 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehind Every Domain There is a Shift: Adapting Distortion-aware Vision Transformers for Panoramic Semantic Segmentation
Jul 27, 2022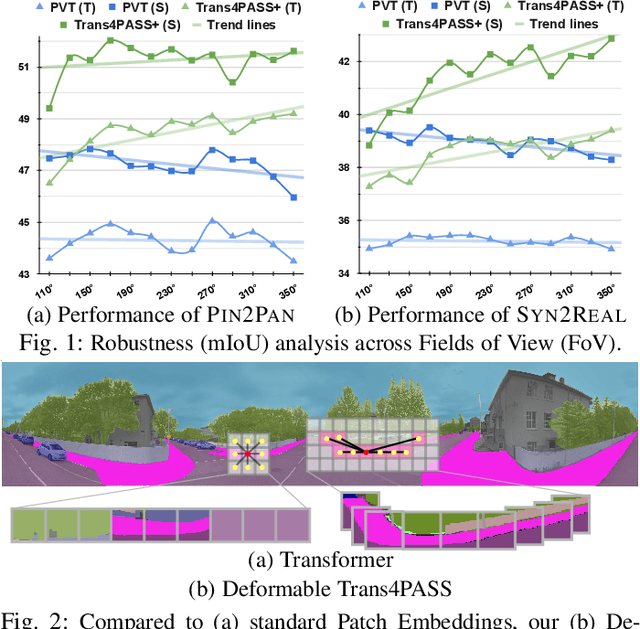
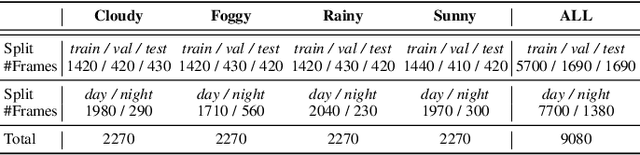
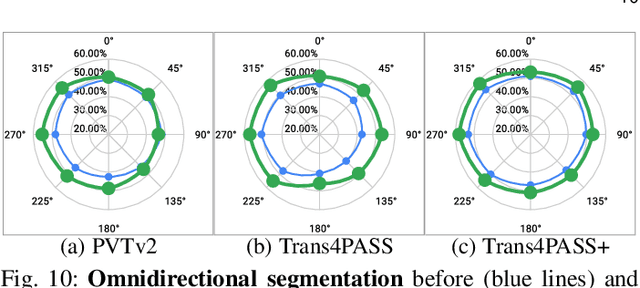

In this paper, we address panoramic semantic segmentation, which provides a full-view and dense-pixel understanding of surroundings in a holistic way. Panoramic segmentation is under-explored due to two critical challenges: (1) image distortions and object deformations on panoramas; (2) lack of annotations for training panoramic segmenters. To tackle these problems, we propose a Transformer for Panoramic Semantic Segmentation (Trans4PASS) architecture. First, to enhance distortion awareness, Trans4PASS, equipped with Deformable Patch Embedding (DPE) and Deformable MLP (DMLP) modules, is capable of handling object deformations and image distortions whenever (before or after adaptation) and wherever (shallow or deep levels) by design. We further introduce the upgraded Trans4PASS+ model, featuring DMLPv2 with parallel token mixing to improve the flexibility and generalizability in modeling discriminative cues. Second, we propose a Mutual Prototypical Adaptation (MPA) strategy for unsupervised domain adaptation. Third, aside from Pinhole-to-Panoramic (Pin2Pan) adaptation, we create a new dataset (SynPASS) with 9,080 panoramic images to explore a Synthetic-to-Real (Syn2Real) adaptation scheme in 360{\deg} imagery. Extensive experiments are conducted, which cover indoor and outdoor scenarios, and each of them is investigated with Pin2Pan and Syn2Real regimens. Trans4PASS+ achieves state-of-the-art performances on four domain adaptive panoramic semantic segmentation benchmarks. Code is available at https://github.com/jamycheung/Trans4PASS.
Trans4Map: Revisiting Holistic Top-down Mapping from Egocentric Images to Allocentric Semantics with Vision Transformers
Jul 13, 2022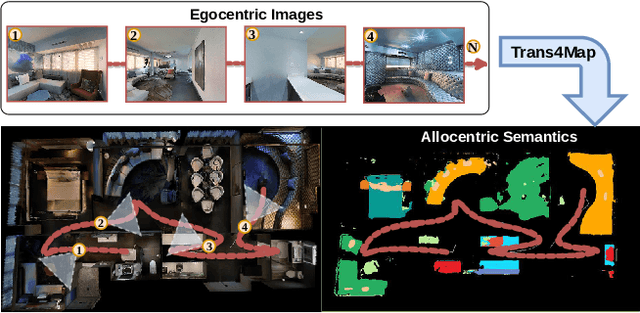
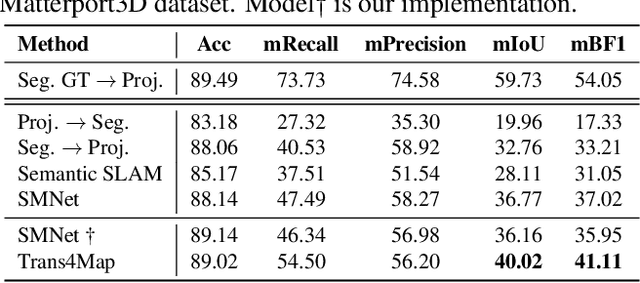
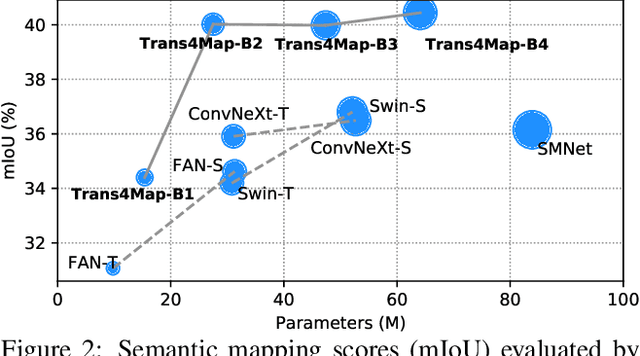
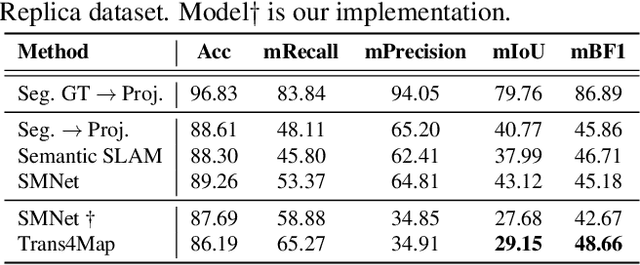
Humans have an innate ability to sense their surroundings, as they can extract the spatial representation from the egocentric perception and form an allocentric semantic map via spatial transformation and memory updating. However, endowing mobile agents with such a spatial sensing ability is still a challenge, due to two difficulties: (1) the previous convolutional models are limited by the local receptive field, thus, struggling to capture holistic long-range dependencies during observation; (2) the excessive computational budgets required for success, often lead to a separation of the mapping pipeline into stages, resulting the entire mapping process inefficient. To address these issues, we propose an end-to-end one-stage Transformer-based framework for Mapping, termed Trans4Map. Our egocentric-to-allocentric mapping process includes three steps: (1) the efficient transformer extracts the contextual features from a batch of egocentric images; (2) the proposed Bidirectional Allocentric Memory (BAM) module projects egocentric features into the allocentric memory; (3) the map decoder parses the accumulated memory and predicts the top-down semantic segmentation map. In contrast, Trans4Map achieves state-of-the-art results, reducing 67.2% parameters, yet gaining a +3.25% mIoU and a +4.09% mBF1 improvements on the Matterport3D dataset. Code will be made publicly available at https://github.com/jamycheung/Trans4Map.
Multi-modal Depression Estimation based on Sub-attentional Fusion
Jul 13, 2022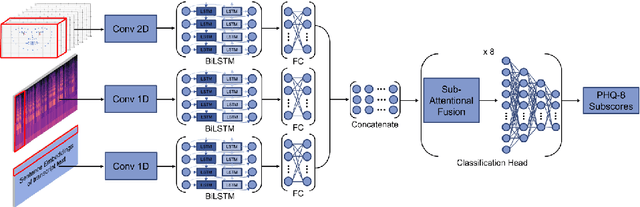
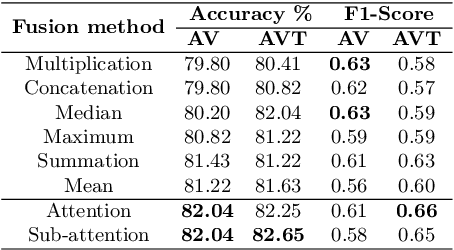
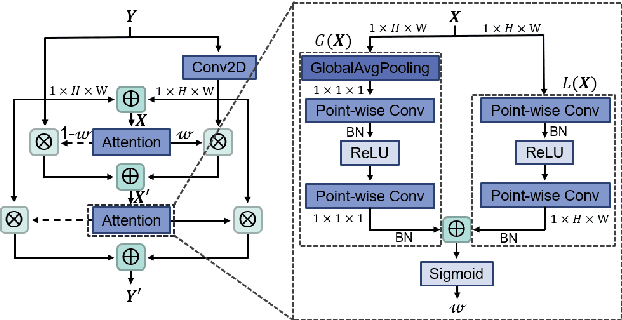

Failure to timely diagnose and effectively treat depression leads to over 280 million people suffering from this psychological disorder worldwide. The information cues of depression can be harvested from diverse heterogeneous resources, e.g., audio, visual, and textual data, raising demand for new effective multi-modal fusion approaches for its automatic estimation. In this work, we tackle the task of automatically identifying depression from multi-modal data and introduce a sub-attention mechanism for linking heterogeneous information while leveraging Convolutional Bidirectional LSTM as our backbone. To validate this idea, we conduct extensive experiments on the public DAIC-WOZ benchmark for depression assessment featuring different evaluation modes and taking gender-specific biases into account. The proposed model yields effective results with 0.89 precision and 0.70 F1-score in detecting major depression and 4.92 MAE in estimating the severity. Our attention-based fusion module consistently outperforms conventional late fusion approaches and achieves a competitive performance compared to the previously published depression estimation frameworks, while learning to diagnose the disorder end-to-end and relying on far less preprocessing steps.
Panoramic Panoptic Segmentation: Insights Into Surrounding Parsing for Mobile Agents via Unsupervised Contrastive Learning
Jun 21, 2022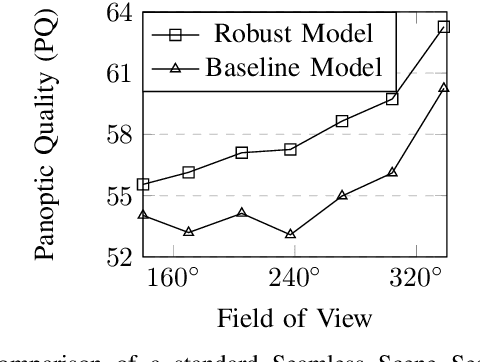
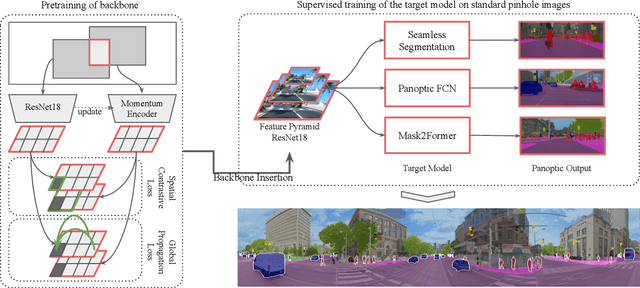
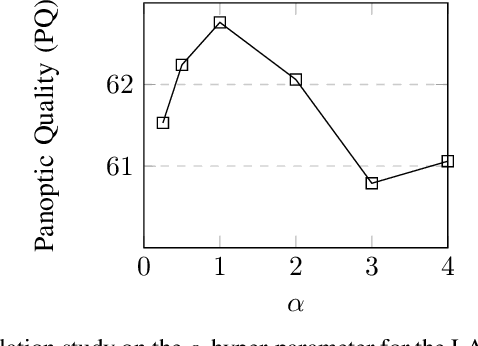
In this work, we introduce panoramic panoptic segmentation, as the most holistic scene understanding, both in terms of Field of View (FoV) and image-level understanding for standard camera-based input. A complete surrounding understanding provides a maximum of information to a mobile agent, which is essential for any intelligent vehicle in order to make informed decisions in a safety-critical dynamic environment such as real-world traffic. In order to overcome the lack of annotated panoramic images, we propose a framework which allows model training on standard pinhole images and transfers the learned features to a different domain in a cost-minimizing way. Using our proposed method with dense contrastive learning, we manage to achieve significant improvements over a non-adapted approach. Depending on the efficient panoptic segmentation architecture, we can improve 3.5-6.5% measured in Panoptic Quality (PQ) over non-adapted models on our established Wild Panoramic Panoptic Segmentation (WildPPS) dataset. Furthermore, our efficient framework does not need access to the images of the target domain, making it a feasible domain generalization approach suitable for a limited hardware setting. As additional contributions, we publish WildPPS: The first panoramic panoptic image dataset to foster progress in surrounding perception and explore a novel training procedure combining supervised and contrastive training.
Breaking with Fixed Set Pathology Recognition through Report-Guided Contrastive Training
May 14, 2022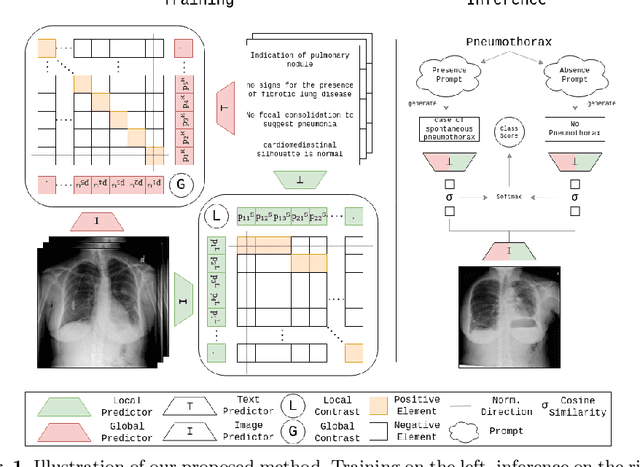
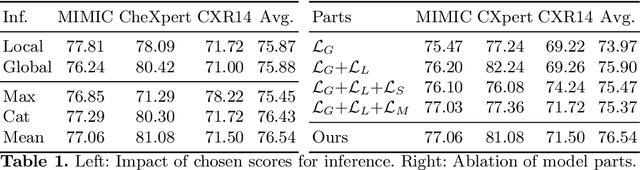
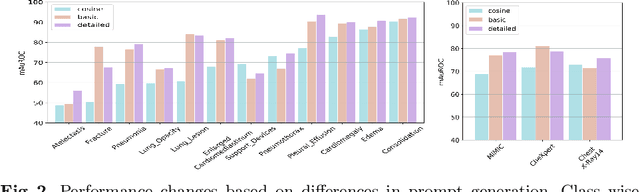
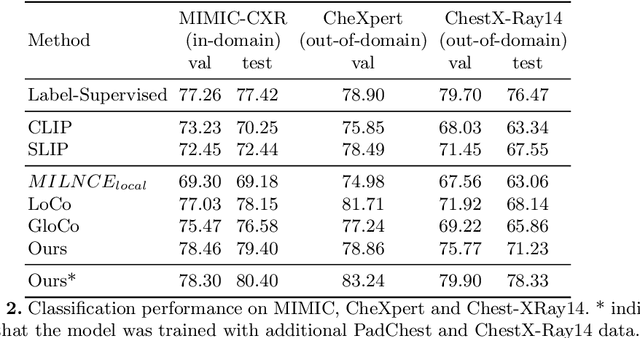
When reading images, radiologists generate text reports describing the findings therein. Current state-of-the-art computer-aided diagnosis tools utilize a fixed set of predefined categories automatically extracted from these medical reports for training. This form of supervision limits the potential usage of models as they are unable to pick up on anomalies outside of their predefined set, thus, making it a necessity to retrain the classifier with additional data when faced with novel classes. In contrast, we investigate direct text supervision to break away from this closed set assumption. By doing so, we avoid noisy label extraction via text classifiers and incorporate more contextual information. We employ a contrastive global-local dual-encoder architecture to learn concepts directly from unstructured medical reports while maintaining its ability to perform free form classification. We investigate relevant properties of open set recognition for radiological data and propose a method to employ currently weakly annotated data into training. We evaluate our approach on the large-scale chest X-Ray datasets MIMIC-CXR, CheXpert, and ChestX-Ray14 for disease classification. We show that despite using unstructured medical report supervision, we perform on par with direct label supervision through a sophisticated inference setting.
Towards Automatic Parsing of Structured Visual Content through the Use of Synthetic Data
Apr 29, 2022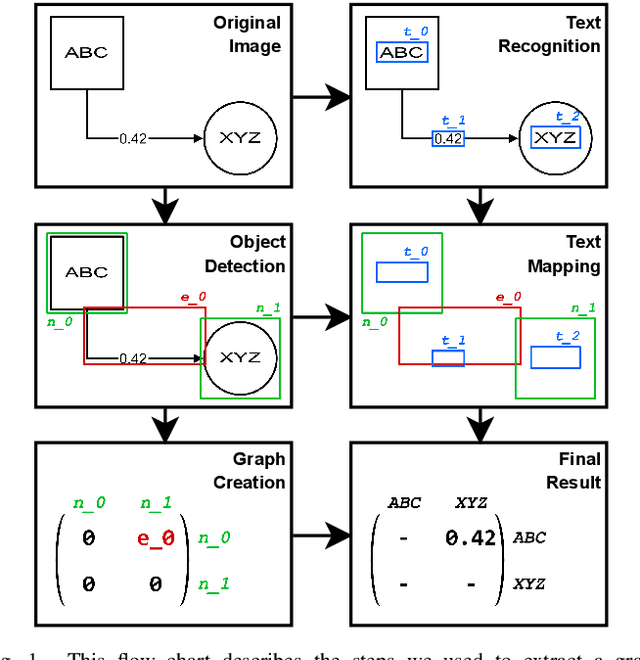
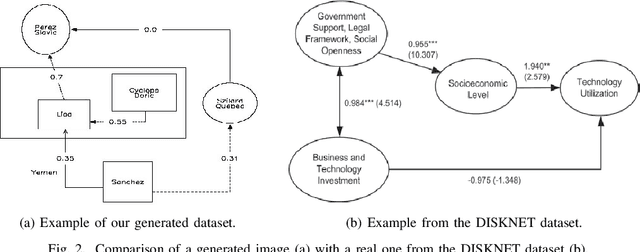
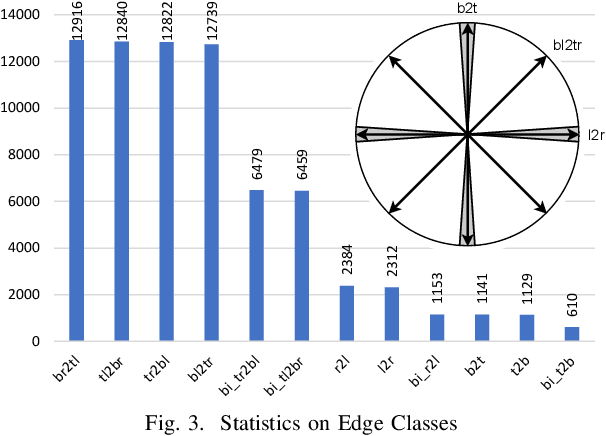

Structured Visual Content (SVC) such as graphs, flow charts, or the like are used by authors to illustrate various concepts. While such depictions allow the average reader to better understand the contents, images containing SVCs are typically not machine-readable. This, in turn, not only hinders automated knowledge aggregation, but also the perception of displayed in-formation for visually impaired people. In this work, we propose a synthetic dataset, containing SVCs in the form of images as well as ground truths. We show the usage of this dataset by an application that automatically extracts a graph representation from an SVC image. This is done by training a model via common supervised learning methods. As there currently exist no large-scale public datasets for the detailed analysis of SVC, we propose the Synthetic SVC (SSVC) dataset comprising 12,000 images with respective bounding box annotations and detailed graph representations. Our dataset enables the development of strong models for the interpretation of SVCs while skipping the time-consuming dense data annotation. We evaluate our model on both synthetic and manually annotated data and show the transferability of synthetic to real via various metrics, given the presented application. Here, we evaluate that this proof of concept is possible to some extend and lay down a solid baseline for this task. We discuss the limitations of our approach for further improvements. Our utilized metrics can be used as a tool for future comparisons in this domain. To enable further research on this task, the dataset is publicly available at https://bit.ly/3jN1pJJ
CMX: Cross-Modal Fusion for RGB-X Semantic Segmentation with Transformers
Apr 12, 2022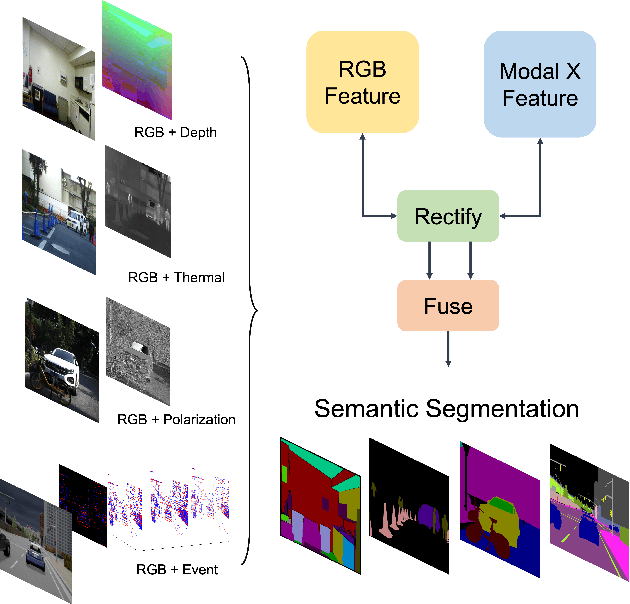
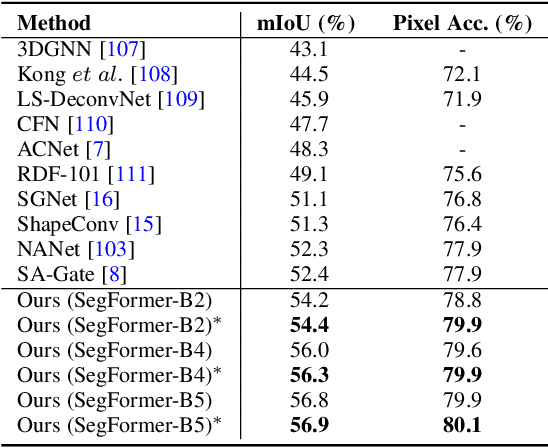
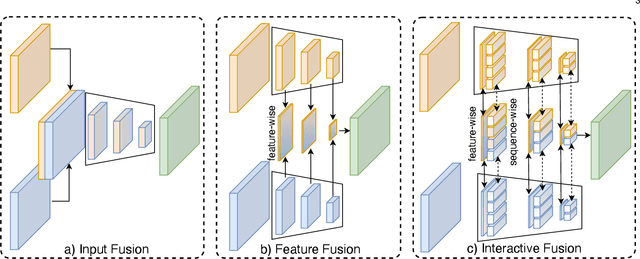
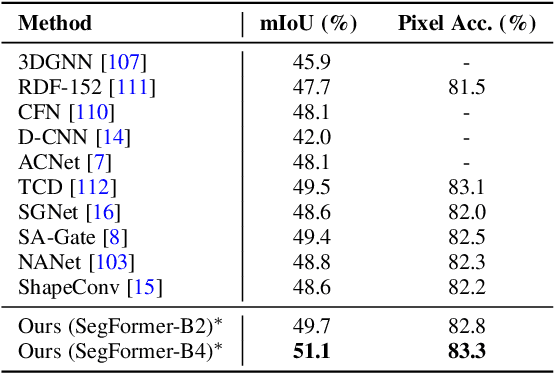
Pixel-wise semantic segmentation of RGB images can be advanced by exploiting informative features from supplementary modalities. In this work, we propose CMX, a vision-transformer-based cross-modal fusion framework for RGB-X semantic segmentation. To generalize to different sensing modalities encompassing various supplements and uncertainties, we consider that comprehensive cross-modal interactions should be provided. CMX is built with two streams to extract features from RGB images and the complementary modality (X-modality). In each feature extraction stage, we design a Cross-Modal Feature Rectification Module (CM-FRM) to calibrate the feature of the current modality by combining the feature from the other modality, in spatial- and channel-wise dimensions. With rectified feature pairs, we deploy a Feature Fusion Module (FFM) to mix them for the final semantic prediction. FFM is constructed with a cross-attention mechanism, which enables exchange of long-range contexts, enhancing both modalities' features at a global level. Extensive experiments show that CMX generalizes to diverse multi-modal combinations, achieving state-of-the-art performances on five RGB-Depth benchmarks, as well as RGB-Thermal and RGB-Polarization datasets. Besides, to investigate the generalizability to dense-sparse data fusion, we establish an RGB-Event semantic segmentation benchmark based on the EventScape dataset, on which CMX sets the new state-of-the-art. Code is available at https://github.com/huaaaliu/RGBX_Semantic_Segmentation.
Hierarchical Nearest Neighbor Graph Embedding for Efficient Dimensionality Reduction
Apr 11, 2022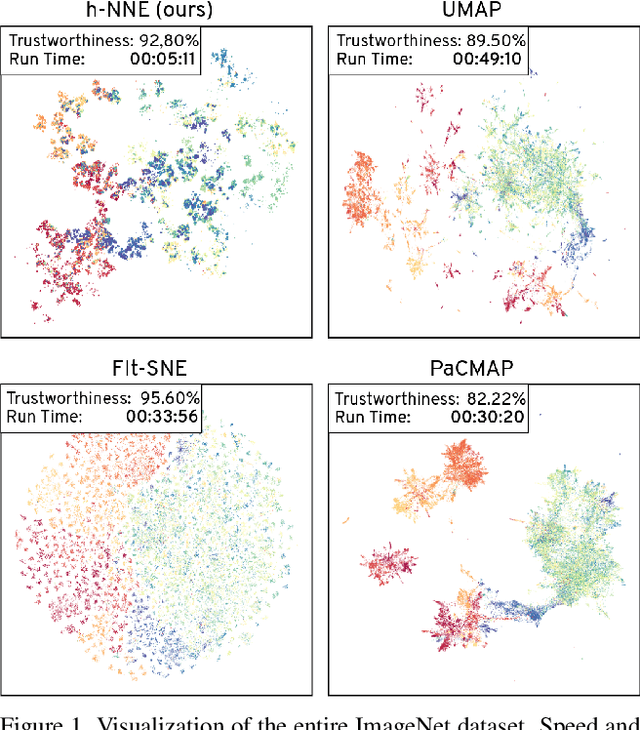

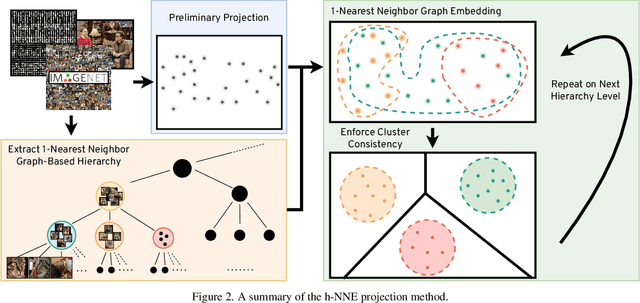
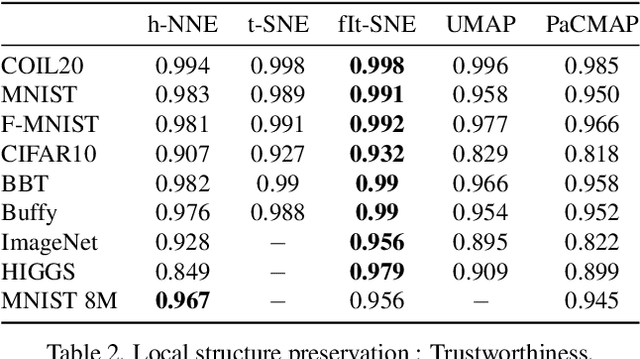
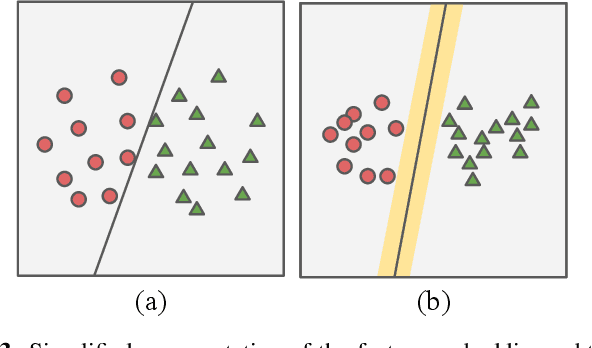
Dimensionality reduction is crucial both for visualization and preprocessing high dimensional data for machine learning. We introduce a novel method based on a hierarchy built on 1-nearest neighbor graphs in the original space which is used to preserve the grouping properties of the data distribution on multiple levels. The core of the proposal is an optimization-free projection that is competitive with the latest versions of t-SNE and UMAP in performance and visualization quality while being an order of magnitude faster in run-time. Furthermore, its interpretable mechanics, the ability to project new data, and the natural separation of data clusters in visualizations make it a general purpose unsupervised dimension reduction technique. In the paper, we argue about the soundness of the proposed method and evaluate it on a diverse collection of datasets with sizes varying from 1K to 11M samples and dimensions from 28 to 16K. We perform comparisons with other state-of-the-art methods on multiple metrics and target dimensions highlighting its efficiency and performance. Code is available at https://github.com/koulakis/h-nne
A Comparative Analysis of Decision-Level Fusion for Multimodal Driver Behaviour Understanding
Apr 10, 2022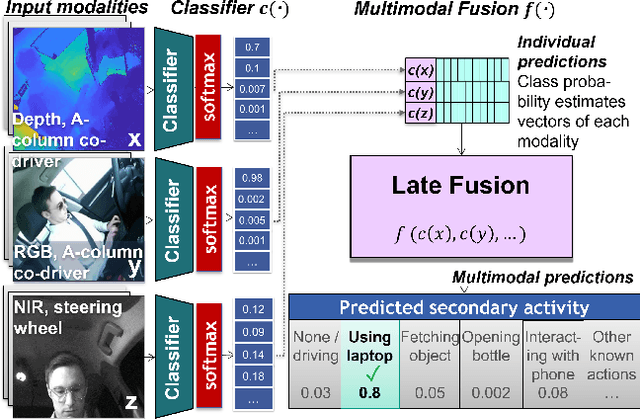

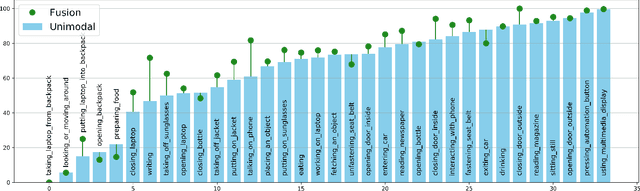
Visual recognition inside the vehicle cabin leads to safer driving and more intuitive human-vehicle interaction but such systems face substantial obstacles as they need to capture different granularities of driver behaviour while dealing with highly limited body visibility and changing illumination. Multimodal recognition mitigates a number of such issues: prediction outcomes of different sensors complement each other due to different modality-specific strengths and weaknesses. While several late fusion methods have been considered in previously published frameworks, they constantly feature different architecture backbones and building blocks making it very hard to isolate the role of the chosen late fusion strategy itself. This paper presents an empirical evaluation of different paradigms for decision-level late fusion in video-based driver observation. We compare seven different mechanisms for joining the results of single-modal classifiers which have been both popular, (e.g. score averaging) and not yet considered (e.g. rank-level fusion) in the context of driver observation evaluating them based on different criteria and benchmark settings. This is the first systematic study of strategies for fusing outcomes of multimodal predictors inside the vehicles, conducted with the goal to provide guidance for fusion scheme selection.
Is my Driver Observation Model Overconfident? Input-guided Calibration Networks for Reliable and Interpretable Confidence Estimates
Apr 10, 2022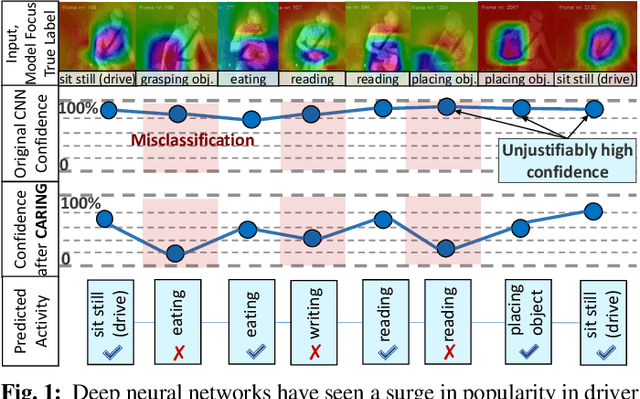
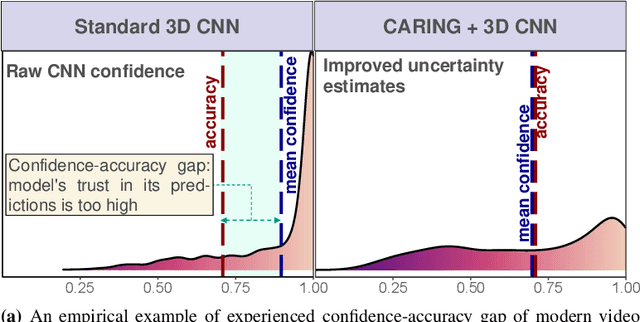
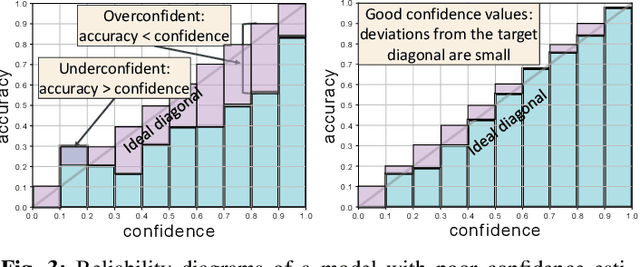

Driver observation models are rarely deployed under perfect conditions. In practice, illumination, camera placement and type differ from the ones present during training and unforeseen behaviours may occur at any time. While observing the human behind the steering wheel leads to more intuitive human-vehicle-interaction and safer driving, it requires recognition algorithms which do not only predict the correct driver state, but also determine their prediction quality through realistic and interpretable confidence measures. Reliable uncertainty estimates are crucial for building trust and are a serious obstacle for deploying activity recognition networks in real driving systems. In this work, we for the first time examine how well the confidence values of modern driver observation models indeed match the probability of the correct outcome and show that raw neural network-based approaches tend to significantly overestimate their prediction quality. To correct this misalignment between the confidence values and the actual uncertainty, we consider two strategies. First, we enhance two activity recognition models often used for driver observation with temperature scaling-an off-the-shelf method for confidence calibration in image classification. Then, we introduce Calibrated Action Recognition with Input Guidance (CARING)-a novel approach leveraging an additional neural network to learn scaling the confidences depending on the video representation. Extensive experiments on the Drive&Act dataset demonstrate that both strategies drastically improve the quality of model confidences, while our CARING model out-performs both, the original architectures and their temperature scaling enhancement, leading to best uncertainty estimates.