 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-driven Embedding Convolution
Jul 28, 2025Text embeddings are essential components in modern NLP pipelines. While numerous embedding models have been proposed, their performance varies across domains, and no single model consistently excels across all tasks. This variability motivates the use of ensemble techniques to combine complementary strengths. However, most existing ensemble methods operate on deterministic embeddings and fail to account for model-specific uncertainty, limiting their robustness and reliability in downstream applications. To address these limitations, we propose Uncertainty-driven Embedding Convolution (UEC). UEC first transforms deterministic embeddings into probabilistic ones in a post-hoc manner. It then computes adaptive ensemble weights based on embedding uncertainty, grounded in a Bayes-optimal solution under a surrogate loss. Additionally, UEC introduces an uncertainty-aware similarity function that directly incorporates uncertainty into similarity scoring. Extensive experiments on retrieval, classification, and semantic similarity benchmarks demonstrate that UEC consistently improves both performance and robustness by leveraging principled uncertainty modeling.
Perturb-and-Compare Approach for Detecting Out-of-Distribution Samples in Constrained Access Environments
Aug 19, 2024Accessing machine learning models through remote APIs has been gaining prevalence following the recent trend of scaling up model parameters for increased performance. Even though these models exhibit remarkable ability, detecting out-of-distribution (OOD) samples remains a crucial safety concern for end users as these samples may induce unreliable outputs from the model. In this work, we propose an OOD detection framework, MixDiff, that is applicable even when the model's parameters or its activations are not accessible to the end user. To bypass the access restriction, MixDiff applies an identical input-level perturbation to a given target sample and a similar in-distribution (ID) sample, then compares the relative difference in the model outputs of these two samples. MixDiff is model-agnostic and compatible with existing output-based OOD detection methods. We provide theoretical analysis to illustrate MixDiff's effectiveness in discerning OOD samples that induce overconfident outputs from the model and empirically demonstrate that MixDiff consistently enhances the OOD detection performance on various datasets in vision and text domains.
Bridging the Gap for Tokenizer-Free Language Models
Aug 27, 2019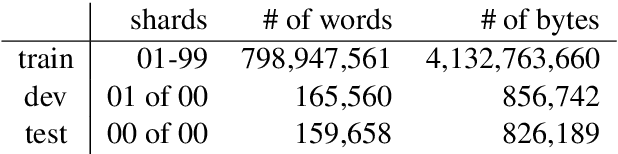
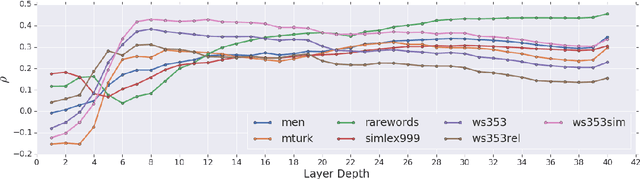
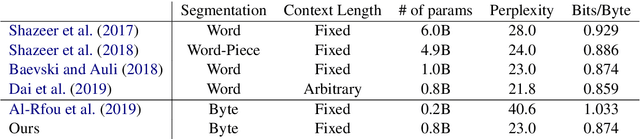
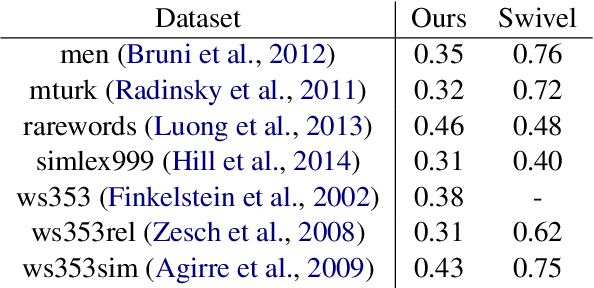
Purely character-based language models (LMs) have been lagging in quality on large scale datasets, and current state-of-the-art LMs rely on word tokenization. It has been assumed that injecting the prior knowledge of a tokenizer into the model is essential to achieving competitive results. In this paper, we show that contrary to this conventional wisdom, tokenizer-free LMs with sufficient capacity can achieve competitive performance on a large scale dataset. We train a vanilla transformer network with 40 self-attention layers on the One Billion Word (lm1b) benchmark and achieve a new state of the art for tokenizer-free LMs, pushing these models to be on par with their word-based counterparts.