 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFed-ZERO: Efficient Zero-shot Personalization with Federated Mixture of Experts
Jun 14, 2023



One of the goals in Federated Learning (FL) is to create personalized models that can adapt to the context of each participating client, while utilizing knowledge from a shared global model. Yet, often, personalization requires a fine-tuning step using clients' labeled data in order to achieve good performance. This may not be feasible in scenarios where incoming clients are fresh and/or have privacy concerns. It, then, remains open how one can achieve zero-shot personalization in these scenarios. We propose a novel solution by using a Mixture-of-Experts (MoE) framework within a FL setup. Our method leverages the diversity of the clients to train specialized experts on different subsets of classes, and a gating function to route the input to the most relevant expert(s). Our gating function harnesses the knowledge of a pretrained model common expert to enhance its routing decisions on-the-fly. As a highlight, our approach can improve accuracy up to 18\% in state of the art FL settings, while maintaining competitive zero-shot performance. In practice, our method can handle non-homogeneous data distributions, scale more efficiently, and improve the state-of-the-art performance on common FL benchmarks.
Analyzing Leakage of Personally Identifiable Information in Language Models
Feb 01, 2023



Language Models (LMs) have been shown to leak information about training data through sentence-level membership inference and reconstruction attacks. Understanding the risk of LMs leaking Personally Identifiable Information (PII) has received less attention, which can be attributed to the false assumption that dataset curation techniques such as scrubbing are sufficient to prevent PII leakage. Scrubbing techniques reduce but do not prevent the risk of PII leakage: in practice scrubbing is imperfect and must balance the trade-off between minimizing disclosure and preserving the utility of the dataset. On the other hand, it is unclear to which extent algorithmic defenses such as differential privacy, designed to guarantee sentence- or user-level privacy, prevent PII disclosure. In this work, we propose (i) a taxonomy of PII leakage in LMs, (ii) metrics to quantify PII leakage, and (iii) attacks showing that PII leakage is a threat in practice. Our taxonomy provides rigorous game-based definitions for PII leakage via black-box extraction, inference, and reconstruction attacks with only API access to an LM. We empirically evaluate attacks against GPT-2 models fine-tuned on three domains: case law, health care, and e-mails. Our main contributions are (i) novel attacks that can extract up to 10 times more PII sequences as existing attacks, (ii) showing that sentence-level differential privacy reduces the risk of PII disclosure but still leaks about 3% of PII sequences, and (iii) a subtle connection between record-level membership inference and PII reconstruction.
TrojanPuzzle: Covertly Poisoning Code-Suggestion Models
Jan 06, 2023



With tools like GitHub Copilot, automatic code suggestion is no longer a dream in software engineering. These tools, based on large language models, are typically trained on massive corpora of code mined from unvetted public sources. As a result, these models are susceptible to data poisoning attacks where an adversary manipulates the model's training or fine-tuning phases by injecting malicious data. Poisoning attacks could be designed to influence the model's suggestions at run time for chosen contexts, such as inducing the model into suggesting insecure code payloads. To achieve this, prior poisoning attacks explicitly inject the insecure code payload into the training data, making the poisoning data detectable by static analysis tools that can remove such malicious data from the training set. In this work, we demonstrate two novel data poisoning attacks, COVERT and TROJANPUZZLE, that can bypass static analysis by planting malicious poisoning data in out-of-context regions such as docstrings. Our most novel attack, TROJANPUZZLE, goes one step further in generating less suspicious poisoning data by never including certain (suspicious) parts of the payload in the poisoned data, while still inducing a model that suggests the entire payload when completing code (i.e., outside docstrings). This makes TROJANPUZZLE robust against signature-based dataset-cleansing methods that identify and filter out suspicious sequences from the training data. Our evaluation against two model sizes demonstrates that both COVERT and TROJANPUZZLE have significant implications for how practitioners should select code used to train or tune code-suggestion models.
Federated Multilingual Models for Medical Transcript Analysis
Nov 04, 2022Federated Learning (FL) is a novel machine learning approach that allows the model trainer to access more data samples, by training the model across multiple decentralized data sources, while data access constraints are in place. Such trained models can achieve significantly higher performance beyond what can be done when trained on a single data source. As part of FL's promises, none of the training data is ever transmitted to any central location, ensuring that sensitive data remains local and private. These characteristics make FL perfectly suited for large-scale applications in healthcare, where a variety of compliance constraints restrict how data may be handled, processed, and stored. Despite the apparent benefits of federated learning, the heterogeneity in the local data distributions pose significant challenges, and such challenges are even more pronounced in the case of multilingual data providers. In this paper we present a federated learning system for training a large-scale multi-lingual model suitable for fine-tuning on downstream tasks such as medical entity tagging. Our work represents one of the first such production-scale systems, capable of training across multiple highly heterogeneous data providers, and achieving levels of accuracy that could not be otherwise achieved by using central training with public data. Finally, we show that the global model performance can be further improved by a training step performed locally.
Synthetic Text Generation with Differential Privacy: A Simple and Practical Recipe
Oct 25, 2022



Privacy concerns have attracted increasing attention in data-driven products and services. Existing legislation forbids arbitrary processing of personal data collected from individuals. Generating synthetic versions of such data with a formal privacy guarantee such as differential privacy (DP) is considered to be a solution to address privacy concerns. In this direction, we show a simple, practical, and effective recipe in the text domain: simply fine-tuning a generative language model with DP allows us to generate useful synthetic text while mitigating privacy concerns. Through extensive empirical analyses, we demonstrate that our method produces synthetic data that is competitive in terms of utility with its non-private counterpart and meanwhile provides strong protection against potential privacy leakages.
Privacy Leakage in Text Classification: A Data Extraction Approach
Jun 09, 2022
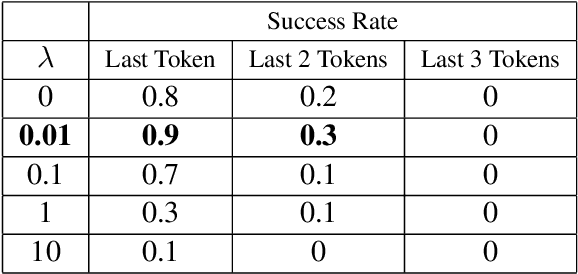
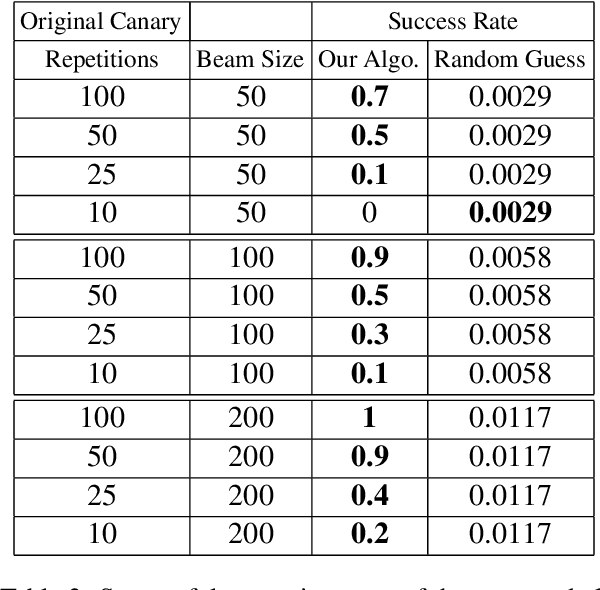
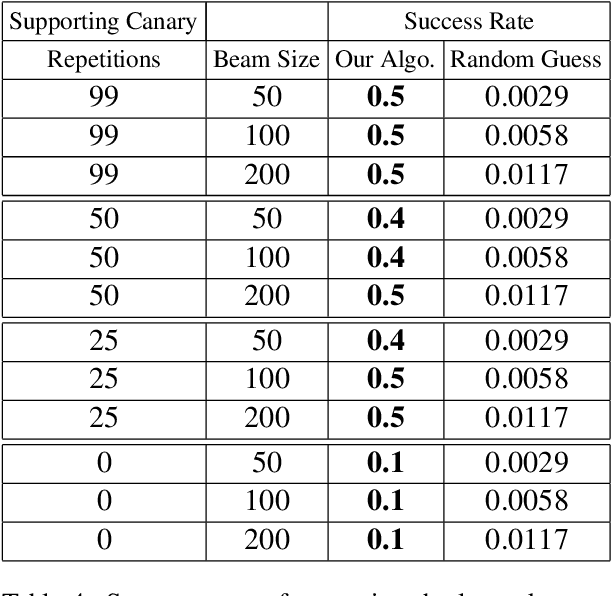
Recent work has demonstrated the successful extraction of training data from generative language models. However, it is not evident whether such extraction is feasible in text classification models since the training objective is to predict the class label as opposed to next-word prediction. This poses an interesting challenge and raises an important question regarding the privacy of training data in text classification settings. Therefore, we study the potential privacy leakage in the text classification domain by investigating the problem of unintended memorization of training data that is not pertinent to the learning task. We propose an algorithm to extract missing tokens of a partial text by exploiting the likelihood of the class label provided by the model. We test the effectiveness of our algorithm by inserting canaries into the training set and attempting to extract tokens in these canaries post-training. In our experiments, we demonstrate that successful extraction is possible to some extent. This can also be used as an auditing strategy to assess any potential unauthorized use of personal data without consent.
Heterogeneous Ensemble Knowledge Transfer for Training Large Models in Federated Learning
Apr 27, 2022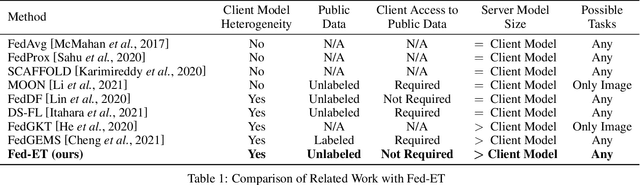
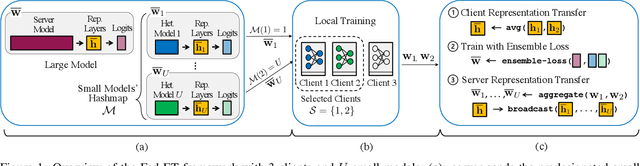
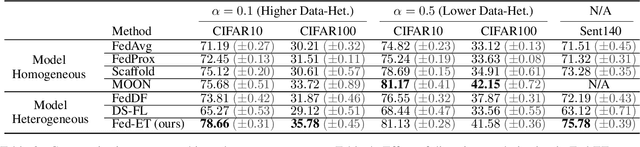
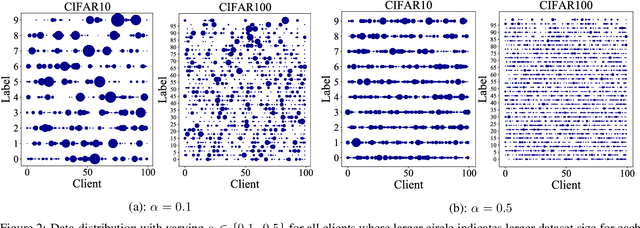
Federated learning (FL) enables edge-devices to collaboratively learn a model without disclosing their private data to a central aggregating server. Most existing FL algorithms require models of identical architecture to be deployed across the clients and server, making it infeasible to train large models due to clients' limited system resources. In this work, we propose a novel ensemble knowledge transfer method named Fed-ET in which small models (different in architecture) are trained on clients, and used to train a larger model at the server. Unlike in conventional ensemble learning, in FL the ensemble can be trained on clients' highly heterogeneous data. Cognizant of this property, Fed-ET uses a weighted consensus distillation scheme with diversity regularization that efficiently extracts reliable consensus from the ensemble while improving generalization by exploiting the diversity within the ensemble. We show the generalization bound for the ensemble of weighted models trained on heterogeneous datasets that supports the intuition of Fed-ET. Our experiments on image and language tasks show that Fed-ET significantly outperforms other state-of-the-art FL algorithms with fewer communicated parameters, and is also robust against high data-heterogeneity.
FLUTE: A Scalable, Extensible Framework for High-Performance Federated Learning Simulations
Mar 25, 2022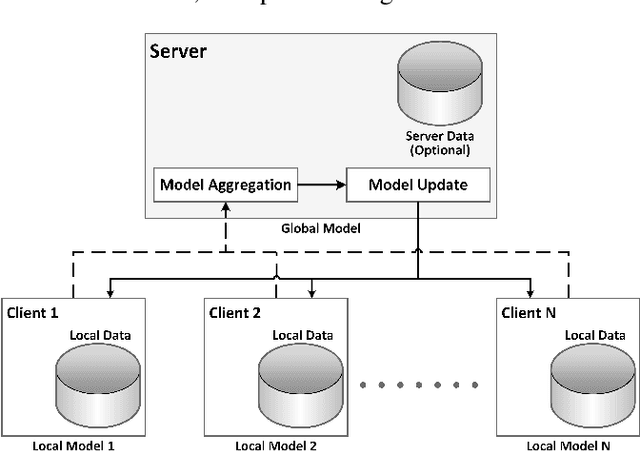
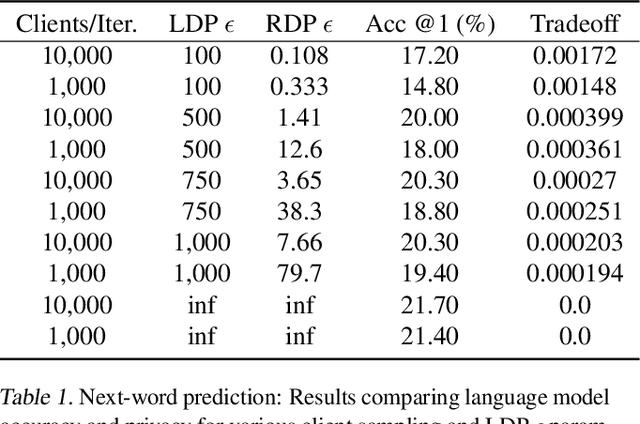
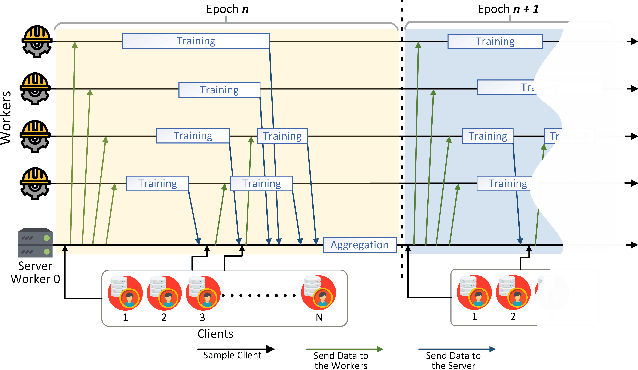
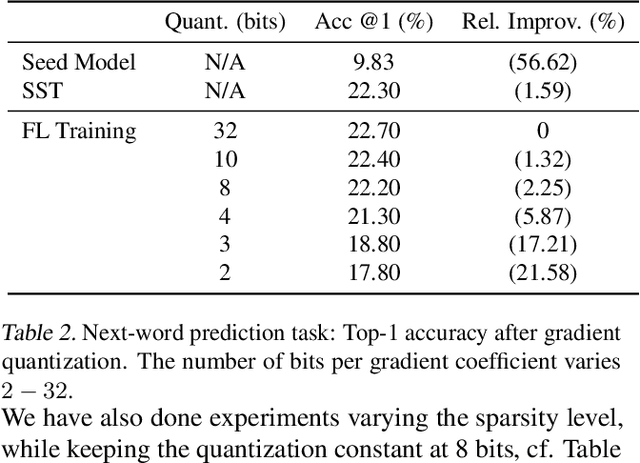
In this paper we introduce "Federated Learning Utilities and Tools for Experimentation" (FLUTE), a high-performance open source platform for federated learning research and offline simulations. The goal of FLUTE is to enable rapid prototyping and simulation of new federated learning algorithms at scale, including novel optimization, privacy, and communications strategies. We describe the architecture of FLUTE, enabling arbitrary federated modeling schemes to be realized, we compare the platform with other state-of-the-art platforms, and we describe available features of FLUTE for experimentation in core areas of active research, such as optimization, privacy and scalability. We demonstrate the effectiveness of the platform with a series of experiments for text prediction and speech recognition, including the addition of differential privacy, quantization, scaling and a variety of optimization and federation approaches.
UserIdentifier: Implicit User Representations for Simple and Effective Personalized Sentiment Analysis
Oct 01, 2021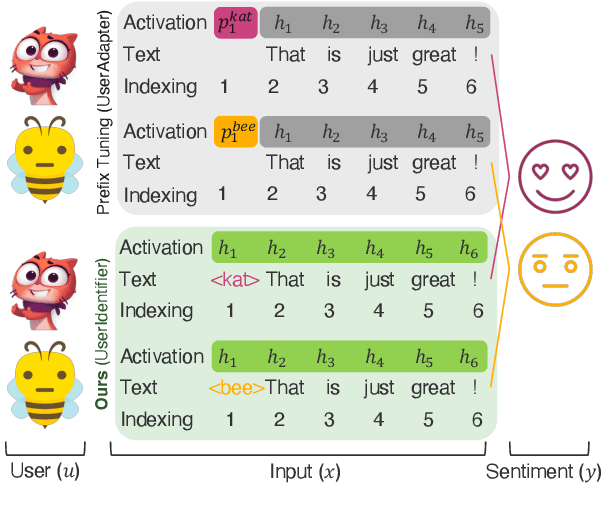
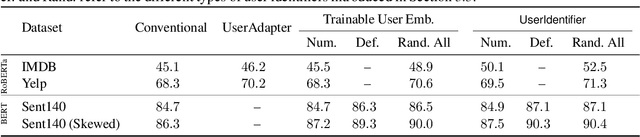
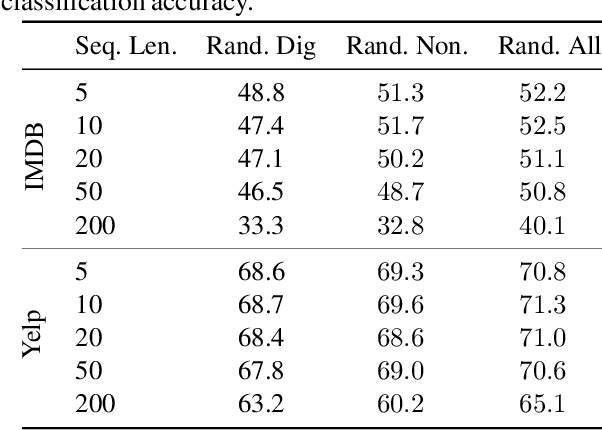
Global models are trained to be as generalizable as possible, with user invariance considered desirable since the models are shared across multitudes of users. As such, these models are often unable to produce personalized responses for individual users, based on their data. Contrary to widely-used personalization techniques based on few-shot learning, we propose UserIdentifier, a novel scheme for training a single shared model for all users. Our approach produces personalized responses by adding fixed, non-trainable user identifiers to the input data. We empirically demonstrate that this proposed method outperforms the prefix-tuning based state-of-the-art approach by up to 13%, on a suite of sentiment analysis datasets. We also show that, unlike prior work, this method needs neither any additional model parameters nor any extra rounds of few-shot fine-tuning.
On Privacy and Confidentiality of Communications in Organizational Graphs
May 27, 2021
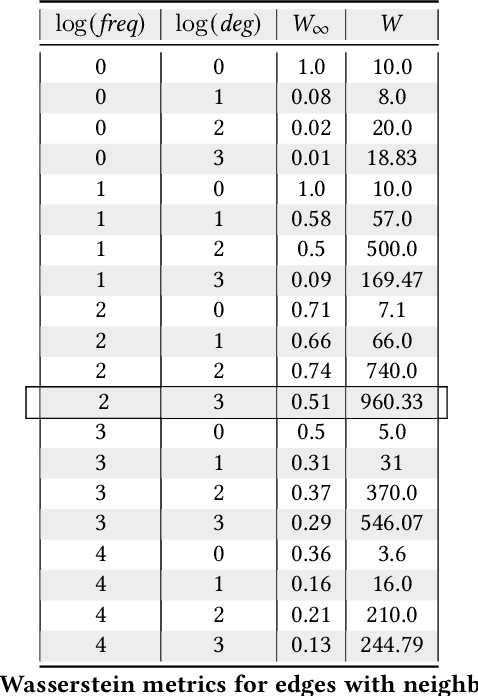
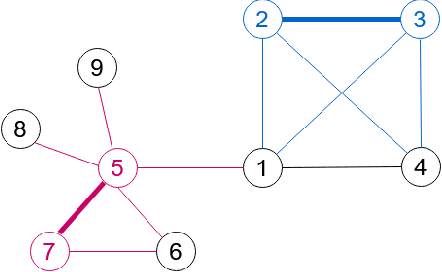
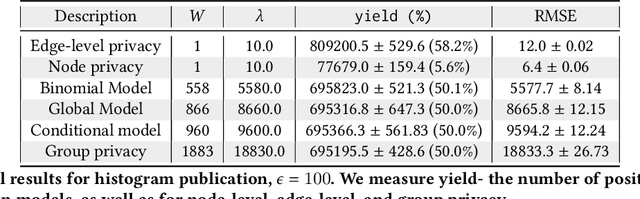
Machine learned models trained on organizational communication data, such as emails in an enterprise, carry unique risks of breaching confidentiality, even if the model is intended only for internal use. This work shows how confidentiality is distinct from privacy in an enterprise context, and aims to formulate an approach to preserving confidentiality while leveraging principles from differential privacy. The goal is to perform machine learning tasks, such as learning a language model or performing topic analysis, using interpersonal communications in the organization, while not learning about confidential information shared in the organization. Works that apply differential privacy techniques to natural language processing tasks usually assume independently distributed data, and overlook potential correlation among the records. Ignoring this correlation results in a fictional promise of privacy. Naively extending differential privacy techniques to focus on group privacy instead of record-level privacy is a straightforward approach to mitigate this issue. This approach, although providing a more realistic privacy-guarantee, is over-cautious and severely impacts model utility. We show this gap between these two extreme measures of privacy over two language tasks, and introduce a middle-ground solution. We propose a model that captures the correlation in the social network graph, and incorporates this correlation in the privacy calculations through Pufferfish privacy principles.