 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinShap: A Modified Shapley Value Approach for Feature Selection
Apr 16, 2026Feature selection is a classical problem in statistics and machine learning, and it continues to remain an extremely challenging problem especially in the context of unknown non-linear relationships with dependent features. On the other hand, Shapley values are a classic solution concept from cooperative game theory that is widely used for feature attribution in general non-linear models with highly-dependent features. However, Shapley values are not naturally suited for feature selection since they tend to capture both direct effects from each feature to the response and indirect effects through other features. In this paper, we combine the advantages of Shapley values and adapt them to feature selection by proposing \emph{MinShap}, a modification of the Shapley value framework along with a suite of other related algorithms. In particular for MinShap, instead of taking the average marginal contributions over permutations of features, considers the minimum marginal contribution across permutations. We provide a theoretical foundation motivated by the faithfulness assumption in DAG (directed acyclic graphical models), a guarantee for the Type I error of MinShap, and show through numerical simulations and real data experiments that MinShap tends to outperform state-of-the-art feature selection algorithms such as LOCO, GCM and Lasso in terms of both accuracy and stability. We also introduce a suite of algorithms related to MinShap by using the multiple testing/p-value perspective that improves performance in lower-sample settings and provide supporting theoretical guarantees.
A Theoretical Framework for LLM Fine-tuning Using Early Stopping for Non-random Initialization
Feb 15, 2026In the era of large language models (LLMs), fine-tuning pretrained models has become ubiquitous. Yet the theoretical underpinning remains an open question. A central question is why only a few epochs of fine-tuning are typically sufficient to achieve strong performance on many different tasks. In this work, we approach this question by developing a statistical framework, combining rigorous early stopping theory with the attention-based Neural Tangent Kernel (NTK) for LLMs, offering new theoretical insights on fine-tuning practices. Specifically, we formally extend classical NTK theory [Jacot et al., 2018] to non-random (i.e., pretrained) initializations and provide a convergence guarantee for attention-based fine-tuning. One key insight provided by the theory is that the convergence rate with respect to sample size is closely linked to the eigenvalue decay rate of the empirical kernel matrix induced by the NTK. We also demonstrate how the framework can be used to explain task vectors for multiple tasks in LLMs. Finally, experiments with modern language models on real-world datasets provide empirical evidence supporting our theoretical insights.
Comparing Model-agnostic Feature Selection Methods through Relative Efficiency
Aug 19, 2025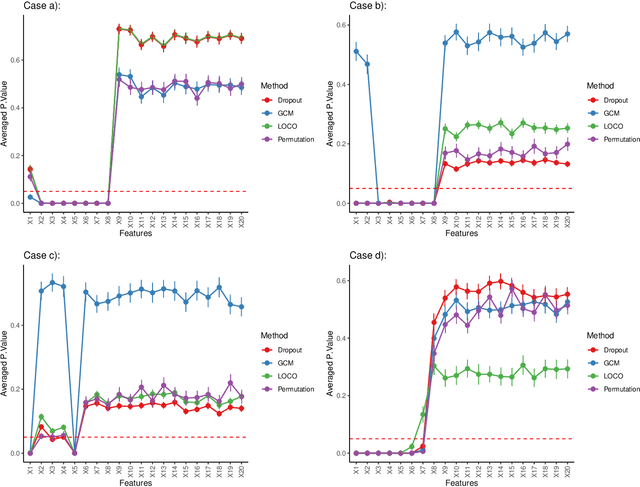
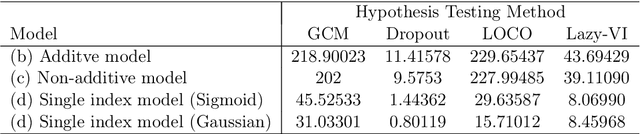
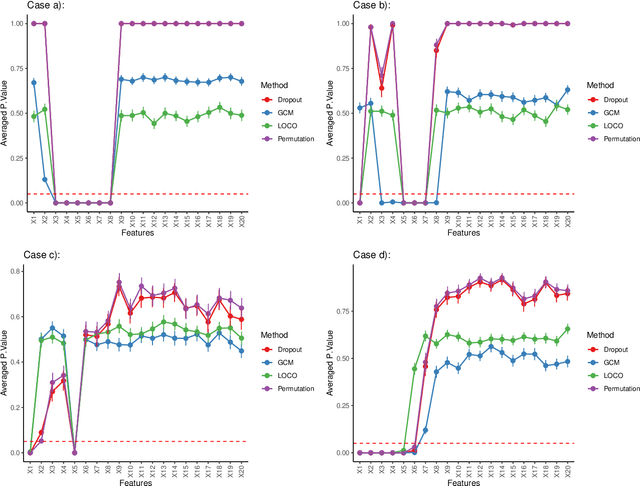
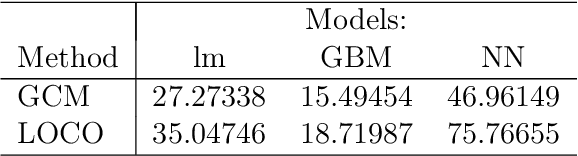
Feature selection and importance estimation in a model-agnostic setting is an ongoing challenge of significant interest. Wrapper methods are commonly used because they are typically model-agnostic, even though they are computationally intensive. In this paper, we focus on feature selection methods related to the Generalized Covariance Measure (GCM) and Leave-One-Covariate-Out (LOCO) estimation, and provide a comparison based on relative efficiency. In particular, we present a theoretical comparison under three model settings: linear models, non-linear additive models, and single index models that mimic a single-layer neural network. We complement this with extensive simulations and real data examples. Our theoretical results, along with empirical findings, demonstrate that GCM-related methods generally outperform LOCO under suitable regularity conditions. Furthermore, we quantify the asymptotic relative efficiency of these approaches. Our simulations and real data analysis include widely used machine learning methods such as neural networks and gradient boosting trees.
Reliable and scalable variable importance estimation via warm-start and early stopping
Dec 02, 2024As opaque black-box predictive models become more prevalent, the need to develop interpretations for these models is of great interest. The concept of variable importance and Shapley values are interpretability measures that applies to any predictive model and assesses how much a variable or set of variables improves prediction performance. When the number of variables is large, estimating variable importance presents a significant computational challenge because re-training neural networks or other black-box algorithms requires significant additional computation. In this paper, we address this challenge for algorithms using gradient descent and gradient boosting (e.g. neural networks, gradient-boosted decision trees). By using the ideas of early stopping of gradient-based methods in combination with warm-start using the dropout method, we develop a scalable method to estimate variable importance for any algorithm that can be expressed as an iterative kernel update equation. Importantly, we provide theoretical guarantees by using the theory for early stopping of kernel-based methods for neural networks with sufficiently large (but not necessarily infinite) width and gradient-boosting decision trees that use symmetric trees as a weaker learner. We also demonstrate the efficacy of our methods through simulations and a real data example which illustrates the computational benefit of early stopping rather than fully re-training the model as well as the increased accuracy of our approach.
Fast, Distribution-free Predictive Inference for Neural Networks with Coverage Guarantees
Jun 11, 2023



This paper introduces a novel, computationally-efficient algorithm for predictive inference (PI) that requires no distributional assumptions on the data and can be computed faster than existing bootstrap-type methods for neural networks. Specifically, if there are $n$ training samples, bootstrap methods require training a model on each of the $n$ subsamples of size $n-1$; for large models like neural networks, this process can be computationally prohibitive. In contrast, our proposed method trains one neural network on the full dataset with $(\epsilon, \delta)$-differential privacy (DP) and then approximates each leave-one-out model efficiently using a linear approximation around the differentially-private neural network estimate. With exchangeable data, we prove that our approach has a rigorous coverage guarantee that depends on the preset privacy parameters and the stability of the neural network, regardless of the data distribution. Simulations and experiments on real data demonstrate that our method satisfies the coverage guarantees with substantially reduced computation compared to bootstrap methods.
Lazy Estimation of Variable Importance for Large Neural Networks
Jul 19, 2022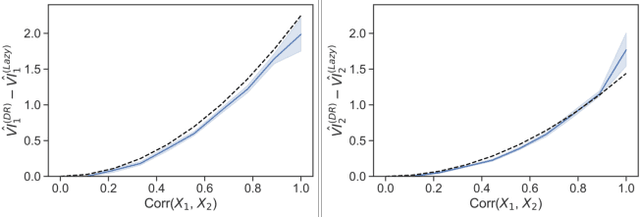
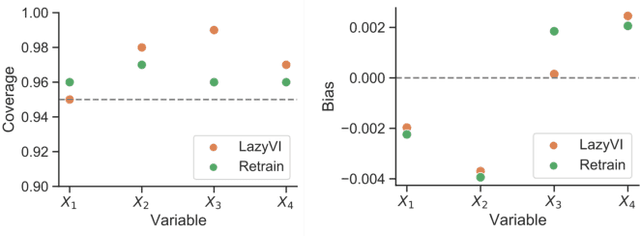

As opaque predictive models increasingly impact many areas of modern life, interest in quantifying the importance of a given input variable for making a specific prediction has grown. Recently, there has been a proliferation of model-agnostic methods to measure variable importance (VI) that analyze the difference in predictive power between a full model trained on all variables and a reduced model that excludes the variable(s) of interest. A bottleneck common to these methods is the estimation of the reduced model for each variable (or subset of variables), which is an expensive process that often does not come with theoretical guarantees. In this work, we propose a fast and flexible method for approximating the reduced model with important inferential guarantees. We replace the need for fully retraining a wide neural network by a linearization initialized at the full model parameters. By adding a ridge-like penalty to make the problem convex, we prove that when the ridge penalty parameter is sufficiently large, our method estimates the variable importance measure with an error rate of $O(\frac{1}{\sqrt{n}})$ where $n$ is the number of training samples. We also show that our estimator is asymptotically normal, enabling us to provide confidence bounds for the VI estimates. We demonstrate through simulations that our method is fast and accurate under several data-generating regimes, and we demonstrate its real-world applicability on a seasonal climate forecasting example.
Gaussian Process Inference Using Mini-batch Stochastic Gradient Descent: Convergence Guarantees and Empirical Benefits
Nov 19, 2021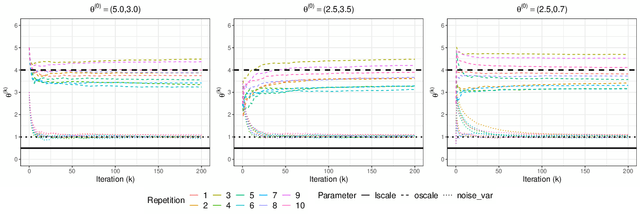
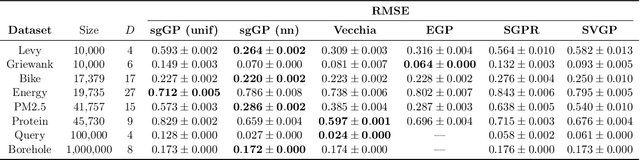
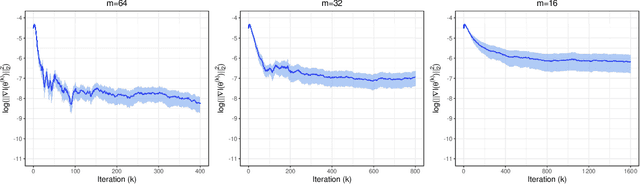
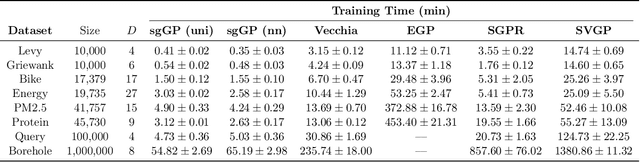
Stochastic gradient descent (SGD) and its variants have established themselves as the go-to algorithms for large-scale machine learning problems with independent samples due to their generalization performance and intrinsic computational advantage. However, the fact that the stochastic gradient is a biased estimator of the full gradient with correlated samples has led to the lack of theoretical understanding of how SGD behaves under correlated settings and hindered its use in such cases. In this paper, we focus on hyperparameter estimation for the Gaussian process (GP) and take a step forward towards breaking the barrier by proving minibatch SGD converges to a critical point of the full log-likelihood loss function, and recovers model hyperparameters with rate $O(\frac{1}{K})$ for $K$ iterations, up to a statistical error term depending on the minibatch size. Our theoretical guarantees hold provided that the kernel functions exhibit exponential or polynomial eigendecay which is satisfied by a wide range of kernels commonly used in GPs. Numerical studies on both simulated and real datasets demonstrate that minibatch SGD has better generalization over state-of-the-art GP methods while reducing the computational burden and opening a new, previously unexplored, data size regime for GPs.
The Internet of Federated Things : A Vision for the Future and In-depth Survey of Data-driven Approaches for Federated Learning
Nov 09, 2021
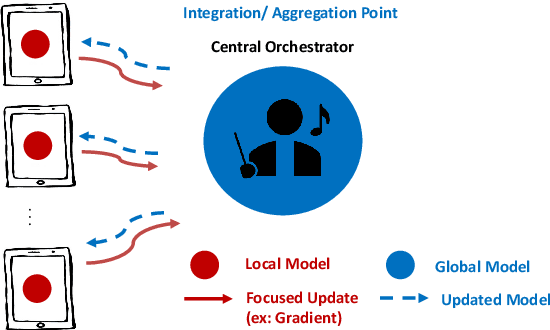
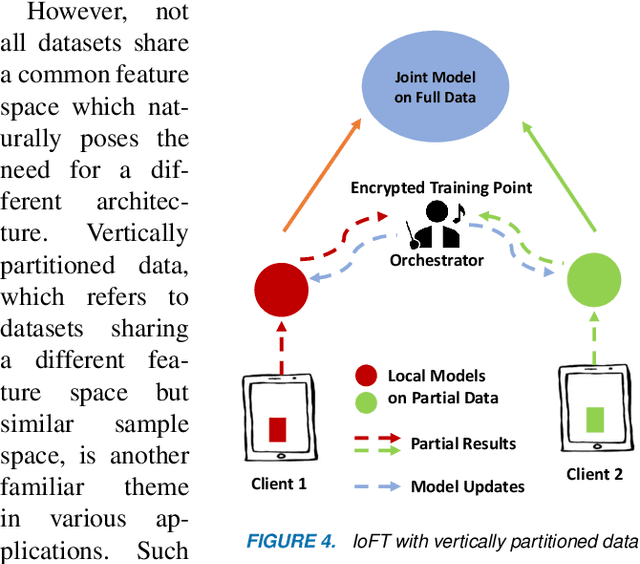
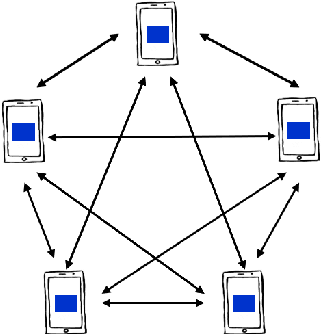
The Internet of Things (IoT) is on the verge of a major paradigm shift. In the IoT system of the future, IoFT, the cloud will be substituted by the crowd where model training is brought to the edge, allowing IoT devices to collaboratively extract knowledge and build smart analytics/models while keeping their personal data stored locally. This paradigm shift was set into motion by the tremendous increase in computational power on IoT devices and the recent advances in decentralized and privacy-preserving model training, coined as federated learning (FL). This article provides a vision for IoFT and a systematic overview of current efforts towards realizing this vision. Specifically, we first introduce the defining characteristics of IoFT and discuss FL data-driven approaches, opportunities, and challenges that allow decentralized inference within three dimensions: (i) a global model that maximizes utility across all IoT devices, (ii) a personalized model that borrows strengths across all devices yet retains its own model, (iii) a meta-learning model that quickly adapts to new devices or learning tasks. We end by describing the vision and challenges of IoFT in reshaping different industries through the lens of domain experts. Those industries include manufacturing, transportation, energy, healthcare, quality & reliability, business, and computing.
Improved Prediction and Network Estimation Using the Monotone Single Index Multi-variate Autoregressive Model
Jun 29, 2021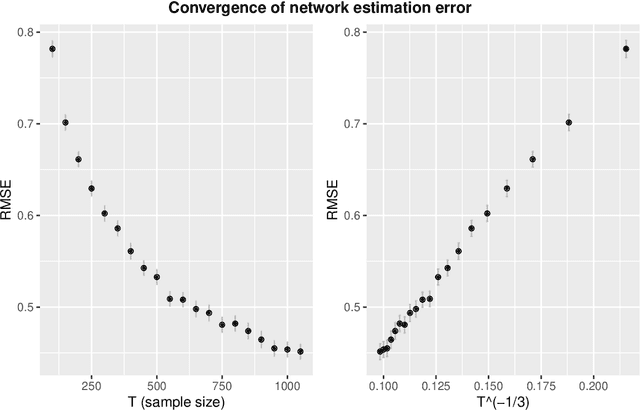

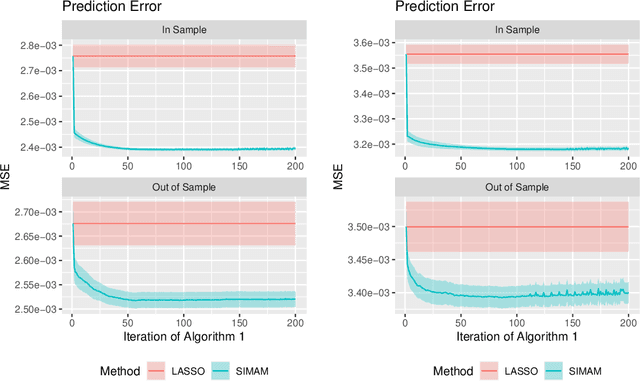

Network estimation from multi-variate point process or time series data is a problem of fundamental importance. Prior work has focused on parametric approaches that require a known parametric model, which makes estimation procedures less robust to model mis-specification, non-linearities and heterogeneities. In this paper, we develop a semi-parametric approach based on the monotone single-index multi-variate autoregressive model (SIMAM) which addresses these challenges. We provide theoretical guarantees for dependent data and an alternating projected gradient descent algorithm. Significantly we do not explicitly assume mixing conditions on the process (although we do require conditions analogous to restricted strong convexity) and we achieve rates of the form $O(T^{-\frac{1}{3}} \sqrt{s\log(TM)})$ (optimal in the independent design case) where $s$ is the threshold for the maximum in-degree of the network that indicates the sparsity level, $M$ is the number of actors and $T$ is the number of time points. In addition, we demonstrate the superior performance both on simulated data and two real data examples where our SIMAM approach out-performs state-of-the-art parametric methods both in terms of prediction and network estimation.
Prediction in the presence of response-dependent missing labels
Mar 25, 2021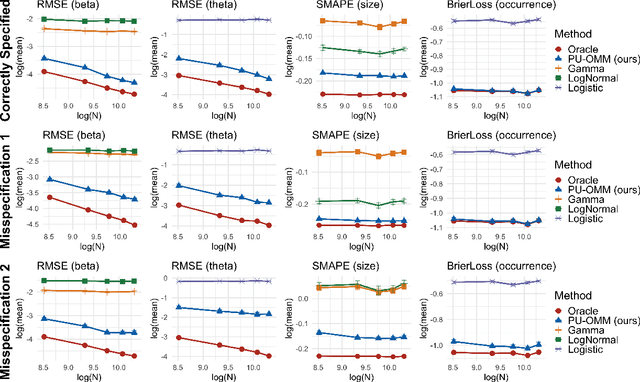
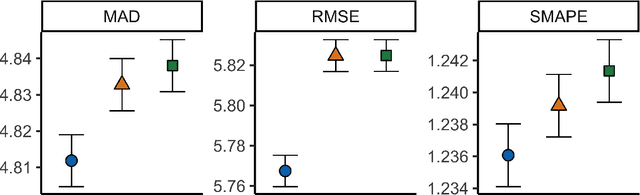
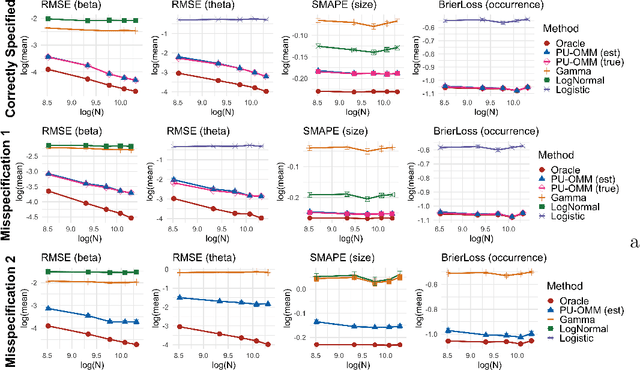
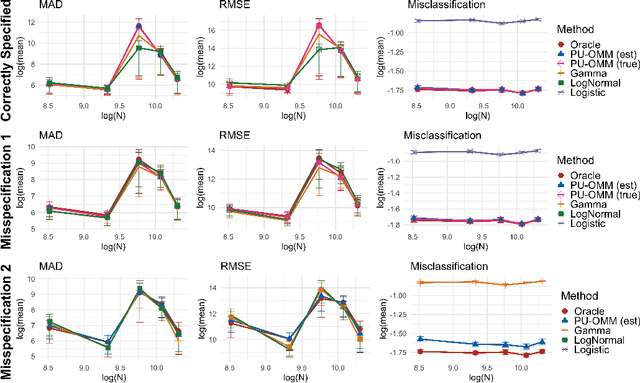
In a variety of settings, limitations of sensing technologies or other sampling mechanisms result in missing labels, where the likelihood of a missing label in the training set is an unknown function of the data. For example, satellites used to detect forest fires cannot sense fires below a certain size threshold. In such cases, training datasets consist of positive and pseudo-negative observations where pseudo-negative observations can be either true negatives or undetected positives with small magnitudes. We develop a new methodology and non-convex algorithm P(ositive) U(nlabeled) - O(ccurrence) M(agnitude) M(ixture) which jointly estimates the occurrence and detection likelihood of positive samples, utilizing prior knowledge of the detection mechanism. Our approach uses ideas from positive-unlabeled (PU)-learning and zero-inflated models that jointly estimate the magnitude and occurrence of events. We provide conditions under which our model is identifiable and prove that even though our approach leads to a non-convex objective, any local minimizer has optimal statistical error (up to a log term) and projected gradient descent has geometric convergence rates. We demonstrate on both synthetic data and a California wildfire dataset that our method out-performs existing state-of-the-art approaches.