 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Approximated ICP
Jan 10, 2021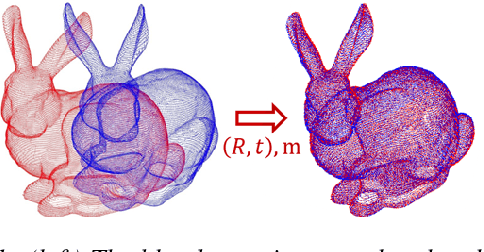
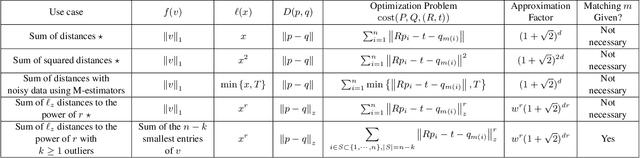
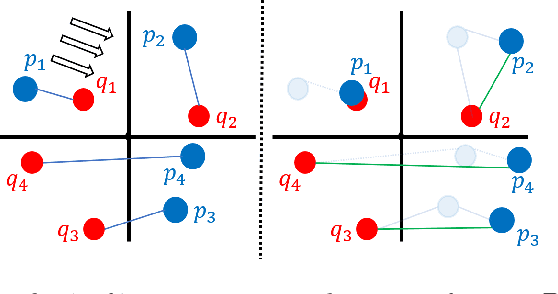
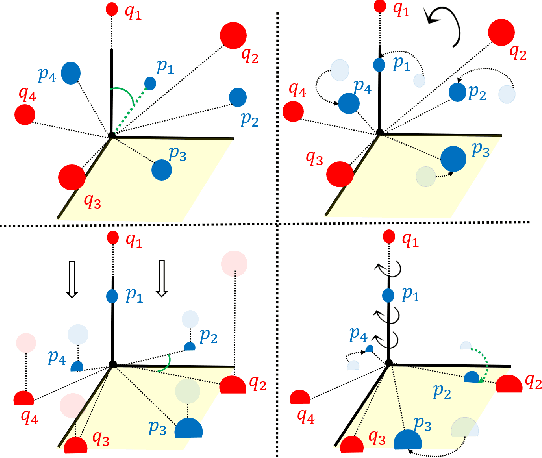
The goal of the \emph{alignment problem} is to align a (given) point cloud $P = \{p_1,\cdots,p_n\}$ to another (observed) point cloud $Q = \{q_1,\cdots,q_n\}$. That is, to compute a rotation matrix $R \in \mathbb{R}^{3 \times 3}$ and a translation vector $t \in \mathbb{R}^{3}$ that minimize the sum of paired distances $\sum_{i=1}^n D(Rp_i-t,q_i)$ for some distance function $D$. A harder version is the \emph{registration problem}, where the correspondence is unknown, and the minimum is also over all possible correspondence functions from $P$ to $Q$. Heuristics such as the Iterative Closest Point (ICP) algorithm and its variants were suggested for these problems, but none yield a provable non-trivial approximation for the global optimum. We prove that there \emph{always} exists a "witness" set of $3$ pairs in $P \times Q$ that, via novel alignment algorithm, defines a constant factor approximation (in the worst case) to this global optimum. We then provide algorithms that recover this witness set and yield the first provable constant factor approximation for the: (i) alignment problem in $O(n)$ expected time, and (ii) registration problem in polynomial time. Such small witness sets exist for many variants including points in $d$-dimensional space, outlier-resistant cost functions, and different correspondence types. Extensive experimental results on real and synthetic datasets show that our approximation constants are, in practice, close to $1$, and up to x$10$ times smaller than state-of-the-art algorithms.
Abiotic Stress Prediction from RGB-T Images of Banana Plantlets
Nov 23, 2020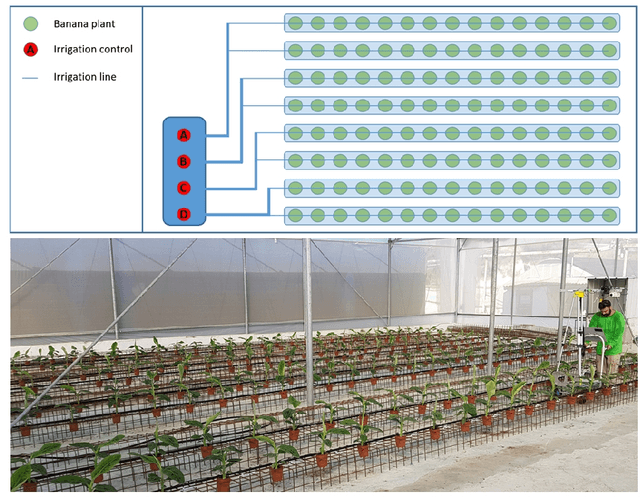

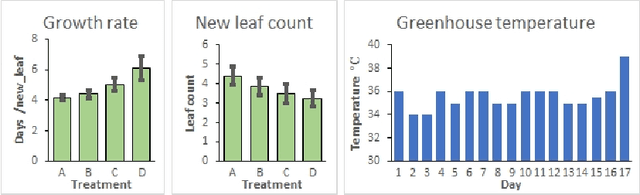
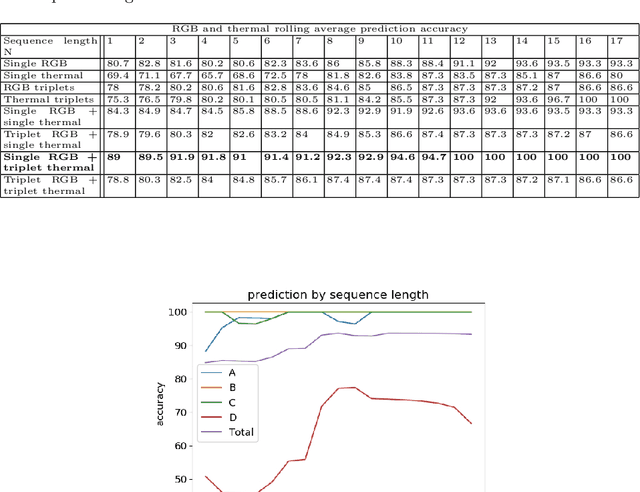
Prediction of stress conditions is important for monitoring plant growth stages, disease detection, and assessment of crop yields. Multi-modal data, acquired from a variety of sensors, offers diverse perspectives and is expected to benefit the prediction process. We present several methods and strategies for abiotic stress prediction in banana plantlets, on a dataset acquired during a two and a half weeks period, of plantlets subject to four separate water and fertilizer treatments. The dataset consists of RGB and thermal images, taken once daily of each plant. Results are encouraging, in the sense that neural networks exhibit high prediction rates (over $90\%$ amongst four classes), in cases where there are hardly any noticeable features distinguishing the treatments, much higher than field experts can supply.
A Color Elastica Model for Vector-Valued Image Regularization
Aug 19, 2020

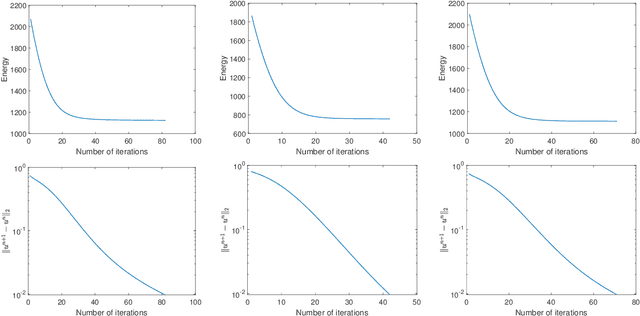

Models related to the Euler's Elastica energy have proven to be very useful for many applications, including image processing and high energy physics. Extending the Elastica models to color images and multi-channel data is challenging, as numerical solvers for these geometric models are difficult to find. In the past, the Polyakov action from high energy physics has been successfully applied for color image processing. Like the single channel Euler's elastica model and the total variation (TV) models, measures that require high order derivatives could help when considering image formation models that minimize elastic properties, in one way or another. Here, we introduce an addition to the Polyakov action for color images that minimizes the color manifold curvature, that is computed by applying of the Laplace-Beltrami operator to the color image channels. When applied to gray scale images, while selecting appropriate scaling between space and color, the proposed model reduces to minimizing the Euler's Elastica operating on the image level sets. Finding a minimizer for the proposed nonlinear geometric model is the challenge we address in this paper. Specifically, we present an operator-splitting method to minimize the proposed functional. The nonlinearity is decoupled by introducing three vector-valued and matrix-valued variables. The problem is then converted into solving for the steady state of an associated initial-value problem. The initial-value problem is time-split into three fractional steps, such that each sub-problem has a closed form solution, or can be solved by fast algorithms. The efficiency, and robustness of the proposed method are demonstrated by systematic numerical experiments.
LIMP: Learning Latent Shape Representations with Metric Preservation Priors
Mar 27, 2020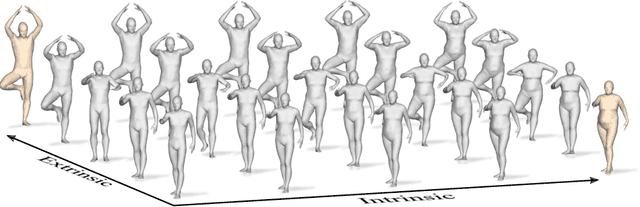
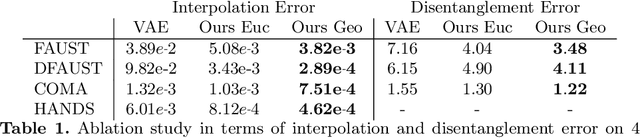
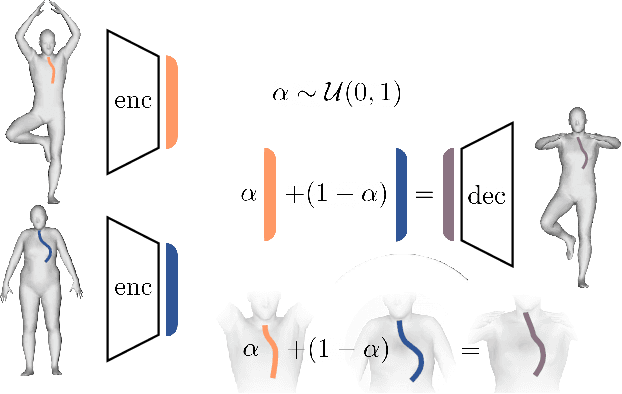
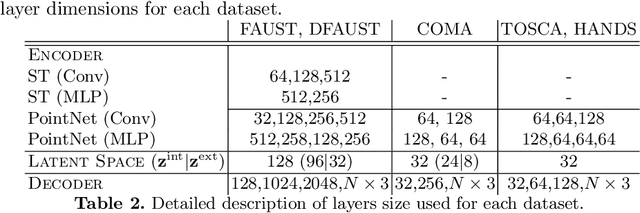
In this paper, we advocate the adoption of metric preservation as a powerful prior for learning latent representations of deformable 3D shapes. Key to our construction is the introduction of a geometric distortion criterion, defined directly on the decoded shapes, translating the preservation of the metric on the decoding to the formation of linear paths in the underlying latent space. Our rationale lies in the observation that training samples alone are often insufficient to endow generative models with high fidelity, motivating the need for large training datasets. In contrast, metric preservation provides a rigorous way to control the amount of geometric distortion incurring in the construction of the latent space, leading in turn to synthetic samples of higher quality. We further demonstrate, for the first time, the adoption of differentiable intrinsic distances in the backpropagation of a geodesic loss. Our geometric priors are particularly relevant in the presence of scarce training data, where learning any meaningful latent structure can be especially challenging. The effectiveness and potential of our generative model is showcased in applications of style transfer, content generation, and shape completion.
Do We Need Depth in State-Of-The-Art Face Authentication?
Mar 24, 2020
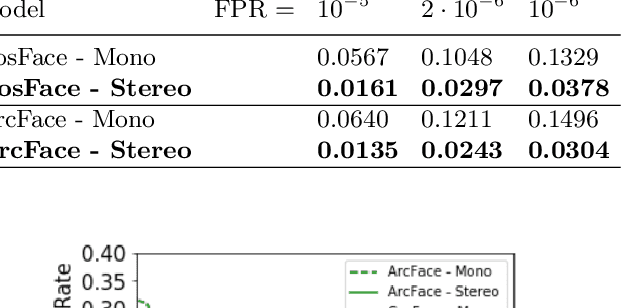


Some face recognition methods are designed to utilize geometric features extracted from depth sensors to handle the challenges of single-image based recognition technologies. However, calculating the geometrical data is an expensive and challenging process. Here, we introduce a novel method that learns distinctive geometric features from stereo camera systems without the need to explicitly compute the facial surface or depth map. The raw face stereo images along with coordinate maps allow a CNN to learn geometric features. This way, we keep the simplicity and cost efficiency of recognition from a single image, while enjoying the benefits of geometric data without explicitly reconstructing it. We demonstrate that the suggested method outperforms both existing single-image and explicit depth based methods on large-scale benchmarks. We also provide an ablation study to show that the suggested method uses the coordinate maps to encode more informative features.
The Whole Is Greater Than the Sum of Its Nonrigid Parts
Jan 27, 2020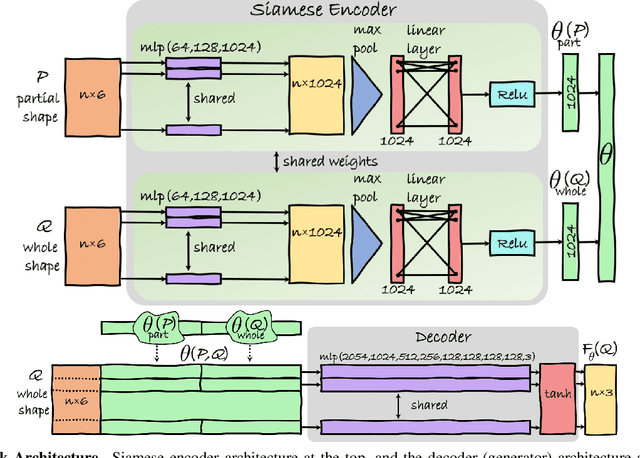

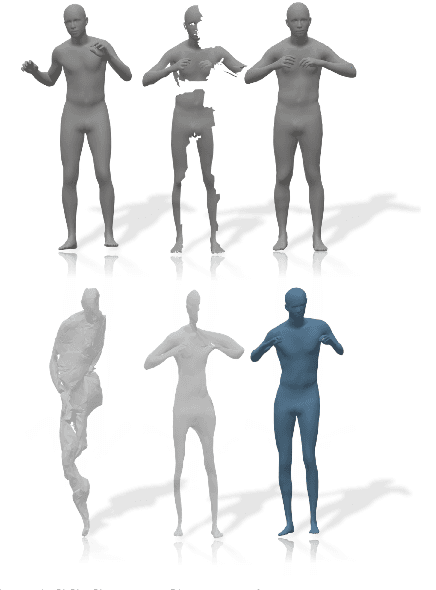

According to Aristotle, a philosopher in Ancient Greece, "the whole is greater than the sum of its parts". This observation was adopted to explain human perception by the Gestalt psychology school of thought in the twentieth century. Here, we claim that observing part of an object which was previously acquired as a whole, one could deal with both partial matching and shape completion in a holistic manner. More specifically, given the geometry of a full, articulated object in a given pose, as well as a partial scan of the same object in a different pose, we address the problem of matching the part to the whole while simultaneously reconstructing the new pose from its partial observation. Our approach is data-driven, and takes the form of a Siamese autoencoder without the requirement of a consistent vertex labeling at inference time; as such, it can be used on unorganized point clouds as well as on triangle meshes. We demonstrate the practical effectiveness of our model in the applications of single-view deformable shape completion and dense shape correspondence, both on synthetic and real-world geometric data, where we outperform prior work on these tasks by a large margin.
Bilateral Operators for Functional Maps
Jul 30, 2019
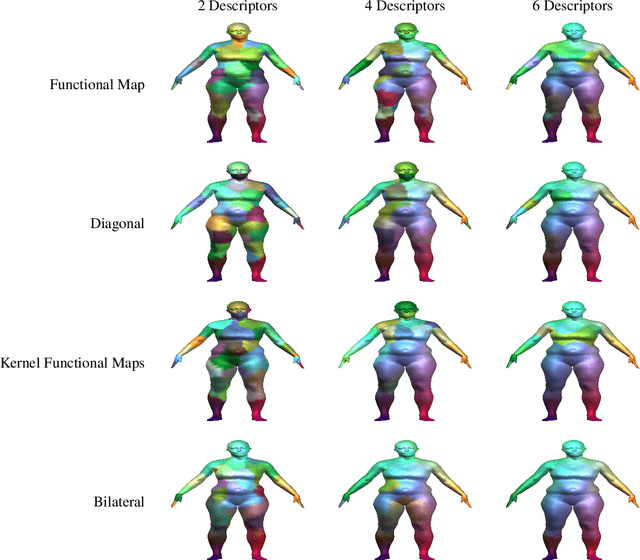
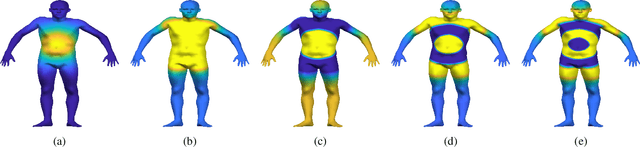
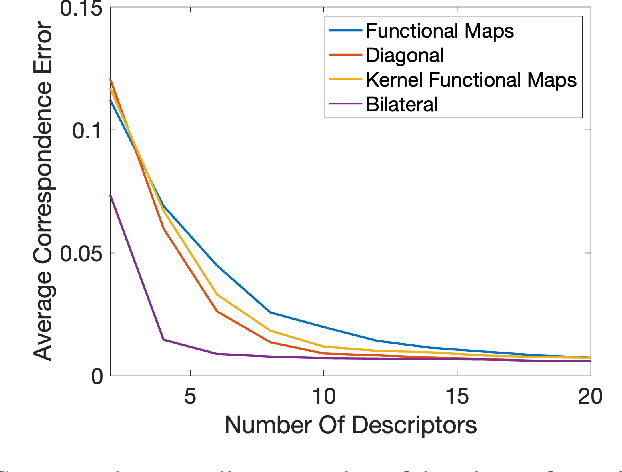
A majority of shape correspondence frameworks are based on devising pointwise and pairwise constraints on the correspondence map. The functional maps framework allows for formulating these constraints in the spectral domain. In this paper, we develop a functional map framework for the shape correspondence problem by constructing pairwise constraints using point-wise descriptors. Our core observation is that, every point-wise descriptor allows for the construction a pairwise kernel operator whose low frequency eigenfunctions depict regions of similar descriptor values at various scales of frequency. By aggregating the pairwise information from the descriptor and the intrinsic geometry of the surface encoded in the heat kernel, we construct a hybrid kernel and call it the bilateral operator. Analogous to the edge preserving bilateral filter in image processing, the action of the bilateral operator on a function defined over the manifold yields a descriptor dependent local smoothing of that function. By forcing the correspondence map to commute with the Bilateral operator, we show that we can maximally exploit the information from a given set of pointwise descriptors in a functional map framework.
Data Augmentation for Leaf Segmentation and Counting Tasks in Rosette Plants
Mar 20, 2019
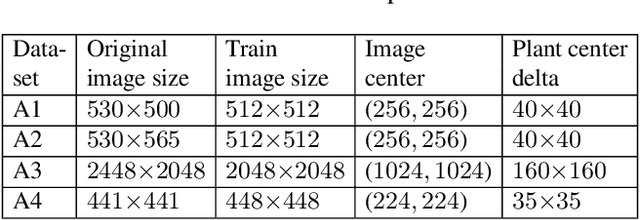

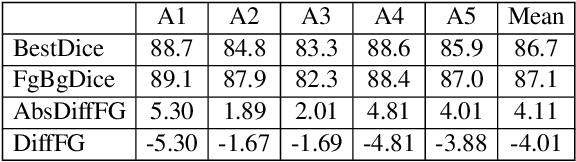
Deep learning techniques involving image processing and data analysis are constantly evolving. Many domains adapt these techniques for object segmentation, instantiation and classification. Recently, agricultural industries adopted those techniques in order to bring automation to farmers around the globe. One analysis procedure required for automatic visual inspection in this domain is leaf count and segmentation. Collecting labeled data from field crops and greenhouses is a complicated task due to the large variety of crops, growth seasons, climate changes, phenotype diversity, and more, especially when specific learning tasks require a large amount of labeled data for training. Data augmentation for training deep neural networks is well established, examples include data synthesis, using generative semi-synthetic models, and applying various kinds of transformations. In this paper we propose a method that preserves the geometric structure of the data objects, thus keeping the physical appearance of the data-set as close as possible to imaged plants in real agricultural scenes. The proposed method provides state of the art results when applied to the standard benchmark in the field, namely, the ongoing Leaf Segmentation Challenge hosted by Computer Vision Problems in Plant Phenotyping.
Deep Eikonal Solvers
Mar 19, 2019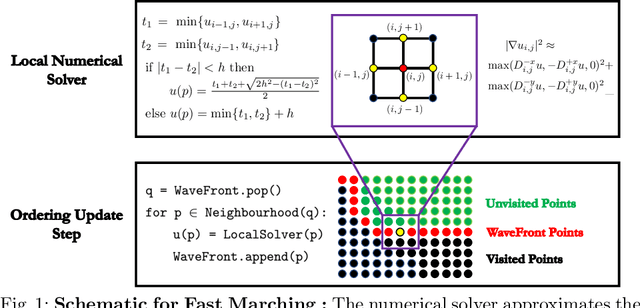
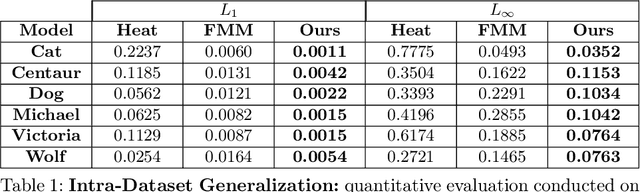
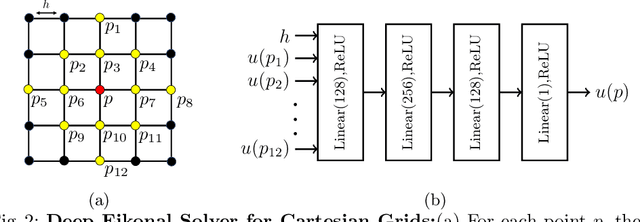
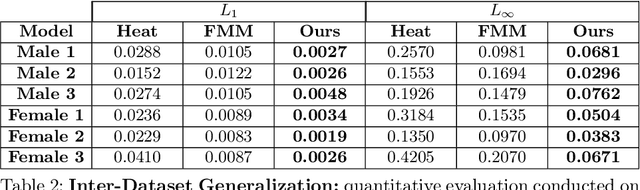
A deep learning approach to numerically approximate the solution to the Eikonal equation is introduced. The proposed method is built on the fast marching scheme which comprises of two components: a local numerical solver and an update scheme. We replace the formulaic local numerical solver with a trained neural network to provide highly accurate estimates of local distances for a variety of different geometries and sampling conditions. Our learning approach generalizes not only to flat Euclidean domains but also to curved surfaces enabled by the incorporation of certain invariant features in the neural network architecture. We show a considerable gain in performance, validated by smaller errors and higher orders of accuracy for the numerical solutions of the Eikonal equation computed on different surfaces The proposed approach leverages the approximation power of neural networks to enhance the performance of numerical algorithms, thereby, connecting the somewhat disparate themes of numerical geometry and learning.
Learning to Optimize Multigrid PDE Solvers
Feb 25, 2019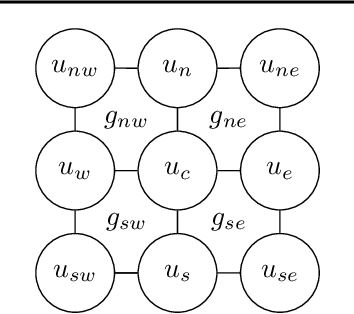
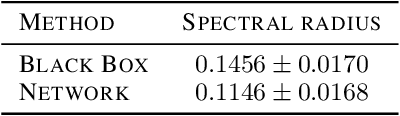
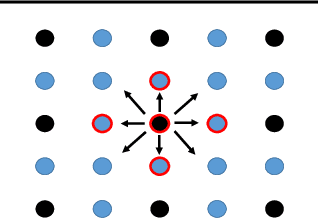
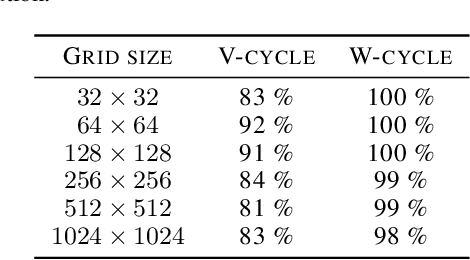
Constructing fast numerical solvers for partial differential equations (PDEs) is crucial for many scientific disciplines. A leading technique for solving large-scale PDEs is using multigrid methods. At the core of a multigrid solver is the prolongation matrix, which relates between different scales of the problem. This matrix is strongly problem-dependent, and its optimal construction is critical to the efficiency of the solver. In practice, however, devising multigrid algorithms for new problems often poses formidable challenges. In this paper we propose a framework for learning multigrid solvers. Our method learns a (single) mapping from discretized PDEs to prolongation operators for a broad class of 2D diffusion problems. We train a neural network once for the entire class of PDEs, using an efficient and unsupervised loss function. Our tests demonstrate improved convergence rates compared to the widely used Black-Box multigrid scheme, suggesting that our method successfully learned rules for constructing prolongation matrices.