 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
Apr 16, 2022

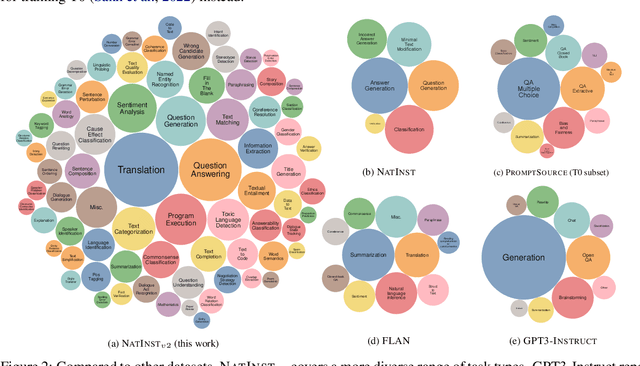
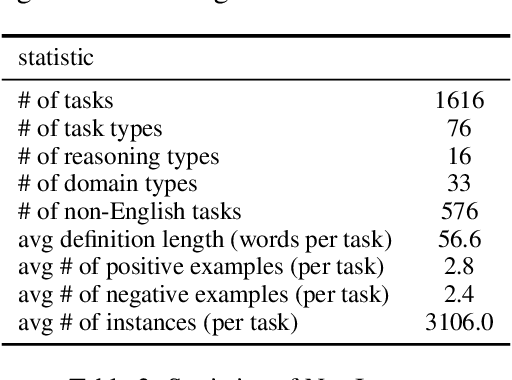
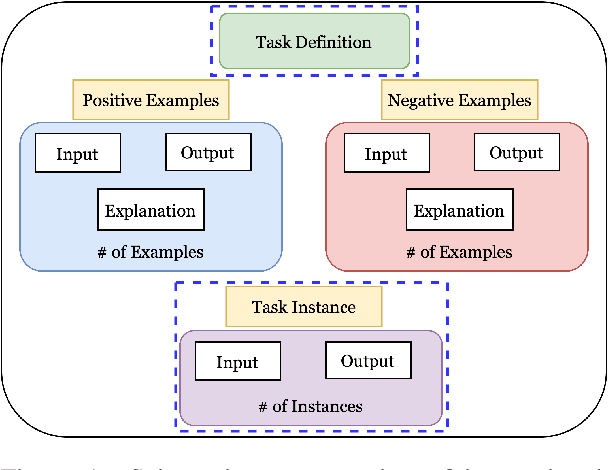
How can we measure the generalization of models to a variety of unseen tasks when provided with their language instructions? To facilitate progress in this goal, we introduce Natural-Instructions v2, a collection of 1,600+ diverse language tasks and their expert written instructions. More importantly, the benchmark covers 70+ distinct task types, such as tagging, in-filling, and rewriting. This benchmark is collected with contributions of NLP practitioners in the community and through an iterative peer review process to ensure their quality. This benchmark enables large-scale evaluation of cross-task generalization of the models -- training on a subset of tasks and evaluating on the remaining unseen ones. For instance, we are able to rigorously quantify generalization as a function of various scaling parameters, such as the number of observed tasks, the number of instances, and model sizes. As a by-product of these experiments. we introduce Tk-Instruct, an encoder-decoder Transformer that is trained to follow a variety of in-context instructions (plain language task definitions or k-shot examples) which outperforms existing larger models on our benchmark. We hope this benchmark facilitates future progress toward more general-purpose language understanding models.
How Many Data Samples is an Additional Instruction Worth?
Mar 18, 2022

Recently introduced instruction-paradigm empowers non-expert users to leverage NLP resources by defining a new task in natural language. Instruction-tuned models have significantly outperformed multitask learning models (without instruction); however they are far from state of the art task specific models. Conventional approaches to improve model performance via creating large datasets with lots of task instances or architectural/training changes in model may not be feasible for non-expert users. However, they can write alternate instructions to represent an instruction task. Is Instruction-augumentation helpful? We augment a subset of tasks in the expanded version of NATURAL INSTRUCTIONS with additional instructions and find that these significantly improve model performance (up to 35%), especially in the low-data regime. Our results indicate that an additional instruction can be equivalent to ~200 data samples on average across tasks.