 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph2Nav: 3D Object-Relation Graph Generation to Robot Navigation
Apr 23, 2025



We propose Graph2Nav, a real-time 3D object-relation graph generation framework, for autonomous navigation in the real world. Our framework fully generates and exploits both 3D objects and a rich set of semantic relationships among objects in a 3D layered scene graph, which is applicable to both indoor and outdoor scenes. It learns to generate 3D semantic relations among objects, by leveraging and advancing state-of-the-art 2D panoptic scene graph works into the 3D world via 3D semantic mapping techniques. This approach avoids previous training data constraints in learning 3D scene graphs directly from 3D data. We conduct experiments to validate the accuracy in locating 3D objects and labeling object-relations in our 3D scene graphs. We also evaluate the impact of Graph2Nav via integration with SayNav, a state-of-the-art planner based on large language models, on an unmanned ground robot to object search tasks in real environments. Our results demonstrate that modeling object relations in our scene graphs improves search efficiency in these navigation tasks.
Striking the Right Balance: Recall Loss for Semantic Segmentation
Jun 28, 2021

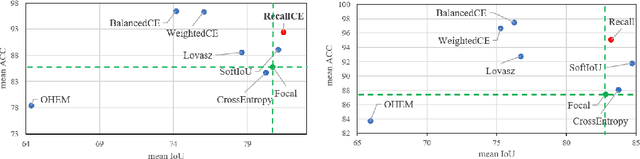

Class imbalance is a fundamental problem in computer vision applications such as semantic segmentation. Specifically, uneven class distributions in a training dataset often result in unsatisfactory performance on under-represented classes. Many works have proposed to weight the standard cross entropy loss function with pre-computed weights based on class statistics, such as the number of samples and class margins. There are two major drawbacks to these methods: 1) constantly up-weighting minority classes can introduce excessive false positives in semantic segmentation; 2) a minority class is not necessarily a hard class. The consequence is low precision due to excessive false positives. In this regard, we propose a hard-class mining loss by reshaping the vanilla cross entropy loss such that it weights the loss for each class dynamically based on instantaneous recall performance. We show that the novel recall loss changes gradually between the standard cross entropy loss and the inverse frequency weighted loss. Recall loss also leads to improved mean accuracy while offering competitive mean Intersection over Union (IoU) performance. On Synthia dataset, recall loss achieves 9% relative improvement on mean accuracy with competitive mean IoU using DeepLab-ResNet18 compared to the cross entropy loss. Code available at https://github.com/PotatoTian/recall-semseg.
MaAST: Map Attention with Semantic Transformersfor Efficient Visual Navigation
Mar 21, 2021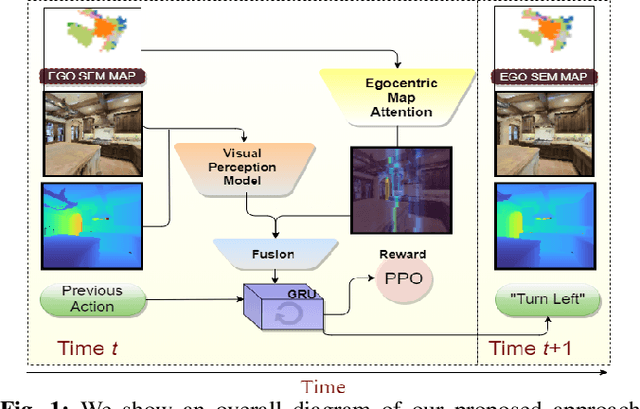

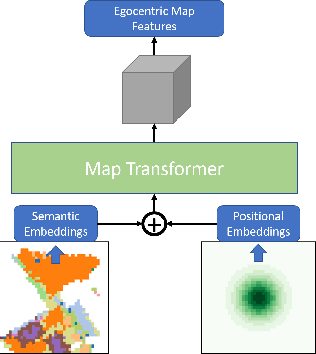
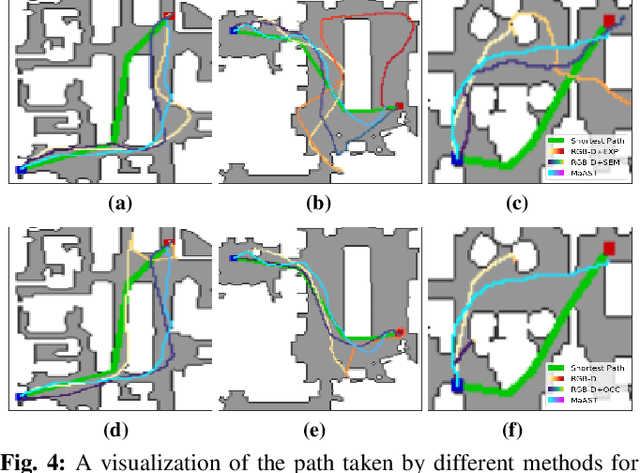
Visual navigation for autonomous agents is a core task in the fields of computer vision and robotics. Learning-based methods, such as deep reinforcement learning, have the potential to outperform the classical solutions developed for this task; however, they come at a significantly increased computational load. Through this work, we design a novel approach that focuses on performing better or comparable to the existing learning-based solutions but under a clear time/computational budget. To this end, we propose a method to encode vital scene semantics such as traversable paths, unexplored areas, and observed scene objects -- alongside raw visual streams such as RGB, depth, and semantic segmentation masks -- into a semantically informed, top-down egocentric map representation. Further, to enable the effective use of this information, we introduce a novel 2-D map attention mechanism, based on the successful multi-layer Transformer networks. We conduct experiments on 3-D reconstructed indoor PointGoal visual navigation and demonstrate the effectiveness of our approach. We show that by using our novel attention schema and auxiliary rewards to better utilize scene semantics, we outperform multiple baselines trained with only raw inputs or implicit semantic information while operating with an 80% decrease in the agent's experience.