 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgenmT5 -- Is parallel data still relevant for pre-training massively multilingual language models?
Jun 03, 2021
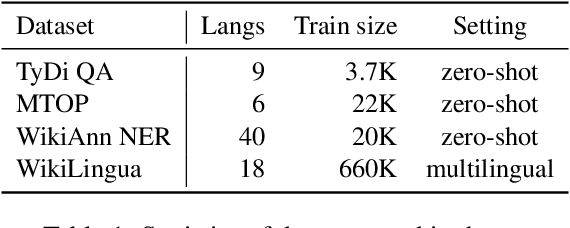
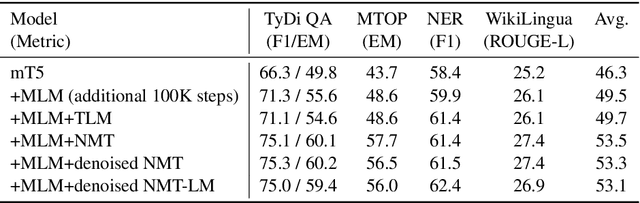
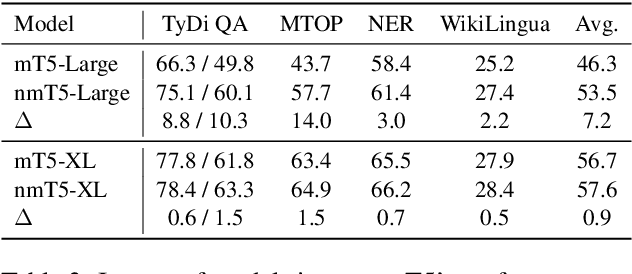
Recently, mT5 - a massively multilingual version of T5 - leveraged a unified text-to-text format to attain state-of-the-art results on a wide variety of multilingual NLP tasks. In this paper, we investigate the impact of incorporating parallel data into mT5 pre-training. We find that multi-tasking language modeling with objectives such as machine translation during pre-training is a straightforward way to improve performance on downstream multilingual and cross-lingual tasks. However, the gains start to diminish as the model capacity increases, suggesting that parallel data might not be as essential for larger models. At the same time, even at larger model sizes, we find that pre-training with parallel data still provides benefits in the limited labelled data regime.
ByT5: Towards a token-free future with pre-trained byte-to-byte models
May 28, 2021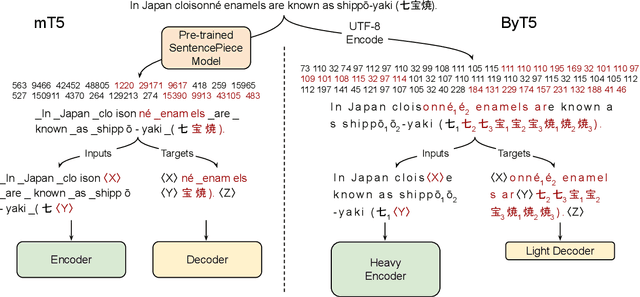
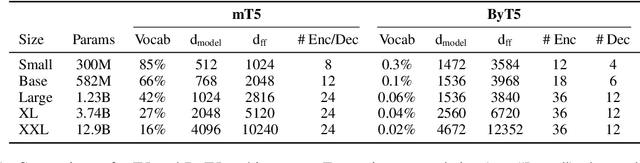
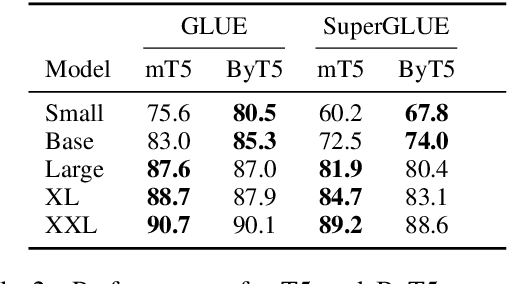
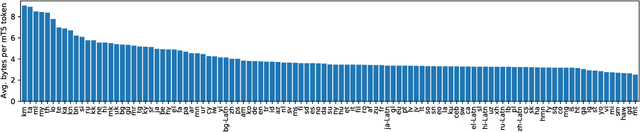
Most widely-used pre-trained language models operate on sequences of tokens corresponding to word or subword units. Encoding text as a sequence of tokens requires a tokenizer, which is typically created as an independent artifact from the model. Token-free models that instead operate directly on raw text (bytes or characters) have many benefits: they can process text in any language out of the box, they are more robust to noise, and they minimize technical debt by removing complex and error-prone text preprocessing pipelines. Since byte or character sequences are longer than token sequences, past work on token-free models has often introduced new model architectures designed to amortize the cost of operating directly on raw text. In this paper, we show that a standard Transformer architecture can be used with minimal modifications to process byte sequences. We carefully characterize the trade-offs in terms of parameter count, training FLOPs, and inference speed, and show that byte-level models are competitive with their token-level counterparts. We also demonstrate that byte-level models are significantly more robust to noise and perform better on tasks that are sensitive to spelling and pronunciation. As part of our contribution, we release a new set of pre-trained byte-level Transformer models based on the T5 architecture, as well as all code and data used in our experiments.
The Power of Scale for Parameter-Efficient Prompt Tuning
Apr 18, 2021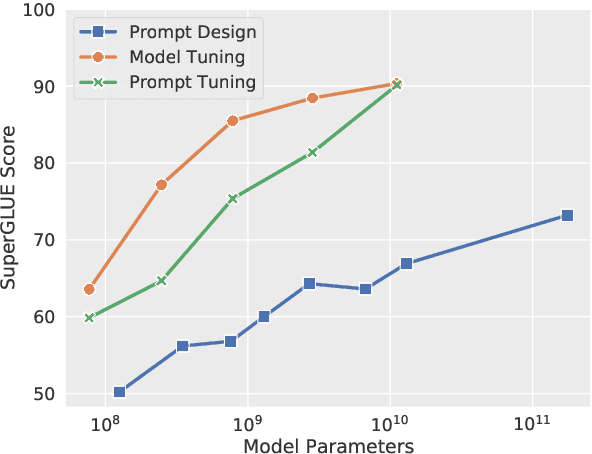
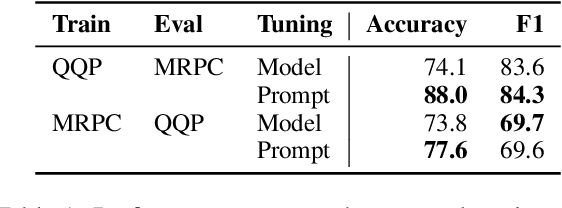
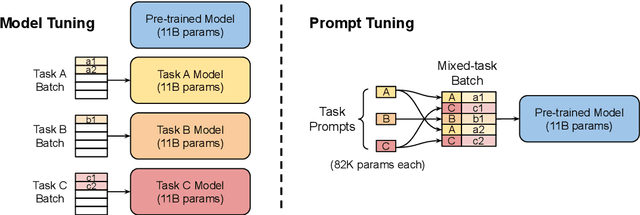
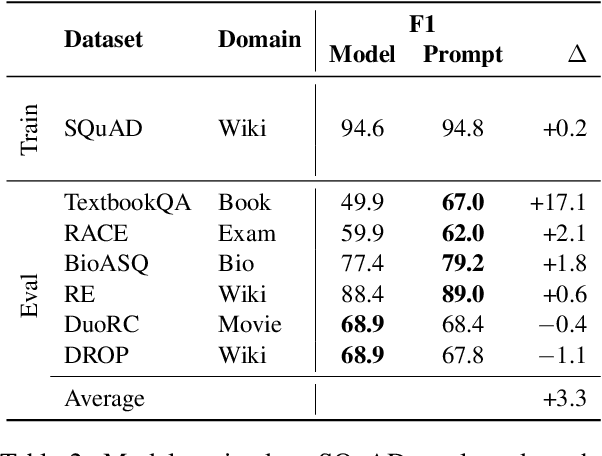
In this work, we explore "prompt tuning", a simple yet effective mechanism for learning "soft prompts" to condition frozen language models to perform specific downstream tasks. Unlike the discrete text prompts used by GPT-3, soft prompts are learned through backpropagation and can be tuned to incorporate signal from any number of labeled examples. Our end-to-end learned approach outperforms GPT-3's "few-shot" learning by a large margin. More remarkably, through ablations on model size using T5, we show that prompt tuning becomes more competitive with scale: as models exceed billions of parameters, our method "closes the gap" and matches the strong performance of model tuning (where all model weights are tuned). This finding is especially relevant in that large models are costly to share and serve, and the ability to reuse one frozen model for multiple downstream tasks can ease this burden. Our method can be seen as a simplification of the recently proposed "prefix tuning" of Li and Liang (2021), and we provide a comparison to this and other similar approaches. Finally, we show that conditioning a frozen model with soft prompts confers benefits in robustness to domain transfer, as compared to full model tuning.
Large Scale Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training
Oct 23, 2020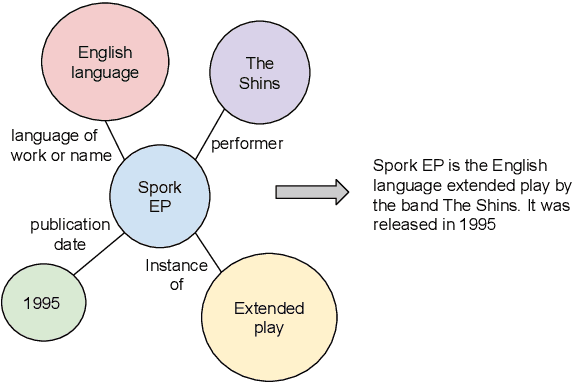

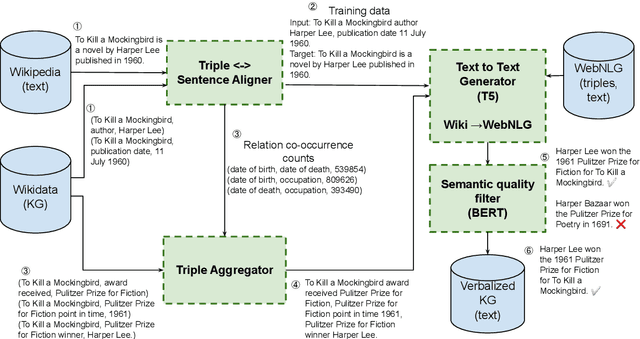
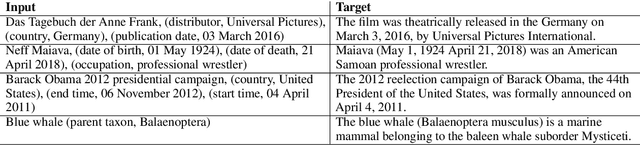
Generating natural sentences from Knowledge Graph (KG) triples, known as Data-To-Text Generation, is a task with many datasets for which numerous complex systems have been developed. However, no prior work has attempted to perform this generation at scale by converting an entire KG into natural text. In this paper, we verbalize the entire Wikidata KG, and create a KG-Text aligned corpus in the training process. We discuss the challenges in verbalizing an entire KG versus verbalizing smaller datasets. We further show that verbalizing an entire KG can be used to integrate structured and natural language data. In contrast to the many architectures that have been developed to integrate the structural differences between these two sources, our approach converts the KG into the same format as natural text allowing it to be seamlessly plugged into existing natural language systems. We evaluate this approach by augmenting the retrieval corpus in REALM and showing improvements, both on the LAMA knowledge probe and open domain QA.
mT5: A massively multilingual pre-trained text-to-text transformer
Oct 23, 2020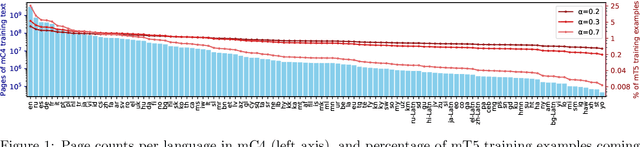

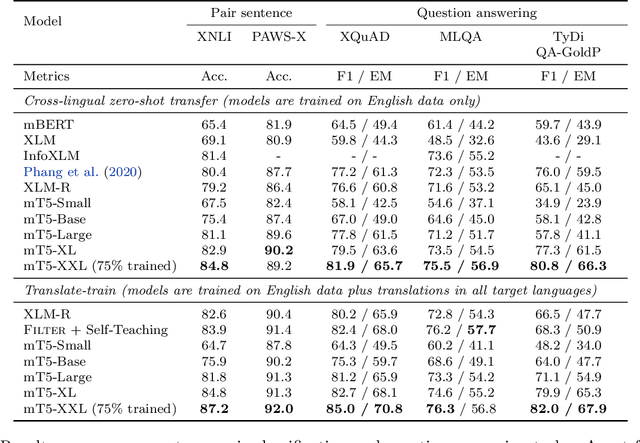
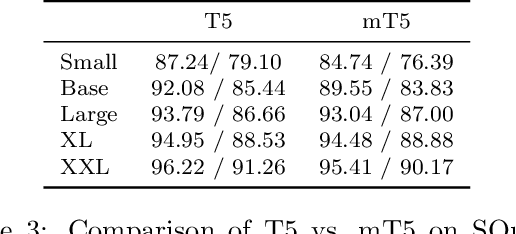
The recent "Text-to-Text Transfer Transformer" (T5) leveraged a unified text-to-text format and scale to attain state-of-the-art results on a wide variety of English-language NLP tasks. In this paper, we introduce mT5, a multilingual variant of T5 that was pre-trained on a new Common Crawl-based dataset covering 101 languages. We describe the design and modified training of mT5 and demonstrate its state-of-the-art performance on many multilingual benchmarks. All of the code and model checkpoints used in this work are publicly available.
LAReQA: Language-agnostic answer retrieval from a multilingual pool
Apr 11, 2020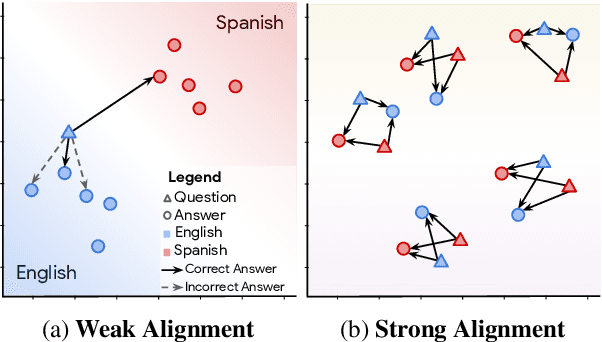
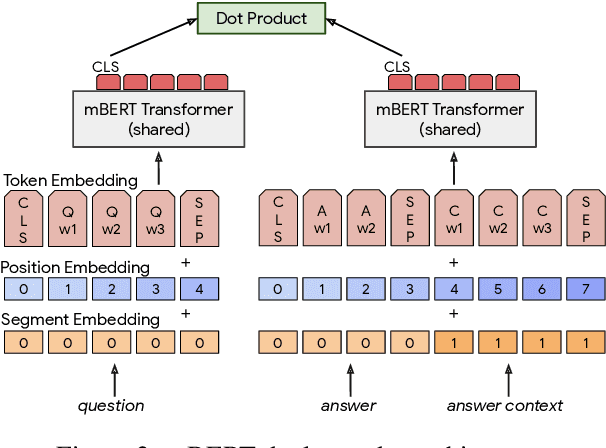
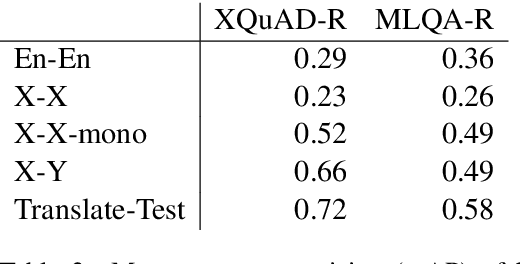
We present LAReQA, a challenging new benchmark for language-agnostic answer retrieval from a multilingual candidate pool. Unlike previous cross-lingual tasks, LAReQA tests for "strong" cross-lingual alignment, requiring semantically related cross-language pairs to be closer in representation space than unrelated same-language pairs. Building on multilingual BERT (mBERT), we study different strategies for achieving strong alignment. We find that augmenting training data via machine translation is effective, and improves significantly over using mBERT out-of-the-box. Interestingly, the embedding baseline that performs the best on LAReQA falls short of competing baselines on zero-shot variants of our task that only target "weak" alignment. This finding underscores our claim that languageagnostic retrieval is a substantively new kind of cross-lingual evaluation.
Bridging the Gap for Tokenizer-Free Language Models
Aug 27, 2019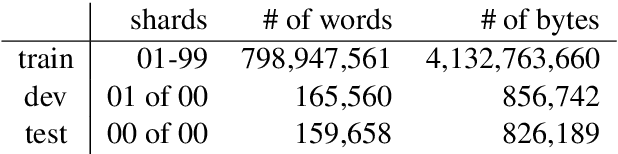
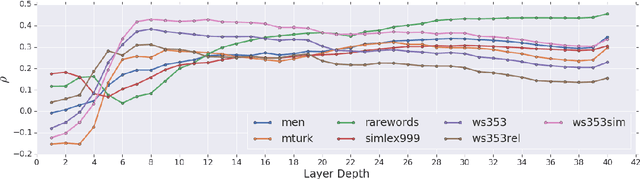
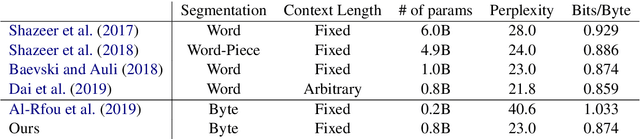
Purely character-based language models (LMs) have been lagging in quality on large scale datasets, and current state-of-the-art LMs rely on word tokenization. It has been assumed that injecting the prior knowledge of a tokenizer into the model is essential to achieving competitive results. In this paper, we show that contrary to this conventional wisdom, tokenizer-free LMs with sufficient capacity can achieve competitive performance on a large scale dataset. We train a vanilla transformer network with 40 self-attention layers on the One Billion Word (lm1b) benchmark and achieve a new state of the art for tokenizer-free LMs, pushing these models to be on par with their word-based counterparts.
DDGK: Learning Graph Representations for Deep Divergence Graph Kernels
Apr 21, 2019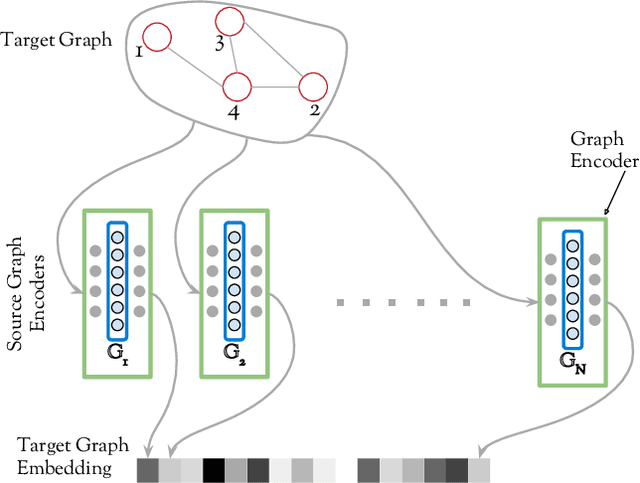

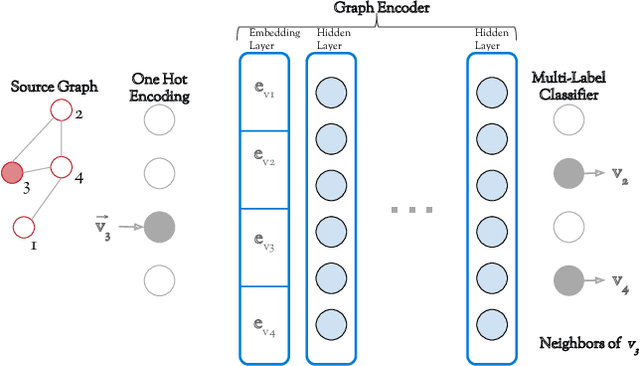
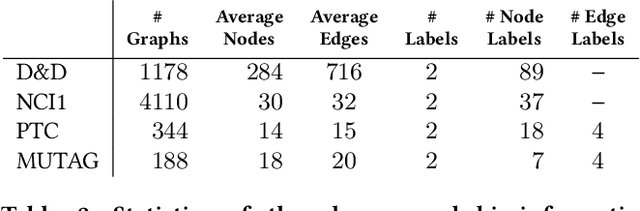
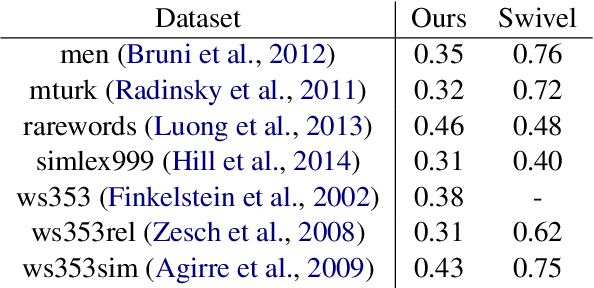
Can neural networks learn to compare graphs without feature engineering? In this paper, we show that it is possible to learn representations for graph similarity with neither domain knowledge nor supervision (i.e.\ feature engineering or labeled graphs). We propose Deep Divergence Graph Kernels, an unsupervised method for learning representations over graphs that encodes a relaxed notion of graph isomorphism. Our method consists of three parts. First, we learn an encoder for each anchor graph to capture its structure. Second, for each pair of graphs, we train a cross-graph attention network which uses the node representations of an anchor graph to reconstruct another graph. This approach, which we call isomorphism attention, captures how well the representations of one graph can encode another. We use the attention-augmented encoder's predictions to define a divergence score for each pair of graphs. Finally, we construct an embedding space for all graphs using these pair-wise divergence scores. Unlike previous work, much of which relies on 1) supervision, 2) domain specific knowledge (e.g. a reliance on Weisfeiler-Lehman kernels), and 3) known node alignment, our unsupervised method jointly learns node representations, graph representations, and an attention-based alignment between graphs. Our experimental results show that Deep Divergence Graph Kernels can learn an unsupervised alignment between graphs, and that the learned representations achieve competitive results when used as features on a number of challenging graph classification tasks. Furthermore, we illustrate how the learned attention allows insight into the the alignment of sub-structures across graphs.
* www '19
Watch Your Step: Learning Node Embeddings via Graph Attention
Sep 12, 2018
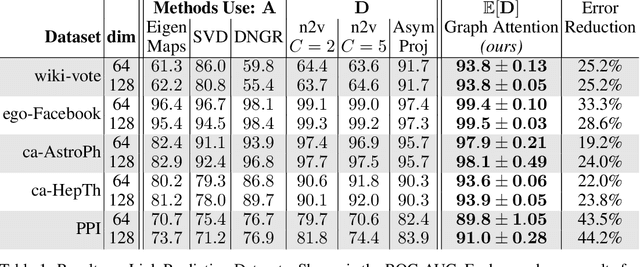
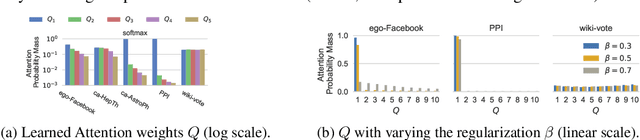

Graph embedding methods represent nodes in a continuous vector space, preserving information from the graph (e.g. by sampling random walks). There are many hyper-parameters to these methods (such as random walk length) which have to be manually tuned for every graph. In this paper, we replace random walk hyper-parameters with trainable parameters that we automatically learn via backpropagation. In particular, we learn a novel attention model on the power series of the transition matrix, which guides the random walk to optimize an upstream objective. Unlike previous approaches to attention models, the method that we propose utilizes attention parameters exclusively on the data (e.g. on the random walk), and not used by the model for inference. We experiment on link prediction tasks, as we aim to produce embeddings that best-preserve the graph structure, generalizing to unseen information. We improve state-of-the-art on a comprehensive suite of real world datasets including social, collaboration, and biological networks. Adding attention to random walks can reduce the error by 20% to 45% on datasets we attempted. Further, our learned attention parameters are different for every graph, and our automatically-found values agree with the optimal choice of hyper-parameter if we manually tune existing methods.
Creating Virtual Universes Using Generative Adversarial Networks
Aug 17, 2018
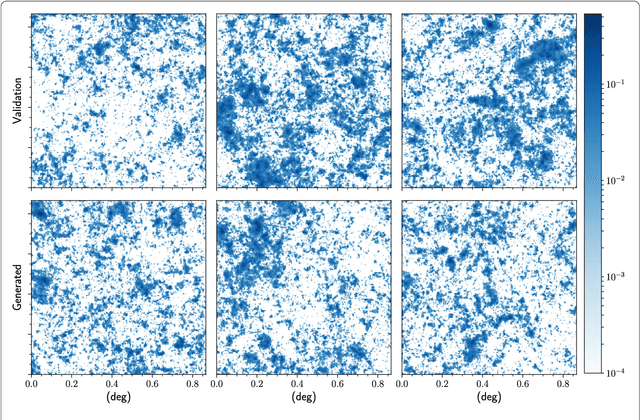

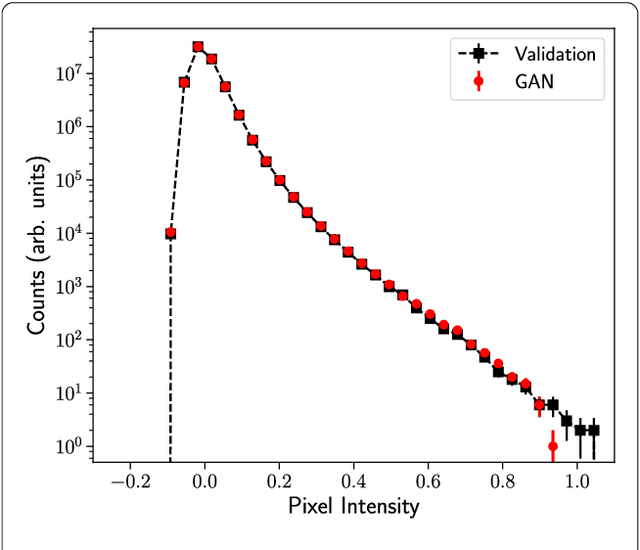
Inferring model parameters from experimental data is a grand challenge in many sciences, including cosmology. This often relies critically on high fidelity numerical simulations, which are prohibitively computationally expensive. The application of deep learning techniques to generative modeling is renewing interest in using high dimensional density estimators as computationally inexpensive emulators of fully-fledged simulations. These generative models have the potential to make a dramatic shift in the field of scientific simulations, but for that shift to happen we need to study the performance of such generators in the precision regime needed for science applications. To this end, in this letter we apply Generative Adversarial Networks to the problem of generating cosmological weak lensing convergence maps. We show that our generator network produces maps that are described by, with high statistical confidence, the same summary statistics as the fully simulated maps.