 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-temporal video autoencoder with differentiable memory
Sep 01, 2016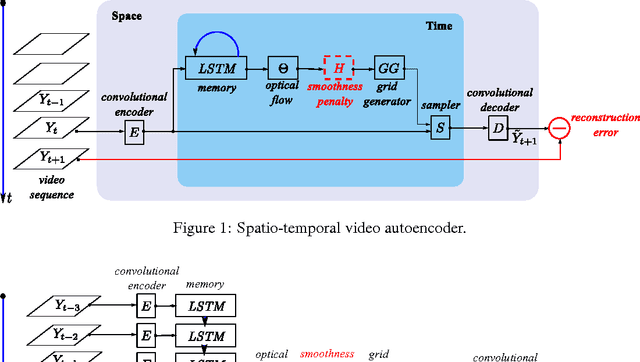
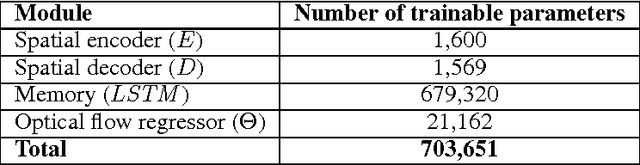


We describe a new spatio-temporal video autoencoder, based on a classic spatial image autoencoder and a novel nested temporal autoencoder. The temporal encoder is represented by a differentiable visual memory composed of convolutional long short-term memory (LSTM) cells that integrate changes over time. Here we target motion changes and use as temporal decoder a robust optical flow prediction module together with an image sampler serving as built-in feedback loop. The architecture is end-to-end differentiable. At each time step, the system receives as input a video frame, predicts the optical flow based on the current observation and the LSTM memory state as a dense transformation map, and applies it to the current frame to generate the next frame. By minimising the reconstruction error between the predicted next frame and the corresponding ground truth next frame, we train the whole system to extract features useful for motion estimation without any supervision effort. We present one direct application of the proposed framework in weakly-supervised semantic segmentation of videos through label propagation using optical flow.
Refining Architectures of Deep Convolutional Neural Networks
Apr 22, 2016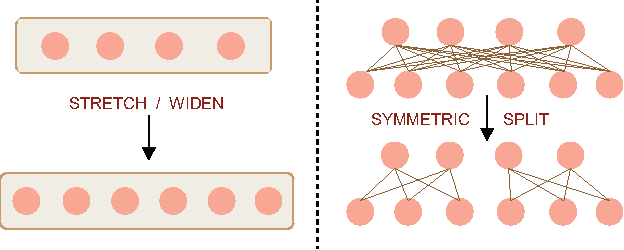
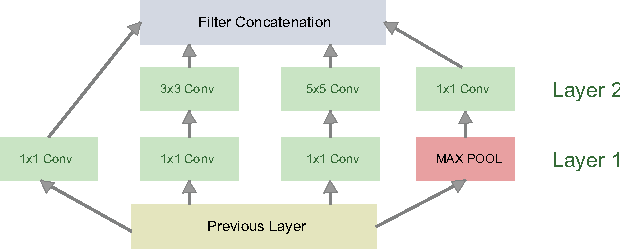

Deep Convolutional Neural Networks (CNNs) have recently evinced immense success for various image recognition tasks. However, a question of paramount importance is somewhat unanswered in deep learning research - is the selected CNN optimal for the dataset in terms of accuracy and model size? In this paper, we intend to answer this question and introduce a novel strategy that alters the architecture of a given CNN for a specified dataset, to potentially enhance the original accuracy while possibly reducing the model size. We use two operations for architecture refinement, viz. stretching and symmetrical splitting. Our procedure starts with a pre-trained CNN for a given dataset, and optimally decides the stretch and split factors across the network to refine the architecture. We empirically demonstrate the necessity of the two operations. We evaluate our approach on two natural scenes attributes datasets, SUN Attributes and CAMIT-NSAD, with architectures of GoogleNet and VGG-11, that are quite contrasting in their construction. We justify our choice of datasets, and show that they are interestingly distinct from each other, and together pose a challenge to our architectural refinement algorithm. Our results substantiate the usefulness of the proposed method.
PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization
Feb 18, 2016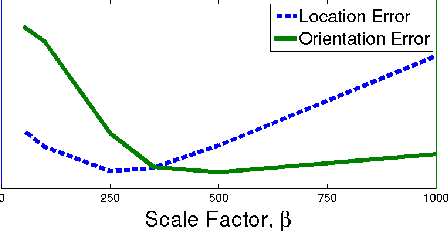
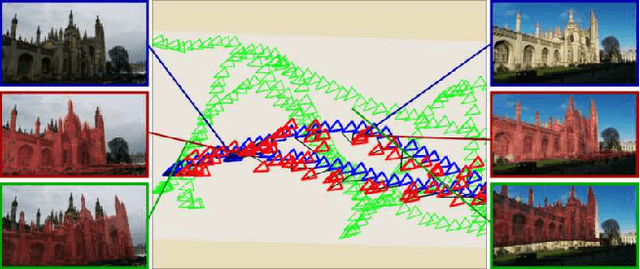
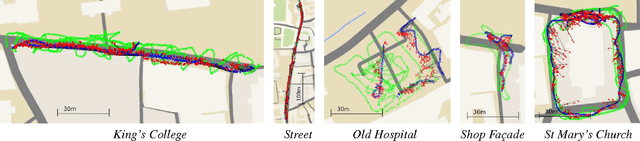
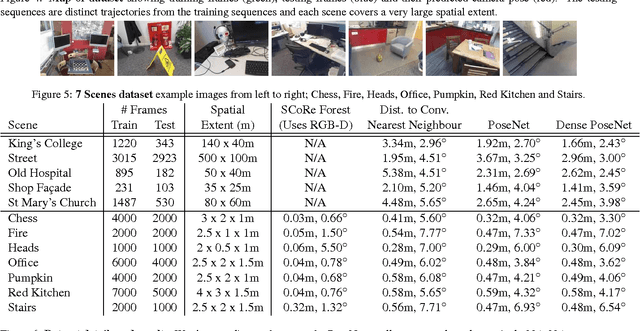
We present a robust and real-time monocular six degree of freedom relocalization system. Our system trains a convolutional neural network to regress the 6-DOF camera pose from a single RGB image in an end-to-end manner with no need of additional engineering or graph optimisation. The algorithm can operate indoors and outdoors in real time, taking 5ms per frame to compute. It obtains approximately 2m and 6 degree accuracy for large scale outdoor scenes and 0.5m and 10 degree accuracy indoors. This is achieved using an efficient 23 layer deep convnet, demonstrating that convnets can be used to solve complicated out of image plane regression problems. This was made possible by leveraging transfer learning from large scale classification data. We show the convnet localizes from high level features and is robust to difficult lighting, motion blur and different camera intrinsics where point based SIFT registration fails. Furthermore we show how the pose feature that is produced generalizes to other scenes allowing us to regress pose with only a few dozen training examples. PoseNet code, dataset and an online demonstration is available on our project webpage, at http://mi.eng.cam.ac.uk/projects/relocalisation/
Modelling Uncertainty in Deep Learning for Camera Relocalization
Feb 18, 2016
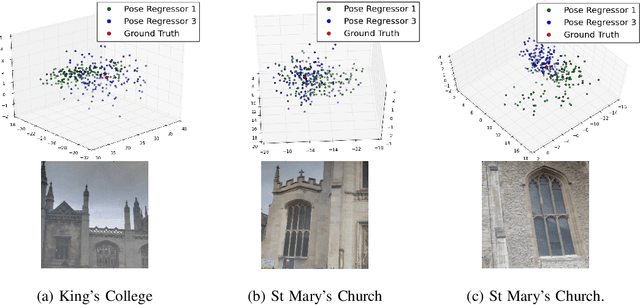
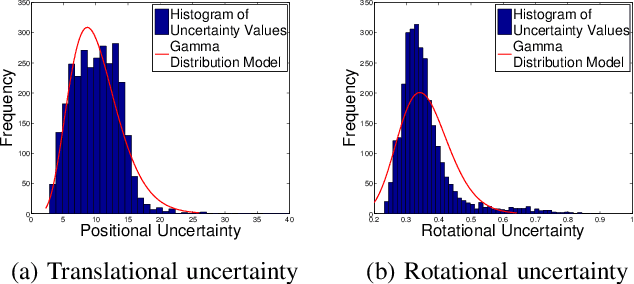
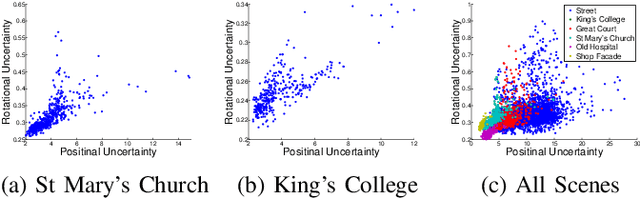
We present a robust and real-time monocular six degree of freedom visual relocalization system. We use a Bayesian convolutional neural network to regress the 6-DOF camera pose from a single RGB image. It is trained in an end-to-end manner with no need of additional engineering or graph optimisation. The algorithm can operate indoors and outdoors in real time, taking under 6ms to compute. It obtains approximately 2m and 6 degrees accuracy for very large scale outdoor scenes and 0.5m and 10 degrees accuracy indoors. Using a Bayesian convolutional neural network implementation we obtain an estimate of the model's relocalization uncertainty and improve state of the art localization accuracy on a large scale outdoor dataset. We leverage the uncertainty measure to estimate metric relocalization error and to detect the presence or absence of the scene in the input image. We show that the model's uncertainty is caused by images being dissimilar to the training dataset in either pose or appearance.
Training CNNs with Low-Rank Filters for Efficient Image Classification
Feb 07, 2016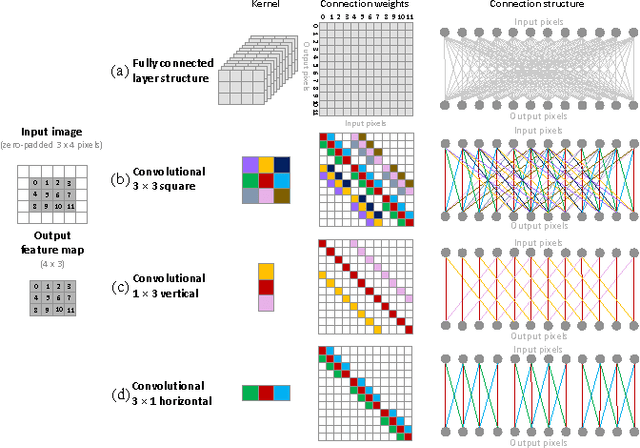
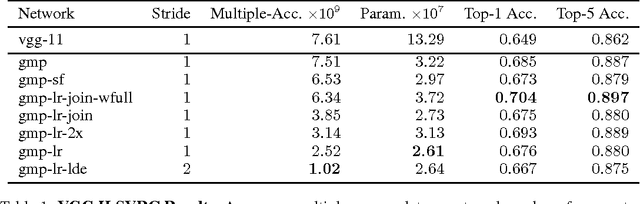
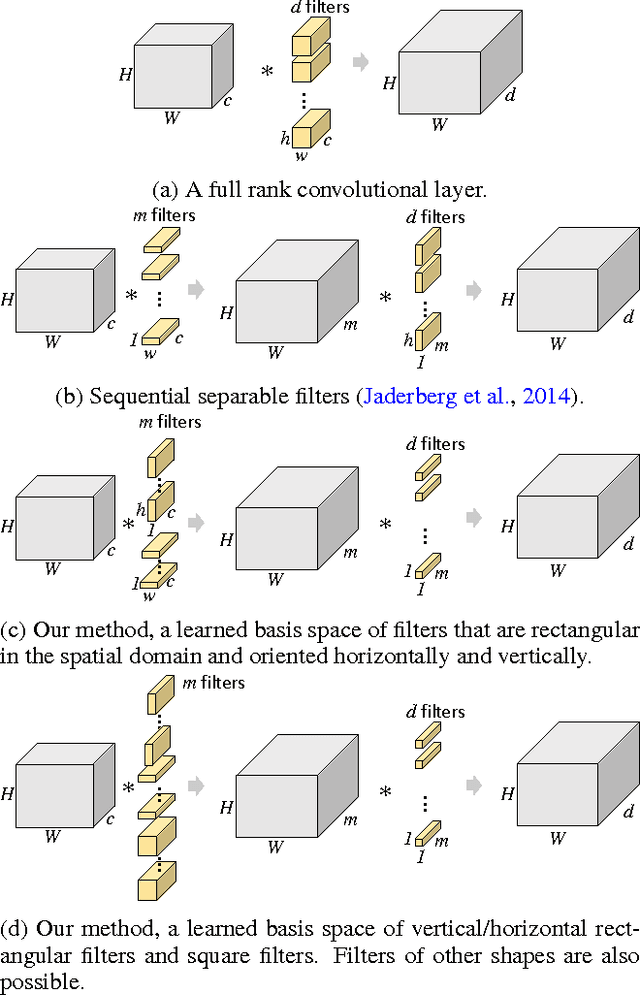
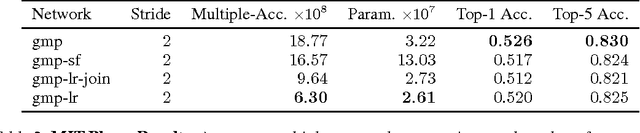
We propose a new method for creating computationally efficient convolutional neural networks (CNNs) by using low-rank representations of convolutional filters. Rather than approximating filters in previously-trained networks with more efficient versions, we learn a set of small basis filters from scratch; during training, the network learns to combine these basis filters into more complex filters that are discriminative for image classification. To train such networks, a novel weight initialization scheme is used. This allows effective initialization of connection weights in convolutional layers composed of groups of differently-shaped filters. We validate our approach by applying it to several existing CNN architectures and training these networks from scratch using the CIFAR, ILSVRC and MIT Places datasets. Our results show similar or higher accuracy than conventional CNNs with much less compute. Applying our method to an improved version of VGG-11 network using global max-pooling, we achieve comparable validation accuracy using 41% less compute and only 24% of the original VGG-11 model parameters; another variant of our method gives a 1 percentage point increase in accuracy over our improved VGG-11 model, giving a top-5 center-crop validation accuracy of 89.7% while reducing computation by 16% relative to the original VGG-11 model. Applying our method to the GoogLeNet architecture for ILSVRC, we achieved comparable accuracy with 26% less compute and 41% fewer model parameters. Applying our method to a near state-of-the-art network for CIFAR, we achieved comparable accuracy with 46% less compute and 55% fewer parameters.
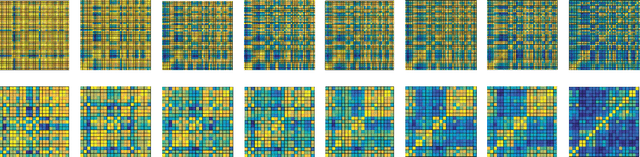
* Published as a conference paper at ICLR 2016. v3: updated ICLR status. v2: Incorporated reviewer's feedback including: Amend Fig. 2 and 5 descriptions to explain that there are no ReLUs within the figures. Fix headings of Table 5 - Fix typo in the sentence at bottom of page 6. Add ref. to Predicting Parameters in Deep Learning. Fix Table 6, GMP-LR and GMP-LR-2x had incorrect numbers of filters
SceneNet: Understanding Real World Indoor Scenes With Synthetic Data
Nov 26, 2015



Scene understanding is a prerequisite to many high level tasks for any automated intelligent machine operating in real world environments. Recent attempts with supervised learning have shown promise in this direction but also highlighted the need for enormous quantity of supervised data --- performance increases in proportion to the amount of data used. However, this quickly becomes prohibitive when considering the manual labour needed to collect such data. In this work, we focus our attention on depth based semantic per-pixel labelling as a scene understanding problem and show the potential of computer graphics to generate virtually unlimited labelled data from synthetic 3D scenes. By carefully synthesizing training data with appropriate noise models we show comparable performance to state-of-the-art RGBD systems on NYUv2 dataset despite using only depth data as input and set a benchmark on depth-based segmentation on SUN RGB-D dataset. Additionally, we offer a route to generating synthesized frame or video data, and understanding of different factors influencing performance gains.
TemplateNet for Depth-Based Object Instance Recognition
Nov 10, 2015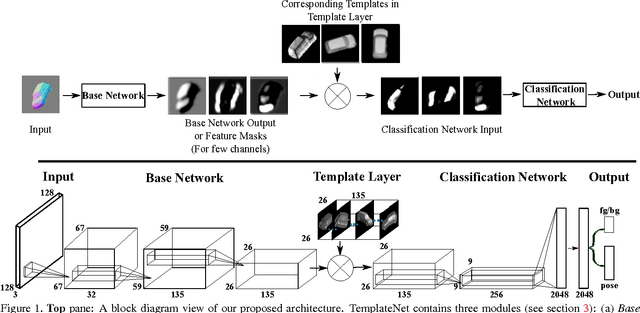
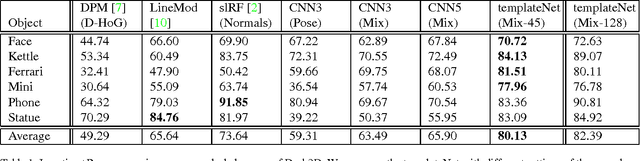
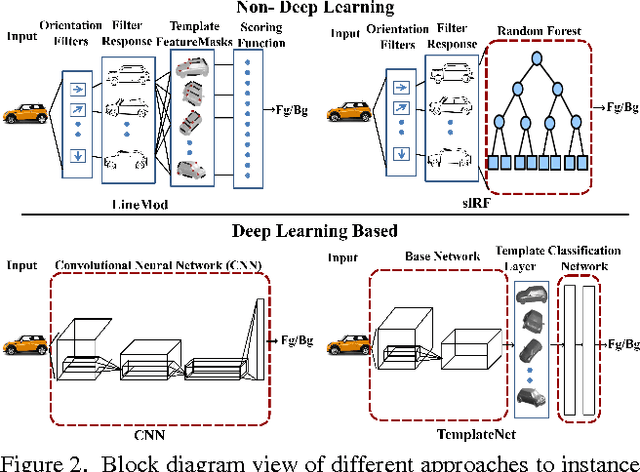
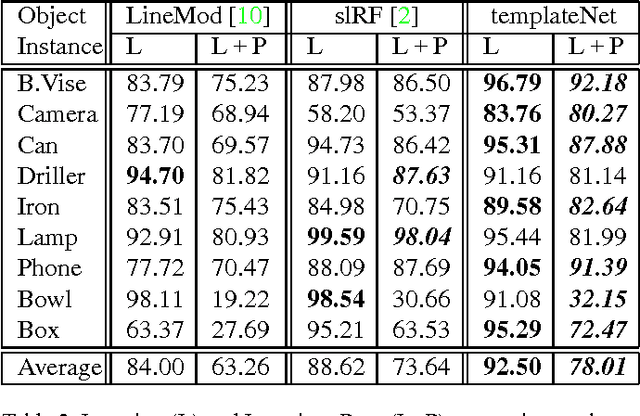
We present a novel deep architecture termed templateNet for depth based object instance recognition. Using an intermediate template layer we exploit prior knowledge of an object's shape to sparsify the feature maps. This has three advantages: (i) the network is better regularised resulting in structured filters; (ii) the sparse feature maps results in intuitive features been learnt which can be visualized as the output of the template layer and (iii) the resulting network achieves state-of-the-art performance. The network benefits from this without any additional parametrization from the template layer. We derive the weight updates needed to efficiently train this network in an end-to-end manner. We benchmark the templateNet for depth based object instance recognition using two publicly available datasets. The datasets present multiple challenges of clutter, large pose variations and similar looking distractors. Through our experiments we show that with the addition of a template layer, a depth based CNN is able to outperform existing state-of-the-art methods in the field.
Symmetry-invariant optimization in deep networks
Nov 07, 2015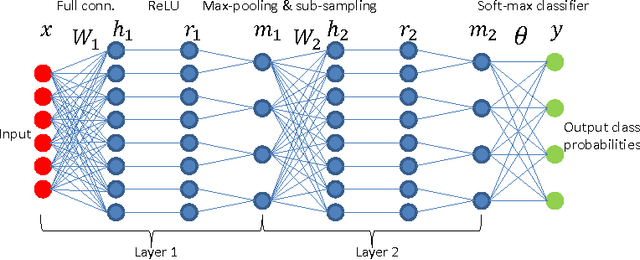

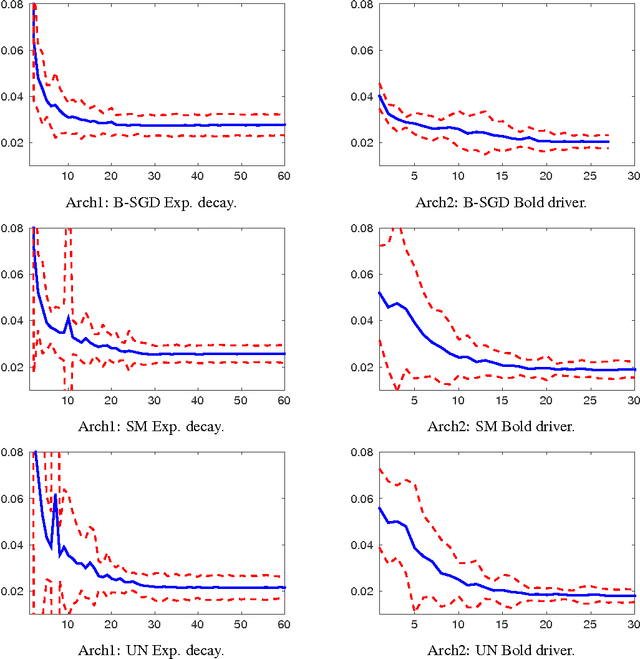
Recent works have highlighted scale invariance or symmetry that is present in the weight space of a typical deep network and the adverse effect that it has on the Euclidean gradient based stochastic gradient descent optimization. In this work, we show that these and other commonly used deep networks, such as those which use a max-pooling and sub-sampling layer, possess more complex forms of symmetry arising from scaling based reparameterization of the network weights. We then propose two symmetry-invariant gradient based weight updates for stochastic gradient descent based learning. Our empirical evidence based on the MNIST dataset shows that these updates improve the test performance without sacrificing the computational efficiency of the weight updates. We also show the results of training with one of the proposed weight updates on an image segmentation problem.
Understanding symmetries in deep networks
Nov 03, 2015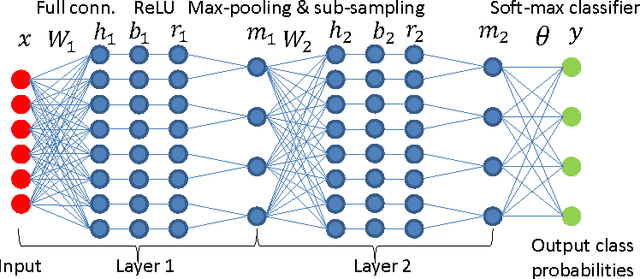

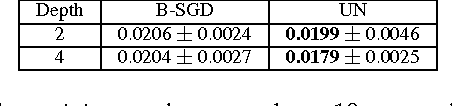

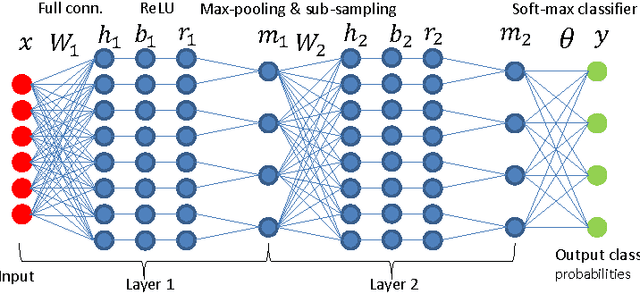
Recent works have highlighted scale invariance or symmetry present in the weight space of a typical deep network and the adverse effect it has on the Euclidean gradient based stochastic gradient descent optimization. In this work, we show that a commonly used deep network, which uses convolution, batch normalization, reLU, max-pooling, and sub-sampling pipeline, possess more complex forms of symmetry arising from scaling-based reparameterization of the network weights. We propose to tackle the issue of the weight space symmetry by constraining the filters to lie on the unit-norm manifold. Consequently, training the network boils down to using stochastic gradient descent updates on the unit-norm manifold. Our empirical evidence based on the MNIST dataset shows that the proposed updates improve the test performance beyond what is achieved with batch normalization and without sacrificing the computational efficiency of the weight updates.
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling
May 27, 2015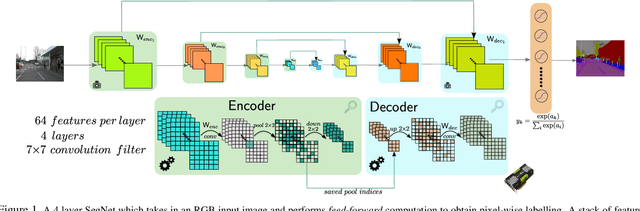
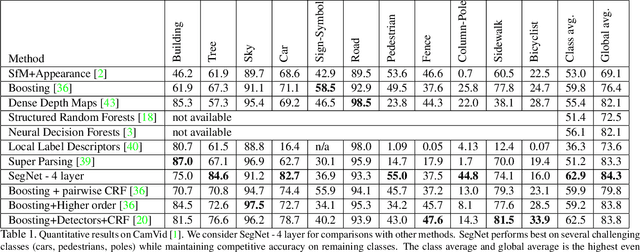


We propose a novel deep architecture, SegNet, for semantic pixel wise image labelling. SegNet has several attractive properties; (i) it only requires forward evaluation of a fully learnt function to obtain smooth label predictions, (ii) with increasing depth, a larger context is considered for pixel labelling which improves accuracy, and (iii) it is easy to visualise the effect of feature activation(s) in the pixel label space at any depth. SegNet is composed of a stack of encoders followed by a corresponding decoder stack which feeds into a soft-max classification layer. The decoders help map low resolution feature maps at the output of the encoder stack to full input image size feature maps. This addresses an important drawback of recent deep learning approaches which have adopted networks designed for object categorization for pixel wise labelling. These methods lack a mechanism to map deep layer feature maps to input dimensions. They resort to ad hoc methods to upsample features, e.g. by replication. This results in noisy predictions and also restricts the number of pooling layers in order to avoid too much upsampling and thus reduces spatial context. SegNet overcomes these problems by learning to map encoder outputs to image pixel labels. We test the performance of SegNet on outdoor RGB scenes from CamVid, KITTI and indoor scenes from the NYU dataset. Our results show that SegNet achieves state-of-the-art performance even without use of additional cues such as depth, video frames or post-processing with CRF models.