 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Generative Models are not Robust
Jun 04, 2019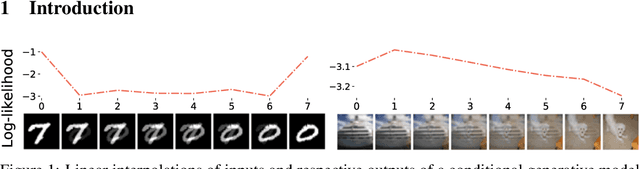


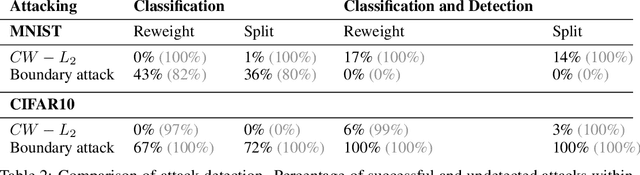
Class-conditional generative models are an increasingly popular approach to achieve robust classification. They are a natural choice to solve discriminative tasks in a robust manner as they jointly optimize for predictive performance and accurate modeling of the input distribution. In this work, we investigate robust classification with likelihood-based conditional generative models from a theoretical and practical perspective. Our theoretical result reveals that it is impossible to guarantee detectability of adversarial examples even for near-optimal generative classifiers. Experimentally, we show that naively trained conditional generative models have poor discriminative performance, making them unsuitable for classification. This is related to overlooked issues with training conditional generative models and we show methods to improve performance. Finally, we analyze the robustness of our proposed conditional generative models on MNIST and CIFAR10. While we are able to train robust models for MNIST, robustness completely breaks down on CIFAR10. This lack of robustness is related to various undesirable model properties maximum likelihood fails to penalize. Our results indicate that likelihood may fundamentally be at odds with robust classification on challenging problems.
High-Level Perceptual Similarity is Enabled by Learning Diverse Tasks
Mar 26, 2019
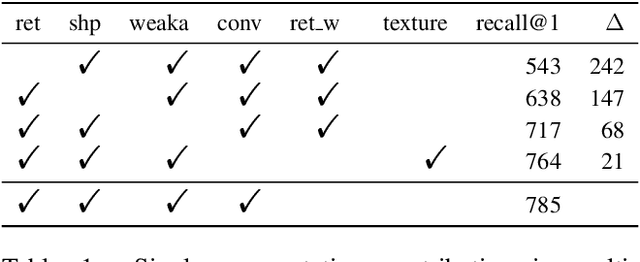
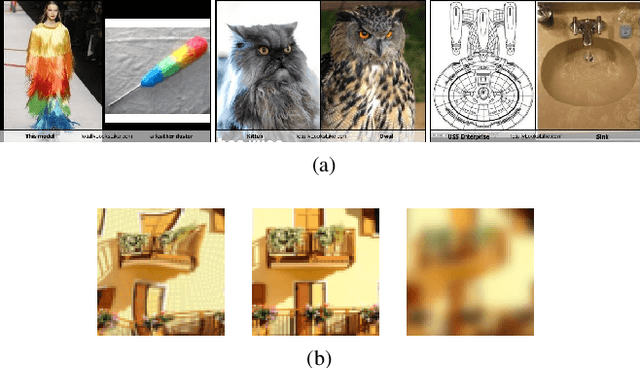

Predicting human perceptual similarity is a challenging subject of ongoing research. The visual process underlying this aspect of human vision is thought to employ multiple different levels of visual analysis (shapes, objects, texture, layout, color, etc). In this paper, we postulate that the perception of image similarity is not an explicitly learned capability, but rather one that is a byproduct of learning others. This claim is supported by leveraging representations learned from a diverse set of visual tasks and using them jointly to predict perceptual similarity. This is done via simple feature concatenation, without any further learning. Nevertheless, experiments performed on the challenging Totally-Looks-Like (TLL) benchmark significantly surpass recent baselines, closing much of the reported gap towards prediction of human perceptual similarity. We provide an analysis of these results and discuss them in a broader context of emergent visual capabilities and their implications on the course of machine-vision research.
Learning Latent Subspaces in Variational Autoencoders
Dec 14, 2018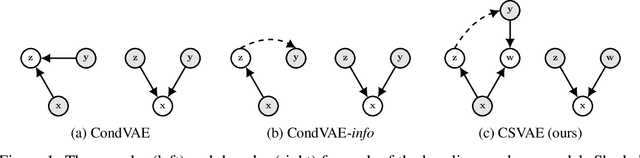
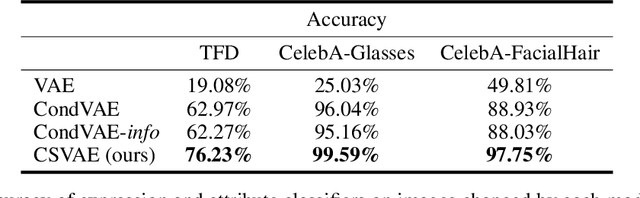


Variational autoencoders (VAEs) are widely used deep generative models capable of learning unsupervised latent representations of data. Such representations are often difficult to interpret or control. We consider the problem of unsupervised learning of features correlated to specific labels in a dataset. We propose a VAE-based generative model which we show is capable of extracting features correlated to binary labels in the data and structuring it in a latent subspace which is easy to interpret. Our model, the Conditional Subspace VAE (CSVAE), uses mutual information minimization to learn a low-dimensional latent subspace associated with each label that can easily be inspected and independently manipulated. We demonstrate the utility of the learned representations for attribute manipulation tasks on both the Toronto Face and CelebA datasets.
Excessive Invariance Causes Adversarial Vulnerability
Nov 01, 2018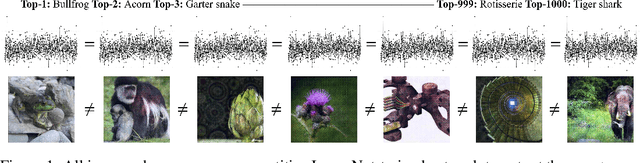

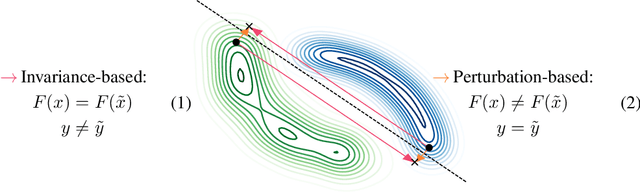

Despite their impressive performance, deep neural networks exhibit striking failures on out-of-distribution inputs. One core idea of adversarial example research is to reveal neural network errors under such distribution shift. We decompose these errors into two complementary sources: sensitivity and invariance. We show deep networks are not only too sensitive to task-irrelevant changes of their input, as is well-known from epsilon-adversarial examples, but are also too invariant to a wide range of task-relevant changes, thus making vast regions in input space vulnerable to adversarial attacks. After identifying this excessive invariance, we propose the usage of bijective deep networks to enable access to all variations. We introduce metameric sampling as an analytic attack for these networks, requiring no optimization, and show that it uncovers large subspaces of misclassified inputs. Then we apply these networks to MNIST and ImageNet and show that one can manipulate the class-specific content of almost any image without changing the hidden activations. Further, we extend the standard cross-entropy loss to strengthen the model against such manipulations via an information-theoretic analysis, providing the first approach tailored explicitly to overcome invariance-based vulnerability. We conclude by empirically illustrating its ability to control undesirable class-specific invariance, showing promise to overcome one major cause for adversarial examples.
Neural Guided Constraint Logic Programming for Program Synthesis
Oct 26, 2018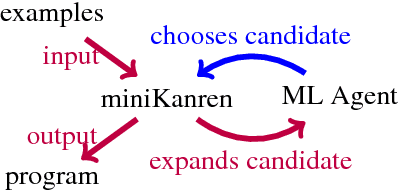
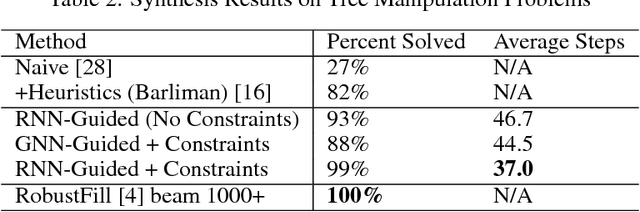
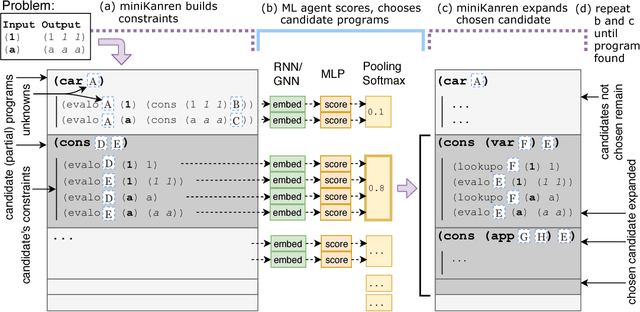
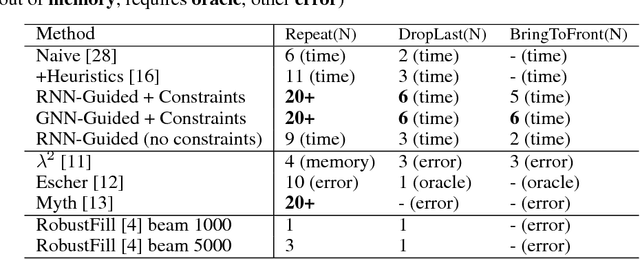
Synthesizing programs using example input/outputs is a classic problem in artificial intelligence. We present a method for solving Programming By Example (PBE) problems by using a neural model to guide the search of a constraint logic programming system called miniKanren. Crucially, the neural model uses miniKanren's internal representation as input; miniKanren represents a PBE problem as recursive constraints imposed by the provided examples. We explore Recurrent Neural Network and Graph Neural Network models. We contribute a modified miniKanren, drivable by an external agent, available at https://github.com/xuexue/neuralkanren. We show that our neural-guided approach using constraints can synthesize programs faster in many cases, and importantly, can generalize to larger problems.
Learning Adversarially Fair and Transferable Representations
Oct 22, 2018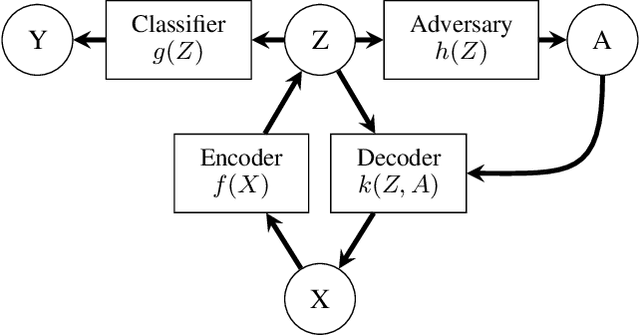
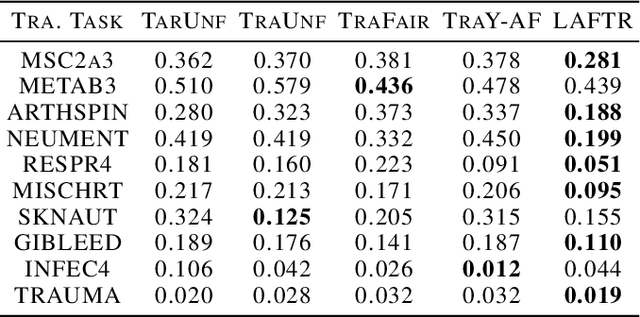
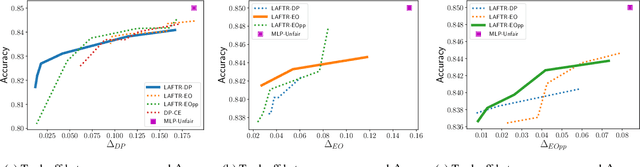
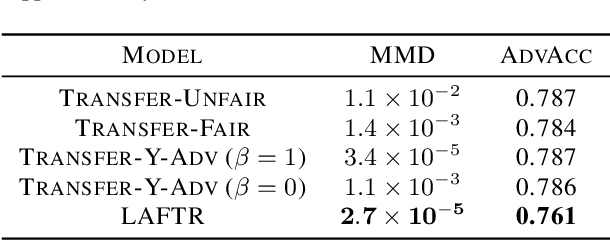
In this paper, we advocate for representation learning as the key to mitigating unfair prediction outcomes downstream. Motivated by a scenario where learned representations are used by third parties with unknown objectives, we propose and explore adversarial representation learning as a natural method of ensuring those parties act fairly. We connect group fairness (demographic parity, equalized odds, and equal opportunity) to different adversarial objectives. Through worst-case theoretical guarantees and experimental validation, we show that the choice of this objective is crucial to fair prediction. Furthermore, we present the first in-depth experimental demonstration of fair transfer learning and demonstrate empirically that our learned representations admit fair predictions on new tasks while maintaining utility, an essential goal of fair representation learning.
Understanding the Origins of Bias in Word Embeddings
Oct 08, 2018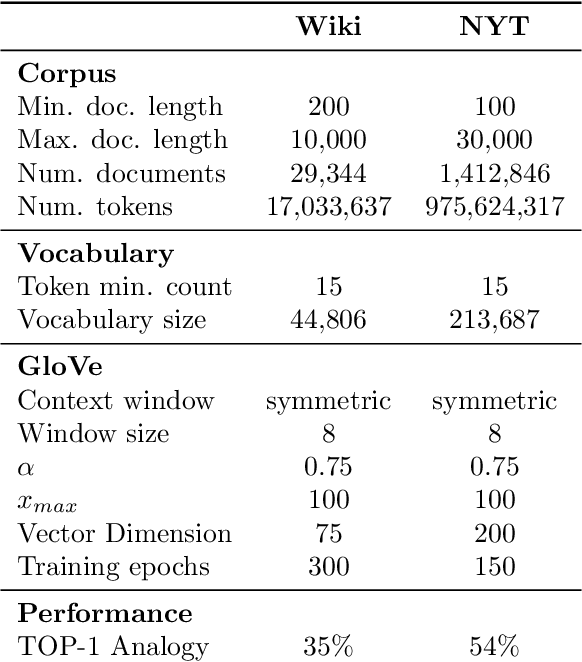
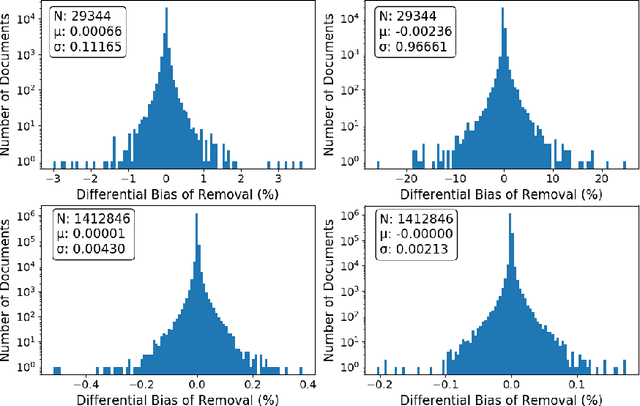
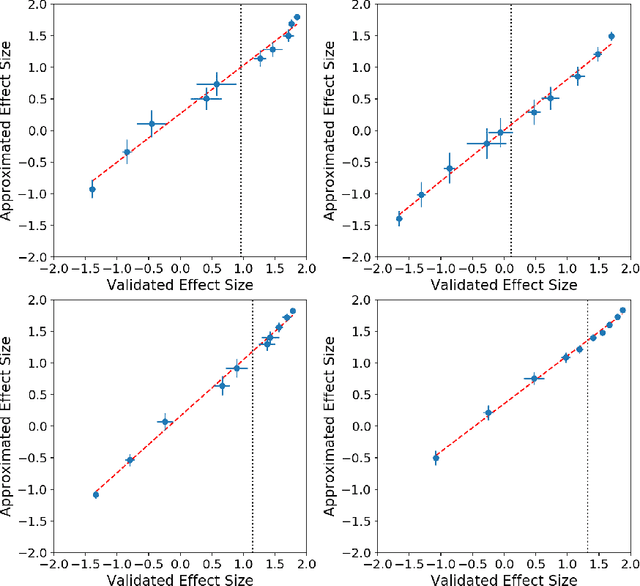
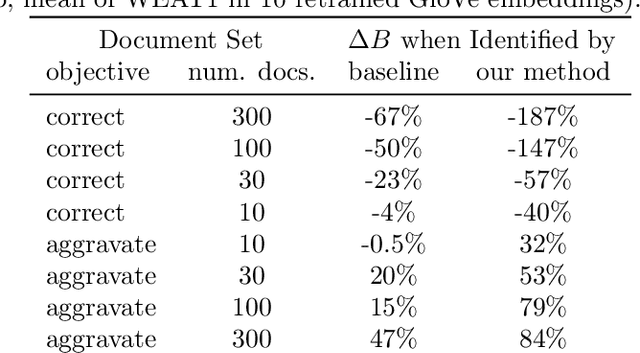
The power of machine learning systems not only promises great technical progress, but risks societal harm. As a recent example, researchers have shown that popular word embedding algorithms exhibit stereotypical biases, such as gender bias. The widespread use of these algorithms in machine learning systems, from automated translation services to curriculum vitae scanners, can amplify stereotypes in important contexts. Although methods have been developed to measure these biases and alter word embeddings to mitigate their biased representations, there is a lack of understanding in how word embedding bias depends on the training data. In this work, we develop a technique for understanding the origins of bias in word embeddings. Given a word embedding trained on a corpus, our method identifies how perturbing the corpus will affect the bias of the resulting embedding. This can be used to trace the origins of word embedding bias back to the original training documents. Using our method, one can investigate trends in the bias of the underlying corpus and identify subsets of documents whose removal would most reduce bias. We demonstrate our techniques on both a New York Times and Wikipedia corpus and find that our influence function-based approximations are extremely accurate.
Fairness Through Causal Awareness: Learning Latent-Variable Models for Biased Data
Sep 10, 2018
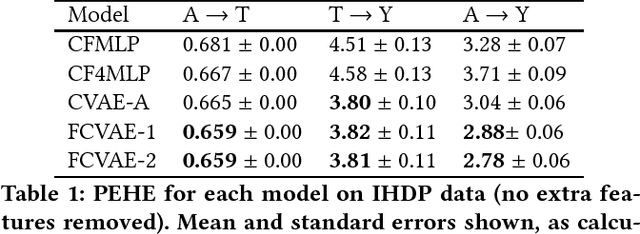
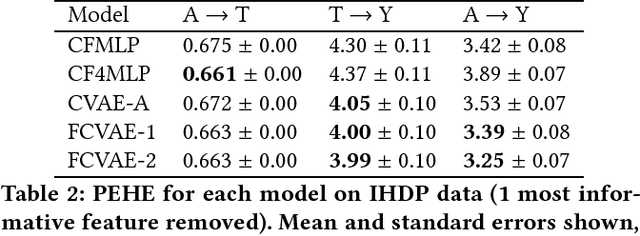

How do we learn from biased data? Historical datasets often reflect historical prejudices; sensitive or protected attributes may affect the observed treatments and outcomes. Classification algorithms tasked with predicting outcomes accurately from these datasets tend to replicate these biases. We advocate a causal modeling approach to learning from biased data and reframe fair classification as an intervention problem. We propose a causal model in which the sensitive attribute confounds both the treatment and the outcome. Building on prior work in deep learning and generative modeling, we describe how to learn the parameters of this causal model from observational data alone, even in the presence of unobserved confounders. We show experimentally that fairness-aware causal modeling provides better estimates of the causal effects between the sensitive attribute, the treatment, and the outcome. We further present evidence that estimating these causal effects can help us to learn policies which are both more accurate and fair, when presented with a historically biased dataset.
Predict Responsibly: Improving Fairness and Accuracy by Learning to Defer
Sep 07, 2018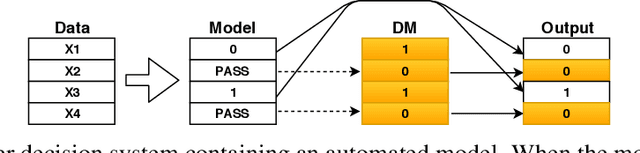
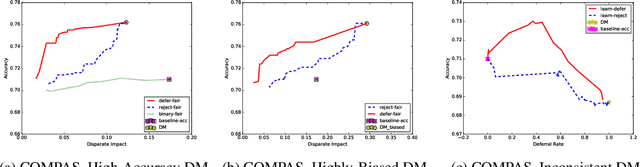
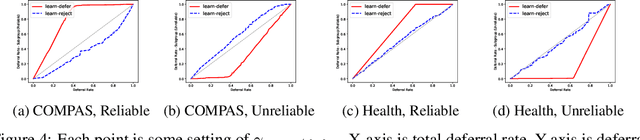
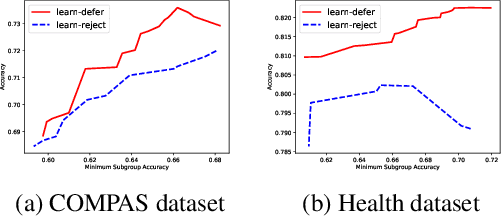
In many machine learning applications, there are multiple decision-makers involved, both automated and human. The interaction between these agents often goes unaddressed in algorithmic development. In this work, we explore a simple version of this interaction with a two-stage framework containing an automated model and an external decision-maker. The model can choose to say "Pass", and pass the decision downstream, as explored in rejection learning. We extend this concept by proposing "learning to defer", which generalizes rejection learning by considering the effect of other agents in the decision-making process. We propose a learning algorithm which accounts for potential biases held by external decision-makers in a system. Experiments demonstrate that learning to defer can make systems not only more accurate but also less biased. Even when working with inconsistent or biased users, we show that deferring models still greatly improve the accuracy and/or fairness of the entire system.
Reviving and Improving Recurrent Back-Propagation
Aug 13, 2018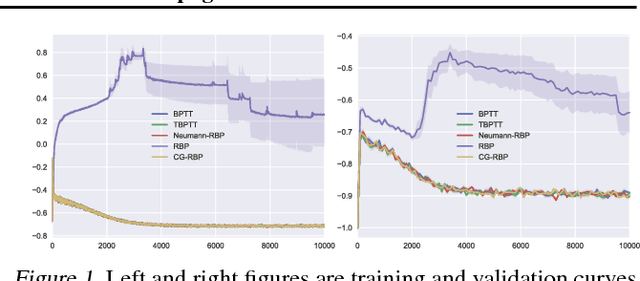
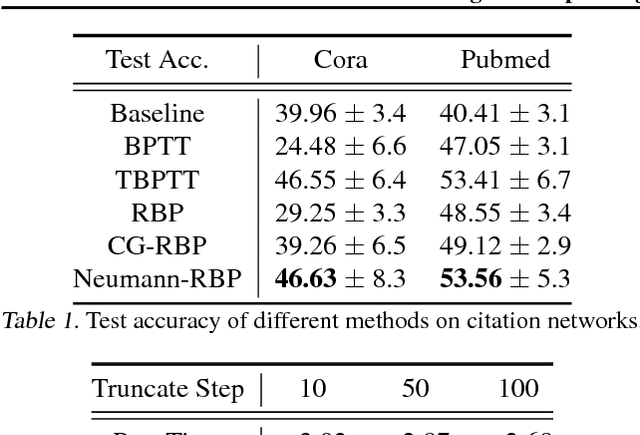
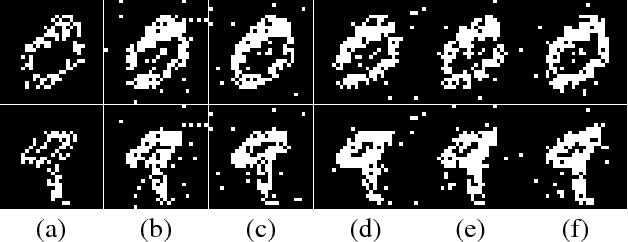

In this paper, we revisit the recurrent back-propagation (RBP) algorithm, discuss the conditions under which it applies as well as how to satisfy them in deep neural networks. We show that RBP can be unstable and propose two variants based on conjugate gradient on the normal equations (CG-RBP) and Neumann series (Neumann-RBP). We further investigate the relationship between Neumann-RBP and back propagation through time (BPTT) and its truncated version (TBPTT). Our Neumann-RBP has the same time complexity as TBPTT but only requires constant memory, whereas TBPTT's memory cost scales linearly with the number of truncation steps. We examine all RBP variants along with BPTT and TBPTT in three different application domains: associative memory with continuous Hopfield networks, document classification in citation networks using graph neural networks and hyperparameter optimization for fully connected networks. All experiments demonstrate that RBPs, especially the Neumann-RBP variant, are efficient and effective for optimizing convergent recurrent neural networks.