 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate measurement of nonlinear correlations between data hosted across multiple parties
Nov 08, 2021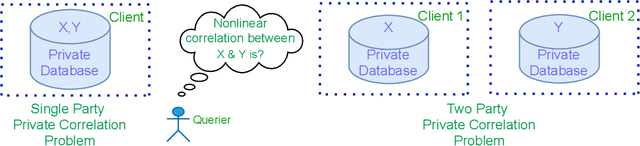

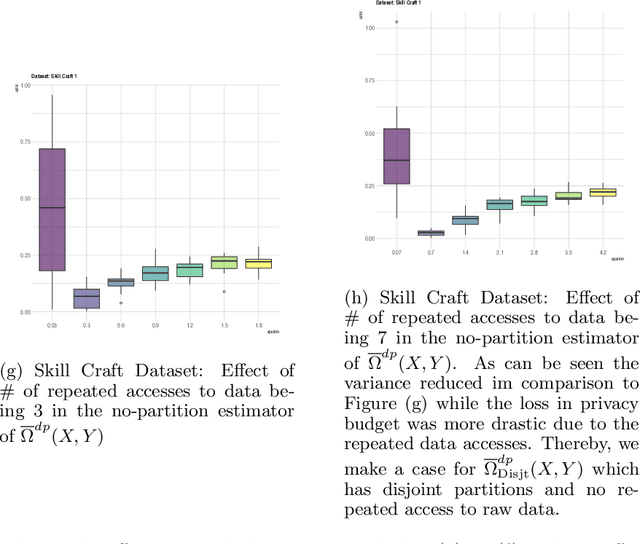
We introduce a differentially private method to measure nonlinear correlations between sensitive data hosted across two entities. We provide utility guarantees of our private estimator. Ours is the first such private estimator of nonlinear correlations, to the best of our knowledge within a multi-party setup. The important measure of nonlinear correlation we consider is distance correlation. This work has direct applications to private feature screening, private independence testing, private k-sample tests, private multi-party causal inference and private data synthesis in addition to exploratory data analysis. Code access: A link to publicly access the code is provided in the supplementary file.
DeepABM: Scalable, efficient and differentiable agent-based simulations via graph neural networks
Oct 09, 2021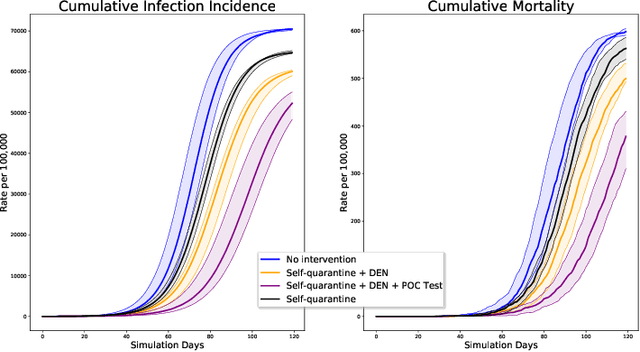

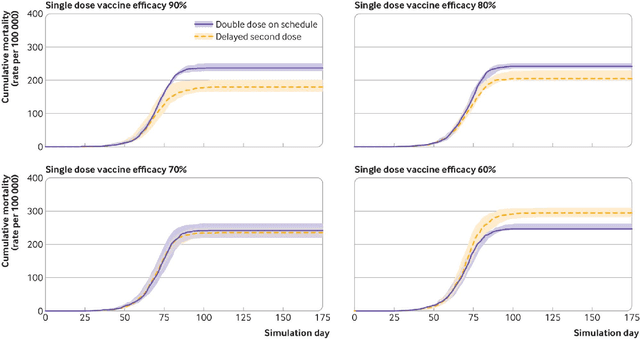
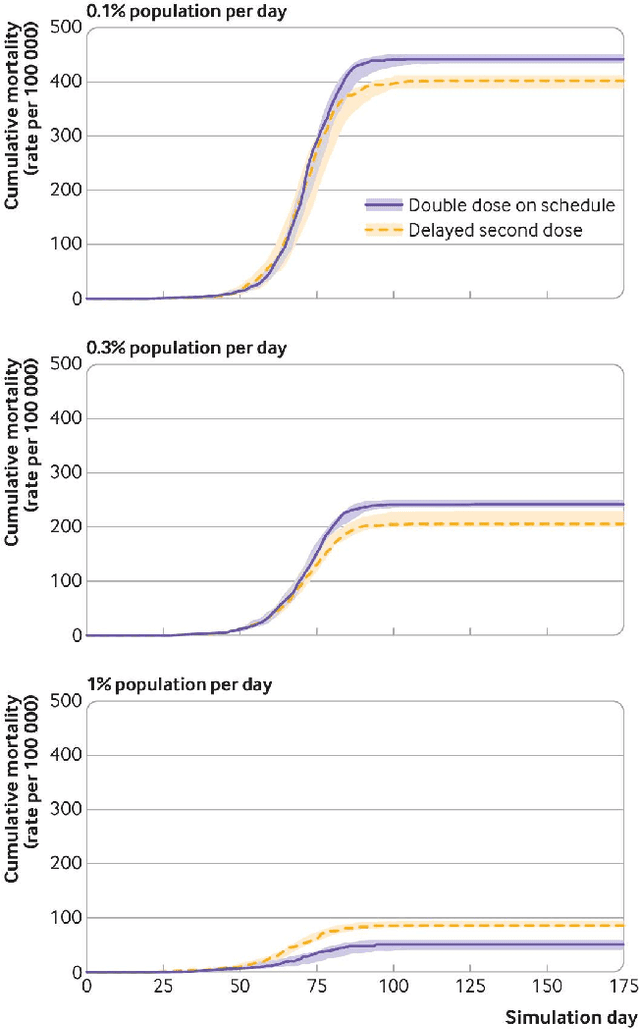
We introduce DeepABM, a framework for agent-based modeling that leverages geometric message passing of graph neural networks for simulating action and interactions over large agent populations. Using DeepABM allows scaling simulations to large agent populations in real-time and running them efficiently on GPU architectures. To demonstrate the effectiveness of DeepABM, we build DeepABM-COVID simulator to provide support for various non-pharmaceutical interventions (quarantine, exposure notification, vaccination, testing) for the COVID-19 pandemic, and can scale to populations of representative size in real-time on a GPU. Specifically, DeepABM-COVID can model 200 million interactions (over 100,000 agents across 180 time-steps) in 90 seconds, and is made available online to help researchers with modeling and analysis of various interventions. We explain various components of the framework and discuss results from one research study to evaluate the impact of delaying the second dose of the COVID-19 vaccine in collaboration with clinical and public health experts. While we simulate COVID-19 spread, the ideas introduced in the paper are generic and can be easily extend to other forms of agent-based simulations. Furthermore, while beyond scope of this document, DeepABM enables inverse agent-based simulations which can be used to learn physical parameters in the (micro) simulations using gradient-based optimization with large-scale real-world (macro) data. We are optimistic that the current work can have interesting implications for bringing ABM and AI communities closer.
Parallel Quasi-concave set optimization: A new frontier that scales without needing submodularity
Aug 19, 2021
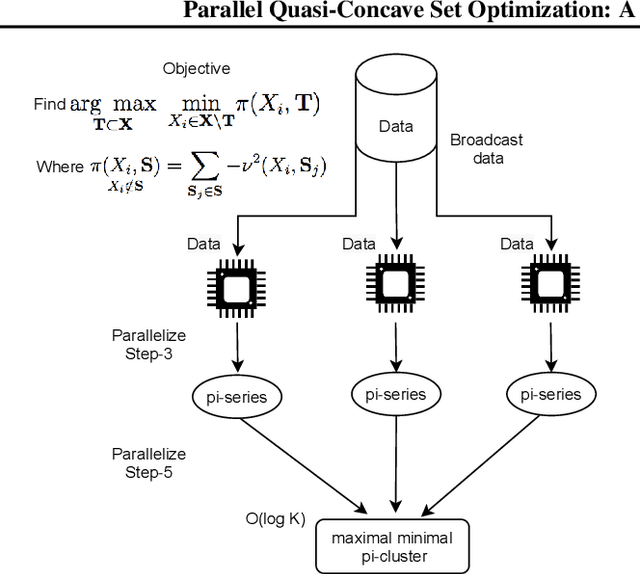
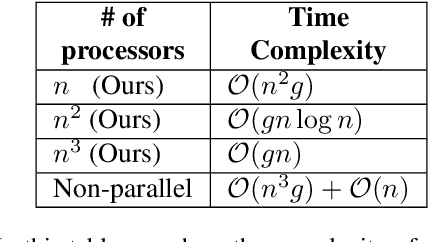
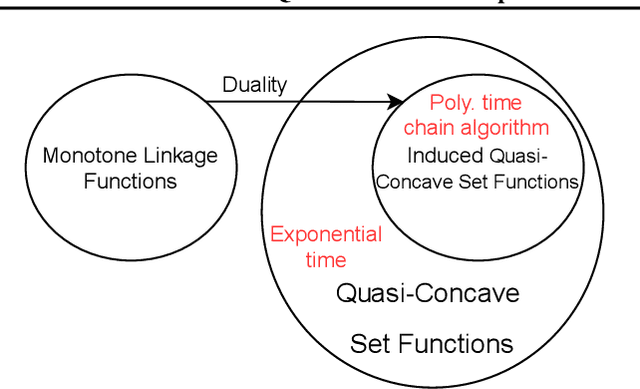
Classes of set functions along with a choice of ground set are a bedrock to determine and develop corresponding variants of greedy algorithms to obtain efficient solutions for combinatorial optimization problems. The class of approximate constrained submodular optimization has seen huge advances at the intersection of good computational efficiency, versatility and approximation guarantees while exact solutions for unconstrained submodular optimization are NP-hard. What is an alternative to situations when submodularity does not hold? Can efficient and globally exact solutions be obtained? We introduce one such new frontier: The class of quasi-concave set functions induced as a dual class to monotone linkage functions. We provide a parallel algorithm with a time complexity over $n$ processors of $\mathcal{O}(n^2g) +\mathcal{O}(\log{\log{n}})$ where $n$ is the cardinality of the ground set and $g$ is the complexity to compute the monotone linkage function that induces a corresponding quasi-concave set function via a duality. The complexity reduces to $\mathcal{O}(gn\log(n))$ on $n^2$ processors and to $\mathcal{O}(gn)$ on $n^3$ processors. Our algorithm provides a globally optimal solution to a maxi-min problem as opposed to submodular optimization which is approximate. We show a potential for widespread applications via an example of diverse feature subset selection with exact global maxi-min guarantees upon showing that a statistical dependency measure called distance correlation can be used to induce a quasi-concave set function.
Automatic calibration of time of flight based non-line-of-sight reconstruction
May 21, 2021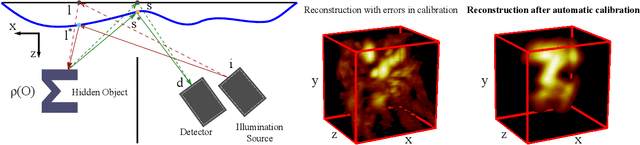

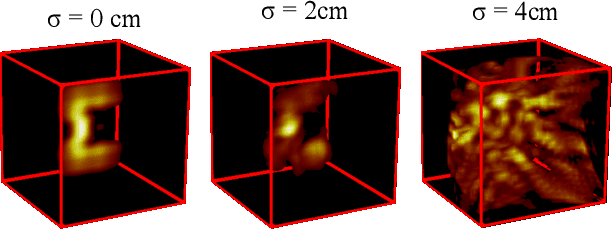

Time of flight based Non-line-of-sight (NLOS) imaging approaches require precise calibration of illumination and detector positions on the visible scene to produce reasonable results. If this calibration error is sufficiently high, reconstruction can fail entirely without any indication to the user. In this work, we highlight the necessity of building autocalibration into NLOS reconstruction in order to handle mis-calibration. We propose a forward model of NLOS measurements that is differentiable with respect to both, the hidden scene albedo, and virtual illumination and detector positions. With only a mean squared error loss and no regularization, our model enables joint reconstruction and recovery of calibration parameters by minimizing the measurement residual using gradient descent. We demonstrate our method is able to produce robust reconstructions using simulated and real data where the calibration error applied causes other state of the art algorithms to fail.
Can Self Reported Symptoms Predict Daily COVID-19 Cases?
May 18, 2021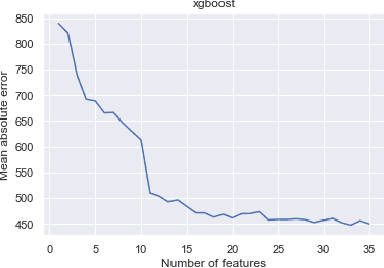
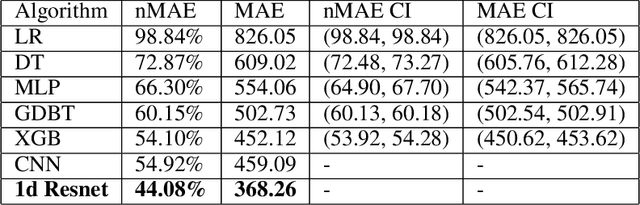
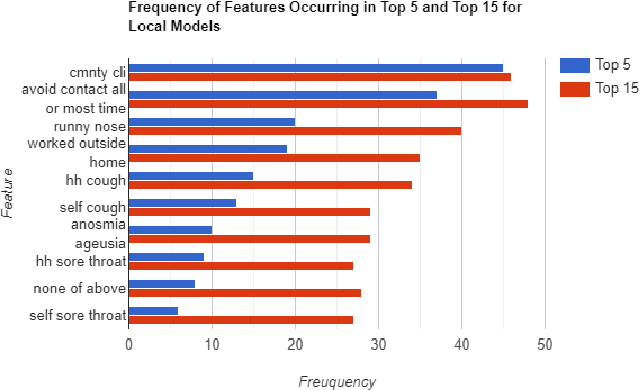

The COVID-19 pandemic has impacted lives and economies across the globe, leading to many deaths. While vaccination is an important intervention, its roll-out is slow and unequal across the globe. Therefore, extensive testing still remains one of the key methods to monitor and contain the virus. Testing on a large scale is expensive and arduous. Hence, we need alternate methods to estimate the number of cases. Online surveys have been shown to be an effective method for data collection amidst the pandemic. In this work, we develop machine learning models to estimate the prevalence of COVID-19 using self-reported symptoms. Our best model predicts the daily cases with a mean absolute error (MAE) of 226.30 (normalized MAE of 27.09%) per state, which demonstrates the possibility of predicting the actual number of confirmed cases by utilizing self-reported symptoms. The models are developed at two levels of data granularity - local models, which are trained at the state level, and a single global model which is trained on the combined data aggregated across all states. Our results indicate a lower error on the local models as opposed to the global model. In addition, we also show that the most important symptoms (features) vary considerably from state to state. This work demonstrates that the models developed on crowd-sourced data, curated via online platforms, can complement the existing epidemiological surveillance infrastructure in a cost-effective manner.
AirMixML: Over-the-Air Data Mixup for Inherently Privacy-Preserving Edge Machine Learning
May 02, 2021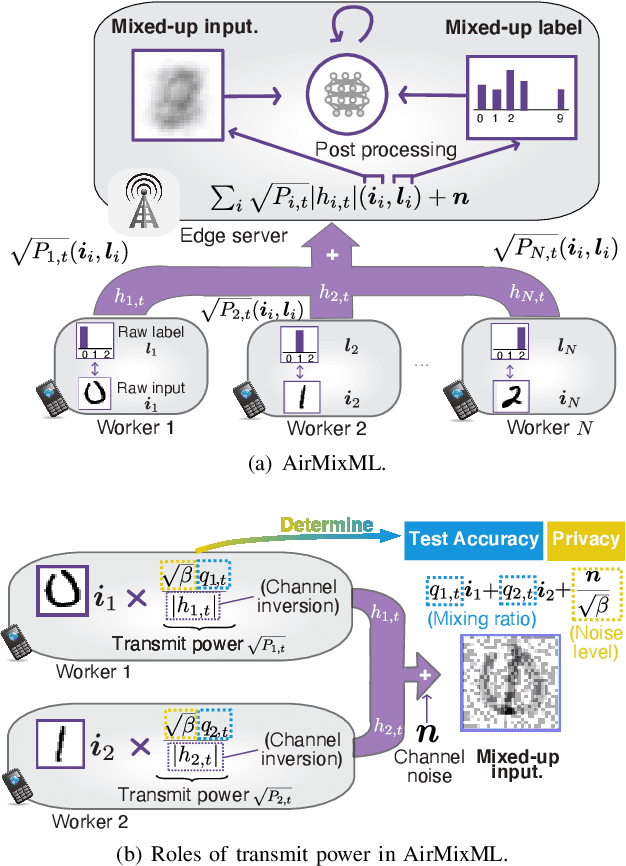
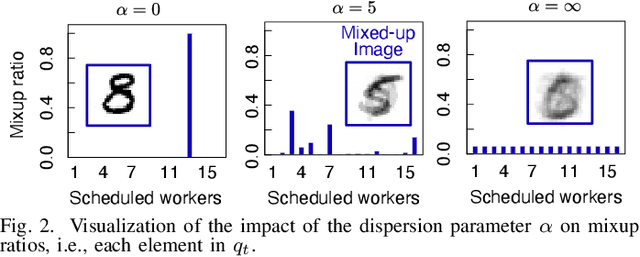
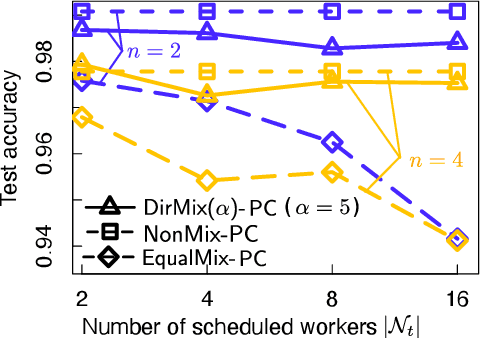
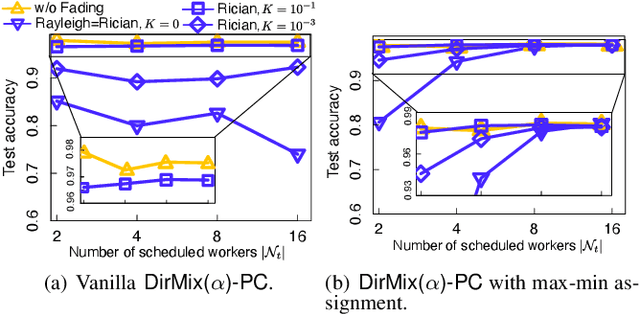
Wireless channels can be inherently privacy-preserving by distorting the received signals due to channel noise, and superpositioning multiple signals over-the-air. By harnessing these natural distortions and superpositions by wireless channels, we propose a novel privacy-preserving machine learning (ML) framework at the network edge, coined over-the-air mixup ML (AirMixML). In AirMixML, multiple workers transmit analog-modulated signals of their private data samples to an edge server who trains an ML model using the received noisy-and superpositioned samples. AirMixML coincides with model training using mixup data augmentation achieving comparable accuracy to that with raw data samples. From a privacy perspective, AirMixML is a differentially private (DP) mechanism limiting the disclosure of each worker's private sample information at the server, while the worker's transmit power determines the privacy disclosure level. To this end, we develop a fractional channel-inversion power control (PC) method, {\alpha}-Dirichlet mixup PC (DirMix({\alpha})-PC), wherein for a given global power scaling factor after channel inversion, each worker's local power contribution to the superpositioned signal is controlled by the Dirichlet dispersion ratio {\alpha}. Mathematically, we derive a closed-form expression clarifying the relationship between the local and global PC factors to guarantee a target DP level. By simulations, we provide DirMix({\alpha})-PC design guidelines to improve accuracy, privacy, and energy-efficiency. Finally, AirMixML with DirMix({\alpha})-PC is shown to achieve reasonable accuracy compared to a privacy-violating baseline with neither superposition nor PC.
Differentially Private Supervised Manifold Learning with Applications like Private Image Retrieval
Feb 22, 2021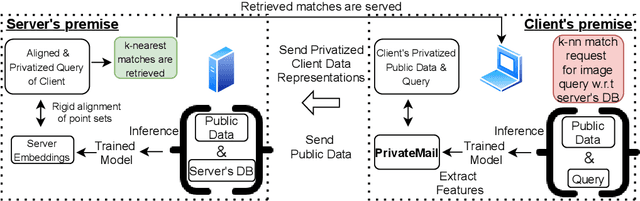
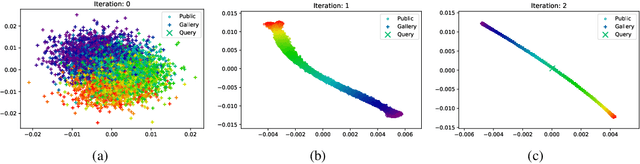

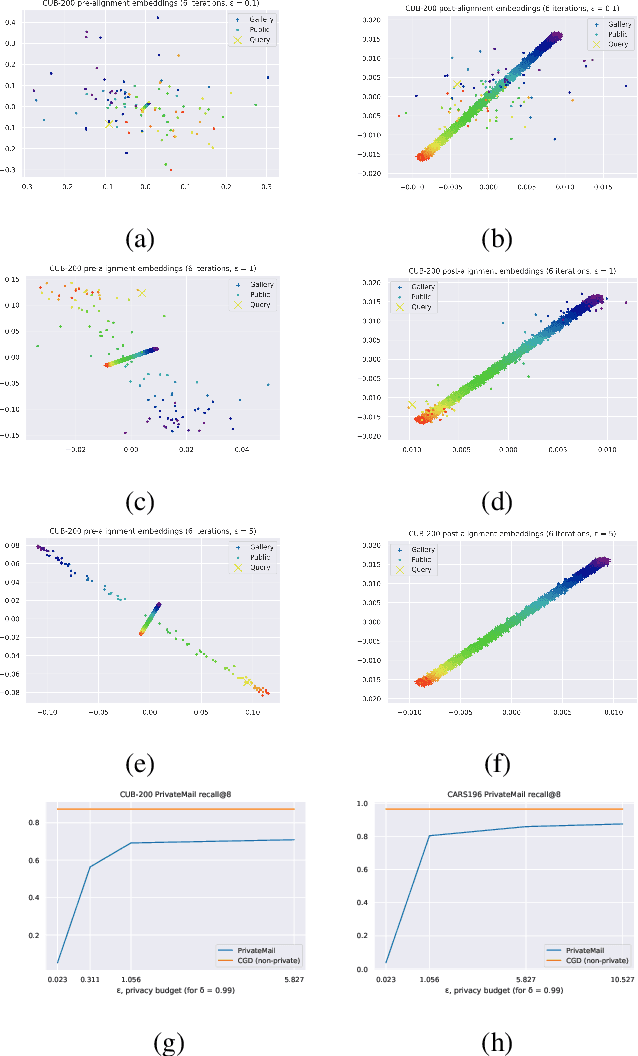
Differential Privacy offers strong guarantees such as immutable privacy under post processing. Thus it is often looked to as a solution to learning on scattered and isolated data. This work focuses on supervised manifold learning, a paradigm that can generate fine-tuned manifolds for a target use case. Our contributions are two fold. 1) We present a novel differentially private method \textit{PrivateMail} for supervised manifold learning, the first of its kind to our knowledge. 2) We provide a novel private geometric embedding scheme for our experimental use case. We experiment on private "content based image retrieval" - embedding and querying the nearest neighbors of images in a private manner - and show extensive privacy-utility tradeoff results, as well as the computational efficiency and practicality of our methods.
COVID-19 Outbreak Prediction and Analysis using Self Reported Symptoms
Dec 21, 2020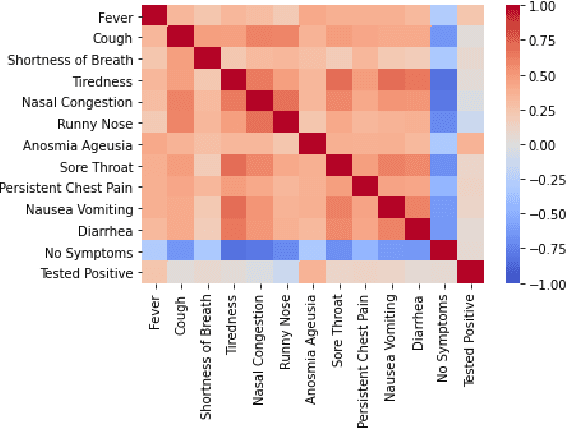
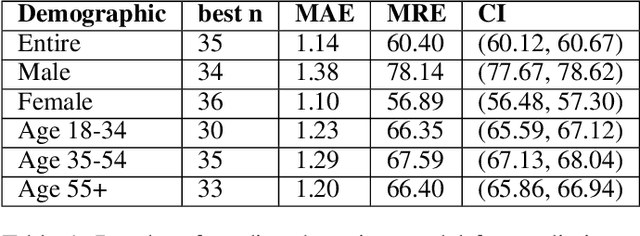
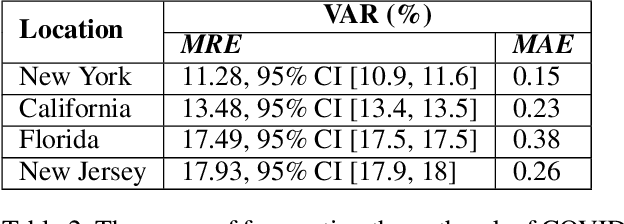
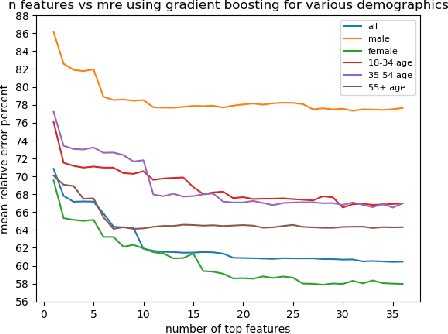
The COVID-19 pandemic has challenged scientists and policy-makers internationally to develop novel approaches to public health policy. Furthermore, it has also been observed that the prevalence and spread of COVID-19 vary across different spatial, temporal, and demographics. Despite ramping up testing, we still are not at the required level in most parts of the globe. Therefore, we utilize self-reported symptoms survey data to understand trends in the spread of COVID-19. The aim of this study is to segment populations that are highly susceptible. In order to understand such populations, we perform exploratory data analysis, outbreak prediction, and time-series forecasting using public health and policy datasets. From our studies, we try to predict the likely % of the population that tested positive for COVID-19 based on self-reported symptoms. Our findings reaffirm the predictive value of symptoms, such as anosmia and ageusia. And we forecast that % of the population having COVID-19-like illness (CLI) and those tested positive as 0.15% and 1.14% absolute error respectively. These findings could help aid faster development of the public health policy, particularly in areas with low levels of testing and having a greater reliance on self-reported symptoms. Our analysis sheds light on identifying clinical attributes of interest across different demographics. We also provide insights into the effects of various policy enactments on COVID-19 prevalence.
DISCO: Dynamic and Invariant Sensitive Channel Obfuscation for deep neural networks
Dec 20, 2020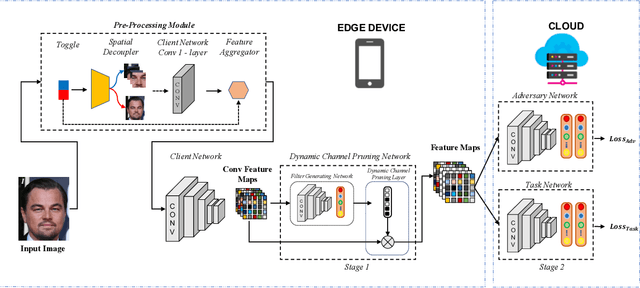
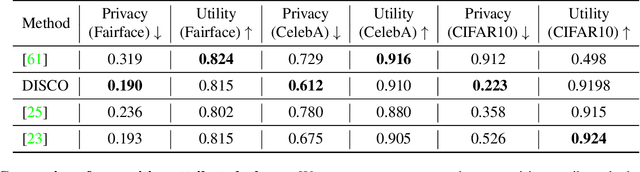

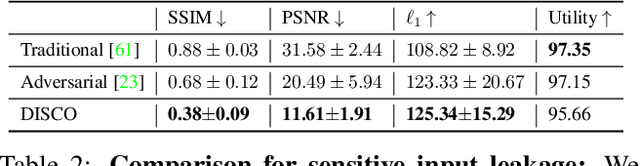
Recent deep learning models have shown remarkable performance in image classification. While these deep learning systems are getting closer to practical deployment, the common assumption made about data is that it does not carry any sensitive information. This assumption may not hold for many practical cases, especially in the domain where an individual's personal information is involved, like healthcare and facial recognition systems. We posit that selectively removing features in this latent space can protect the sensitive information and provide a better privacy-utility trade-off. Consequently, we propose DISCO which learns a dynamic and data driven pruning filter to selectively obfuscate sensitive information in the feature space. We propose diverse attack schemes for sensitive inputs \& attributes and demonstrate the effectiveness of DISCO against state-of-the-art methods through quantitative and qualitative evaluation. Finally, we also release an evaluation benchmark dataset of 1 million sensitive representations to encourage rigorous exploration of novel attack schemes.
Proximity Sensing for Contact Tracing
Sep 04, 2020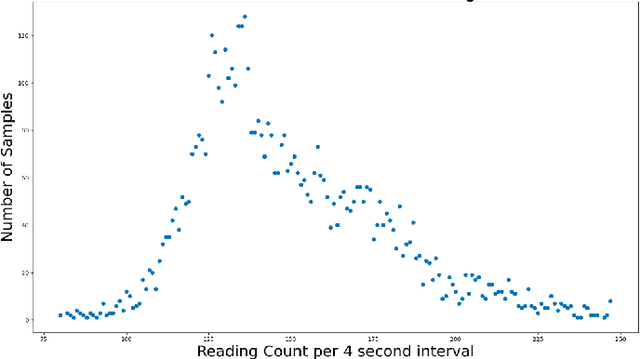
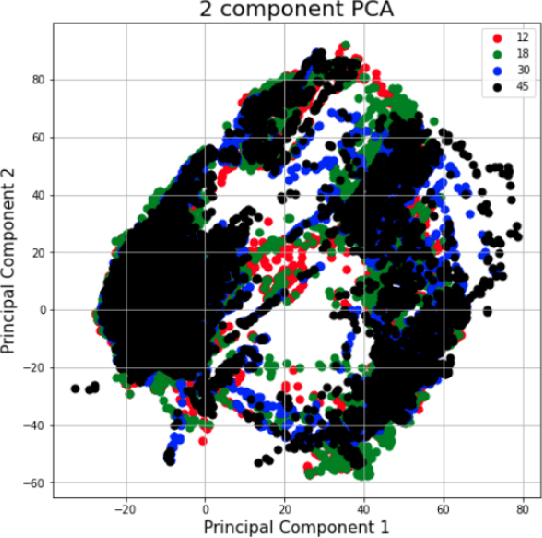
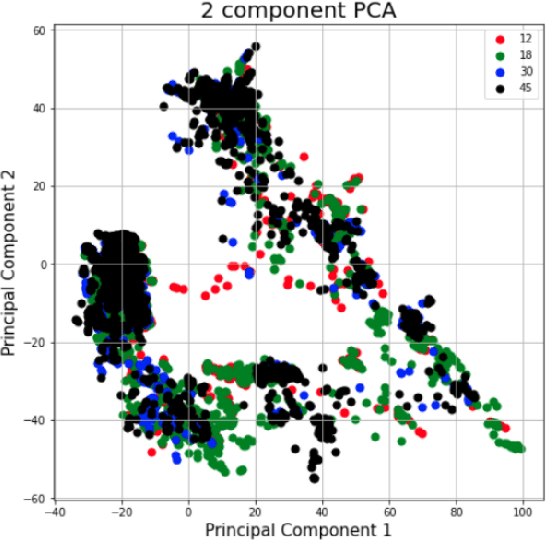
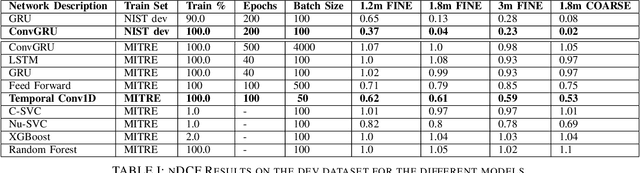
The TC4TL (Too Close For Too Long) challenge is aimed towards designing an effective proximity sensing algorithm that can accurately provide exposure notifications. In this paper, we describe our approach to model sensor and other device-level data to estimate the distance between two phones. We also present our research and data analysis on the TC4TL challenge and discuss various limitations associated with the task, and the dataset used for this purpose.