 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretrained Transformers for Text Ranking: BERT and Beyond
Oct 13, 2020

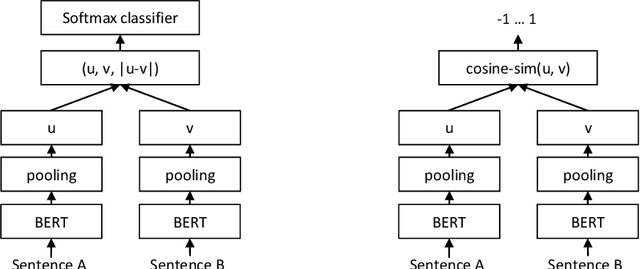
The goal of text ranking is to generate an ordered list of texts retrieved from a corpus in response to a query. Although the most common formulation of text ranking is search, instances of the task can also be found in many natural language processing applications. This survey provides an overview of text ranking with neural network architectures known as transformers, of which BERT is the best-known example. The combination of transformers and self-supervised pretraining has, without exaggeration, revolutionized the fields of natural language processing (NLP), information retrieval (IR), and beyond. In this survey, we provide a synthesis of existing work as a single point of entry for practitioners who wish to gain a better understanding of how to apply transformers to text ranking problems and researchers who wish to pursue work in this area. We cover a wide range of modern techniques, grouped into two high-level categories: transformer models that perform reranking in multi-stage ranking architectures and learned dense representations that attempt to perform ranking directly. There are two themes that pervade our survey: techniques for handling long documents, beyond the typical sentence-by-sentence processing approaches used in NLP, and techniques for addressing the tradeoff between effectiveness (result quality) and efficiency (query latency). Although transformer architectures and pretraining techniques are recent innovations, many aspects of how they are applied to text ranking are relatively well understood and represent mature techniques. However, there remain many open research questions, and thus in addition to laying out the foundations of pretrained transformers for text ranking, this survey also attempts to prognosticate where the field is heading.
Can questions summarize a corpus? Using question generation for characterizing COVID-19 research
Sep 19, 2020

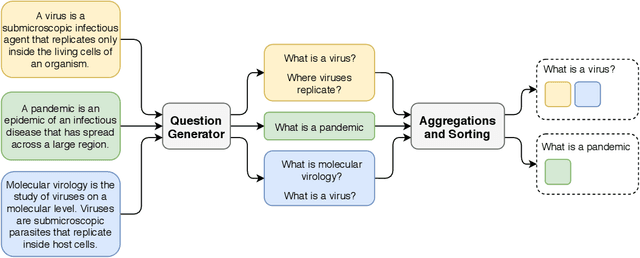
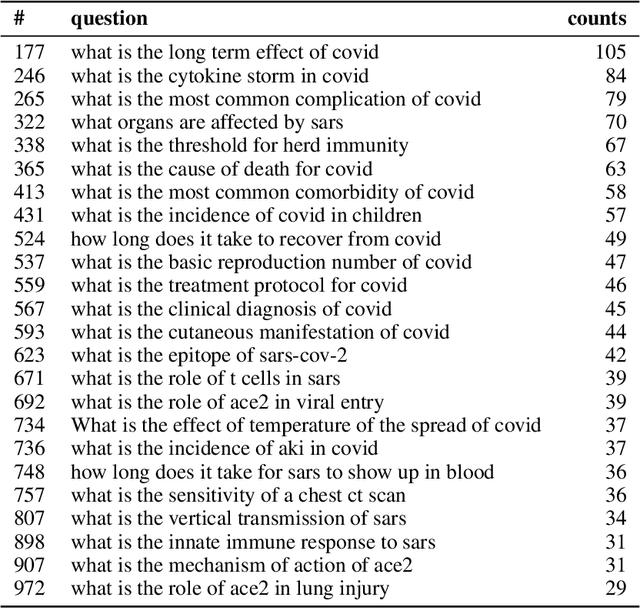
What are the latent questions on some textual data? In this work, we investigate using question generation models for exploring a collection of documents. Our method, dubbed corpus2question, consists of applying a pre-trained question generation model over a corpus and aggregating the resulting questions by frequency and time. This technique is an alternative to methods such as topic modelling and word cloud for summarizing large amounts of textual data. Results show that applying corpus2question on a corpus of scientific articles related to COVID-19 yields relevant questions about the topic. The most frequent questions are "what is covid 19" and "what is the treatment for covid". Among the 1000 most frequent questions are "what is the threshold for herd immunity" and "what is the role of ace2 in viral entry". We show that the proposed method generated similar questions for 13 of the 27 expert-made questions from the CovidQA question answering dataset. The code to reproduce our experiments and the generated questions are available at: https://github.com/unicamp-dl/corpus2question
PTT5: Pretraining and validating the T5 model on Brazilian Portuguese data
Aug 20, 2020
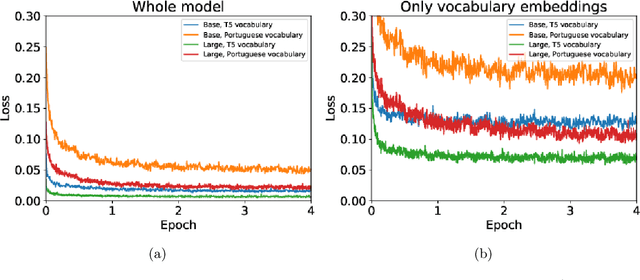

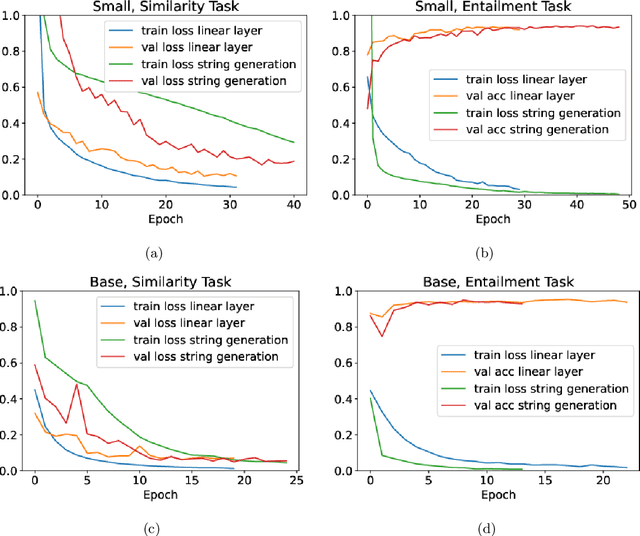
In natural language processing (NLP), there is a need for more resources in Portuguese, since much of the data used in the state-of-the-art research is in other languages. In this paper, we pretrain a T5 model on the BrWac corpus, an extensive collection of web pages in Portuguese, and evaluate its performance against other Portuguese pretrained models and multilingual models on the sentence similarity and sentence entailment tasks. We show that our Portuguese pretrained models have significantly better performance over the original T5 models. Moreover, we showcase the positive impact of using a Portuguese vocabulary.
Lite Training Strategies for Portuguese-English and English-Portuguese Translation
Aug 20, 2020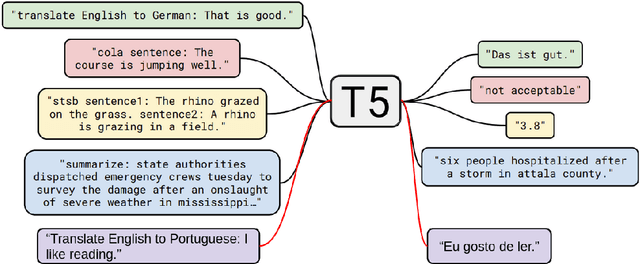



Despite the widespread adoption of deep learning for machine translation, it is still expensive to develop high-quality translation models. In this work, we investigate the use of pre-trained models, such as T5 for Portuguese-English and English-Portuguese translation tasks using low-cost hardware. We explore the use of Portuguese and English pre-trained language models and propose an adaptation of the English tokenizer to represent Portuguese characters, such as diaeresis, acute and grave accents. We compare our models to the Google Translate API and MarianMT on a subset of the ParaCrawl dataset, as well as to the winning submission to the WMT19 Biomedical Translation Shared Task. We also describe our submission to the WMT20 Biomedical Translation Shared Task. Our results show that our models have a competitive performance to state-of-the-art models while being trained on modest hardware (a single 8GB gaming GPU for nine days). Our data, models and code are available at https://github.com/unicamp-dl/Lite-T5-Translation.
Covidex: Neural Ranking Models and Keyword Search Infrastructure for the COVID-19 Open Research Dataset
Jul 14, 2020
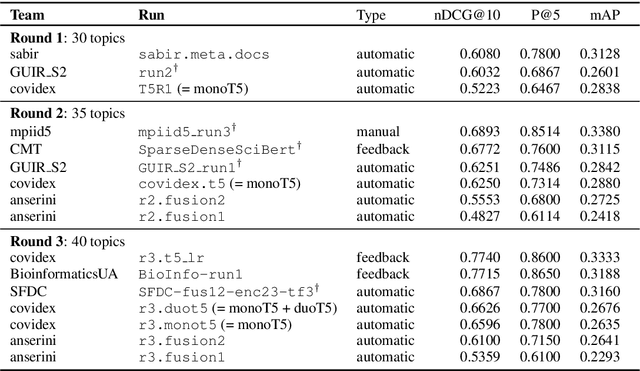
We present Covidex, a search engine that exploits the latest neural ranking models to provide information access to the COVID-19 Open Research Dataset curated by the Allen Institute for AI. Our system has been online and serving users since late March 2020. The Covidex is the user application component of our three-pronged strategy to develop technologies for helping domain experts tackle the ongoing global pandemic. In addition, we provide robust and easy-to-use keyword search infrastructure that exploits mature fusion-based methods as well as standalone neural ranking models that can be incorporated into other applications. These techniques have been evaluated in the ongoing TREC-COVID challenge: Our infrastructure and baselines have been adopted by many participants, including some of the highest-scoring runs in rounds 1, 2, and 3. In round 3, we report the highest-scoring run that takes advantage of previous training data and the second-highest fully automatic run.
Query Reformulation using Query History for Passage Retrieval in Conversational Search
May 05, 2020
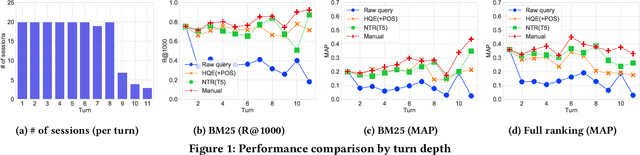
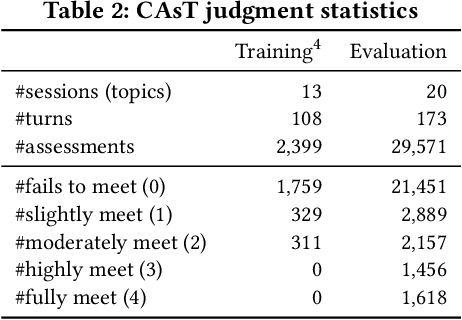
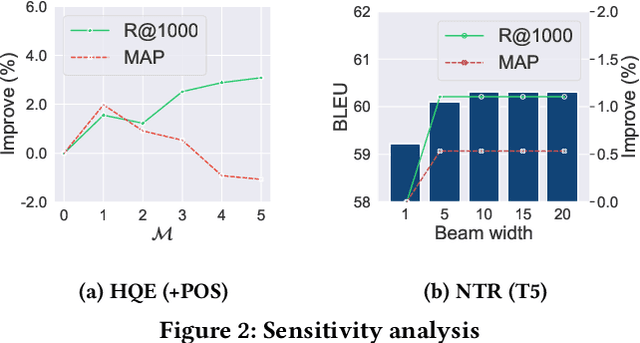
Passage retrieval in a conversational context is essential for many downstream applications; it is however extremely challenging due to limited data resources. To address this problem, we present an effective multi-stage pipeline for passage ranking in conversational search that integrates a widely-used IR system with a conversational query reformulation module. Along these lines, we propose two simple yet effective query reformulation approaches: historical query expansion (HQE) and neural transfer reformulation (NTR). Whereas HQE applies query expansion, a traditional IR query reformulation technique, NTR transfers human knowledge of conversational query understanding to a neural query reformulation model. The proposed HQE method was the top-performing submission of automatic systems in CAsT Track at TREC 2019. Building on this, our NTR approach improves an additional 18% over that best entry in terms of NDCG@3. We further analyze the distinct behaviors of the two approaches, and show that fusing their output reduces the performance gap (measured in NDCG@3) between the manually-rewritten and automatically-generated queries to 4 from 22 points when compared with the best CAsT submission.
Rapidly Bootstrapping a Question Answering Dataset for COVID-19
Apr 23, 2020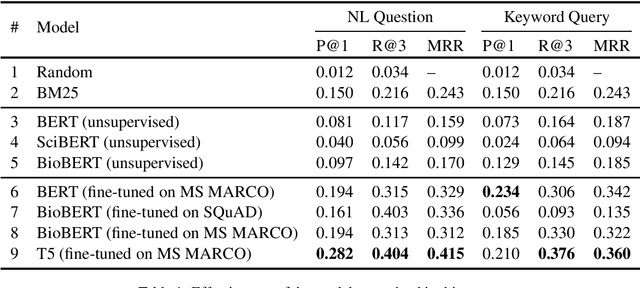
We present CovidQA, the beginnings of a question answering dataset specifically designed for COVID-19, built by hand from knowledge gathered from Kaggle's COVID-19 Open Research Dataset Challenge. To our knowledge, this is the first publicly available resource of its type, and intended as a stopgap measure for guiding research until more substantial evaluation resources become available. While this dataset, comprising 124 question-article pairs as of the present version 0.1 release, does not have sufficient examples for supervised machine learning, we believe that it can be helpful for evaluating the zero-shot or transfer capabilities of existing models on topics specifically related to COVID-19. This paper describes our methodology for constructing the dataset and presents the effectiveness of a number of baselines, including term-based techniques and various transformer-based models. The dataset is available at http://covidqa.ai/
Rapidly Deploying a Neural Search Engine for the COVID-19 Open Research Dataset: Preliminary Thoughts and Lessons Learned
Apr 10, 2020
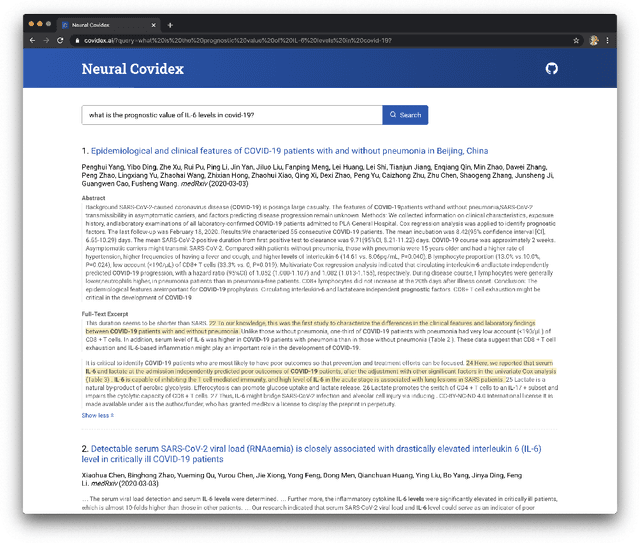
We present the Neural Covidex, a search engine that exploits the latest neural ranking architectures to provide information access to the COVID-19 Open Research Dataset curated by the Allen Institute for AI. This web application exists as part of a suite of tools that we have developed over the past few weeks to help domain experts tackle the ongoing global pandemic. We hope that improved information access capabilities to the scientific literature can inform evidence-based decision making and insight generation. This paper describes our initial efforts and offers a few thoughts about lessons we have learned along the way.
Conversational Question Reformulation via Sequence-to-Sequence Architectures and Pretrained Language Models
Apr 04, 2020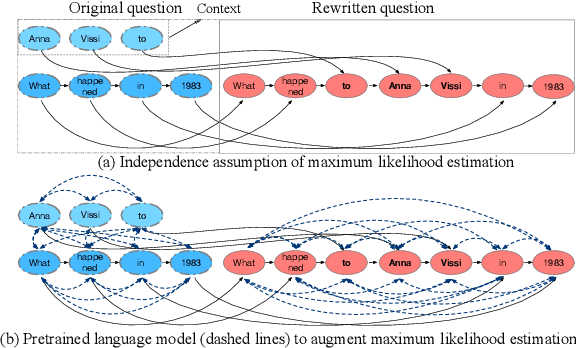
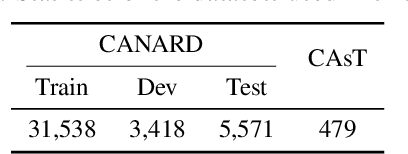
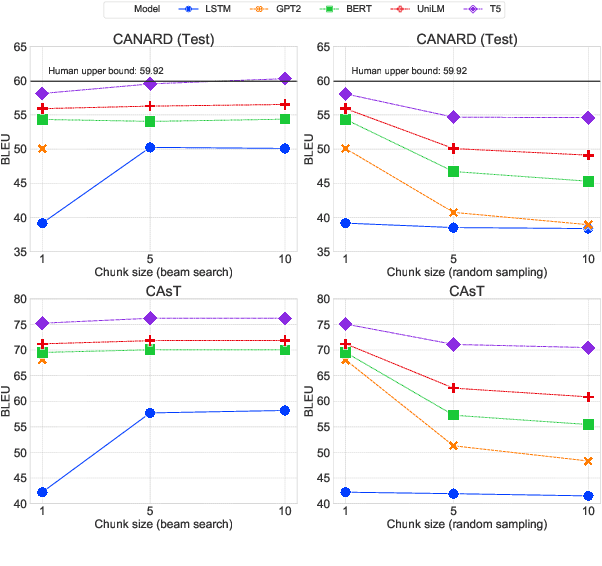
This paper presents an empirical study of conversational question reformulation (CQR) with sequence-to-sequence architectures and pretrained language models (PLMs). We leverage PLMs to address the strong token-to-token independence assumption made in the common objective, maximum likelihood estimation, for the CQR task. In CQR benchmarks of task-oriented dialogue systems, we evaluate fine-tuned PLMs on the recently-introduced CANARD dataset as an in-domain task and validate the models using data from the TREC 2019 CAsT Track as an out-domain task. Examining a variety of architectures with different numbers of parameters, we demonstrate that the recent text-to-text transfer transformer (T5) achieves the best results both on CANARD and CAsT with fewer parameters, compared to similar transformer architectures.
TTTTTackling WinoGrande Schemas
Mar 18, 2020
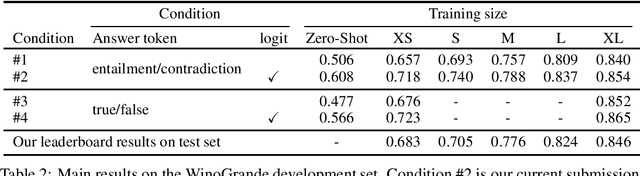
We applied the T5 sequence-to-sequence model to tackle the AI2 WinoGrande Challenge by decomposing each example into two input text strings, each containing a hypothesis, and using the probabilities assigned to the "entailment" token as a score of the hypothesis. Our first (and only) submission to the official leaderboard yielded 0.7673 AUC on March 13, 2020, which is the best known result at this time and beats the previous state of the art by over five points.