 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-to-Token Alignment of Text Embeddings for Semantic Blending
Jun 22, 2026In modern generative models, images are specified and controlled through text prompts. In practice, images are generated from sequences of tokens derived from these prompts. However, the space of token sequences lacks a consistent accessible structure: semantically similar images may correspond to sequences that differ in wording, ordering, and placement of concepts, while similar token sequences may encode very different semantics. This apparent lack of structure makes it difficult to perform smooth transitions in this space, hindering applications such as image blending and continuous control of edits. We argue that this limitation stems not from the absence of semantic structure, but from misalignment between representations. To address this misalignment, we introduce Token-to-Token alignment, a framework that establishes explicit semantic correspondence between tokens across prompts. Our approach transforms prompts into a structured representation in which semantically corresponding concepts are mapped to consistent positions across prompts, and then aligns their token embeddings based on semantic similarity. Concretely, the method consists of two stages: a structural alignment that rephrases prompts into a shared structured form, followed by an embedding-level alignment that matches token representations across prompts. With this alignment in place, simple linear interpolation becomes a meaningful operation, producing smooth and coherent semantic transitions and enabling applications such as blending and continuous editing. Our results show that text embedding spaces in text-to-image models implicitly encode a continuous semantic structure that becomes accessible once representations are properly aligned, suggesting that semantic control can be achieved by organizing existing representations rather than modifying the generative model.
Deep Accurate Solver for the Geodesic Problem
Feb 25, 2026A common approach to compute distances on continuous surfaces is by considering a discretized polygonal mesh approximating the surface and estimating distances on the polygon. We show that exact geodesic distances restricted to the polygon are at most second-order accurate with respect to the distances on the corresponding continuous surface. By order of accuracy we refer to the convergence rate as a function of the average distance between sampled points. Next, a higher-order accurate deep learning method for computing geodesic distances on surfaces is introduced. Traditionally, one considers two main components when computing distances on surfaces: a numerical solver that locally approximates the distance function, and an efficient causal ordering scheme by which surface points are updated. Classical minimal path methods often exploit a dynamic programming principle with quasi-linear computational complexity in the number of sampled points. The quality of the distance approximation is determined by the local solver that is revisited in this paper. To improve state of the art accuracy, we consider a neural network-based local solver which implicitly approximates the structure of the continuous surface. We supply numerical evidence that the proposed learned update scheme provides better accuracy compared to the best possible polyhedral approximations and previous learning-based methods. The result is a third-order accurate solver with a bootstrapping-recipe for further improvement.
* Extended version of Deep Accurate Solver for the Geodesic Problem originally published in Scale Space and Variational Methods in Computer Vision (SSVM 2023), Lecture Notes in Computer Science, Springer. This version includes additional experiments and detailed analysis
BBQ-to-Image: Numeric Bounding Box and Qolor Control in Large-Scale Text-to-Image Models
Feb 24, 2026Text-to-image models have rapidly advanced in realism and controllability, with recent approaches leveraging long, detailed captions to support fine-grained generation. However, a fundamental parametric gap remains: existing models rely on descriptive language, whereas professional workflows require precise numeric control over object location, size, and color. In this work, we introduce BBQ, a large-scale text-to-image model that directly conditions on numeric bounding boxes and RGB triplets within a unified structured-text framework. We obtain precise spatial and chromatic control by training on captions enriched with parametric annotations, without architectural modifications or inference-time optimization. This also enables intuitive user interfaces such as object dragging and color pickers, replacing ambiguous iterative prompting with precise, familiar controls. Across comprehensive evaluations, BBQ achieves strong box alignment and improves RGB color fidelity over state-of-the-art baselines. More broadly, our results support a new paradigm in which user intent is translated into an intermediate structured language, consumed by a flow-based transformer acting as a renderer and naturally accommodating numeric parameters.
SemanticMoments: Training-Free Motion Similarity via Third Moment Features
Feb 09, 2026Retrieving videos based on semantic motion is a fundamental, yet unsolved, problem. Existing video representation approaches overly rely on static appearance and scene context rather than motion dynamics, a bias inherited from their training data and objectives. Conversely, traditional motion-centric inputs like optical flow lack the semantic grounding needed to understand high-level motion. To demonstrate this inherent bias, we introduce the SimMotion benchmarks, combining controlled synthetic data with a new human-annotated real-world dataset. We show that existing models perform poorly on these benchmarks, often failing to disentangle motion from appearance. To address this gap, we propose SemanticMoments, a simple, training-free method that computes temporal statistics (specifically, higher-order moments) over features from pre-trained semantic models. Across our benchmarks, SemanticMoments consistently outperforms existing RGB, flow, and text-supervised methods. This demonstrates that temporal statistics in a semantic feature space provide a scalable and perceptually grounded foundation for motion-centric video understanding.
Generating an Image From 1,000 Words: Enhancing Text-to-Image With Structured Captions
Nov 10, 2025
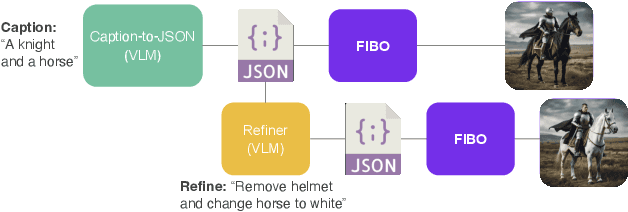


Text-to-image models have rapidly evolved from casual creative tools to professional-grade systems, achieving unprecedented levels of image quality and realism. Yet, most models are trained to map short prompts into detailed images, creating a gap between sparse textual input and rich visual outputs. This mismatch reduces controllability, as models often fill in missing details arbitrarily, biasing toward average user preferences and limiting precision for professional use. We address this limitation by training the first open-source text-to-image model on long structured captions, where every training sample is annotated with the same set of fine-grained attributes. This design maximizes expressive coverage and enables disentangled control over visual factors. To process long captions efficiently, we propose DimFusion, a fusion mechanism that integrates intermediate tokens from a lightweight LLM without increasing token length. We also introduce the Text-as-a-Bottleneck Reconstruction (TaBR) evaluation protocol. By assessing how well real images can be reconstructed through a captioning-generation loop, TaBR directly measures controllability and expressiveness, even for very long captions where existing evaluation methods fail. Finally, we demonstrate our contributions by training the large-scale model FIBO, achieving state-of-the-art prompt alignment among open-source models. Model weights are publicly available at https://huggingface.co/briaai/FIBO