 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBasis Pursuit and Orthogonal Matching Pursuit for Subspace-preserving Recovery: Theoretical Analysis
Dec 30, 2019
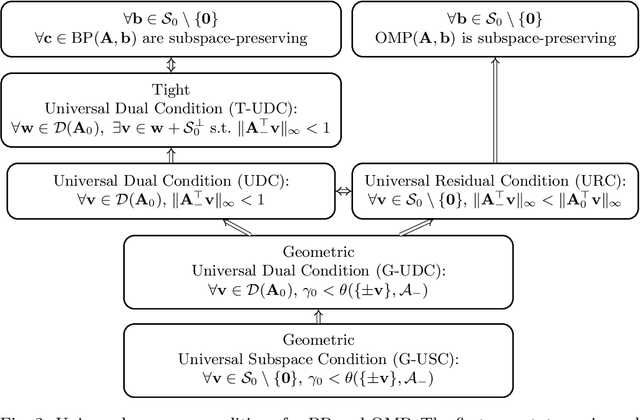
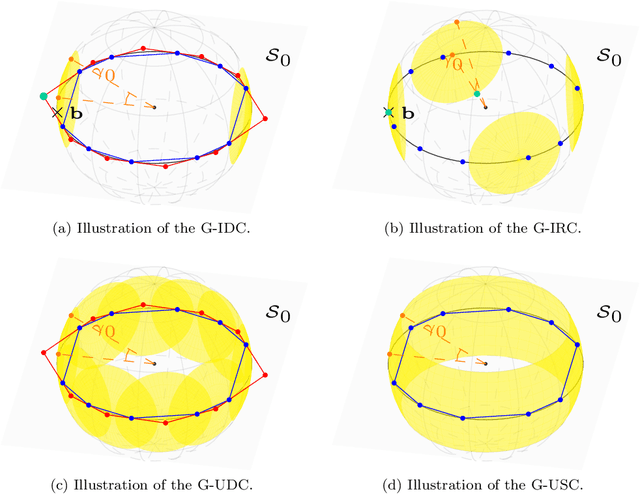
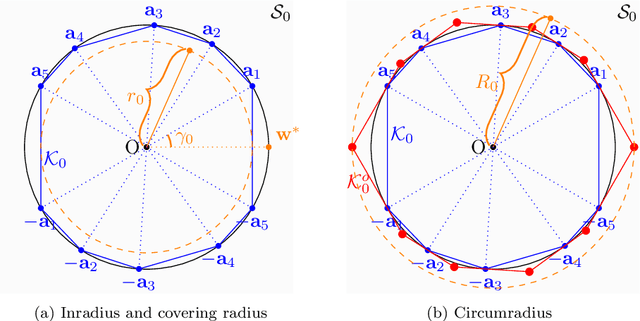
Given an overcomplete dictionary $A$ and a signal $b = Ac^*$ for some sparse vector $c^*$ whose nonzero entries correspond to linearly independent columns of $A$, classical sparse signal recovery theory considers the problem of whether $c^*$ can be recovered as the unique sparsest solution to $b = A c$. It is now well-understood that such recovery is possible by practical algorithms when the dictionary $A$ is incoherent or restricted isometric. In this paper, we consider the more general case where $b$ lies in a subspace $\mathcal{S}_0$ spanned by a subset of linearly dependent columns of $A$, and the remaining columns are outside of the subspace. In this case, the sparsest representation may not be unique, and the dictionary may not be incoherent or restricted isometric. The goal is to have the representation $c$ correctly identify the subspace, i.e. the nonzero entries of $c$ should correspond to columns of $A$ that are in the subspace $\mathcal{S}_0$. Such a representation $c$ is called subspace-preserving, a key concept that has found important applications for learning low-dimensional structures in high-dimensional data. We present various geometric conditions that guarantee subspace-preserving recovery. Among them, the major results are characterized by the covering radius and the angular distance, which capture the distribution of points in the subspace and the similarity between points in the subspace and points outside the subspace, respectively. Importantly, these conditions do not require the dictionary to be incoherent or restricted isometric. By establishing that the subspace-preserving recovery problem and the classical sparse signal recovery problem are equivalent under common assumptions on the latter, we show that several of our proposed conditions are generalizations of some well-known conditions in the sparse signal recovery literature.
Dual Principal Component Pursuit: Probability Analysis and Efficient Algorithms
Dec 24, 2018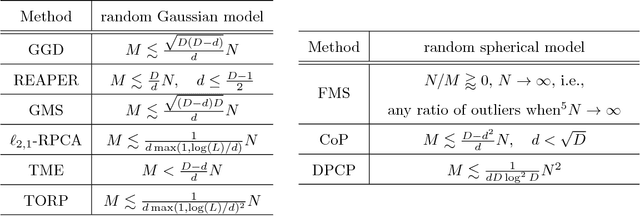
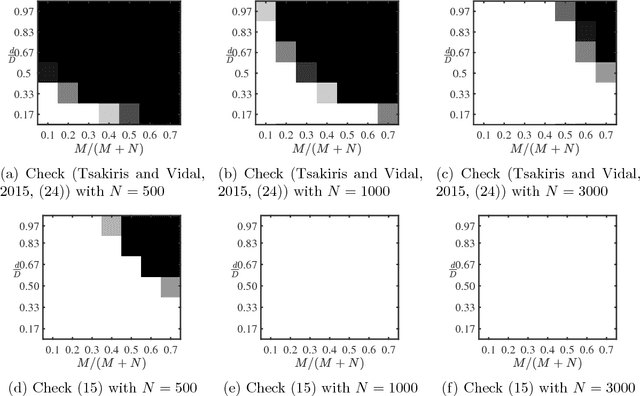
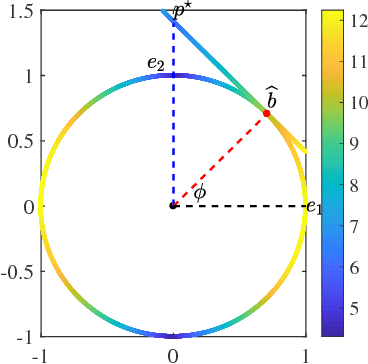
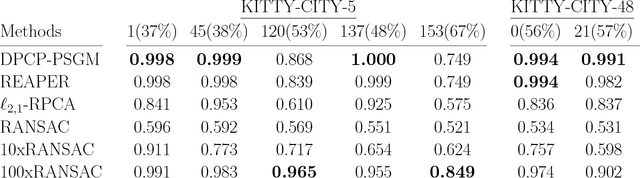
Recent methods for learning a linear subspace from data corrupted by outliers are based on convex $\ell_1$ and nuclear norm optimization and require the dimension of the subspace and the number of outliers to be sufficiently small. In sharp contrast, the recently proposed Dual Principal Component Pursuit (DPCP) method can provably handle subspaces of high dimension by solving a non-convex $\ell_1$ optimization problem on the sphere. However, its geometric analysis is based on quantities that are difficult to interpret and are not amenable to statistical analysis. In this paper we provide a refined geometric analysis and a new statistical analysis that show that DPCP can tolerate as many outliers as the square of the number of inliers, thus improving upon other provably correct robust PCA methods. We also propose a scalable Projected Sub-Gradient Method method (DPCP-PSGM) for solving the DPCP problem and show it admits linear convergence even though the underlying optimization problem is non-convex and non-smooth. Experiments on road plane detection from 3D point cloud data demonstrate that DPCP-PSGM can be more efficient than the traditional RANSAC algorithm, which is one of the most popular methods for such computer vision applications.
Dual Principal Component Pursuit
Aug 04, 2018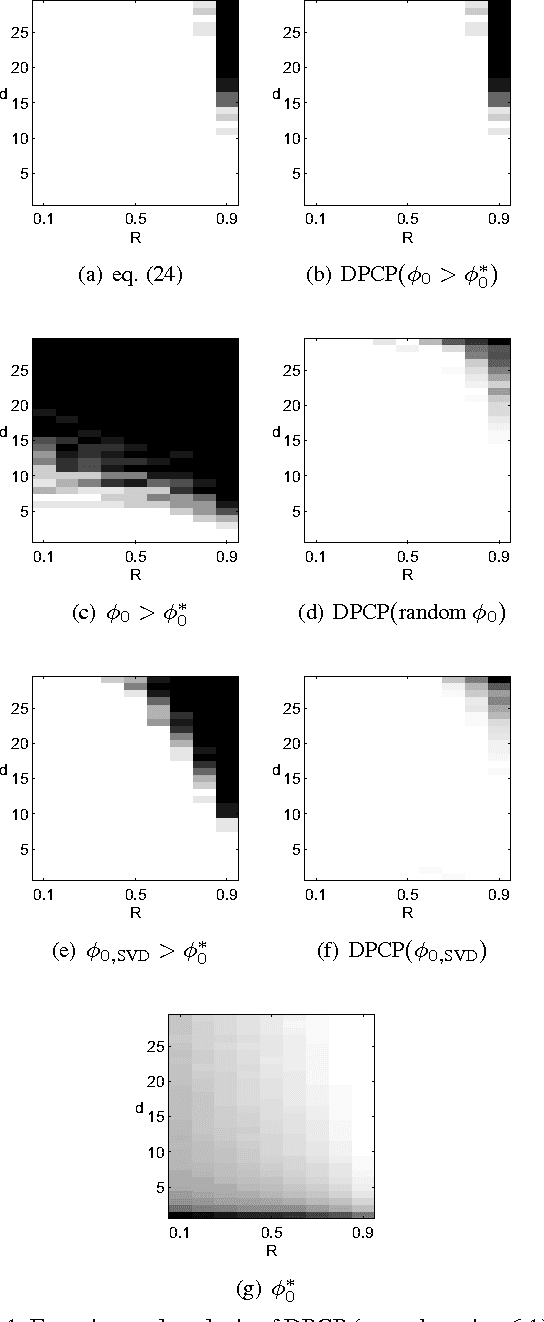
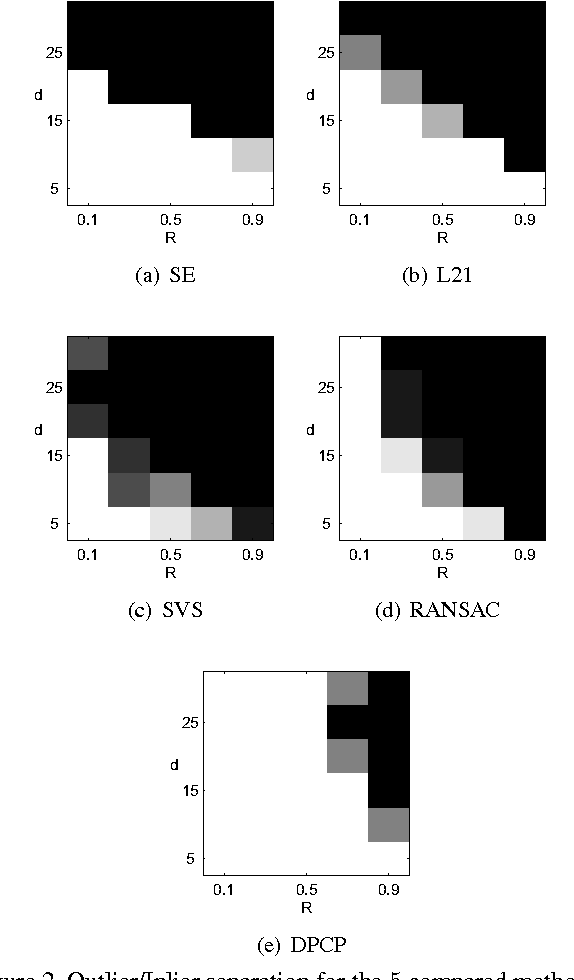
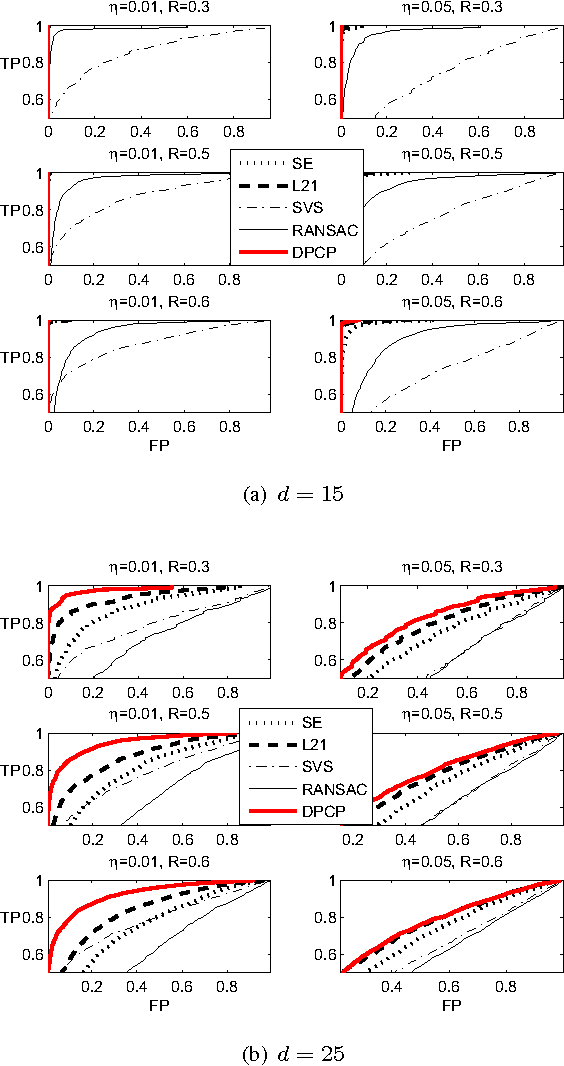
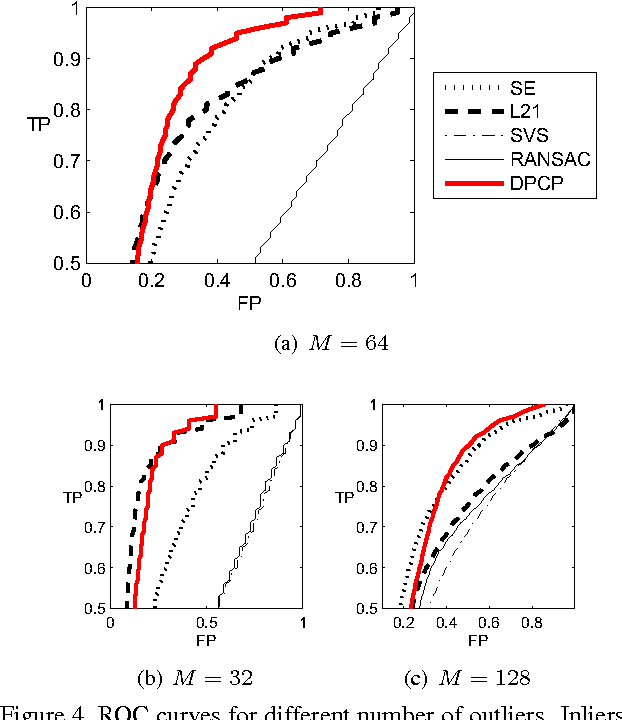
We consider the problem of learning a linear subspace from data corrupted by outliers. Classical approaches are typically designed for the case in which the subspace dimension is small relative to the ambient dimension. Our approach works with a dual representation of the subspace and hence aims to find its orthogonal complement; as such, it is particularly suitable for subspaces whose dimension is close to the ambient dimension (subspaces of high relative dimension). We pose the problem of computing normal vectors to the inlier subspace as a non-convex $\ell_1$ minimization problem on the sphere, which we call Dual Principal Component Pursuit (DPCP) problem. We provide theoretical guarantees under which every global solution to DPCP is a vector in the orthogonal complement of the inlier subspace. Moreover, we relax the non-convex DPCP problem to a recursion of linear programs whose solutions are shown to converge in a finite number of steps to a vector orthogonal to the subspace. In particular, when the inlier subspace is a hyperplane, the solutions to the recursion of linear programs converge to the global minimum of the non-convex DPCP problem in a finite number of steps. We also propose algorithms based on alternating minimization and iteratively re-weighted least squares, which are suitable for dealing with large-scale data. Experiments on synthetic data show that the proposed methods are able to handle more outliers and higher relative dimensions than current state-of-the-art methods, while experiments in the context of the three-view geometry problem in computer vision suggest that the proposed methods can be a useful or even superior alternative to traditional RANSAC-based approaches for computer vision and other applications.
Convolutional Networks for Object Category and 3D Pose Estimation from 2D Images
Jul 20, 2018
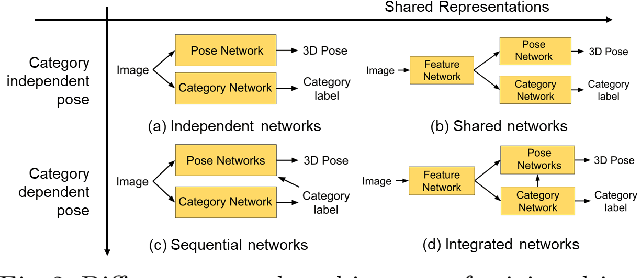
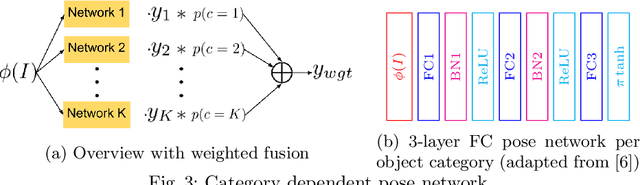
Current CNN-based algorithms for recovering the 3D pose of an object in an image assume knowledge about both the object category and its 2D localization in the image. In this paper, we relax one of these constraints and propose to solve the task of joint object category and 3D pose estimation from an image assuming known 2D localization. We design a new architecture for this task composed of a feature network that is shared between subtasks, an object categorization network built on top of the feature network, and a collection of category dependent pose regression networks. We also introduce suitable loss functions and a training method for the new architecture. Experiments on the challenging PASCAL3D+ dataset show state-of-the-art performance in the joint categorization and pose estimation task. Moreover, our performance on the joint task is comparable to the performance of state-of-the-art methods on the simpler 3D pose estimation with known object category task.
On the Implicit Bias of Dropout
Jun 26, 2018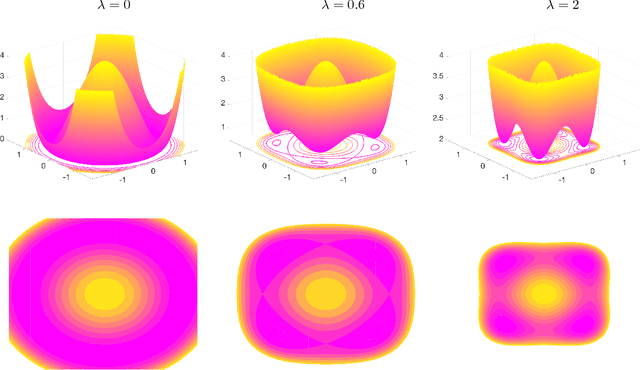
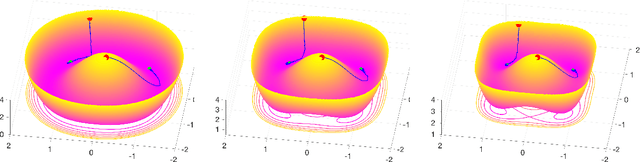
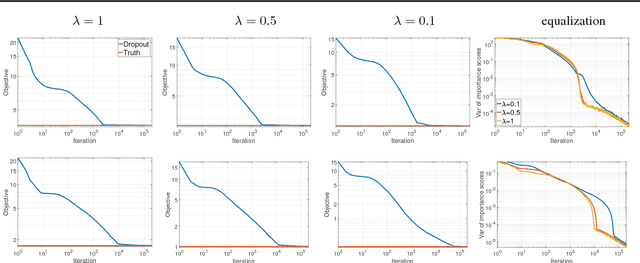
Algorithmic approaches endow deep learning systems with implicit bias that helps them generalize even in over-parametrized settings. In this paper, we focus on understanding such a bias induced in learning through dropout, a popular technique to avoid overfitting in deep learning. For single hidden-layer linear neural networks, we show that dropout tends to make the norm of incoming/outgoing weight vectors of all the hidden nodes equal. In addition, we provide a complete characterization of the optimization landscape induced by dropout.
A Mixed Classification-Regression Framework for 3D Pose Estimation from 2D Images
May 08, 2018
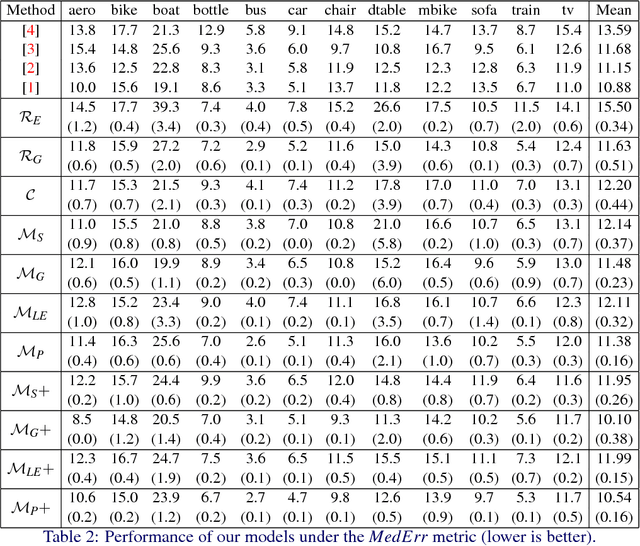

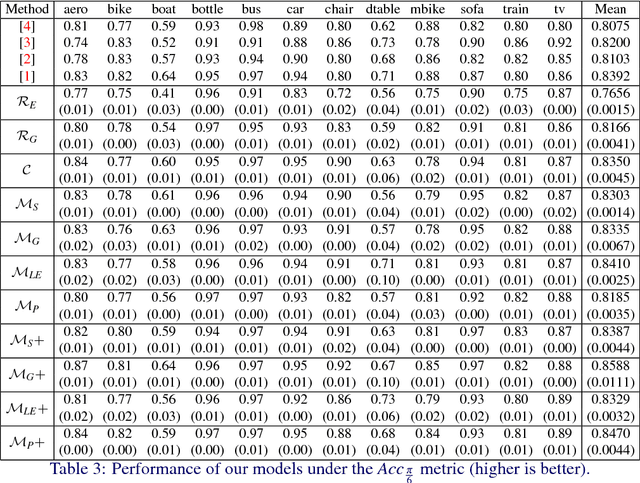
3D pose estimation from a single 2D image is an important and challenging task in computer vision with applications in autonomous driving, robot manipulation and augmented reality. Since 3D pose is a continuous quantity, a natural formulation for this task is to solve a pose regression problem. However, since pose regression methods return a single estimate of the pose, they have difficulties handling multimodal pose distributions (e.g. in the case of symmetric objects). An alternative formulation, which can capture multimodal pose distributions, is to discretize the pose space into bins and solve a pose classification problem. However, pose classification methods can give large pose estimation errors depending on the coarseness of the discretization. In this paper, we propose a mixed classification-regression framework that uses a classification network to produce a discrete multimodal pose estimate and a regression network to produce a continuous refinement of the discrete estimate. The proposed framework can accommodate different architectures and loss functions, leading to multiple classification-regression models, some of which achieve state-of-the-art performance on the challenging Pascal3D+ dataset.
Theoretical Analysis of Sparse Subspace Clustering with Missing Entries
Feb 09, 2018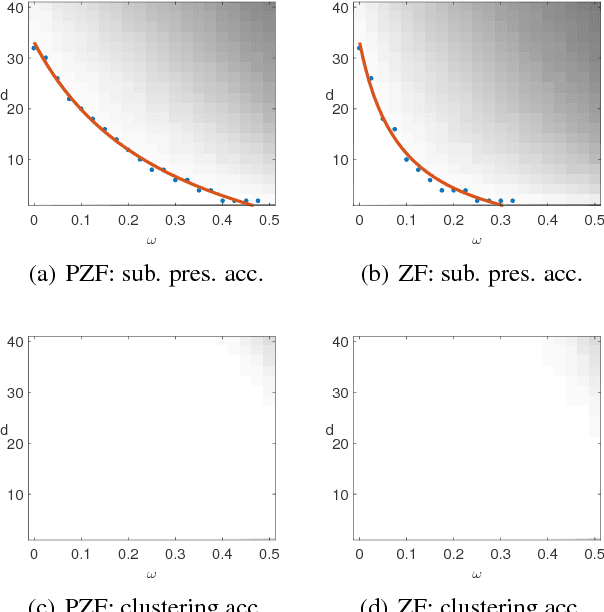
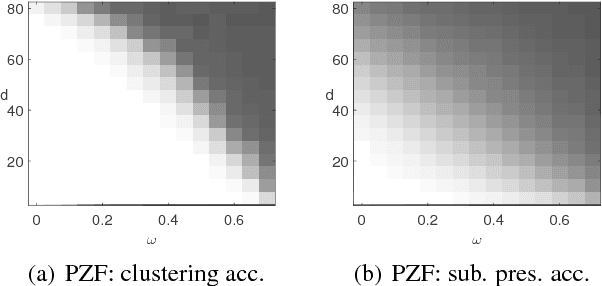
Sparse Subspace Clustering (SSC) is a popular unsupervised machine learning method for clustering data lying close to an unknown union of low-dimensional linear subspaces; a problem with numerous applications in pattern recognition and computer vision. Even though the behavior of SSC for complete data is by now well-understood, little is known about its theoretical properties when applied to data with missing entries. In this paper we give theoretical guarantees for SSC with incomplete data, and analytically establish that projecting the zero-filled data onto the observation pattern of the point being expressed leads to a substantial improvement in performance. The main insight that stems from our analysis is that even though the projection induces additional missing entries, this is counterbalanced by the fact that the projected and zero-filled data are in effect incomplete points associated with the union of the corresponding projected subspaces, with respect to which the point being expressed is complete. The significance of this phenomenon potentially extends to the entire class of self-expressive methods.
Mathematics of Deep Learning
Dec 13, 2017
Recently there has been a dramatic increase in the performance of recognition systems due to the introduction of deep architectures for representation learning and classification. However, the mathematical reasons for this success remain elusive. This tutorial will review recent work that aims to provide a mathematical justification for several properties of deep networks, such as global optimality, geometric stability, and invariance of the learned representations.
Stretching Domain Adaptation: How far is too far?
Dec 06, 2017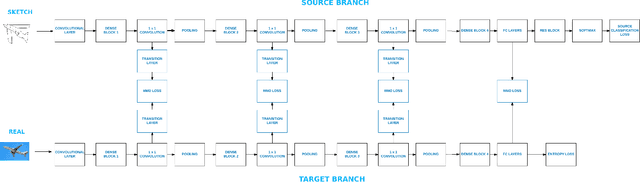
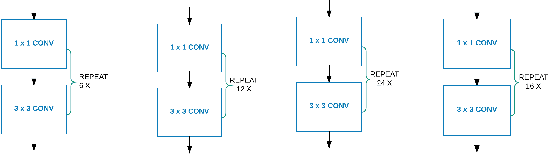
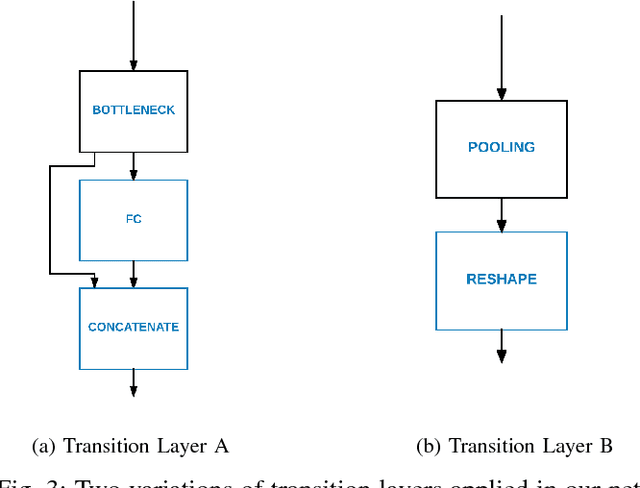

While deep learning has led to significant advances in visual recognition over the past few years, such advances often require a lot of annotated data. While unsupervised domain adaptation has emerged as an alternative approach that doesn't require as much annotated data, prior evaluations of domain adaptation have been limited to relatively simple datasets. This work pushes the state of the art in unsupervised domain adaptation through an in depth evaluation of AlexNet, DenseNet and Residual Transfer Networks (RTN) on multimodal benchmark datasets that shows and identifies which layers more effectively transfer features across different domains. We also modify the existing RTN architecture and propose a novel domain adaptation architecture called "Deep MagNet" that combines Deep Convolutional Blocks with multiple Maximum Mean Discrepancy losses. Our experiments show quantitative and qualitative improvements in performance of our method on benchmarking datasets for complex data domains.
Dropout as a Low-Rank Regularizer for Matrix Factorization
Oct 13, 2017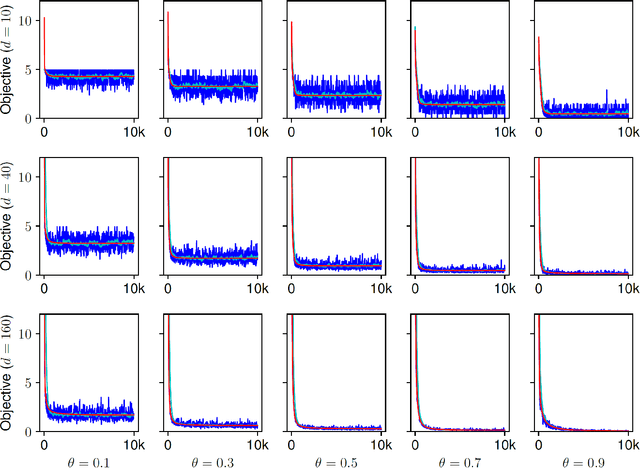
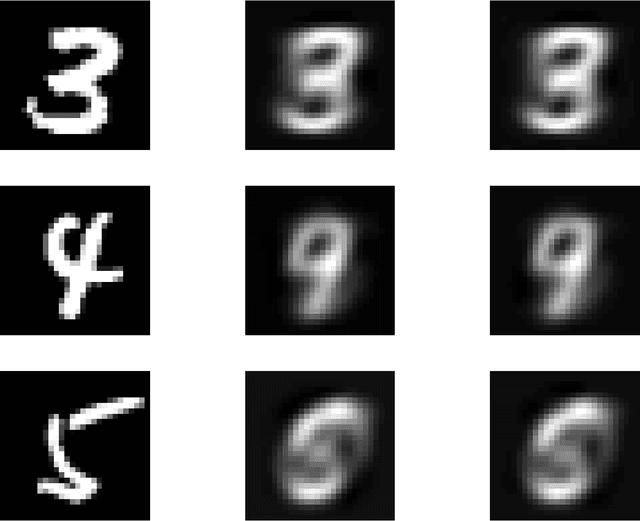
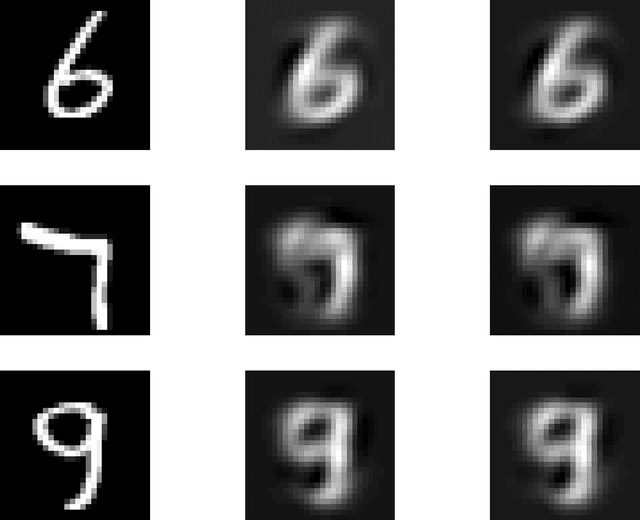
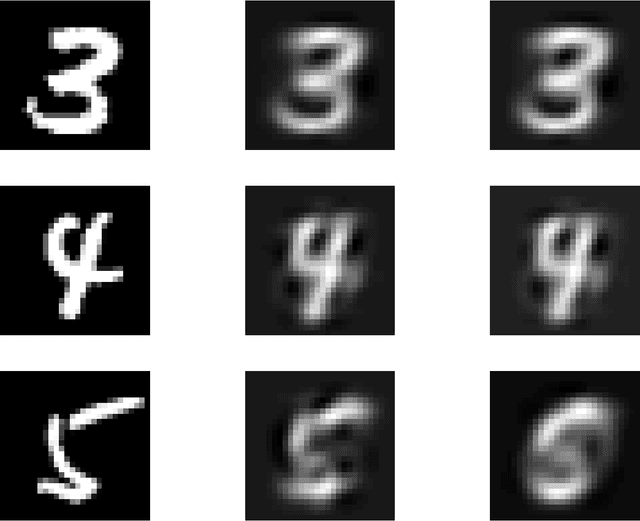
Regularization for matrix factorization (MF) and approximation problems has been carried out in many different ways. Due to its popularity in deep learning, dropout has been applied also for this class of problems. Despite its solid empirical performance, the theoretical properties of dropout as a regularizer remain quite elusive for this class of problems. In this paper, we present a theoretical analysis of dropout for MF, where Bernoulli random variables are used to drop columns of the factors. We demonstrate the equivalence between dropout and a fully deterministic model for MF in which the factors are regularized by the sum of the product of squared Euclidean norms of the columns. Additionally, we inspect the case of a variable sized factorization and we prove that dropout achieves the global minimum of a convex approximation problem with (squared) nuclear norm regularization. As a result, we conclude that dropout can be used as a low-rank regularizer with data dependent singular-value thresholding.