 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Adversarial Training: Learning together is better than going alone
Dec 09, 2021
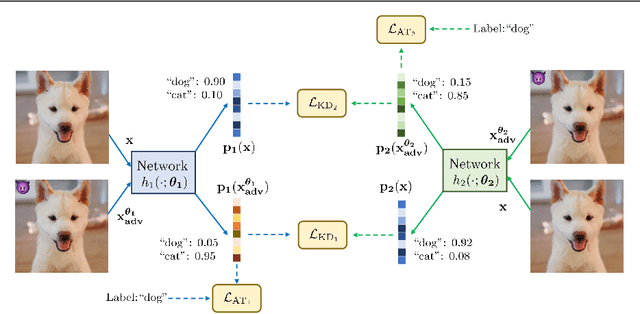
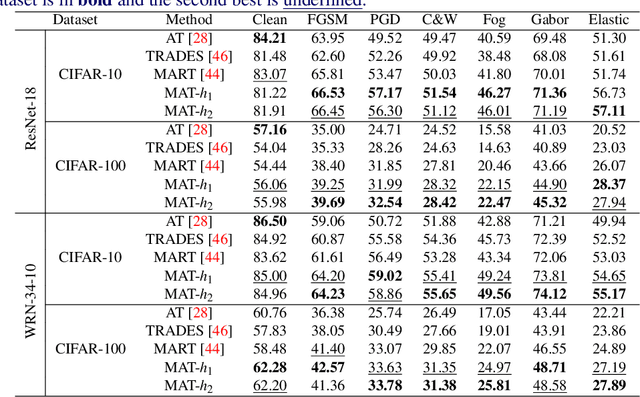
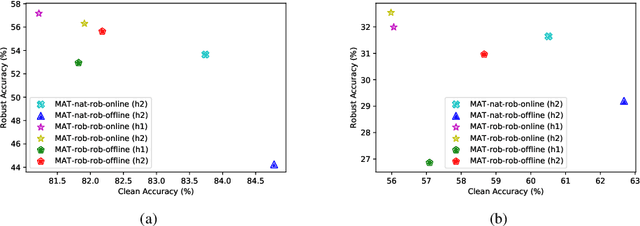
Recent studies have shown that robustness to adversarial attacks can be transferred across networks. In other words, we can make a weak model more robust with the help of a strong teacher model. We ask if instead of learning from a static teacher, can models "learn together" and "teach each other" to achieve better robustness? In this paper, we study how interactions among models affect robustness via knowledge distillation. We propose mutual adversarial training (MAT), in which multiple models are trained together and share the knowledge of adversarial examples to achieve improved robustness. MAT allows robust models to explore a larger space of adversarial samples, and find more robust feature spaces and decision boundaries. Through extensive experiments on CIFAR-10 and CIFAR-100, we demonstrate that MAT can effectively improve model robustness and outperform state-of-the-art methods under white-box attacks, bringing $\sim$8% accuracy gain to vanilla adversarial training (AT) under PGD-100 attacks. In addition, we show that MAT can also mitigate the robustness trade-off among different perturbation types, bringing as much as 13.1% accuracy gain to AT baselines against the union of $l_\infty$, $l_2$ and $l_1$ attacks. These results show the superiority of the proposed method and demonstrate that collaborative learning is an effective strategy for designing robust models.
Segment and Complete: Defending Object Detectors against Adversarial Patch Attacks with Robust Patch Detection
Dec 08, 2021
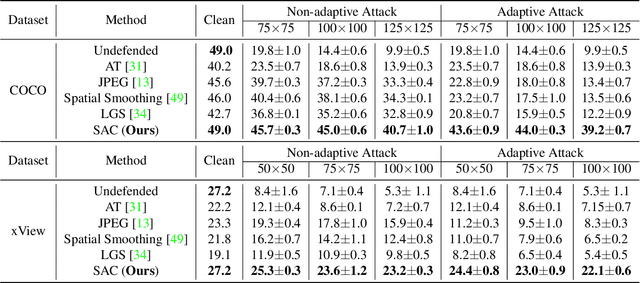

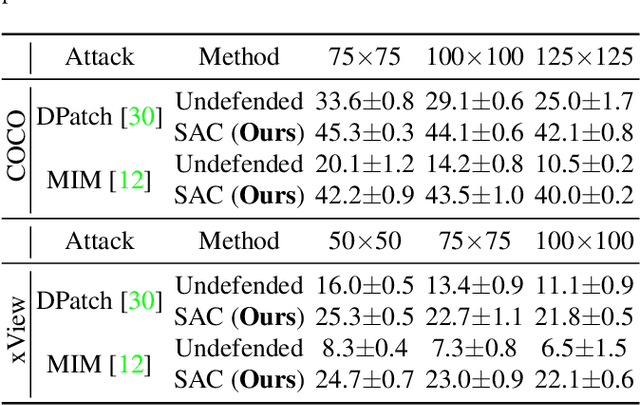
Object detection plays a key role in many security-critical systems. Adversarial patch attacks, which are easy to implement in the physical world, pose a serious threat to state-of-the-art object detectors. Developing reliable defenses for object detectors against patch attacks is critical but severely understudied. In this paper, we propose Segment and Complete defense (SAC), a general framework for defending object detectors against patch attacks through detecting and removing adversarial patches. We first train a patch segmenter that outputs patch masks that provide pixel-level localization of adversarial patches. We then propose a self adversarial training algorithm to robustify the patch segmenter. In addition, we design a robust shape completion algorithm, which is guaranteed to remove the entire patch from the images given the outputs of the patch segmenter are within a certain Hamming distance of the ground-truth patch masks. Our experiments on COCO and xView datasets demonstrate that SAC achieves superior robustness even under strong adaptive attacks with no performance drop on clean images, and generalizes well to unseen patch shapes, attack budgets, and unseen attack methods. Furthermore, we present the APRICOT-Mask dataset, which augments the APRICOT dataset with pixel-level annotations of adversarial patches. We show SAC can significantly reduce the targeted attack success rate of physical patch attacks.
The 5th Recognizing Families in the Wild Data Challenge: Predicting Kinship from Faces
Nov 26, 2021

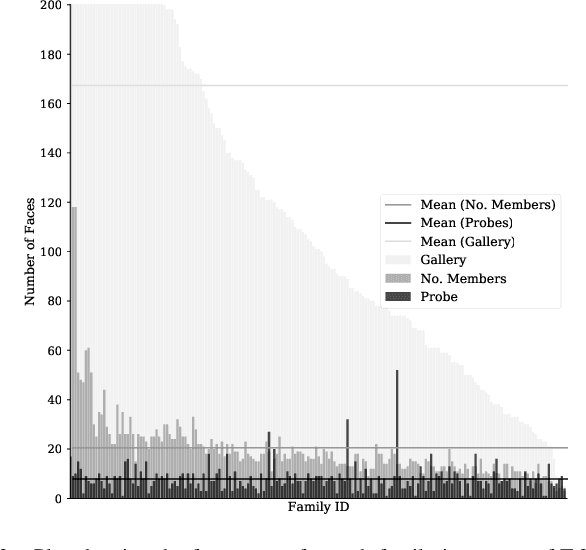

Recognizing Families In the Wild (RFIW), held as a data challenge in conjunction with the 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG), is a large-scale, multi-track visual kinship recognition evaluation. For the fifth edition of RFIW, we continue to attract scholars, bring together professionals, publish new work, and discuss prospects. In this paper, we summarize submissions for the three tasks of this year's RFIW: specifically, we review the results for kinship verification, tri-subject verification, and family member search and retrieval. We look at the RFIW problem, share current efforts, and make recommendations for promising future directions.
Self-Denoising Neural Networks for Few Shot Learning
Oct 26, 2021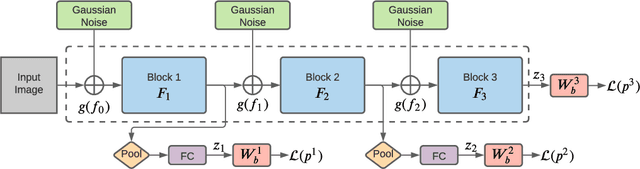
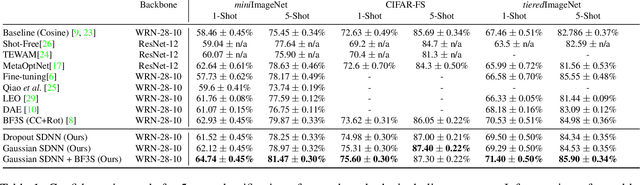
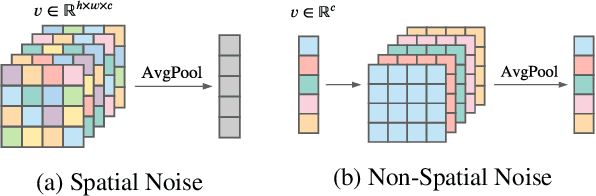
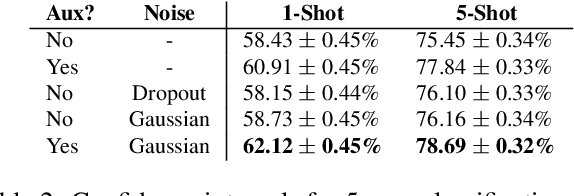
In this paper, we introduce a new architecture for few shot learning, the task of teaching a neural network from as few as one or five labeled examples. Inspired by the theoretical results of Alaine et al that Denoising Autoencoders refine features to lie closer to the true data manifold, we present a new training scheme that adds noise at multiple stages of an existing neural architecture while simultaneously learning to be robust to this added noise. This architecture, which we call a Self-Denoising Neural Network (SDNN), can be applied easily to most modern convolutional neural architectures, and can be used as a supplement to many existing few-shot learning techniques. We empirically show that SDNNs out-perform previous state-of-the-art methods for few shot image recognition using the Wide-ResNet architecture on the \textit{mini}ImageNet, tiered-ImageNet, and CIFAR-FS few shot learning datasets. We also perform a series of ablation experiments to empirically justify the construction of the SDNN architecture. Finally, we show that SDNNs even improve few shot performance on the task of human action detection in video using experiments on the ActEV SDL Surprise Activities challenge.
Identification of Attack-Specific Signatures in Adversarial Examples
Oct 13, 2021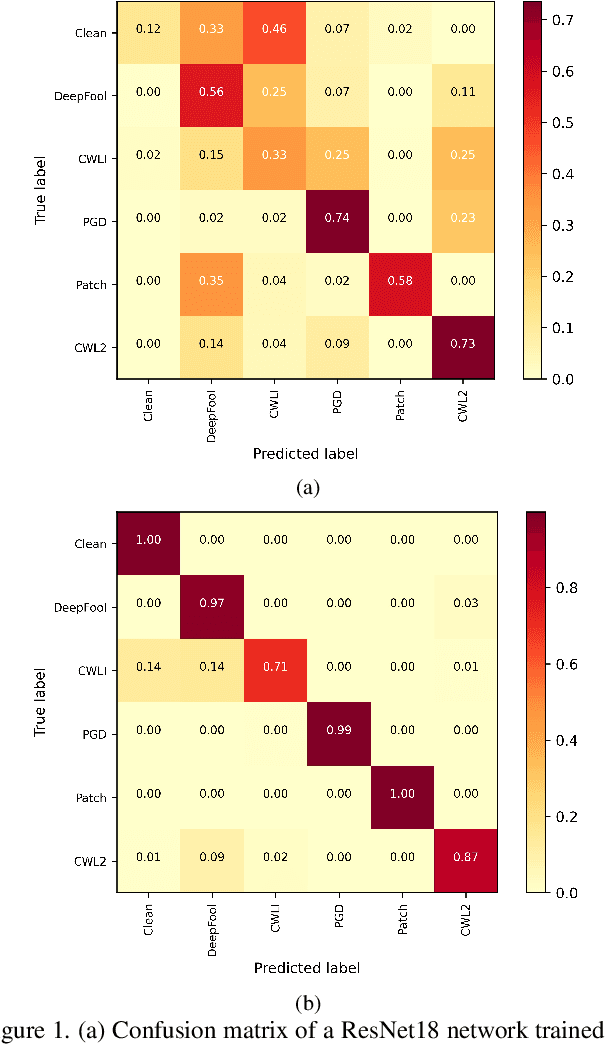

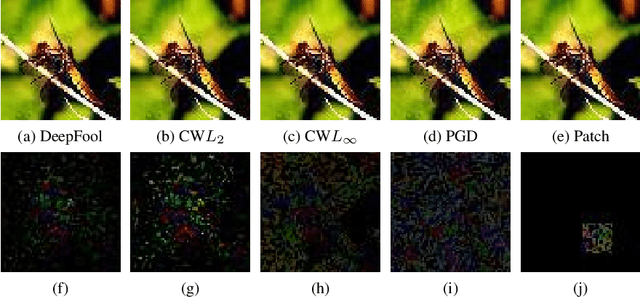
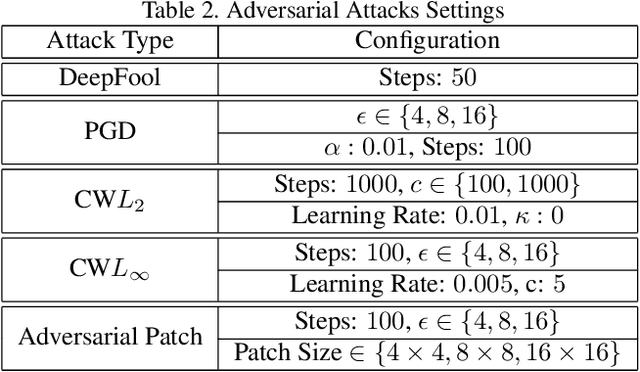
The adversarial attack literature contains a myriad of algorithms for crafting perturbations which yield pathological behavior in neural networks. In many cases, multiple algorithms target the same tasks and even enforce the same constraints. In this work, we show that different attack algorithms produce adversarial examples which are distinct not only in their effectiveness but also in how they qualitatively affect their victims. We begin by demonstrating that one can determine the attack algorithm that crafted an adversarial example. Then, we leverage recent advances in parameter-space saliency maps to show, both visually and quantitatively, that adversarial attack algorithms differ in which parts of the network and image they target. Our findings suggest that prospective adversarial attacks should be compared not only via their success rates at fooling models but also via deeper downstream effects they have on victims.
LR-to-HR Face Hallucination with an Adversarial Progressive Attribute-Induced Network
Sep 29, 2021

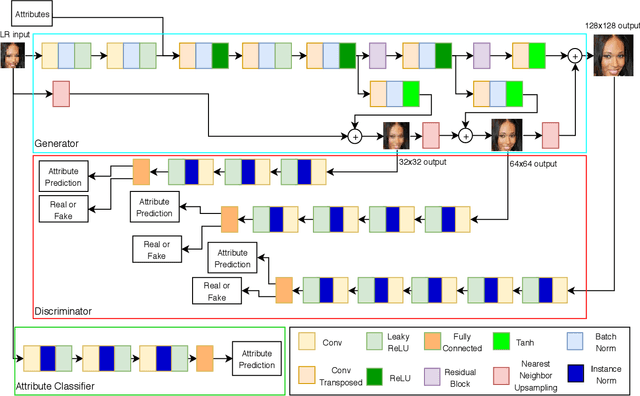

Face super-resolution is a challenging and highly ill-posed problem since a low-resolution (LR) face image may correspond to multiple high-resolution (HR) ones during the hallucination process and cause a dramatic identity change for the final super-resolved results. Thus, to address this problem, we propose an end-to-end progressive learning framework incorporating facial attributes and enforcing additional supervision from multi-scale discriminators. By incorporating facial attributes into the learning process and progressively resolving the facial image, the mapping between LR and HR images is constrained more, and this significantly helps to reduce the ambiguity and uncertainty in one-to-many mapping. In addition, we conduct thorough evaluations on the CelebA dataset following the settings of previous works (i.e. super-resolving by a factor of 8x from tiny 16x16 face images.), and the results demonstrate that the proposed approach can yield satisfactory face hallucination images outperforming other state-of-the-art approaches.
Finding Facial Forgery Artifacts with Parts-Based Detectors
Sep 21, 2021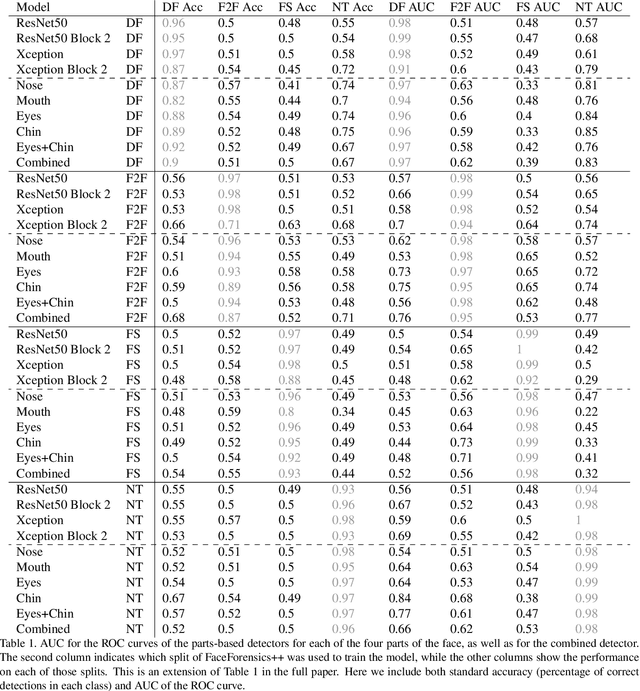
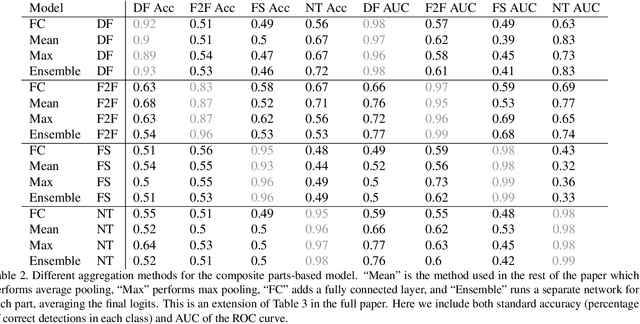
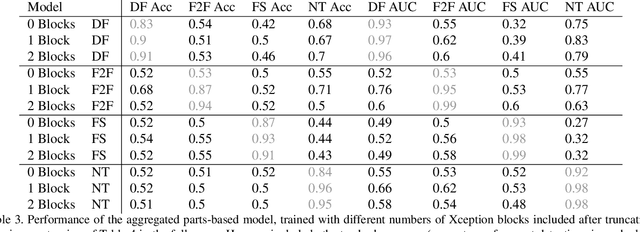
Manipulated videos, especially those where the identity of an individual has been modified using deep neural networks, are becoming an increasingly relevant threat in the modern day. In this paper, we seek to develop a generalizable, explainable solution to detecting these manipulated videos. To achieve this, we design a series of forgery detection systems that each focus on one individual part of the face. These parts-based detection systems, which can be combined and used together in a single architecture, meet all of our desired criteria - they generalize effectively between datasets and give us valuable insights into what the network is looking at when making its decision. We thus use these detectors to perform detailed empirical analysis on the FaceForensics++, Celeb-DF, and Facebook Deepfake Detection Challenge datasets, examining not just what the detectors find but also collecting and analyzing useful related statistics on the datasets themselves.
A Synthesis-Based Approach for Thermal-to-Visible Face Verification
Aug 21, 2021
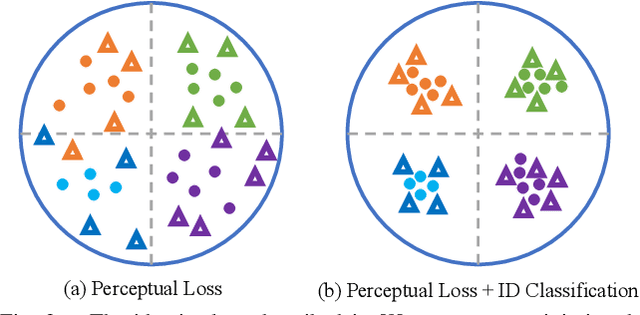
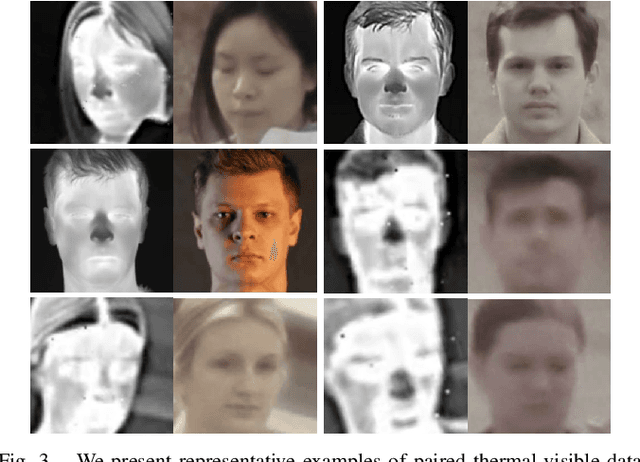
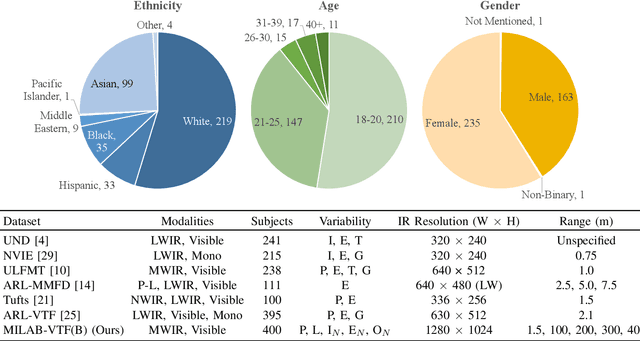
In recent years, visible-spectrum face verification systems have been shown to match expert forensic examiner recognition performance. However, such systems are ineffective in low-light and nighttime conditions. Thermal face imagery, which captures body heat emissions, effectively augments the visible spectrum, capturing discriminative facial features in scenes with limited illumination. Due to the increased cost and difficulty of obtaining diverse, paired thermal and visible spectrum datasets, algorithms and large-scale benchmarks for low-light recognition are limited. This paper presents an algorithm that achieves state-of-the-art performance on both the ARL-VTF and TUFTS multi-spectral face datasets. Importantly, we study the impact of face alignment, pixel-level correspondence, and identity classification with label smoothing for multi-spectral face synthesis and verification. We show that our proposed method is widely applicable, robust, and highly effective. In addition, we show that the proposed method significantly outperforms face frontalization methods on profile-to-frontal verification. Finally, we present MILAB-VTF(B), a challenging multi-spectral face dataset that is composed of paired thermal and visible videos. To the best of our knowledge, with face data from 400 subjects, this dataset represents the most extensive collection of publicly available indoor and long-range outdoor thermal-visible face imagery. Lastly, we show that our end-to-end thermal-to-visible face verification system provides strong performance on the MILAB-VTF(B) dataset.
PASS: Protected Attribute Suppression System for Mitigating Bias in Face Recognition
Aug 09, 2021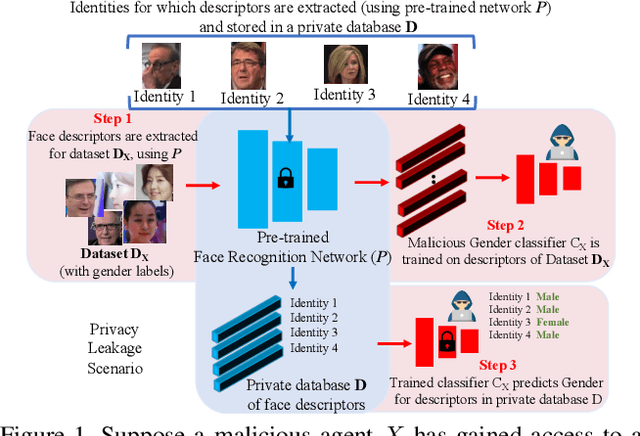
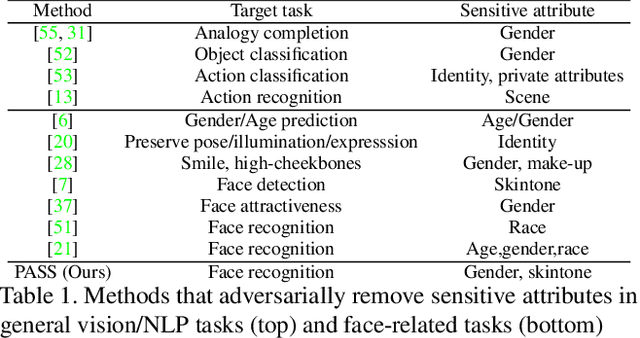
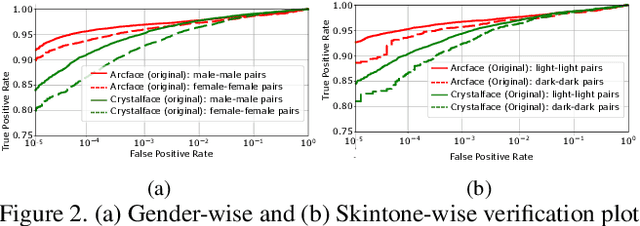

Face recognition networks encode information about sensitive attributes while being trained for identity classification. Such encoding has two major issues: (a) it makes the face representations susceptible to privacy leakage (b) it appears to contribute to bias in face recognition. However, existing bias mitigation approaches generally require end-to-end training and are unable to achieve high verification accuracy. Therefore, we present a descriptor-based adversarial de-biasing approach called `Protected Attribute Suppression System (PASS)'. PASS can be trained on top of descriptors obtained from any previously trained high-performing network to classify identities and simultaneously reduce encoding of sensitive attributes. This eliminates the need for end-to-end training. As a component of PASS, we present a novel discriminator training strategy that discourages a network from encoding protected attribute information. We show the efficacy of PASS to reduce gender and skintone information in descriptors from SOTA face recognition networks like Arcface. As a result, PASS descriptors outperform existing baselines in reducing gender and skintone bias on the IJB-C dataset, while maintaining a high verification accuracy.
To Boost or not to Boost: On the Limits of Boosted Neural Networks
Jul 28, 2021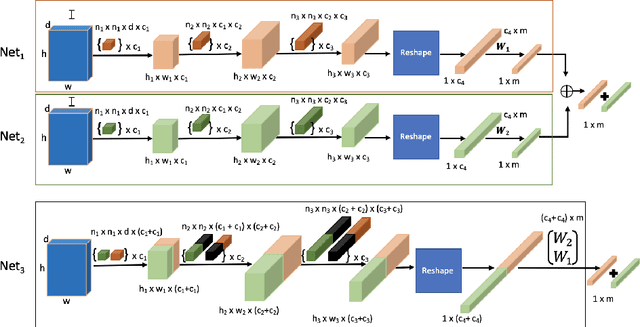
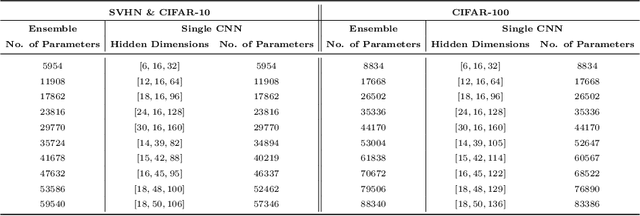

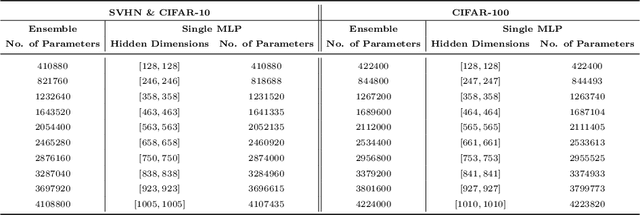
Boosting is a method for finding a highly accurate hypothesis by linearly combining many ``weak" hypotheses, each of which may be only moderately accurate. Thus, boosting is a method for learning an ensemble of classifiers. While boosting has been shown to be very effective for decision trees, its impact on neural networks has not been extensively studied. We prove one important difference between sums of decision trees compared to sums of convolutional neural networks (CNNs) which is that a sum of decision trees cannot be represented by a single decision tree with the same number of parameters while a sum of CNNs can be represented by a single CNN. Next, using standard object recognition datasets, we verify experimentally the well-known result that a boosted ensemble of decision trees usually generalizes much better on testing data than a single decision tree with the same number of parameters. In contrast, using the same datasets and boosting algorithms, our experiments show the opposite to be true when using neural networks (both CNNs and multilayer perceptrons (MLPs)). We find that a single neural network usually generalizes better than a boosted ensemble of smaller neural networks with the same total number of parameters.