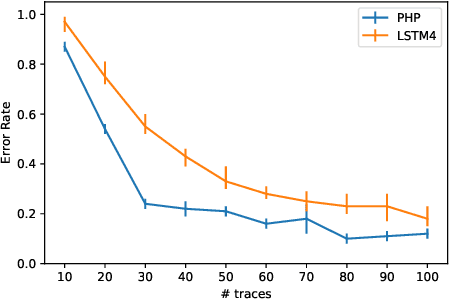
Autonomous agents can learn by imitating teacher demonstrations of the intended behavior. Hierarchical control policies are ubiquitously useful for such learning, having the potential to break down structured tasks into simpler sub-tasks, thereby improving data efficiency and generalization. In this paper, we propose a variational inference method for imitation learning of a control policy represented by parametrized hierarchical procedures (PHP), a program-like structure in which procedures can invoke sub-procedures to perform sub-tasks. Our method discovers the hierarchical structure in a dataset of observation-action traces of teacher demonstrations, by learning an approximate posterior distribution over the latent sequence of procedure calls and terminations. Samples from this learned distribution then guide the training of the hierarchical control policy. We identify and demonstrate a novel benefit of variational inference in the context of hierarchical imitation learning: in decomposing the policy into simpler procedures, inference can leverage acausal information that is unused by other methods. Training PHP with variational inference outperforms LSTM baselines in terms of data efficiency and generalization, requiring less than half as much data to achieve a 24% error rate in executing the bubble sort algorithm, and to achieve no error in executing Karel programs.
Generalizing Robot Imitation Learning with Invariant Hidden Semi-Markov Models
Nov 19, 2018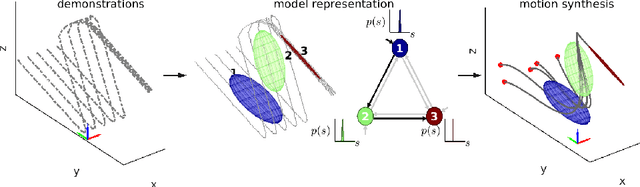
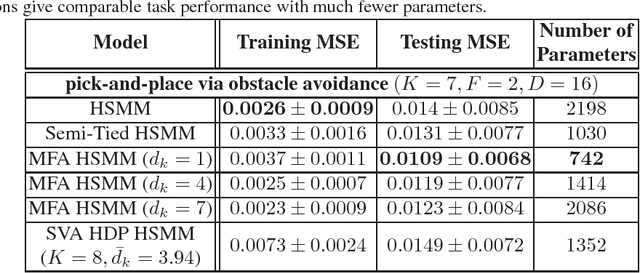
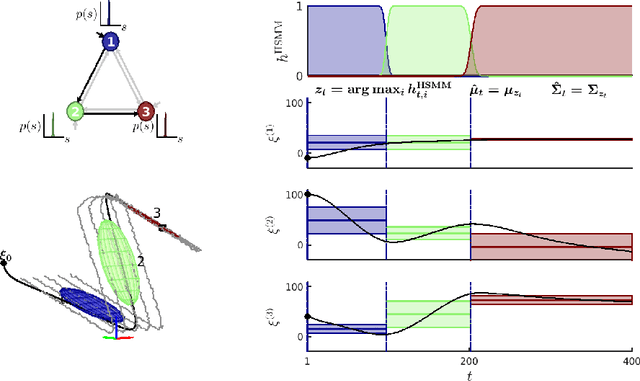
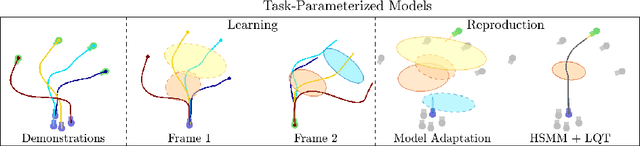
Generalizing manipulation skills to new situations requires extracting invariant patterns from demonstrations. For example, the robot needs to understand the demonstrations at a higher level while being invariant to the appearance of the objects, geometric aspects of objects such as its position, size, orientation and viewpoint of the observer in the demonstrations. In this paper, we propose an algorithm that learns a joint probability density function of the demonstrations with invariant formulations of hidden semi-Markov models to extract invariant segments (also termed as sub-goals or options), and smoothly follow the generated sequence of states with a linear quadratic tracking controller. The algorithm takes as input the demonstrations with respect to different coordinate systems describing virtual landmarks or objects of interest with a task-parameterized formulation, and adapt the segments according to the environmental changes in a systematic manner. We present variants of this algorithm in latent space with low-rank covariance decompositions, semi-tied covariances, and non-parametric online estimation of model parameters under small variance asymptotics; yielding considerably low sample and model complexity for acquiring new manipulation skills. The algorithm allows a Baxter robot to learn a pick-and-place task while avoiding a movable obstacle based on only 4 kinesthetic demonstrations.
Constraint Estimation and Derivative-Free Recovery for Robot Learning from Demonstrations
Oct 16, 2018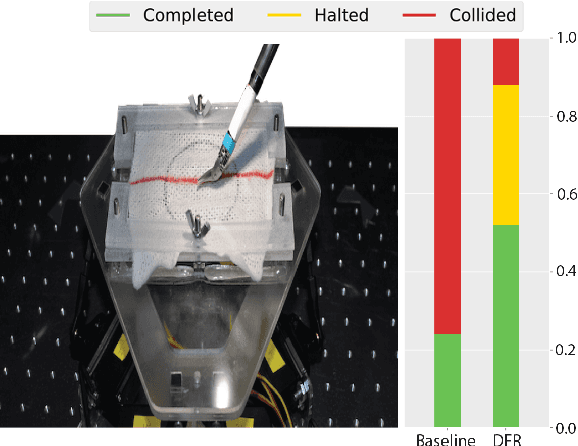
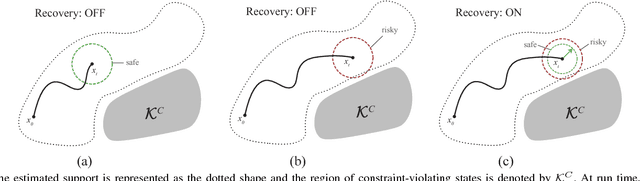
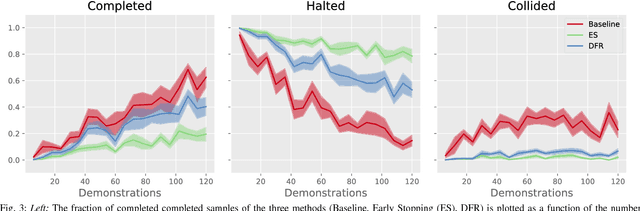
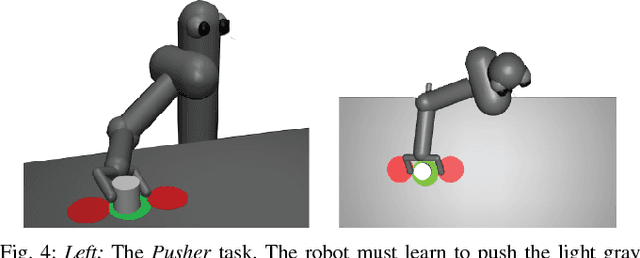
Learning from human demonstrations can facilitate automation but is risky because the execution of the learned policy might lead to collisions and other failures. Adding explicit constraints to avoid unsafe states is generally not possible when the state representations are complex. Furthermore, enforcing these constraints during execution of the learned policy can be challenging in environments where dynamics are difficult to model such as push mechanics in grasping. In this paper, we propose Derivative-Free Recovery (DFR), a two-phase method for generating robust policies from demonstrations in robotic manipulation tasks where the system comes to rest at each time step. In the first phase, we use support estimation of supervisor demonstrations and treat the support as implicit constraints on states. We also propose a time-varying modification for sequential tasks. In the second phase, we use this support estimate to derive a switching policy that employs the learned policy in the interior of the support and switches to a recovery policy to steer the robot away from the boundary of the support if it drifts too close. We present additional conditions, which linearly bound the difference in state at each time step by the magnitude of control, allowing us to prove that the robot will not violate the constraints using the recovery policy. A simulated pushing task in MuJoCo suggests that DFR can reduce collisions by 83\%. On a physical line tracking task using a da Vinci Surgical Robot and a moving Stewart platform, DFR reduced collisions by 84\%.
RLlib: Abstractions for Distributed Reinforcement Learning
Jun 29, 2018


Reinforcement learning (RL) algorithms involve the deep nesting of highly irregular computation patterns, each of which typically exhibits opportunities for distributed computation. We argue for distributing RL components in a composable way by adapting algorithms for top-down hierarchical control, thereby encapsulating parallelism and resource requirements within short-running compute tasks. We demonstrate the benefits of this principle through RLlib: a library that provides scalable software primitives for RL. These primitives enable a broad range of algorithms to be implemented with high performance, scalability, and substantial code reuse. RLlib is available at https://rllib.io/.
Fast and Reliable Autonomous Surgical Debridement with Cable-Driven Robots Using a Two-Phase Calibration Procedure
Feb 24, 2018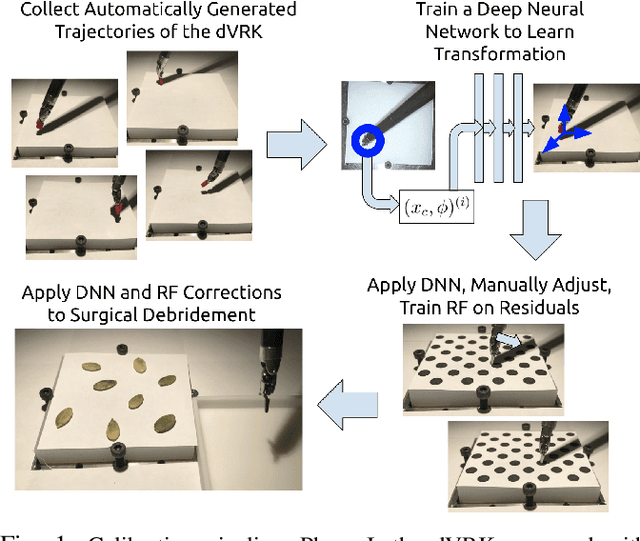
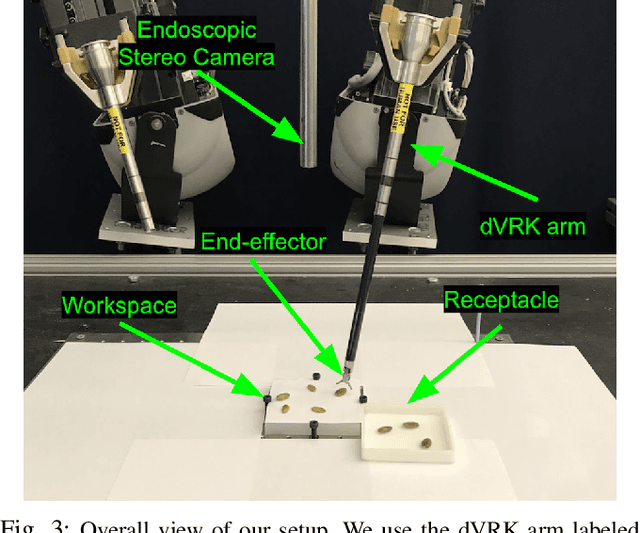

Automating precision subtasks such as debridement (removing dead or diseased tissue fragments) with Robotic Surgical Assistants (RSAs) such as the da Vinci Research Kit (dVRK) is challenging due to inherent non-linearities in cable-driven systems. We propose and evaluate a novel two-phase coarse-to-fine calibration method. In Phase I (coarse), we place a red calibration marker on the end effector and let it randomly move through a set of open-loop trajectories to obtain a large sample set of camera pixels and internal robot end-effector configurations. This coarse data is then used to train a Deep Neural Network (DNN) to learn the coarse transformation bias. In Phase II (fine), the bias from Phase I is applied to move the end-effector toward a small set of specific target points on a printed sheet. For each target, a human operator manually adjusts the end-effector position by direct contact (not through teleoperation) and the residual compensation bias is recorded. This fine data is then used to train a Random Forest (RF) to learn the fine transformation bias. Subsequent experiments suggest that without calibration, position errors average 4.55mm. Phase I can reduce average error to 2.14mm and the combination of Phase I and Phase II can reduces average error to 1.08mm. We apply these results to debridement of raisins and pumpkin seeds as fragment phantoms. Using an endoscopic stereo camera with standard edge detection, experiments with 120 trials achieved average success rates of 94.5%, exceeding prior results with much larger fragments (89.4%) and achieving a speedup of 2.1x, decreasing time per fragment from 15.8 seconds to 7.3 seconds. Source code, data, and videos are available at https://sites.google.com/view/calib-icra/.
DDCO: Discovery of Deep Continuous Options for Robot Learning from Demonstrations
Oct 31, 2017
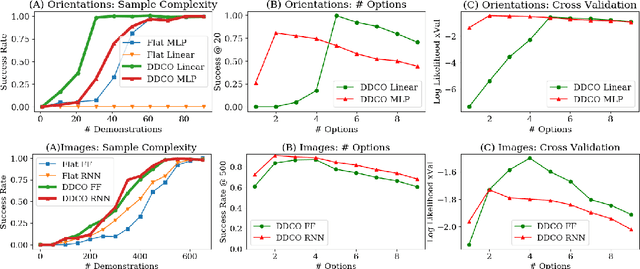
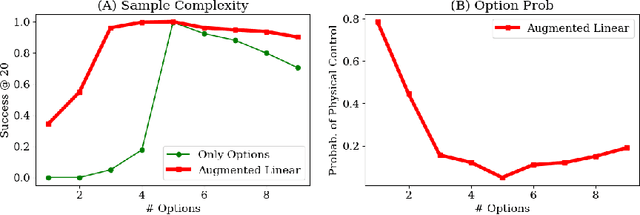
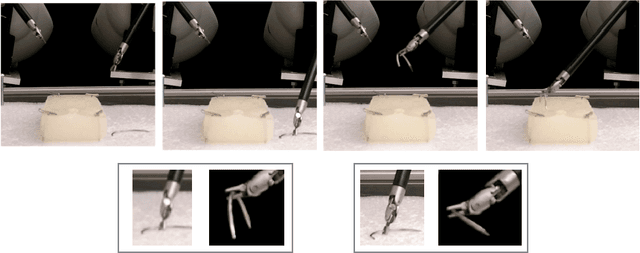
An option is a short-term skill consisting of a control policy for a specified region of the state space, and a termination condition recognizing leaving that region. In prior work, we proposed an algorithm called Deep Discovery of Options (DDO) to discover options to accelerate reinforcement learning in Atari games. This paper studies an extension to robot imitation learning, called Discovery of Deep Continuous Options (DDCO), where low-level continuous control skills parametrized by deep neural networks are learned from demonstrations. We extend DDO with: (1) a hybrid categorical-continuous distribution model to parametrize high-level policies that can invoke discrete options as well continuous control actions, and (2) a cross-validation method that relaxes DDO's requirement that users specify the number of options to be discovered. We evaluate DDCO in simulation of a 3-link robot in the vertical plane pushing a block with friction and gravity, and in two physical experiments on the da Vinci surgical robot, needle insertion where a needle is grasped and inserted into a silicone tissue phantom, and needle bin picking where needles and pins are grasped from a pile and categorized into bins. In the 3-link arm simulation, results suggest that DDCO can take 3x fewer demonstrations to achieve the same reward compared to a baseline imitation learning approach. In the needle insertion task, DDCO was successful 8/10 times compared to the next most accurate imitation learning baseline 6/10. In the surgical bin picking task, the learned policy successfully grasps a single object in 66 out of 99 attempted grasps, and in all but one case successfully recovered from failed grasps by retrying a second time.
* Published at CoRL 2017