 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Stochastic Mechanics
May 31, 2023This paper introduces a novel deep-learning-based approach for numerical simulation of a time-evolving Schr\"odinger equation inspired by stochastic mechanics and generative diffusion models. Unlike existing approaches, which exhibit computational complexity that scales exponentially in the problem dimension, our method allows us to adapt to the latent low-dimensional structure of the wave function by sampling from the Markovian diffusion. Depending on the latent dimension, our method may have far lower computational complexity in higher dimensions. Moreover, we propose novel equations for stochastic quantum mechanics, resulting in linear computational complexity with respect to the number of dimensions. Numerical simulations verify our theoretical findings and show a significant advantage of our method compared to other deep-learning-based approaches used for quantum mechanics.
Linear Neural Network Layers Promote Learning Single- and Multiple-Index Models
May 24, 2023This paper explores the implicit bias of overparameterized neural networks of depth greater than two layers. Our framework considers a family of networks of varying depths that all have the same capacity but different implicitly defined representation costs. The representation cost of a function induced by a neural network architecture is the minimum sum of squared weights needed for the network to represent the function; it reflects the function space bias associated with the architecture. Our results show that adding linear layers to a ReLU network yields a representation cost that favors functions that can be approximated by a low-rank linear operator composed with a function with low representation cost using a two-layer network. Specifically, using a neural network to fit training data with minimum representation cost yields an interpolating function that is nearly constant in directions orthogonal to a low-dimensional subspace. This means that the learned network will approximately be a single- or multiple-index model. Our experiments show that when this active subspace structure exists in the data, adding linear layers can improve generalization and result in a network that is well-aligned with the true active subspace.
Bagging Provides Assumption-free Stability
Jan 30, 2023



Bagging is an important technique for stabilizing machine learning models. In this paper, we derive a finite-sample guarantee on the stability of bagging for any model with bounded outputs. Our result places no assumptions on the distribution of the data, on the properties of the base algorithm, or on the dimensionality of the covariates. Our guarantee applies to many variants of bagging and is optimal up to a constant.
Reduced-Order Autodifferentiable Ensemble Kalman Filters
Jan 27, 2023This paper introduces a computational framework to reconstruct and forecast a partially observed state that evolves according to an unknown or expensive-to-simulate dynamical system. Our reduced-order autodifferentiable ensemble Kalman filters (ROAD-EnKFs) learn a latent low-dimensional surrogate model for the dynamics and a decoder that maps from the latent space to the state space. The learned dynamics and decoder are then used within an ensemble Kalman filter to reconstruct and forecast the state. Numerical experiments show that if the state dynamics exhibit a hidden low-dimensional structure, ROAD-EnKFs achieve higher accuracy at lower computational cost compared to existing methods. If such structure is not expressed in the latent state dynamics, ROAD-EnKFs achieve similar accuracy at lower cost, making them a promising approach for surrogate state reconstruction and forecasting.
Beyond Ensemble Averages: Leveraging Climate Model Ensembles for Subseasonal Forecasting
Nov 29, 2022Producing high-quality forecasts of key climate variables such as temperature and precipitation on subseasonal time scales has long been a gap in operational forecasting. Recent studies have shown promising results using machine learning (ML) models to advance subseasonal forecasting (SSF), but several open questions remain. First, several past approaches use the average of an ensemble of physics-based forecasts as an input feature of these models. However, ensemble forecasts contain information that can aid prediction beyond only the ensemble mean. Second, past methods have focused on average performance, whereas forecasts of extreme events are far more important for planning and mitigation purposes. Third, climate forecasts correspond to a spatially-varying collection of forecasts, and different methods account for spatial variability in the response differently. Trade-offs between different approaches may be mitigated with model stacking. This paper describes the application of a variety of ML methods used to predict monthly average precipitation and two meter temperature using physics-based predictions (ensemble forecasts) and observational data such as relative humidity, pressure at sea level, or geopotential height, two weeks in advance for the whole continental United States. Regression, quantile regression, and tercile classification tasks using linear models, random forests, convolutional neural networks, and stacked models are considered. The proposed models outperform common baselines such as historical averages (or quantiles) and ensemble averages (or quantiles). This paper further includes an investigation of feature importance, trade-offs between using the full ensemble or only the ensemble average, and different modes of accounting for spatial variability.
Embed and Emulate: Learning to estimate parameters of dynamical systems with uncertainty quantification
Nov 03, 2022This paper explores learning emulators for parameter estimation with uncertainty estimation of high-dimensional dynamical systems. We assume access to a computationally complex simulator that inputs a candidate parameter and outputs a corresponding multichannel time series. Our task is to accurately estimate a range of likely values of the underlying parameters. Standard iterative approaches necessitate running the simulator many times, which is computationally prohibitive. This paper describes a novel framework for learning feature embeddings of observed dynamics jointly with an emulator that can replace high-cost simulators for parameter estimation. Leveraging a contrastive learning approach, our method exploits intrinsic data properties within and across parameter and trajectory domains. On a coupled 396-dimensional multiscale Lorenz 96 system, our method significantly outperforms a typical parameter estimation method based on predefined metrics and a classical numerical simulator, and with only 1.19% of the baseline's computation time. Ablation studies highlight the potential of explicitly designing learned emulators for parameter estimation by leveraging contrastive learning.
Cloud Classification with Unsupervised Deep Learning
Sep 30, 2022
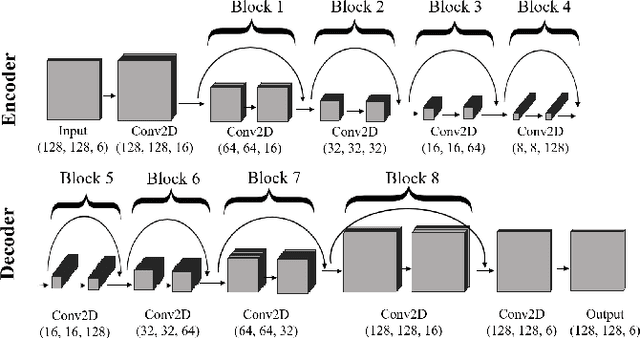
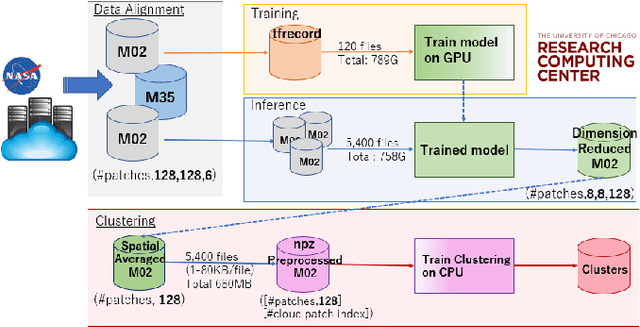
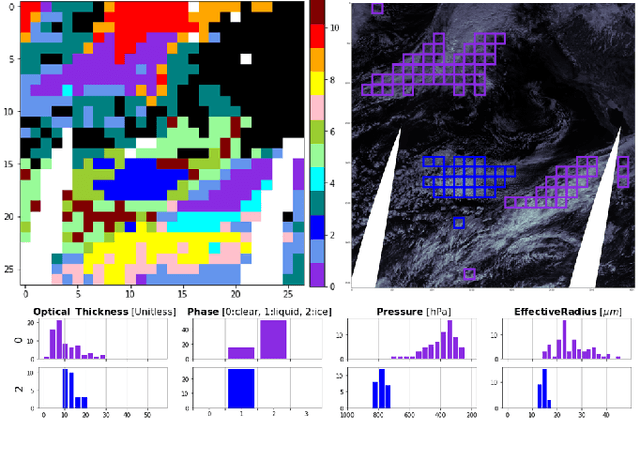
We present a framework for cloud characterization that leverages modern unsupervised deep learning technologies. While previous neural network-based cloud classification models have used supervised learning methods, unsupervised learning allows us to avoid restricting the model to artificial categories based on historical cloud classification schemes and enables the discovery of novel, more detailed classifications. Our framework learns cloud features directly from radiance data produced by NASA's Moderate Resolution Imaging Spectroradiometer (MODIS) satellite instrument, deriving cloud characteristics from millions of images without relying on pre-defined cloud types during the training process. We present preliminary results showing that our method extracts physically relevant information from radiance data and produces meaningful cloud classes.
NURD: Negative-Unlabeled Learning for Online Datacenter Straggler Prediction
Mar 16, 2022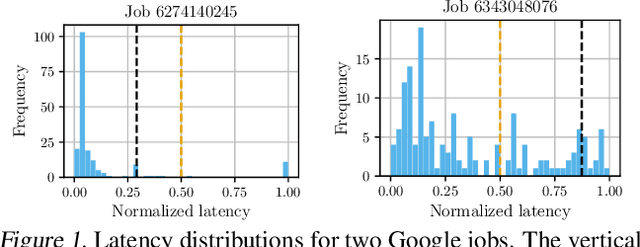


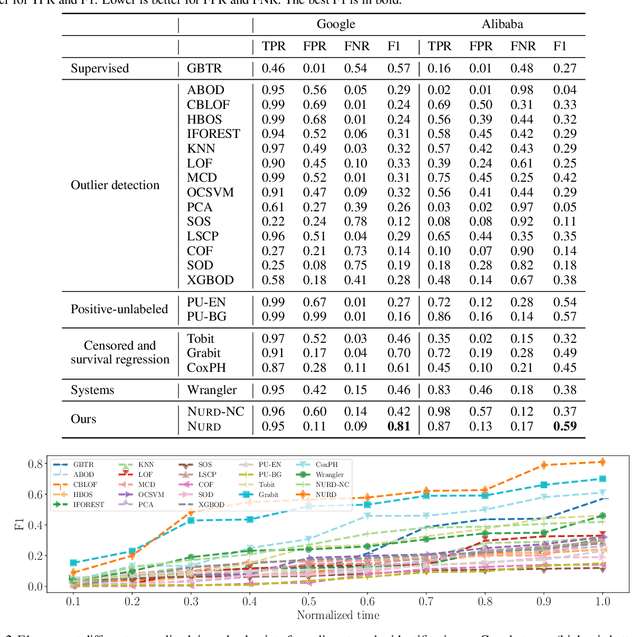
Datacenters execute large computational jobs, which are composed of smaller tasks. A job completes when all its tasks finish, so stragglers -- rare, yet extremely slow tasks -- are a major impediment to datacenter performance. Accurately predicting stragglers would enable proactive intervention, allowing datacenter operators to mitigate stragglers before they delay a job. While much prior work applies machine learning to predict computer system performance, these approaches rely on complete labels -- i.e., sufficient examples of all possible behaviors, including straggling and non-straggling -- or strong assumptions about the underlying latency distributions -- e.g., whether Gaussian or not. Within a running job, however, none of this information is available until stragglers have revealed themselves when they have already delayed the job. To predict stragglers accurately and early without labeled positive examples or assumptions on latency distributions, this paper presents NURD, a novel Negative-Unlabeled learning approach with Reweighting and Distribution-compensation that only trains on negative and unlabeled streaming data. The key idea is to train a predictor using finished tasks of non-stragglers to predict latency for unlabeled running tasks, and then reweight each unlabeled task's prediction based on a weighting function of its feature space. We evaluate NURD on two production traces from Google and Alibaba, and find that compared to the best baseline approach, NURD produces 2--11 percentage point increases in the F1 score in terms of prediction accuracy, and 4.7--8.8 percentage point improvements in job completion time.
The Role of Linear Layers in Nonlinear Interpolating Networks
Feb 02, 2022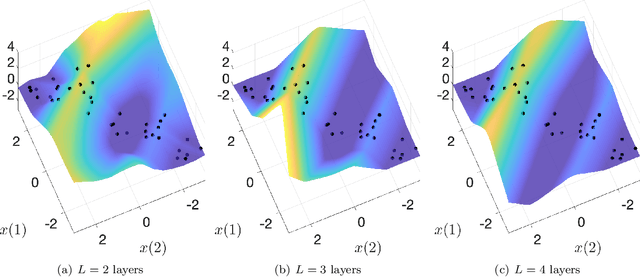
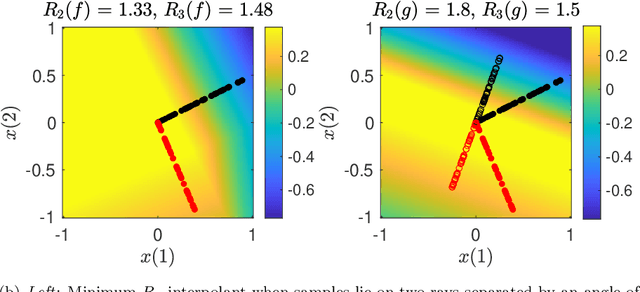
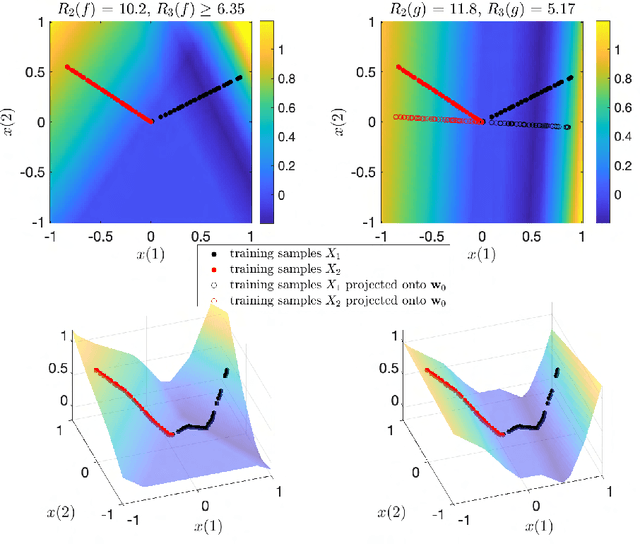
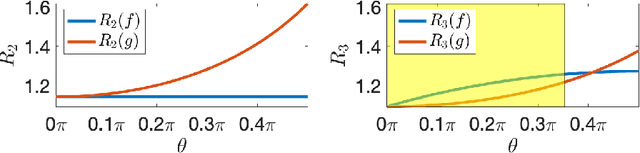
This paper explores the implicit bias of overparameterized neural networks of depth greater than two layers. Our framework considers a family of networks of varying depth that all have the same capacity but different implicitly defined representation costs. The representation cost of a function induced by a neural network architecture is the minimum sum of squared weights needed for the network to represent the function; it reflects the function space bias associated with the architecture. Our results show that adding linear layers to a ReLU network yields a representation cost that reflects a complex interplay between the alignment and sparsity of ReLU units. Specifically, using a neural network to fit training data with minimum representation cost yields an interpolating function that is constant in directions perpendicular to a low-dimensional subspace on which a parsimonious interpolant exists.
Adaptive Differentially Private Empirical Risk Minimization
Oct 25, 2021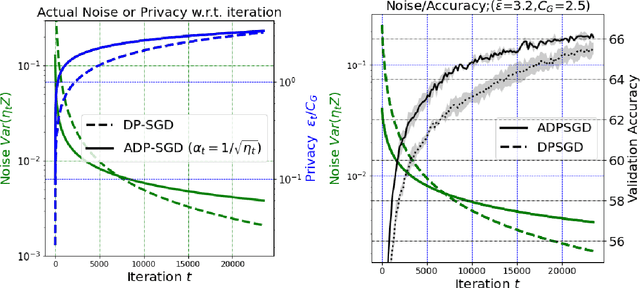
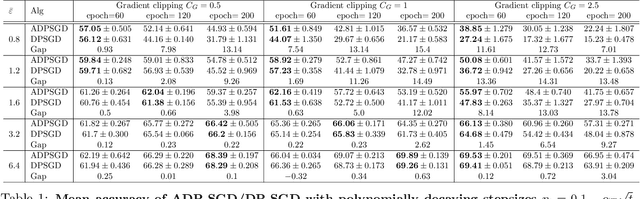
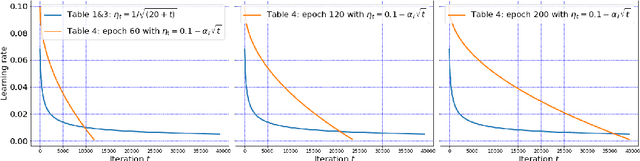
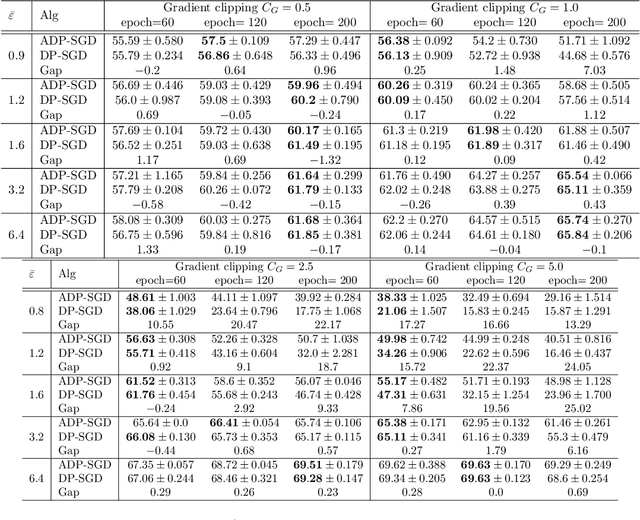
We propose an adaptive (stochastic) gradient perturbation method for differentially private empirical risk minimization. At each iteration, the random noise added to the gradient is optimally adapted to the stepsize; we name this process adaptive differentially private (ADP) learning. Given the same privacy budget, we prove that the ADP method considerably improves the utility guarantee compared to the standard differentially private method in which vanilla random noise is added. Our method is particularly useful for gradient-based algorithms with time-varying learning rates, including variants of AdaGrad (Duchi et al., 2011). We provide extensive numerical experiments to demonstrate the effectiveness of the proposed adaptive differentially private algorithm.