 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter-Level Language Modeling with Deeper Self-Attention
Aug 09, 2018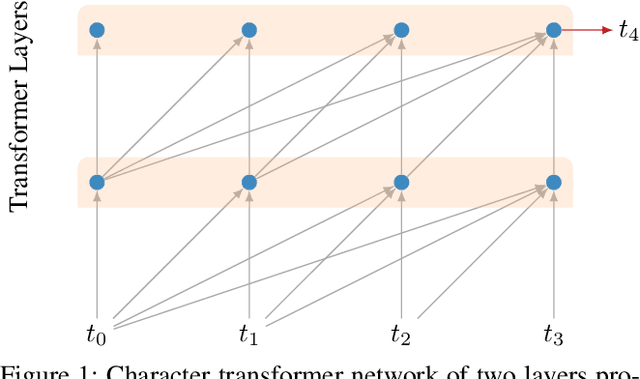
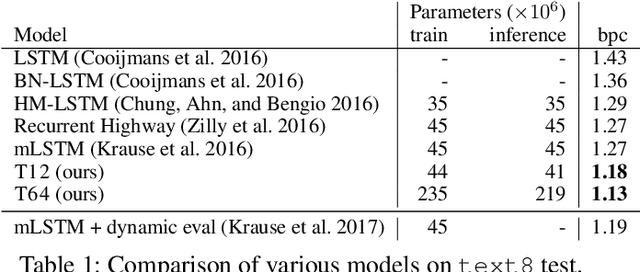
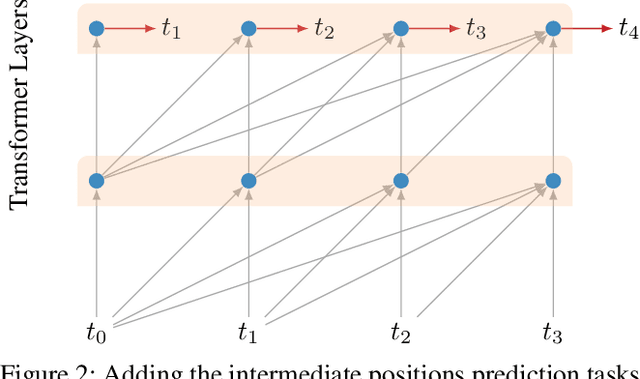
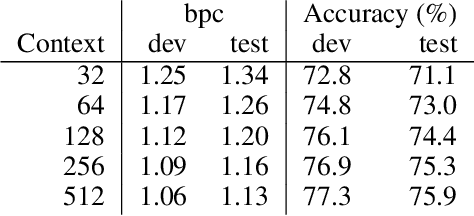
LSTMs and other RNN variants have shown strong performance on character-level language modeling. These models are typically trained using truncated backpropagation through time, and it is common to assume that their success stems from their ability to remember long-term contexts. In this paper, we show that a deep (64-layer) transformer model with fixed context outperforms RNN variants by a large margin, achieving state of the art on two popular benchmarks- 1.13 bits per character on text8 and 1.06 on enwik8. To get good results at this depth, we show that it is important to add auxiliary losses, both at intermediate network layers and intermediate sequence positions.
Learning Edge Representations via Low-Rank Asymmetric Projections
Sep 13, 2017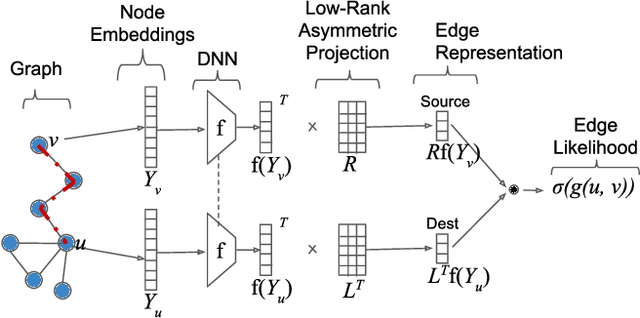
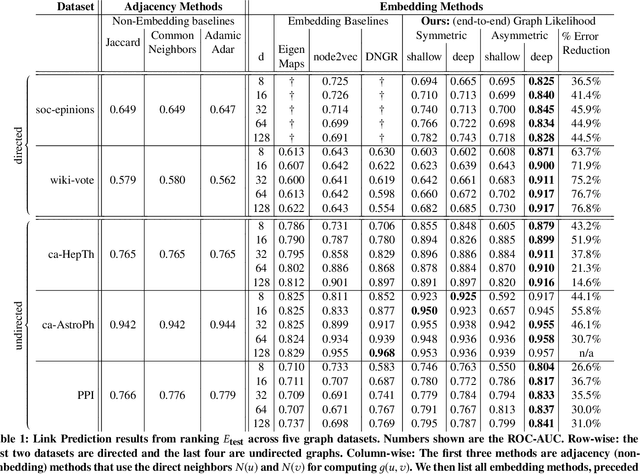
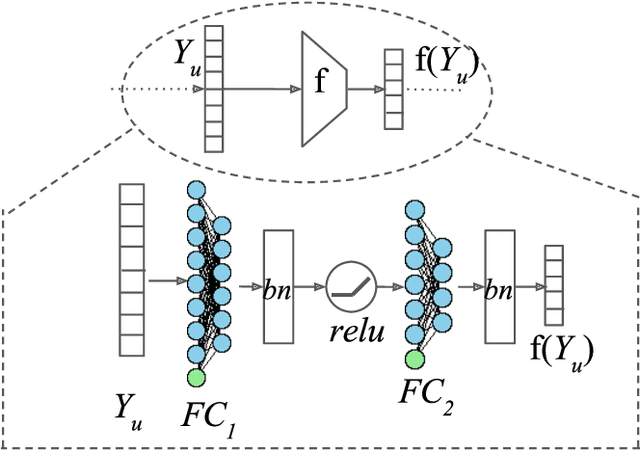
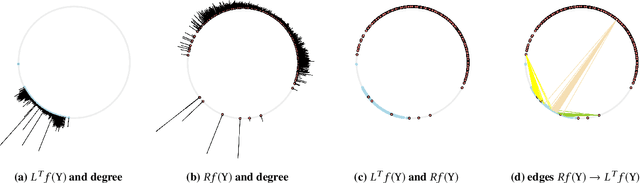
We propose a new method for embedding graphs while preserving directed edge information. Learning such continuous-space vector representations (or embeddings) of nodes in a graph is an important first step for using network information (from social networks, user-item graphs, knowledge bases, etc.) in many machine learning tasks. Unlike previous work, we (1) explicitly model an edge as a function of node embeddings, and we (2) propose a novel objective, the "graph likelihood", which contrasts information from sampled random walks with non-existent edges. Individually, both of these contributions improve the learned representations, especially when there are memory constraints on the total size of the embeddings. When combined, our contributions enable us to significantly improve the state-of-the-art by learning more concise representations that better preserve the graph structure. We evaluate our method on a variety of link-prediction task including social networks, collaboration networks, and protein interactions, showing that our proposed method learn representations with error reductions of up to 76% and 55%, on directed and undirected graphs. In addition, we show that the representations learned by our method are quite space efficient, producing embeddings which have higher structure-preserving accuracy but are 10 times smaller.
Efficient Natural Language Response Suggestion for Smart Reply
May 01, 2017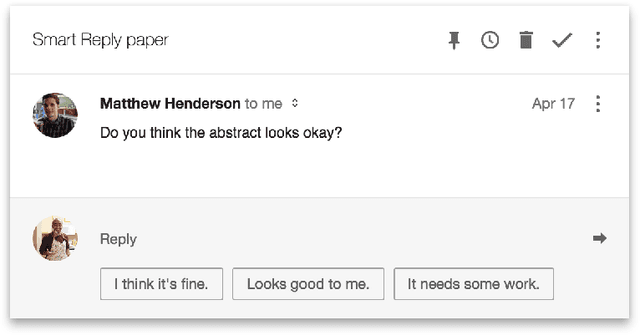

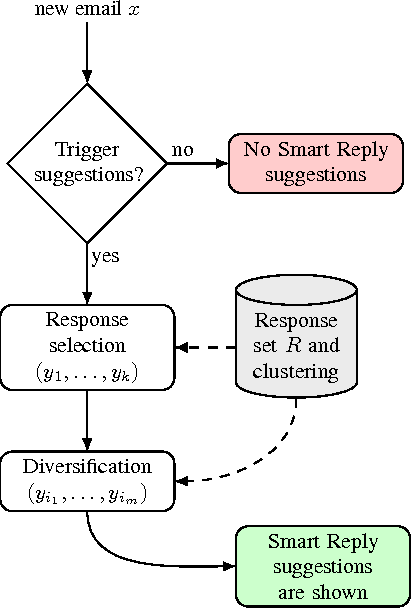
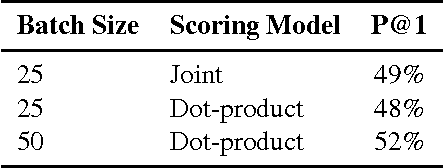
This paper presents a computationally efficient machine-learned method for natural language response suggestion. Feed-forward neural networks using n-gram embedding features encode messages into vectors which are optimized to give message-response pairs a high dot-product value. An optimized search finds response suggestions. The method is evaluated in a large-scale commercial e-mail application, Inbox by Gmail. Compared to a sequence-to-sequence approach, the new system achieves the same quality at a small fraction of the computational requirements and latency.
Visualizing Linguistic Shift
Nov 20, 2016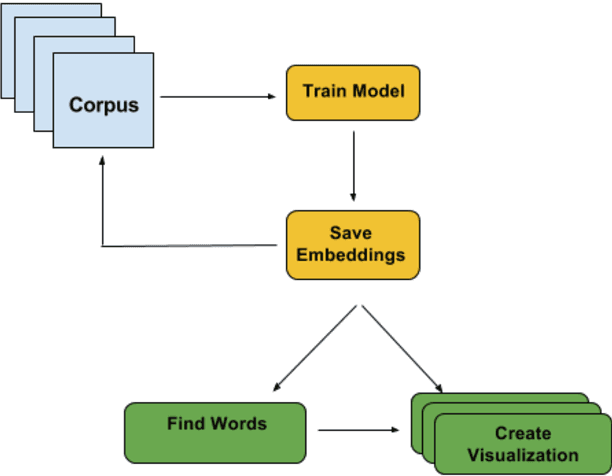
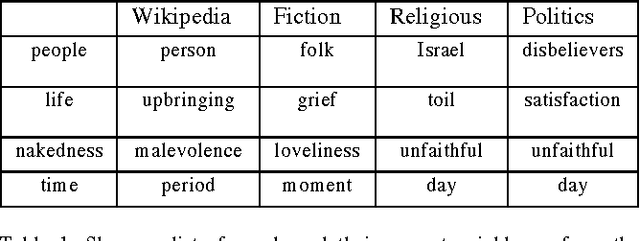

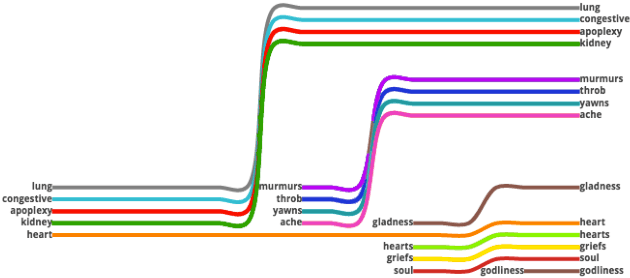
Neural network based models are a very powerful tool for creating word embeddings, the objective of these models is to group similar words together. These embeddings have been used as features to improve results in various applications such as document classification, named entity recognition, etc. Neural language models are able to learn word representations which have been used to capture semantic shifts across time and geography. The objective of this paper is to first identify and then visualize how words change meaning in different text corpus. We will train a neural language model on texts from a diverse set of disciplines philosophy, religion, fiction etc. Each text will alter the embeddings of the words to represent the meaning of the word inside that text. We will present a computational technique to detect words that exhibit significant linguistic shift in meaning and usage. We then use enhanced scatterplots and storyline visualization to visualize the linguistic shift.
A Growing Long-term Episodic & Semantic Memory
Oct 20, 2016
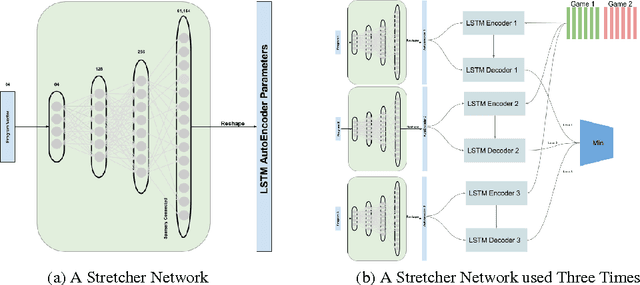
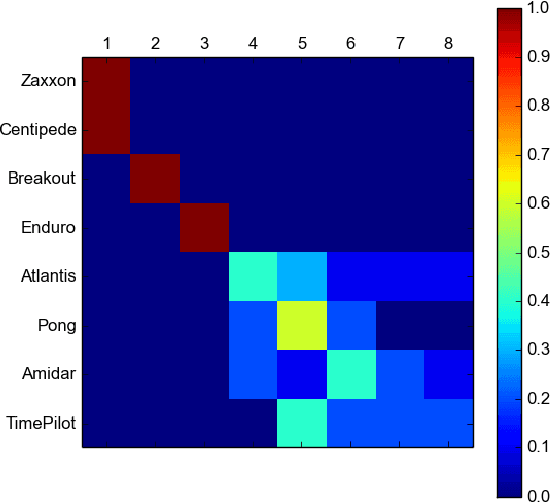
The long-term memory of most connectionist systems lies entirely in the weights of the system. Since the number of weights is typically fixed, this bounds the total amount of knowledge that can be learned and stored. Though this is not normally a problem for a neural network designed for a specific task, such a bound is undesirable for a system that continually learns over an open range of domains. To address this, we describe a lifelong learning system that leverages a fast, though non-differentiable, content-addressable memory which can be exploited to encode both a long history of sequential episodic knowledge and semantic knowledge over many episodes for an unbounded number of domains. This opens the door for investigation into transfer learning, and leveraging prior knowledge that has been learned over a lifetime of experiences to new domains.
Conversational Contextual Cues: The Case of Personalization and History for Response Ranking
Jun 01, 2016



We investigate the task of modeling open-domain, multi-turn, unstructured, multi-participant, conversational dialogue. We specifically study the effect of incorporating different elements of the conversation. Unlike previous efforts, which focused on modeling messages and responses, we extend the modeling to long context and participant's history. Our system does not rely on handwritten rules or engineered features; instead, we train deep neural networks on a large conversational dataset. In particular, we exploit the structure of Reddit comments and posts to extract 2.1 billion messages and 133 million conversations. We evaluate our models on the task of predicting the next response in a conversation, and we find that modeling both context and participants improves prediction accuracy.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
Statistically Significant Detection of Linguistic Change
Nov 12, 2014

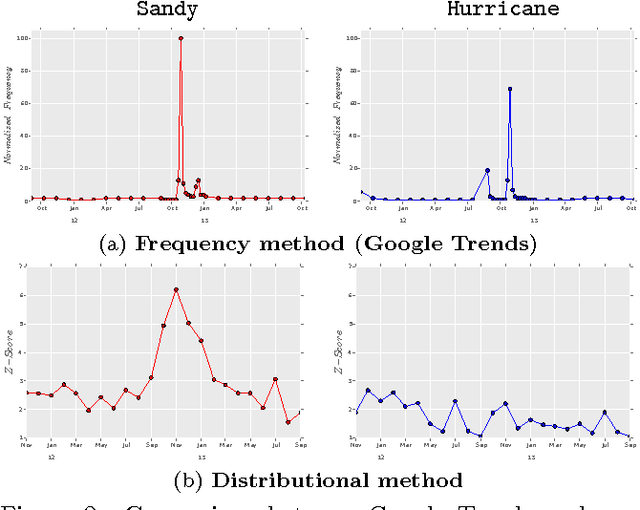
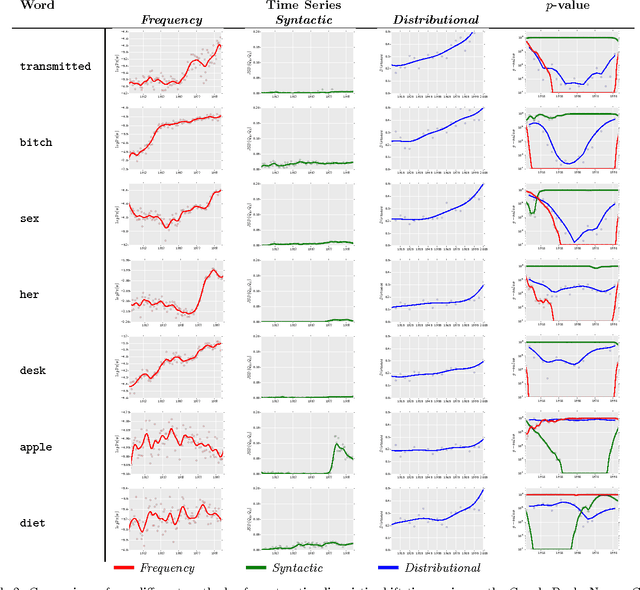
We propose a new computational approach for tracking and detecting statistically significant linguistic shifts in the meaning and usage of words. Such linguistic shifts are especially prevalent on the Internet, where the rapid exchange of ideas can quickly change a word's meaning. Our meta-analysis approach constructs property time series of word usage, and then uses statistically sound change point detection algorithms to identify significant linguistic shifts. We consider and analyze three approaches of increasing complexity to generate such linguistic property time series, the culmination of which uses distributional characteristics inferred from word co-occurrences. Using recently proposed deep neural language models, we first train vector representations of words for each time period. Second, we warp the vector spaces into one unified coordinate system. Finally, we construct a distance-based distributional time series for each word to track it's linguistic displacement over time. We demonstrate that our approach is scalable by tracking linguistic change across years of micro-blogging using Twitter, a decade of product reviews using a corpus of movie reviews from Amazon, and a century of written books using the Google Book-ngrams. Our analysis reveals interesting patterns of language usage change commensurate with each medium.
POLYGLOT-NER: Massive Multilingual Named Entity Recognition
Oct 14, 2014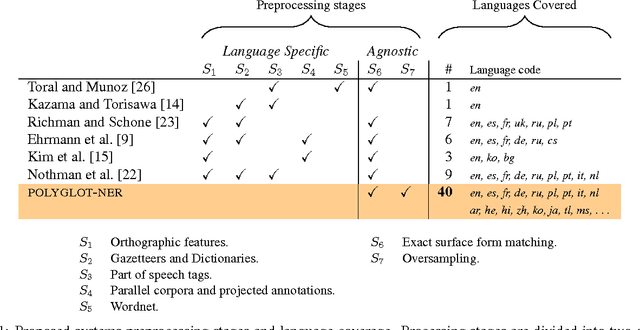
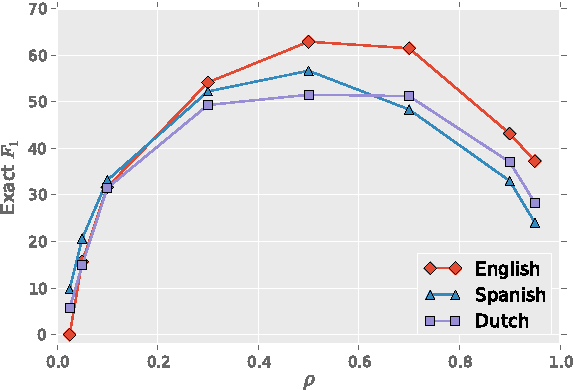
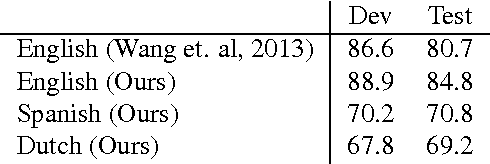
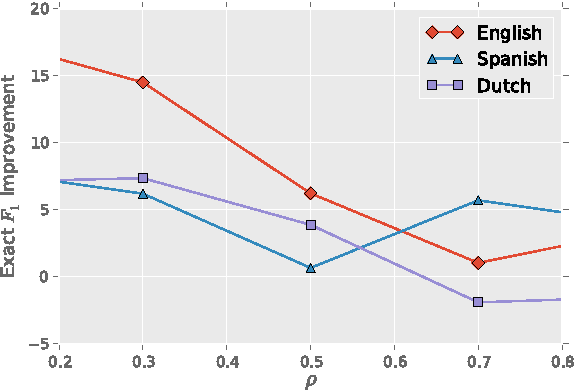
The increasing diversity of languages used on the web introduces a new level of complexity to Information Retrieval (IR) systems. We can no longer assume that textual content is written in one language or even the same language family. In this paper, we demonstrate how to build massive multilingual annotators with minimal human expertise and intervention. We describe a system that builds Named Entity Recognition (NER) annotators for 40 major languages using Wikipedia and Freebase. Our approach does not require NER human annotated datasets or language specific resources like treebanks, parallel corpora, and orthographic rules. The novelty of approach lies therein - using only language agnostic techniques, while achieving competitive performance. Our method learns distributed word representations (word embeddings) which encode semantic and syntactic features of words in each language. Then, we automatically generate datasets from Wikipedia link structure and Freebase attributes. Finally, we apply two preprocessing stages (oversampling and exact surface form matching) which do not require any linguistic expertise. Our evaluation is two fold: First, we demonstrate the system performance on human annotated datasets. Second, for languages where no gold-standard benchmarks are available, we propose a new method, distant evaluation, based on statistical machine translation.
Inducing Language Networks from Continuous Space Word Representations
Jun 27, 2014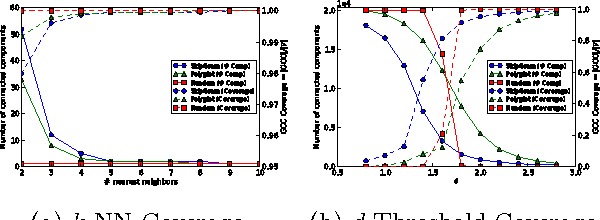

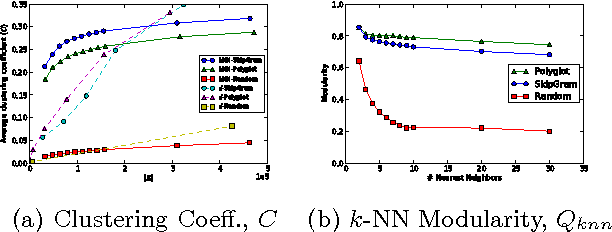

Recent advancements in unsupervised feature learning have developed powerful latent representations of words. However, it is still not clear what makes one representation better than another and how we can learn the ideal representation. Understanding the structure of latent spaces attained is key to any future advancement in unsupervised learning. In this work, we introduce a new view of continuous space word representations as language networks. We explore two techniques to create language networks from learned features by inducing them for two popular word representation methods and examining the properties of their resulting networks. We find that the induced networks differ from other methods of creating language networks, and that they contain meaningful community structure.