 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaGNET: Uniform Sampling from Deep Generative Network Manifolds Without Retraining
Oct 18, 2021
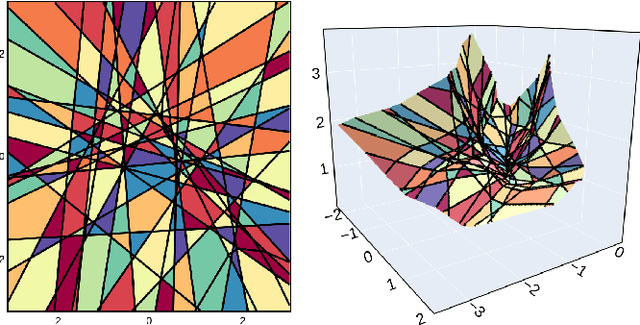
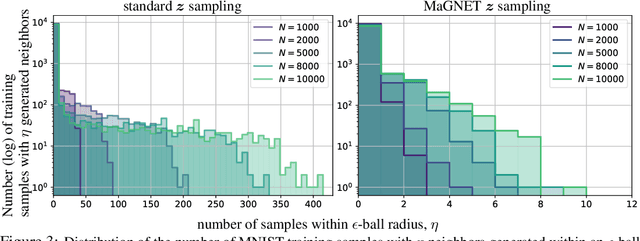
Deep Generative Networks (DGNs) are extensively employed in Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and their variants to approximate the data manifold, and data distribution on that manifold. However, training samples are often obtained based on preferences, costs, or convenience producing artifacts in the empirical data distribution e.g., the large fraction of smiling faces in the CelebA dataset or the large fraction of dark-haired individuals in FFHQ. These inconsistencies will be reproduced when sampling from the trained DGN, which has far-reaching potential implications for fairness, data augmentation, anomaly detection, domain adaptation, and beyond. In response, we develop a differential geometry based sampler -- coined MaGNET -- that, given any trained DGN, produces samples that are uniformly distributed on the learned manifold. We prove theoretically and empirically that our technique produces a uniform distribution on the manifold regardless of the training set distribution. We perform a range of experiments on various datasets and DGNs. One of them considers the state-of-the-art StyleGAN2 trained on FFHQ dataset, where uniform sampling via MaGNET increases distribution precision and recall by 4.1% & 3.0% and decreases gender bias by 41.2%, without requiring labels or retraining.
Thermal Image Processing via Physics-Inspired Deep Networks
Aug 25, 2021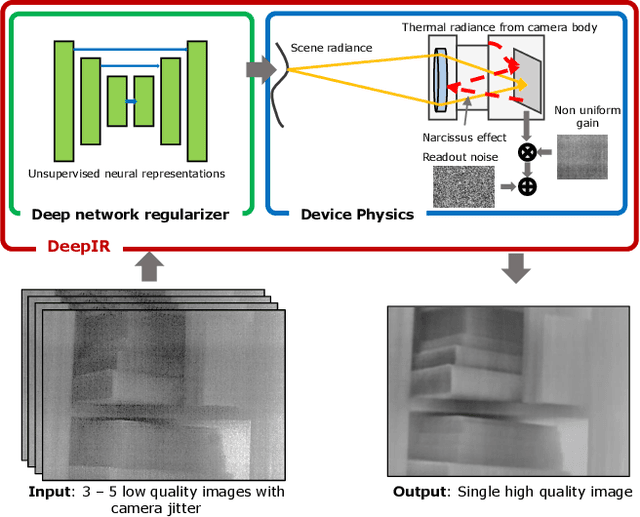



We introduce DeepIR, a new thermal image processing framework that combines physically accurate sensor modeling with deep network-based image representation. Our key enabling observations are that the images captured by thermal sensors can be factored into slowly changing, scene-independent sensor non-uniformities (that can be accurately modeled using physics) and a scene-specific radiance flux (that is well-represented using a deep network-based regularizer). DeepIR requires neither training data nor periodic ground-truth calibration with a known black body target--making it well suited for practical computer vision tasks. We demonstrate the power of going DeepIR by developing new denoising and super-resolution algorithms that exploit multiple images of the scene captured with camera jitter. Simulated and real data experiments demonstrate that DeepIR can perform high-quality non-uniformity correction with as few as three images, achieving a 10dB PSNR improvement over competing approaches.
Double Descent and Other Interpolation Phenomena in GANs
Jun 07, 2021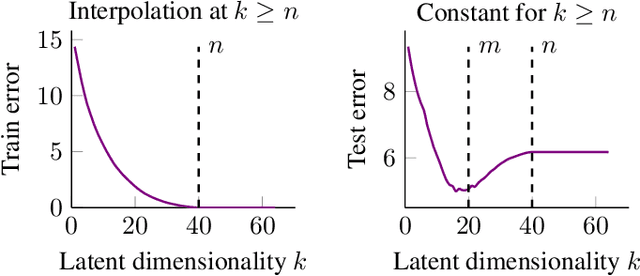
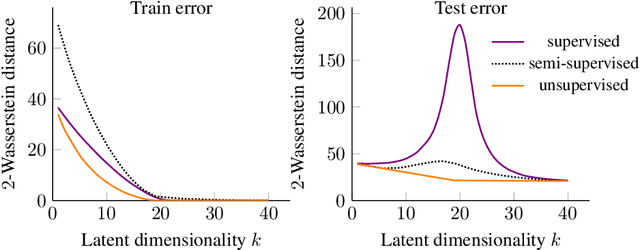
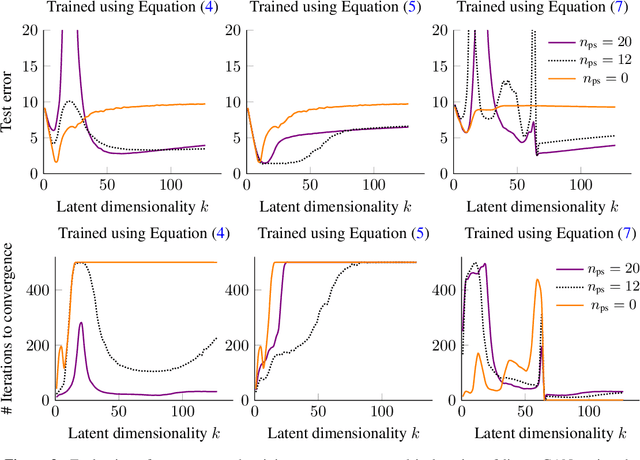
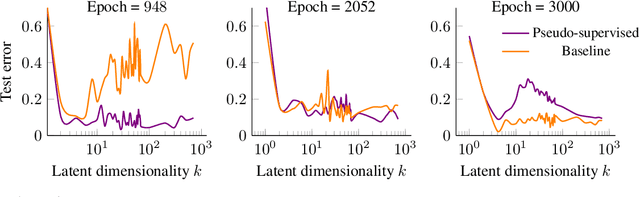
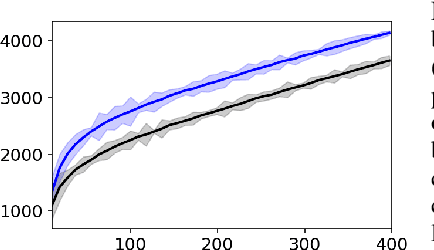
We study overparameterization in generative adversarial networks (GANs) that can interpolate the training data. We show that overparameterization can improve generalization performance and accelerate the training process. We study the generalization error as a function of latent space dimension and identify two main behaviors, depending on the learning setting. First, we show that overparameterized generative models that learn distributions by minimizing a metric or $f$-divergence do not exhibit double descent in generalization errors; specifically, all the interpolating solutions achieve the same generalization error. Second, we develop a new pseudo-supervised learning approach for GANs where the training utilizes pairs of fabricated (noise) inputs in conjunction with real output samples. Our pseudo-supervised setting exhibits double descent (and in some cases, triple descent) of generalization errors. We combine pseudo-supervision with overparameterization (i.e., overly large latent space dimension) to accelerate training while performing better, or close to, the generalization performance without pseudo-supervision. While our analysis focuses mostly on linear GANs, we also apply important insights for improving generalization of nonlinear, multilayer GANs.
Math Operation Embeddings for Open-ended Solution Analysis and Feedback
Apr 25, 2021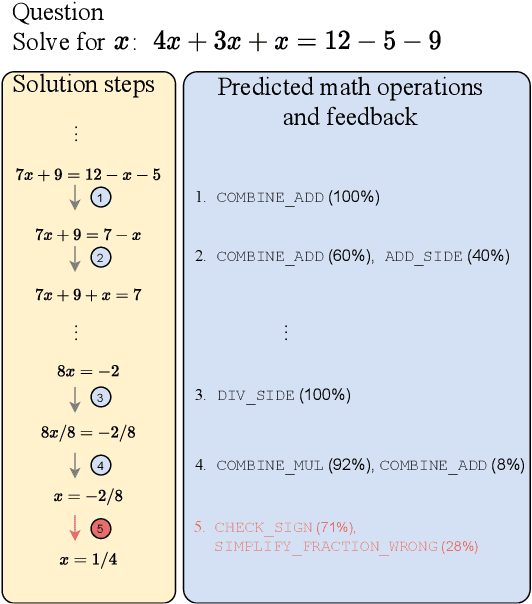


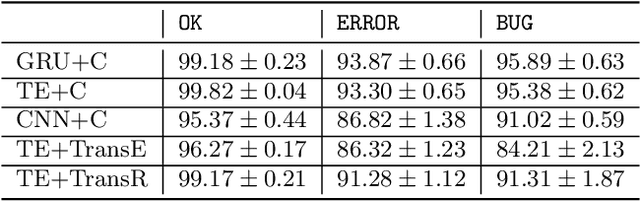
Feedback on student answers and even during intermediate steps in their solutions to open-ended questions is an important element in math education. Such feedback can help students correct their errors and ultimately lead to improved learning outcomes. Most existing approaches for automated student solution analysis and feedback require manually constructing cognitive models and anticipating student errors for each question. This process requires significant human effort and does not scale to most questions used in homework and practices that do not come with this information. In this paper, we analyze students' step-by-step solution processes to equation solving questions in an attempt to scale up error diagnostics and feedback mechanisms developed for a small number of questions to a much larger number of questions. Leveraging a recent math expression encoding method, we represent each math operation applied in solution steps as a transition in the math embedding vector space. We use a dataset that contains student solution steps in the Cognitive Tutor system to learn implicit and explicit representations of math operations. We explore whether these representations can i) identify math operations a student intends to perform in each solution step, regardless of whether they did it correctly or not, and ii) select the appropriate feedback type for incorrect steps. Experimental results show that our learned math operation representations generalize well across different data distributions.
Fast Jacobian-Vector Product for Deep Networks
Apr 01, 2021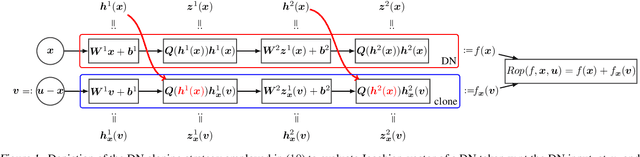
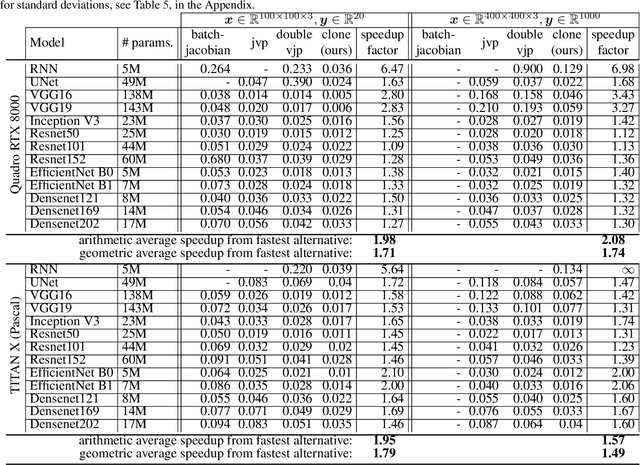
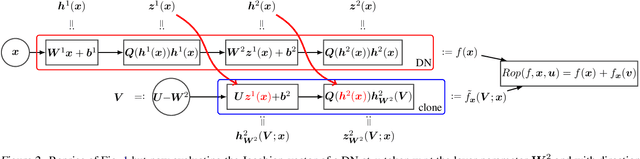
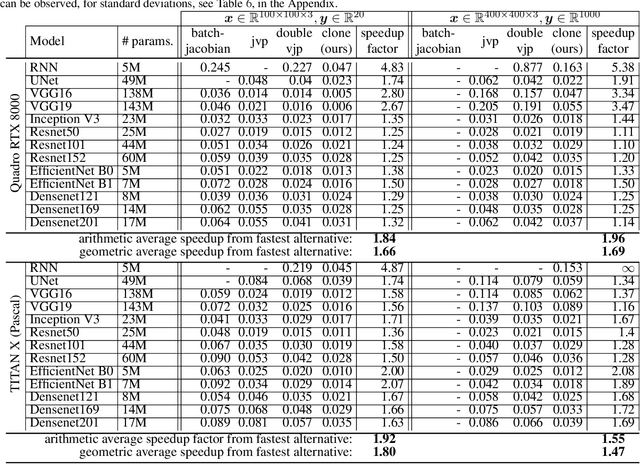
Jacobian-vector products (JVPs) form the backbone of many recent developments in Deep Networks (DNs), with applications including faster constrained optimization, regularization with generalization guarantees, and adversarial example sensitivity assessments. Unfortunately, JVPs are computationally expensive for real world DN architectures and require the use of automatic differentiation to avoid manually adapting the JVP program when changing the DN architecture. We propose a novel method to quickly compute JVPs for any DN that employ Continuous Piecewise Affine (e.g., leaky-ReLU, max-pooling, maxout, etc.) nonlinearities. We show that our technique is on average $2\times$ faster than the fastest alternative over $13$ DN architectures and across various hardware. In addition, our solution does not require automatic differentiation and is thus easy to deploy in software, requiring only the modification of a few lines of codes that do not depend on the DN architecture.
Max-Affine Spline Insights Into Deep Network Pruning
Jan 07, 2021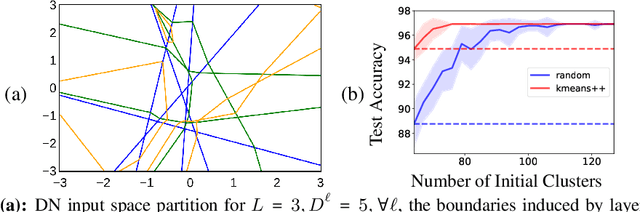
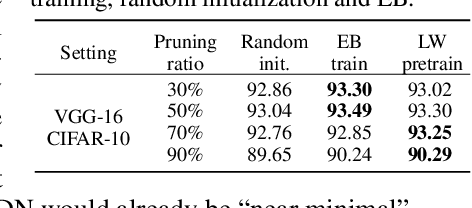
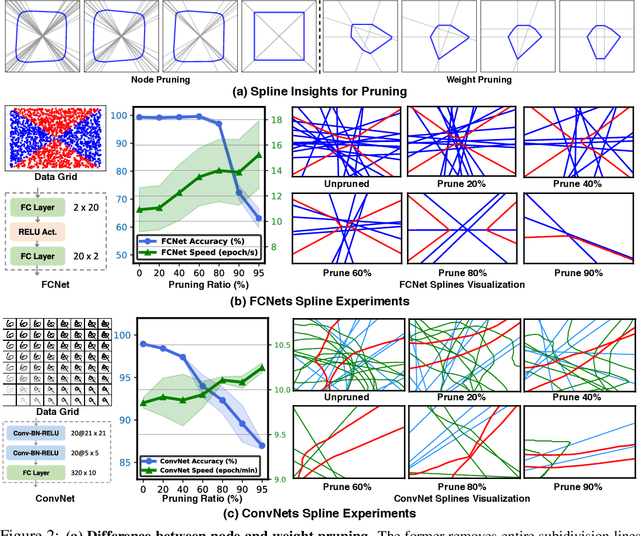
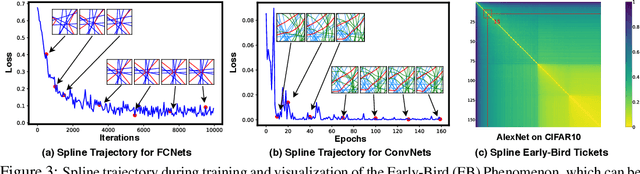
In this paper, we study the importance of pruning in Deep Networks (DNs) and motivate it based on the current absence of data aware weight initialization. Current DN initializations, focusing primarily at maintaining first order statistics of the feature maps through depth, force practitioners to overparametrize a model in order to reach high performances. This overparametrization can then be pruned a posteriori, leading to a phenomenon known as "winning tickets". However, the pruning literature still relies on empirical investigations, lacking a theoretical understanding of (1) how pruning affects the decision boundary, (2) how to interpret pruning, (3) how to design principled pruning techniques, and (4) how to theoretically study pruning. To tackle those questions, we propose to employ recent advances in the theoretical analysis of Continuous Piecewise Affine (CPA) DNs. From this viewpoint, we can study the DNs' input space partitioning and detect the early-bird (EB) phenomenon, guide practitioners by identifying when to stop the first training step, provide interpretability into current pruning techniques, and develop a principled pruning criteria towards efficient DN training. Finally, we conduct extensive experiments to show the effectiveness of the proposed spline pruning criteria in terms of both layerwise and global pruning over state-of-the-art pruning methods.
SASSI -- Super-Pixelated Adaptive Spatio-Spectral Imaging
Dec 28, 2020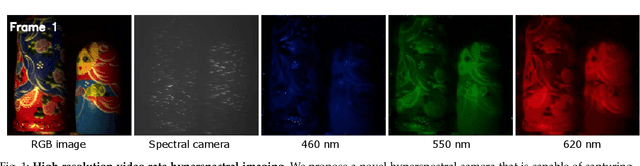
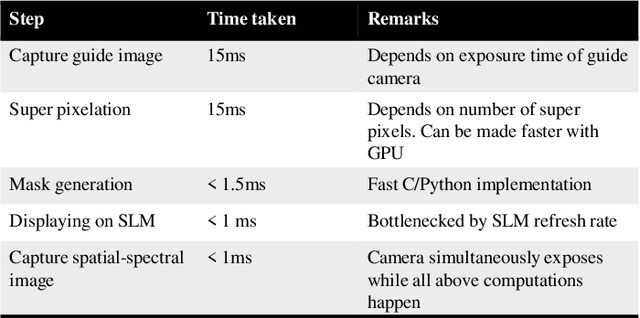


We introduce a novel video-rate hyperspectral imager with high spatial, and temporal resolutions. Our key hypothesis is that spectral profiles of pixels in a super-pixel of an oversegmented image tend to be very similar. Hence, a scene-adaptive spatial sampling of an hyperspectral scene, guided by its super-pixel segmented image, is capable of obtaining high-quality reconstructions. To achieve this, we acquire an RGB image of the scene, compute its super-pixels, from which we generate a spatial mask of locations where we measure high-resolution spectrum. The hyperspectral image is subsequently estimated by fusing the RGB image and the spectral measurements using a learnable guided filtering approach. Due to low computational complexity of the superpixel estimation step, our setup can capture hyperspectral images of the scenes with little overhead over traditional snapshot hyperspectral cameras, but with significantly higher spatial and spectral resolutions. We validate the proposed technique with extensive simulations as well as a lab prototype that measures hyperspectral video at a spatial resolution of $600 \times 900$ pixels, at a spectral resolution of 10 nm over visible wavebands, and achieving a frame rate at $18$fps.
Interpretable Image Clustering via Diffeomorphism-Aware K-Means
Dec 16, 2020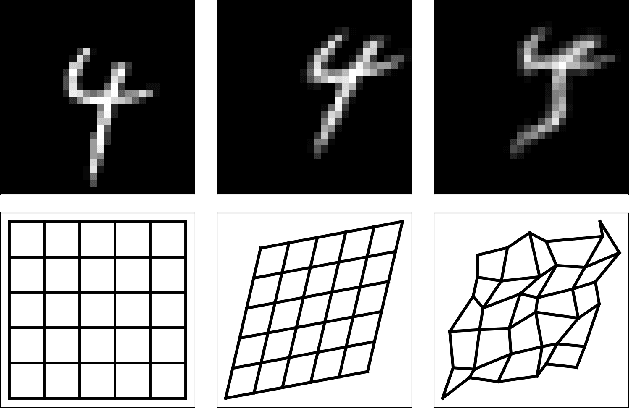
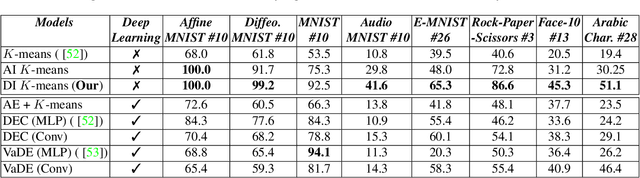
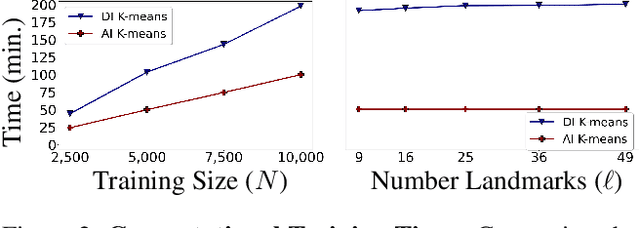

We design an interpretable clustering algorithm aware of the nonlinear structure of image manifolds. Our approach leverages the interpretability of $K$-means applied in the image space while addressing its clustering performance issues. Specifically, we develop a measure of similarity between images and centroids that encompasses a general class of deformations: diffeomorphisms, rendering the clustering invariant to them. Our work leverages the Thin-Plate Spline interpolation technique to efficiently learn diffeomorphisms best characterizing the image manifolds. Extensive numerical simulations show that our approach competes with state-of-the-art methods on various datasets.
Scalable Neural Tangent Kernel of Recurrent Architectures
Dec 09, 2020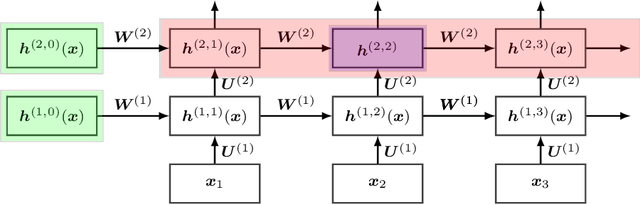
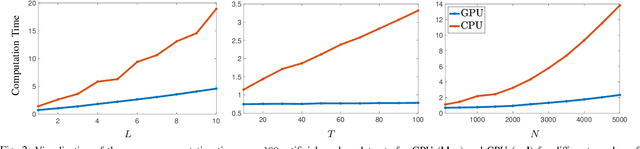
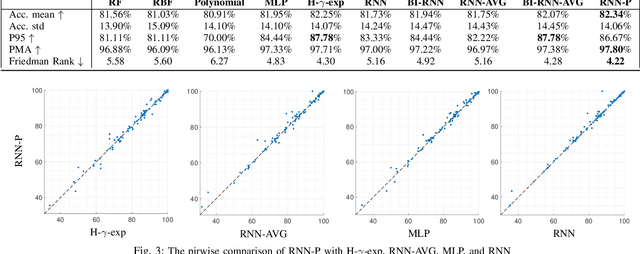
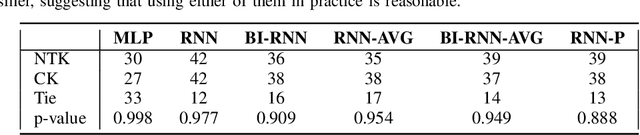
Kernels derived from deep neural networks (DNNs) in the infinite-width provide not only high performance in a range of machine learning tasks but also new theoretical insights into DNN training dynamics and generalization. In this paper, we extend the family of kernels associated with recurrent neural networks (RNNs), which were previously derived only for simple RNNs, to more complex architectures that are bidirectional RNNs and RNNs with average pooling. We also develop a fast GPU implementation to exploit its full practical potential. While RNNs are typically only applied to time-series data, we demonstrate that classifiers using RNN-based kernels outperform a range of baseline methods on 90 non-time-series datasets from the UCI data repository.
Provable Finite Data Generalization with Group Autoencoder
Sep 20, 2020

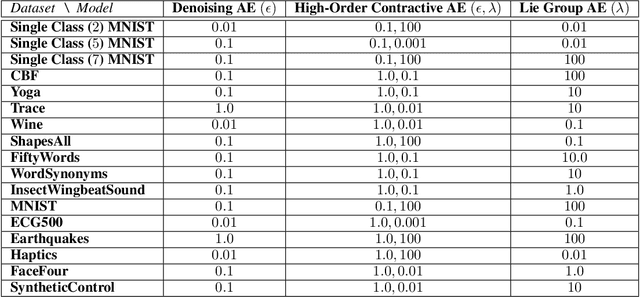
Deep Autoencoders (AEs) provide a versatile framework to learn a compressed, interpretable, or structured representation of data. As such, AEs have been used extensively for denoising, compression, data completion as well as pre-training of Deep Networks (DNs) for various tasks such as classification. By providing a careful analysis of current AEs from a spline perspective, we can interpret the input-output mapping, in turn allowing us to derive conditions for generalization and reconstruction guarantee. By assuming a Lie group structure on the data at hand, we are able to derive a novel regularization of AEs, allowing for the first time to ensure the generalization of AEs in the finite training set case. We validate our theoretical analysis by demonstrating how this regularization significantly increases the generalization of the AE on various datasets.