 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Prosociality in Multi-Agent Games Through Gifting
May 13, 2021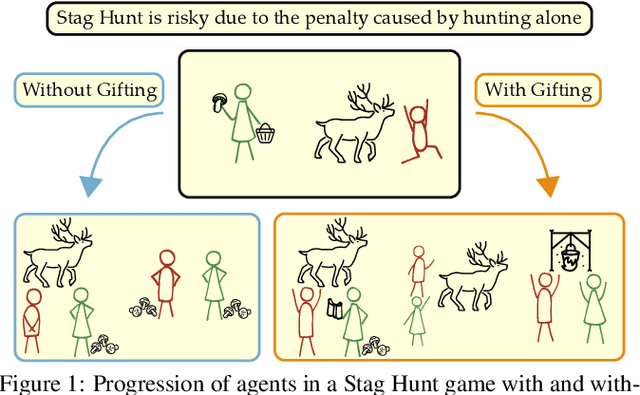
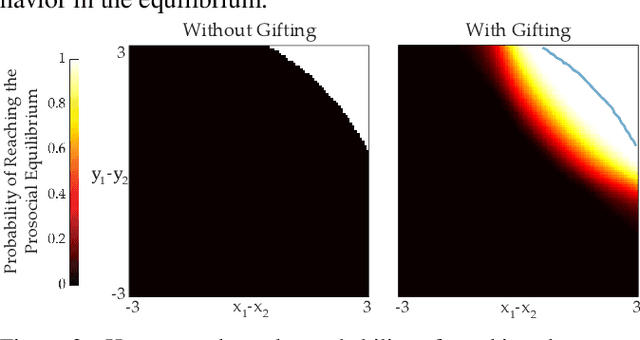

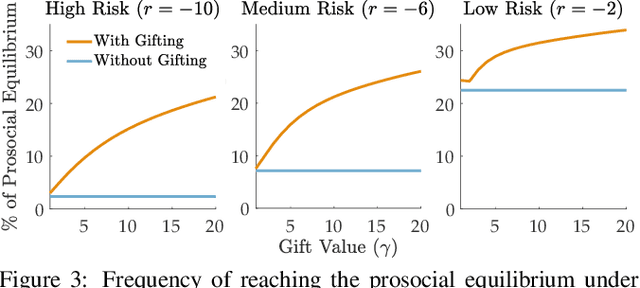
Coordination is often critical to forming prosocial behaviors -- behaviors that increase the overall sum of rewards received by all agents in a multi-agent game. However, state of the art reinforcement learning algorithms often suffer from converging to socially less desirable equilibria when multiple equilibria exist. Previous works address this challenge with explicit reward shaping, which requires the strong assumption that agents can be forced to be prosocial. We propose using a less restrictive peer-rewarding mechanism, gifting, that guides the agents toward more socially desirable equilibria while allowing agents to remain selfish and decentralized. Gifting allows each agent to give some of their reward to other agents. We employ a theoretical framework that captures the benefit of gifting in converging to the prosocial equilibrium by characterizing the equilibria's basins of attraction in a dynamical system. With gifting, we demonstrate increased convergence of high risk, general-sum coordination games to the prosocial equilibrium both via numerical analysis and experiments.
Robust Classification Under $\ell_0$ Attack for the Gaussian Mixture Model
Apr 05, 2021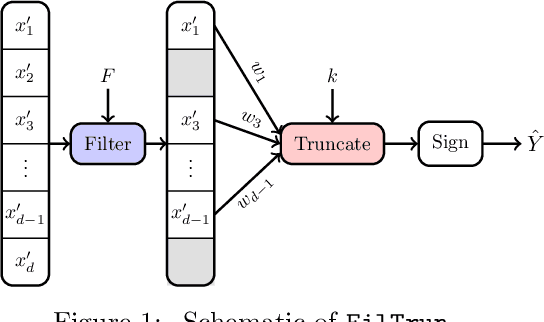
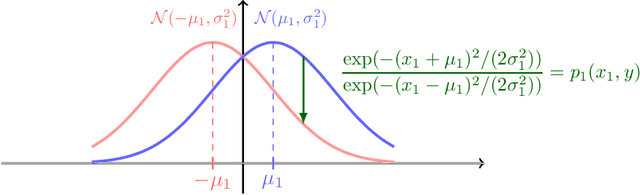

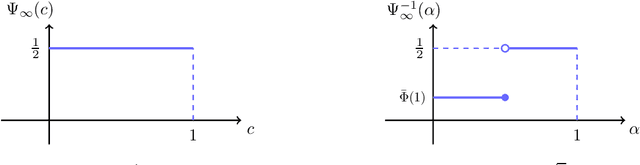
It is well-known that machine learning models are vulnerable to small but cleverly-designed adversarial perturbations that can cause misclassification. While there has been major progress in designing attacks and defenses for various adversarial settings, many fundamental and theoretical problems are yet to be resolved. In this paper, we consider classification in the presence of $\ell_0$-bounded adversarial perturbations, a.k.a. sparse attacks. This setting is significantly different from other $\ell_p$-adversarial settings, with $p\geq 1$, as the $\ell_0$-ball is non-convex and highly non-smooth. Under the assumption that data is distributed according to the Gaussian mixture model, our goal is to characterize the optimal robust classifier and the corresponding robust classification error as well as a variety of trade-offs between robustness, accuracy, and the adversary's budget. To this end, we develop a novel classification algorithm called FilTrun that has two main modules: Filtration and Truncation. The key idea of our method is to first filter out the non-robust coordinates of the input and then apply a carefully-designed truncated inner product for classification. By analyzing the performance of FilTrun, we derive an upper bound on the optimal robust classification error. We also find a lower bound by designing a specific adversarial strategy that enables us to derive the corresponding robust classifier and its achieved error. For the case that the covariance matrix of the Gaussian mixtures is diagonal, we show that as the input's dimension gets large, the upper and lower bounds converge; i.e. we characterize the asymptotically-optimal robust classifier. Throughout, we discuss several examples that illustrate interesting behaviors such as the existence of a phase transition for adversary's budget determining whether the effect of adversarial perturbation can be fully neutralized.
Straggler-Resilient Federated Learning: Leveraging the Interplay Between Statistical Accuracy and System Heterogeneity
Dec 28, 2020

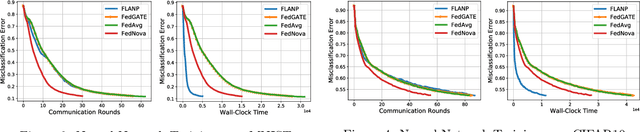
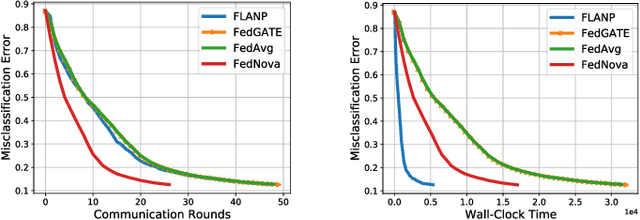
Federated Learning is a novel paradigm that involves learning from data samples distributed across a large network of clients while the data remains local. It is, however, known that federated learning is prone to multiple system challenges including system heterogeneity where clients have different computation and communication capabilities. Such heterogeneity in clients' computation speeds has a negative effect on the scalability of federated learning algorithms and causes significant slow-down in their runtime due to the existence of stragglers. In this paper, we propose a novel straggler-resilient federated learning method that incorporates statistical characteristics of the clients' data to adaptively select the clients in order to speed up the learning procedure. The key idea of our algorithm is to start the training procedure with faster nodes and gradually involve the slower nodes in the model training once the statistical accuracy of the data corresponding to the current participating nodes is reached. The proposed approach reduces the overall runtime required to achieve the statistical accuracy of data of all nodes, as the solution for each stage is close to the solution of the subsequent stage with more samples and can be used as a warm-start. Our theoretical results characterize the speedup gain in comparison to standard federated benchmarks for strongly convex objectives, and our numerical experiments also demonstrate significant speedups in wall-clock time of our straggler-resilient method compared to federated learning benchmarks.
Incentivizing Routing Choices for Safe and Efficient Transportation in the Face of the COVID-19 Pandemic
Dec 28, 2020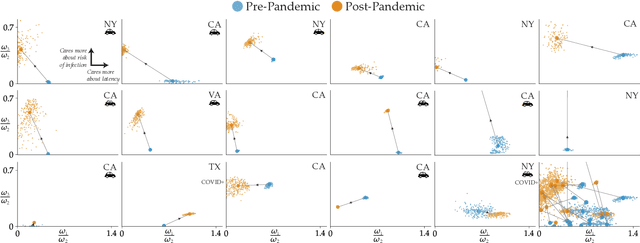
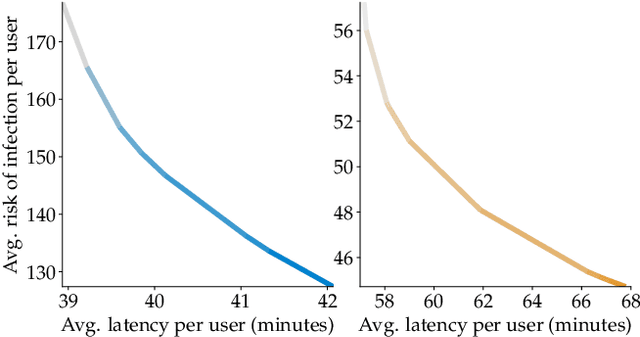
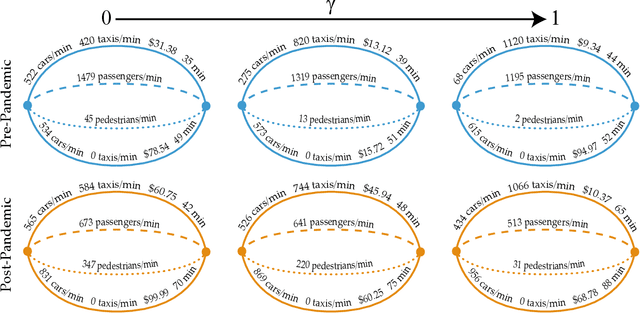
The COVID-19 pandemic has severely affected many aspects of people's daily lives. While many countries are in a re-opening stage, some effects of the pandemic on people's behaviors are expected to last much longer, including how they choose between different transport options. Experts predict considerably delayed recovery of the public transport options, as people try to avoid crowded places. In turn, significant increases in traffic congestion are expected, since people are likely to prefer using their own vehicles or taxis as opposed to riskier and more crowded options such as the railway. In this paper, we propose to use financial incentives to set the tradeoff between risk of infection and congestion to achieve safe and efficient transportation networks. To this end, we formulate a network optimization problem to optimize taxi fares. For our framework to be useful in various cities and times of the day without much designer effort, we also propose a data-driven approach to learn human preferences about transport options, which is then used in our taxi fare optimization. Our user studies and simulation experiments show our framework is able to minimize congestion and risk of infection.
Adversarially Robust Classification based on GLRT
Nov 16, 2020
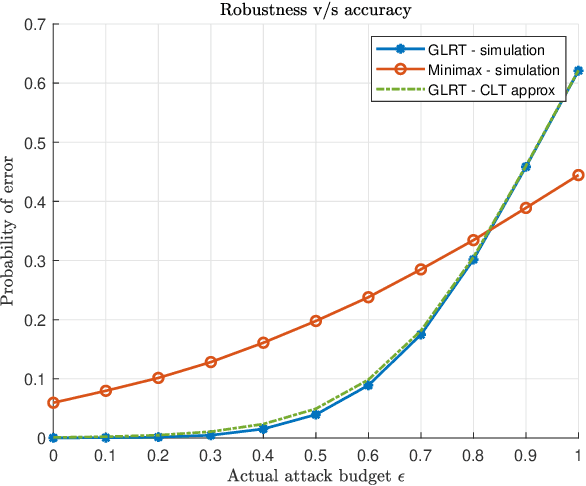
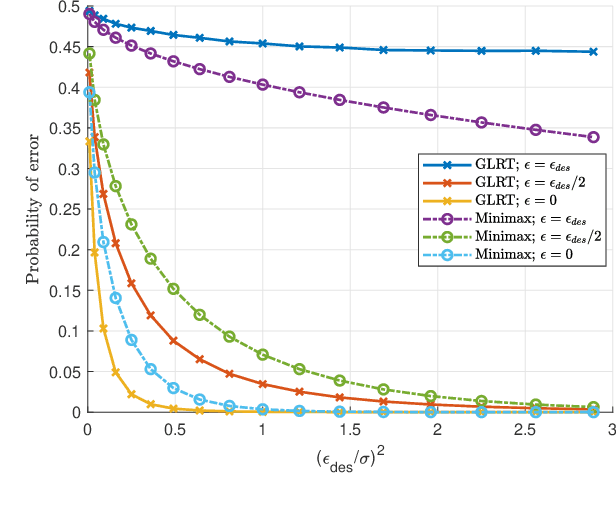
Machine learning models are vulnerable to adversarial attacks that can often cause misclassification by introducing small but well designed perturbations. In this paper, we explore, in the setting of classical composite hypothesis testing, a defense strategy based on the generalized likelihood ratio test (GLRT), which jointly estimates the class of interest and the adversarial perturbation. We evaluate the GLRT approach for the special case of binary hypothesis testing in white Gaussian noise under $\ell_{\infty}$ norm-bounded adversarial perturbations, a setting for which a minimax strategy optimizing for the worst-case attack is known. We show that the GLRT approach yields performance competitive with that of the minimax approach under the worst-case attack, and observe that it yields a better robustness-accuracy trade-off under weaker attacks, depending on the values of signal components relative to the attack budget. We also observe that the GLRT defense generalizes naturally to more complex models for which optimal minimax classifiers are not known.
Asymptotic Behavior of Adversarial Training in Binary Classification
Oct 26, 2020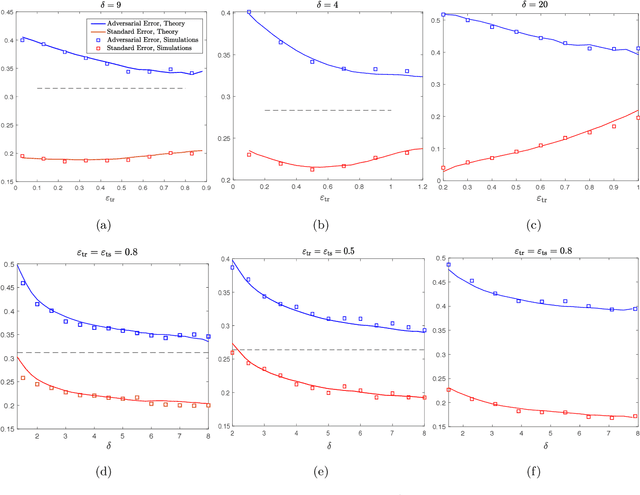
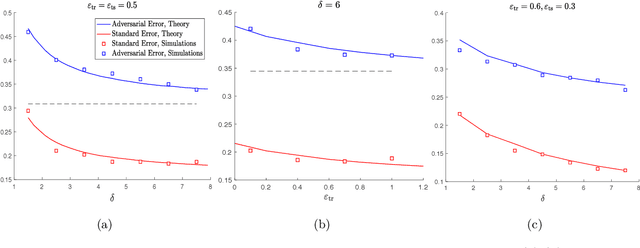
It is widely known that several machine learning models are susceptible to adversarial attacks i.e., small adversarial perturbations applied to data points causing the model to misclassify the data. Adversarial training using empirical risk minimization methods, is the state-of-the-art method for defense against adversarial attacks. Despite being successful, several problems in understanding generalization performance of adversarial training remain open. In this paper, we derive precise theoretical predictions for the performance of adversarial training in binary linear classification. We consider the modern high-dimensional regime where the dimension of data grows with the size of the training dataset at a constant ratio. Our results provide exact asymptotics for the performance of estimators obtained by adversarial training with $\ell_q$-norm bounded perturbations ($q \ge 1$) and for binary labels and Gaussian features. These sharp predictions enable us to explore the role of various factors including over-parametrization ratio, data model and attack budget on the performance of adversarial training.
Fundamental Limits of Ridge-Regularized Empirical Risk Minimization in High Dimensions
Jul 05, 2020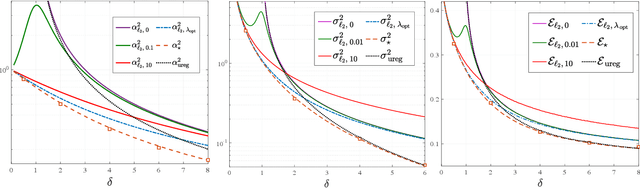
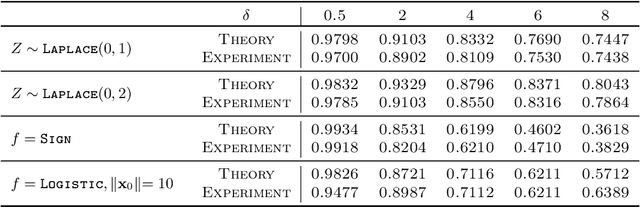
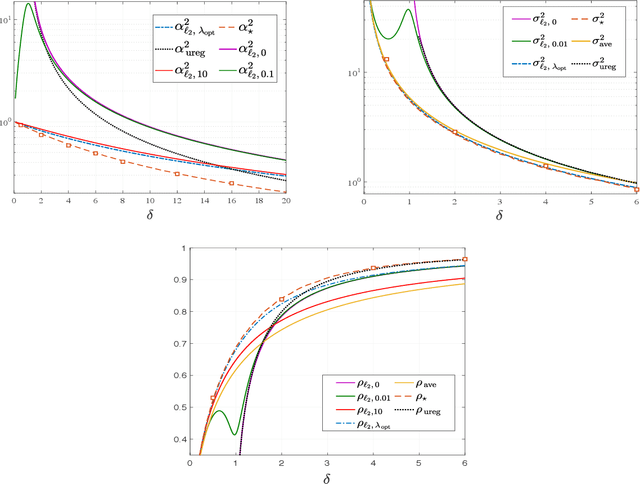
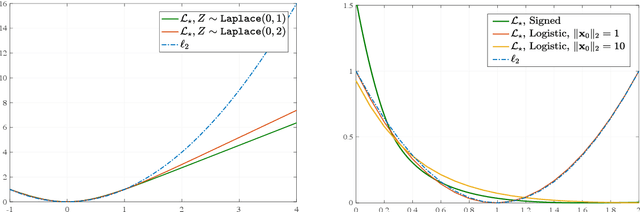
Empirical Risk Minimization (ERM) algorithms are widely used in a variety of estimation and prediction tasks in signal-processing and machine learning applications. Despite their popularity, a theory that explains their statistical properties in modern regimes where both the number of measurements and the number of unknown parameters is large is only recently emerging. In this paper, we characterize for the first time the fundamental limits on the statistical accuracy of convex ERM for inference in high-dimensional generalized linear models. For a stylized setting with Gaussian features and problem dimensions that grow large at a proportional rate, we start with sharp performance characterizations and then derive tight lower bounds on the estimation and prediction error that hold over a wide class of loss functions and for any value of the regularization parameter. Our precise analysis has several attributes. First, it leads to a recipe for optimally tuning the loss function and the regularization parameter. Second, it allows to precisely quantify the sub-optimality of popular heuristic choices: for instance, we show that optimally-tuned least-squares is (perhaps surprisingly) approximately optimal for standard logistic data, but the sub-optimality gap grows drastically as the signal strength increases. Third, we use the bounds to precisely assess the merits of ridge-regularization as a function of the over-parameterization ratio. Notably, our bounds are expressed in terms of the Fisher Information of random variables that are simple functions of the data distribution, thus making ties to corresponding bounds in classical statistics.
Robust Federated Learning: The Case of Affine Distribution Shifts
Jun 16, 2020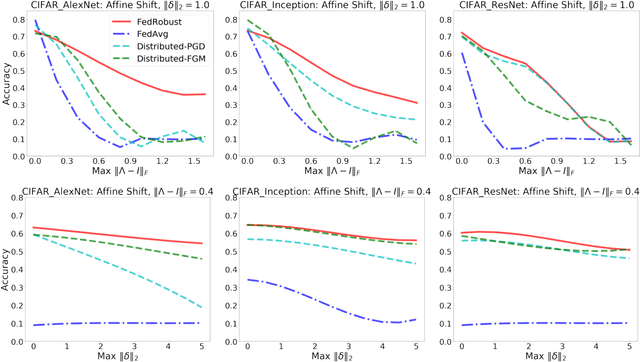

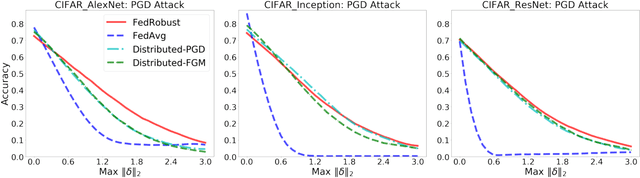
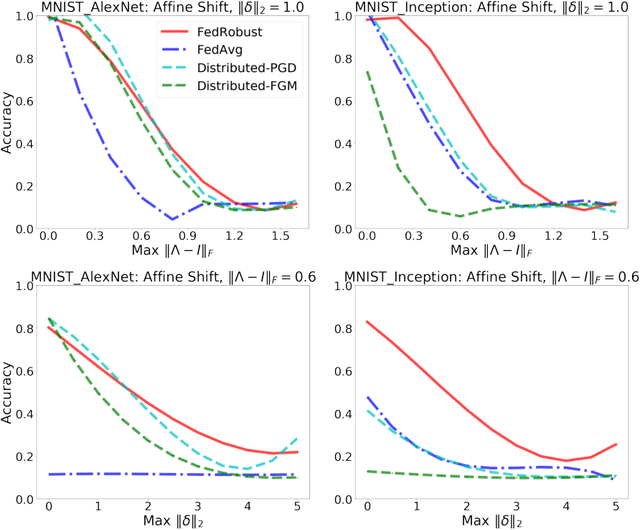
Federated learning is a distributed paradigm that aims at training models using samples distributed across multiple users in a network while keeping the samples on users' devices with the aim of efficiency and protecting users privacy. In such settings, the training data is often statistically heterogeneous and manifests various distribution shifts across users, which degrades the performance of the learnt model. The primary goal of this paper is to develop a robust federated learning algorithm that achieves satisfactory performance against distribution shifts in users' samples. To achieve this goal, we first consider a structured affine distribution shift in users' data that captures the device-dependent data heterogeneity in federated settings. This perturbation model is applicable to various federated learning problems such as image classification where the images undergo device-dependent imperfections, e.g. different intensity, contrast, and brightness. To address affine distribution shifts across users, we propose a Federated Learning framework Robust to Affine distribution shifts (FLRA) that is provably robust against affine Wasserstein shifts to the distribution of observed samples. To solve the FLRA's distributed minimax problem, we propose a fast and efficient optimization method and provide convergence guarantees via a gradient Descent Ascent (GDA) method. We further prove generalization error bounds for the learnt classifier to show proper generalization from empirical distribution of samples to the true underlying distribution. We perform several numerical experiments to empirically support FLRA. We show that an affine distribution shift indeed suffices to significantly decrease the performance of the learnt classifier in a new test user, and our proposed algorithm achieves a significant gain in comparison to standard federated learning and adversarial training methods.
Sharp Asymptotics and Optimal Performance for Inference in Binary Models
Feb 26, 2020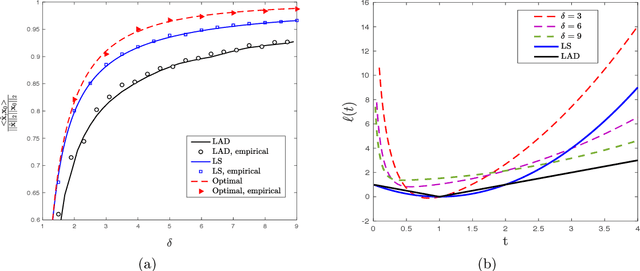

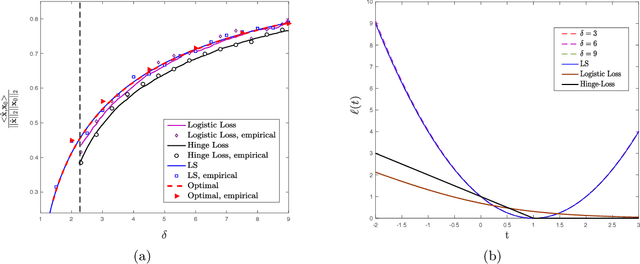
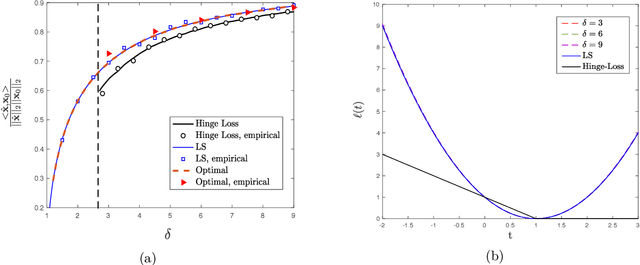
We study convex empirical risk minimization for high-dimensional inference in binary models. Our first result sharply predicts the statistical performance of such estimators in the linear asymptotic regime under isotropic Gaussian features. Importantly, the predictions hold for a wide class of convex loss functions, which we exploit in order to prove a bound on the best achievable performance among them. Notably, we show that the proposed bound is tight for popular binary models (such as Signed, Logistic or Probit), by constructing appropriate loss functions that achieve it. More interestingly, for binary linear classification under the Logistic and Probit models, we prove that the performance of least-squares is no worse than 0.997 and 0.98 times the optimal one. Numerical simulations corroborate our theoretical findings and suggest they are accurate even for relatively small problem dimensions.
Quantized Push-sum for Gossip and Decentralized Optimization over Directed Graphs
Feb 25, 2020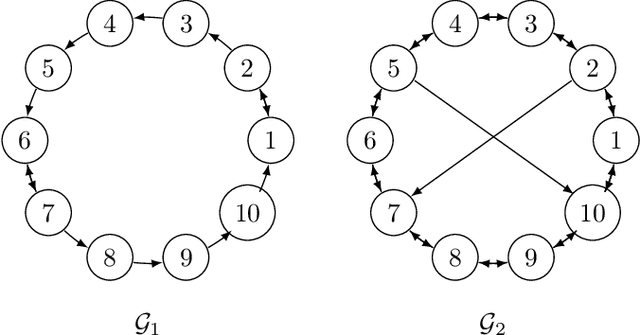
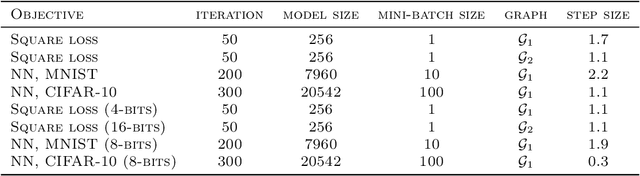
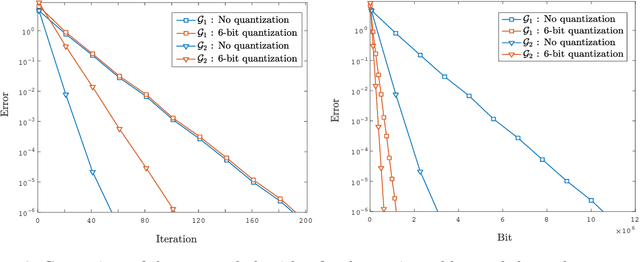
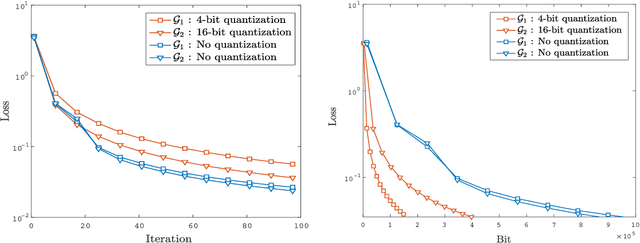
We consider a decentralized stochastic learning problem where data points are distributed among computing nodes communicating over a directed graph. As the model size gets large, decentralized learning faces a major bottleneck that is the heavy communication load due to each node transmitting large messages (model updates) to its neighbors. To tackle this bottleneck, we propose the quantized decentralized stochastic learning algorithm over directed graphs that is based on the push-sum algorithm in decentralized consensus optimization. More importantly, we prove that our algorithm achieves the same convergence rates of the decentralized stochastic learning algorithm with exact-communication for both convex and non-convex losses. A key technical challenge of the work is to prove exact convergence of the proposed decentralized learning algorithm in the presence of quantization noise with unbounded variance over directed graphs. We provide numerical evaluations that corroborate our main theoretical results and illustrate significant speed-up compared to the exact-communication methods.