 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe THUMOS Challenge on Action Recognition for Videos "in the Wild"
Apr 21, 2016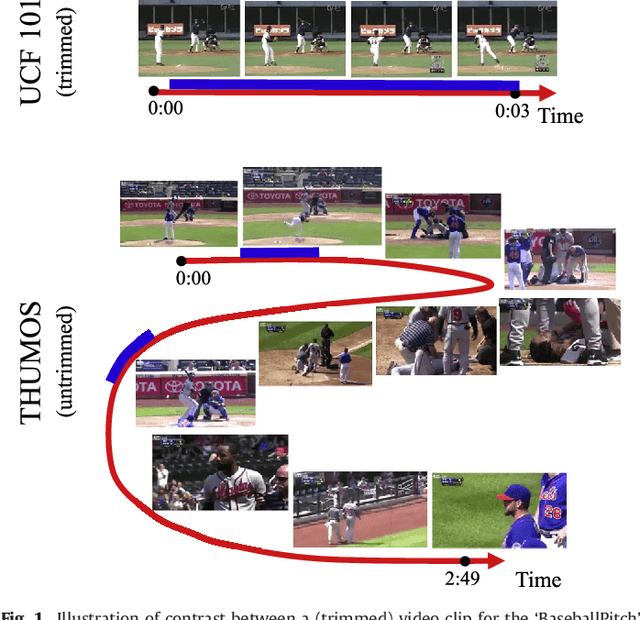
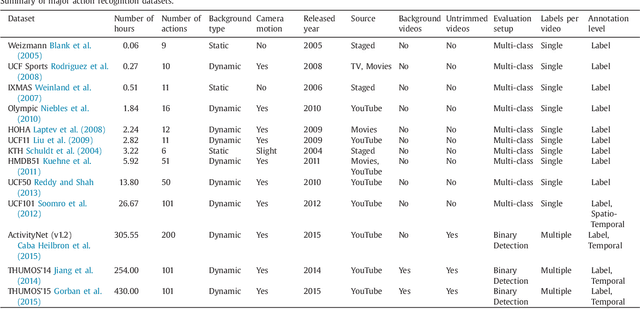
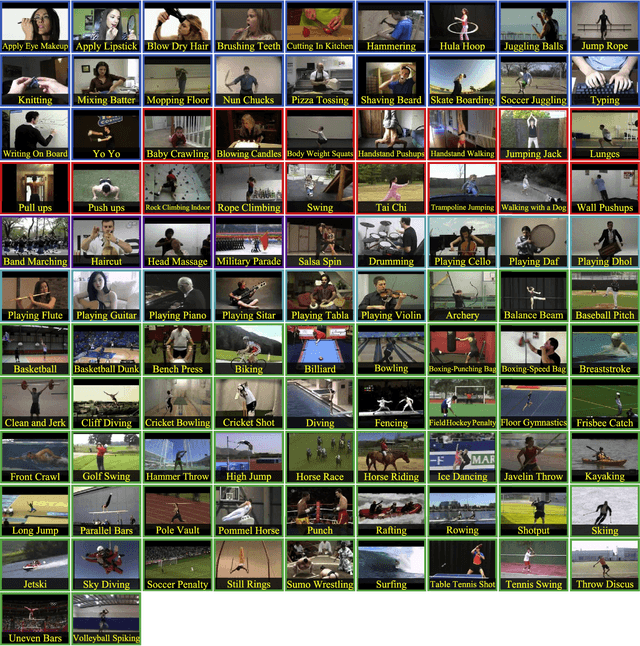
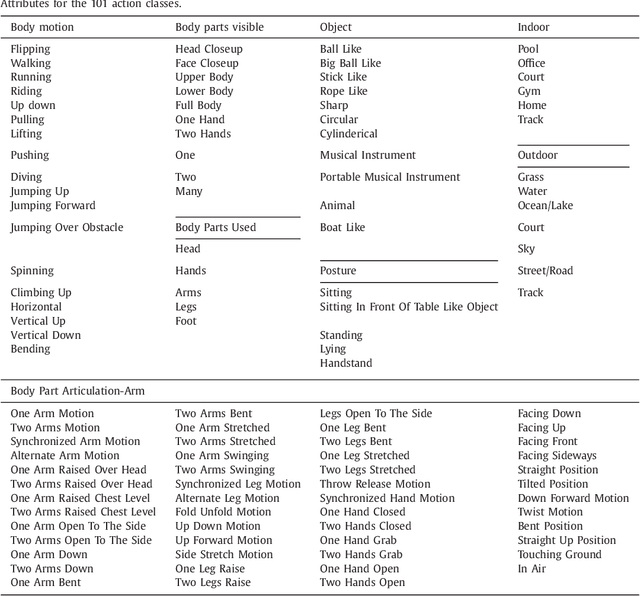
Automatically recognizing and localizing wide ranges of human actions has crucial importance for video understanding. Towards this goal, the THUMOS challenge was introduced in 2013 to serve as a benchmark for action recognition. Until then, video action recognition, including THUMOS challenge, had focused primarily on the classification of pre-segmented (i.e., trimmed) videos, which is an artificial task. In THUMOS 2014, we elevated action recognition to a more practical level by introducing temporally untrimmed videos. These also include `background videos' which share similar scenes and backgrounds as action videos, but are devoid of the specific actions. The three editions of the challenge organized in 2013--2015 have made THUMOS a common benchmark for action classification and detection and the annual challenge is widely attended by teams from around the world. In this paper we describe the THUMOS benchmark in detail and give an overview of data collection and annotation procedures. We present the evaluation protocols used to quantify results in the two THUMOS tasks of action classification and temporal detection. We also present results of submissions to the THUMOS 2015 challenge and review the participating approaches. Additionally, we include a comprehensive empirical study evaluating the differences in action recognition between trimmed and untrimmed videos, and how well methods trained on trimmed videos generalize to untrimmed videos. We conclude by proposing several directions and improvements for future THUMOS challenges.
Variable Rate Image Compression with Recurrent Neural Networks
Mar 01, 2016
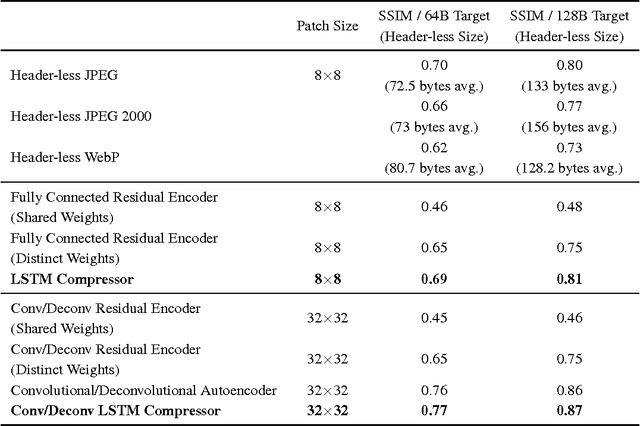
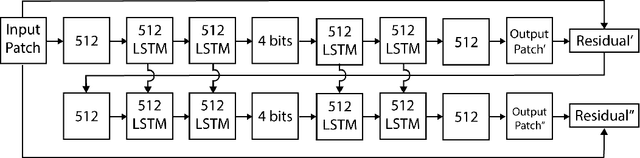

A large fraction of Internet traffic is now driven by requests from mobile devices with relatively small screens and often stringent bandwidth requirements. Due to these factors, it has become the norm for modern graphics-heavy websites to transmit low-resolution, low-bytecount image previews (thumbnails) as part of the initial page load process to improve apparent page responsiveness. Increasing thumbnail compression beyond the capabilities of existing codecs is therefore a current research focus, as any byte savings will significantly enhance the experience of mobile device users. Toward this end, we propose a general framework for variable-rate image compression and a novel architecture based on convolutional and deconvolutional LSTM recurrent networks. Our models address the main issues that have prevented autoencoder neural networks from competing with existing image compression algorithms: (1) our networks only need to be trained once (not per-image), regardless of input image dimensions and the desired compression rate; (2) our networks are progressive, meaning that the more bits are sent, the more accurate the image reconstruction; and (3) the proposed architecture is at least as efficient as a standard purpose-trained autoencoder for a given number of bits. On a large-scale benchmark of 32$\times$32 thumbnails, our LSTM-based approaches provide better visual quality than (headerless) JPEG, JPEG2000 and WebP, with a storage size that is reduced by 10% or more.
Labeling the Features Not the Samples: Efficient Video Classification with Minimal Supervision
Dec 01, 2015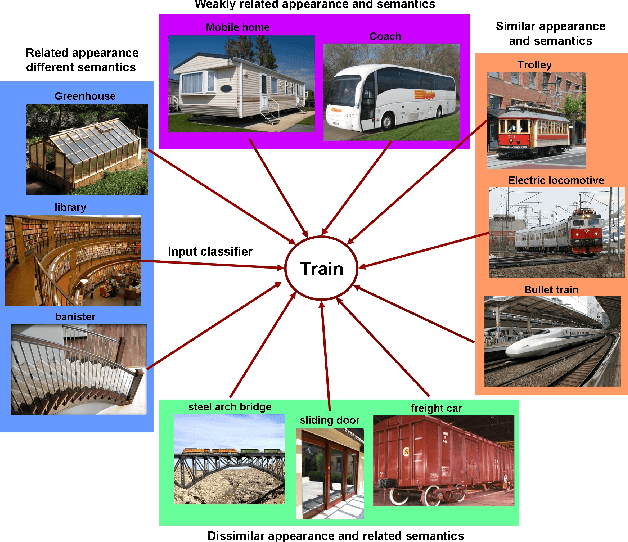

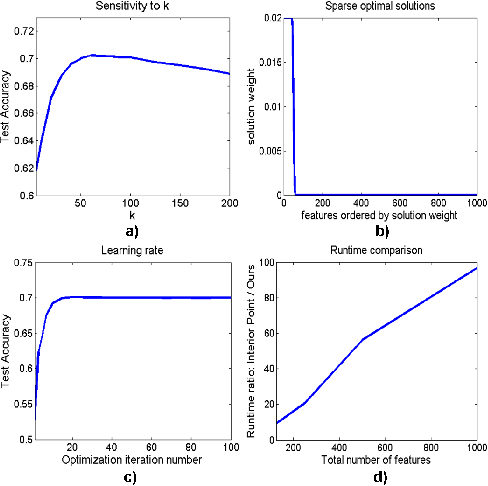
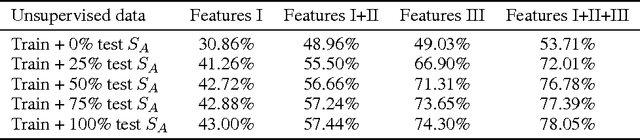
Feature selection is essential for effective visual recognition. We propose an efficient joint classifier learning and feature selection method that discovers sparse, compact representations of input features from a vast sea of candidates, with an almost unsupervised formulation. Our method requires only the following knowledge, which we call the \emph{feature sign}---whether or not a particular feature has on average stronger values over positive samples than over negatives. We show how this can be estimated using as few as a single labeled training sample per class. Then, using these feature signs, we extend an initial supervised learning problem into an (almost) unsupervised clustering formulation that can incorporate new data without requiring ground truth labels. Our method works both as a feature selection mechanism and as a fully competitive classifier. It has important properties, low computational cost and excellent accuracy, especially in difficult cases of very limited training data. We experiment on large-scale recognition in video and show superior speed and performance to established feature selection approaches such as AdaBoost, Lasso, greedy forward-backward selection, and powerful classifiers such as SVM.
Coreset-Based Adaptive Tracking
Nov 19, 2015
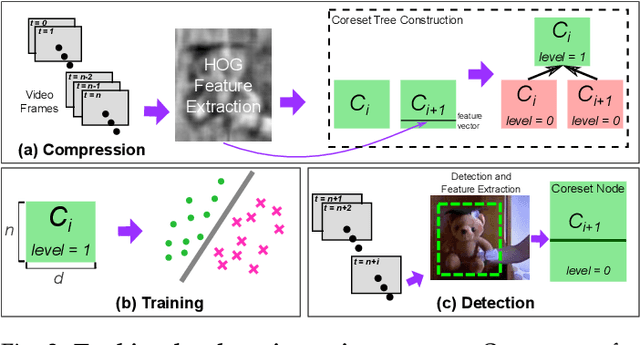
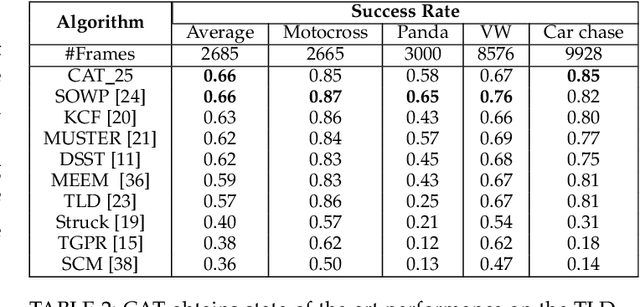
We propose a method for learning from streaming visual data using a compact, constant size representation of all the data that was seen until a given moment. Specifically, we construct a 'coreset' representation of streaming data using a parallelized algorithm, which is an approximation of a set with relation to the squared distances between this set and all other points in its ambient space. We learn an adaptive object appearance model from the coreset tree in constant time and logarithmic space and use it for object tracking by detection. Our method obtains excellent results for object tracking on three standard datasets over more than 100 videos. The ability to summarize data efficiently makes our method ideally suited for tracking in long videos in presence of space and time constraints. We demonstrate this ability by outperforming a variety of algorithms on the TLD dataset with 2685 frames on average. This coreset based learning approach can be applied for both real-time learning of small, varied data and fast learning of big data.
Temporal Localization of Fine-Grained Actions in Videos by Domain Transfer from Web Images
Aug 04, 2015
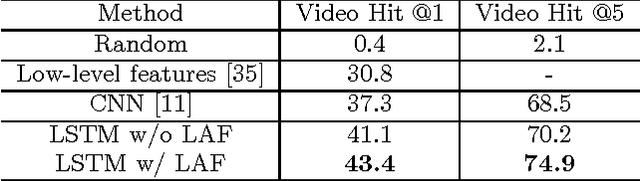
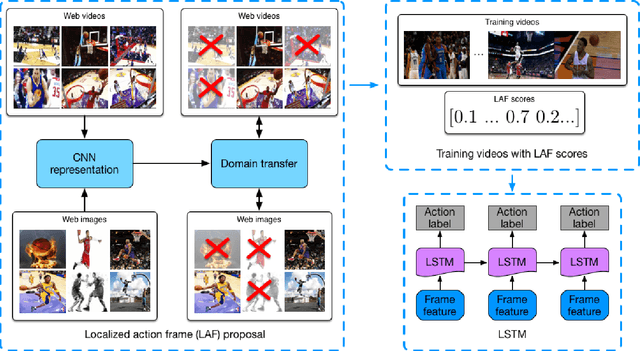
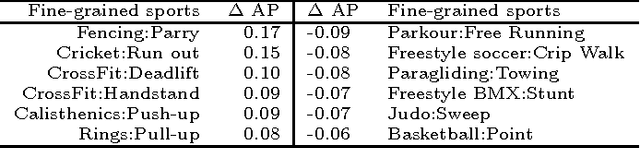
We address the problem of fine-grained action localization from temporally untrimmed web videos. We assume that only weak video-level annotations are available for training. The goal is to use these weak labels to identify temporal segments corresponding to the actions, and learn models that generalize to unconstrained web videos. We find that web images queried by action names serve as well-localized highlights for many actions, but are noisily labeled. To solve this problem, we propose a simple yet effective method that takes weak video labels and noisy image labels as input, and generates localized action frames as output. This is achieved by cross-domain transfer between video frames and web images, using pre-trained deep convolutional neural networks. We then use the localized action frames to train action recognition models with long short-term memory networks. We collect a fine-grained sports action data set FGA-240 of more than 130,000 YouTube videos. It has 240 fine-grained actions under 85 sports activities. Convincing results are shown on the FGA-240 data set, as well as the THUMOS 2014 localization data set with untrimmed training videos.
Articulated motion discovery using pairs of trajectories
Apr 24, 2015
We propose an unsupervised approach for discovering characteristic motion patterns in videos of highly articulated objects performing natural, unscripted behaviors, such as tigers in the wild. We discover consistent patterns in a bottom-up manner by analyzing the relative displacements of large numbers of ordered trajectory pairs through time, such that each trajectory is attached to a different moving part on the object. The pairs of trajectories descriptor relies entirely on motion and is more discriminative than state-of-the-art features that employ single trajectories. Our method generates temporal video intervals, each automatically trimmed to one instance of the discovered behavior, and clusters them by type (e.g., running, turning head, drinking water). We present experiments on two datasets: dogs from YouTube-Objects and a new dataset of National Geographic tiger videos. Results confirm that our proposed descriptor outperforms existing appearance- and trajectory-based descriptors (e.g., HOG and DTFs) on both datasets and enables us to segment unconstrained animal video into intervals containing single behaviors.
Features in Concert: Discriminative Feature Selection meets Unsupervised Clustering
Nov 27, 2014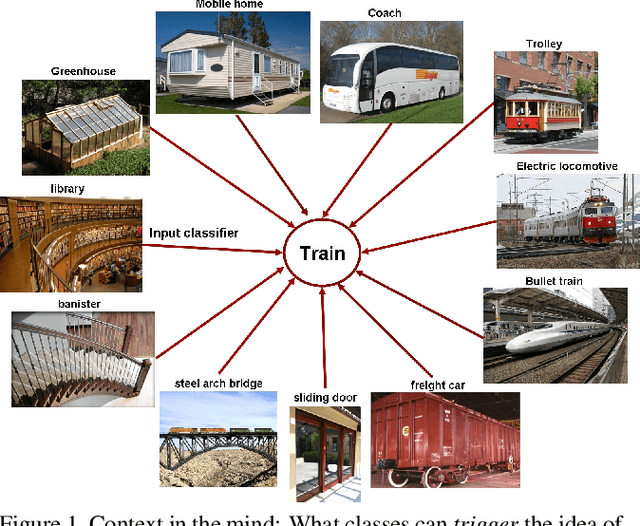
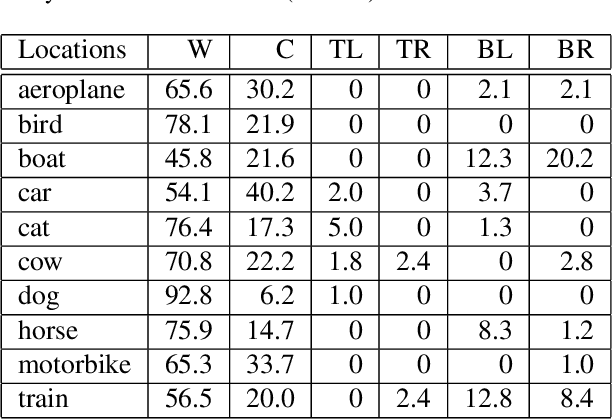
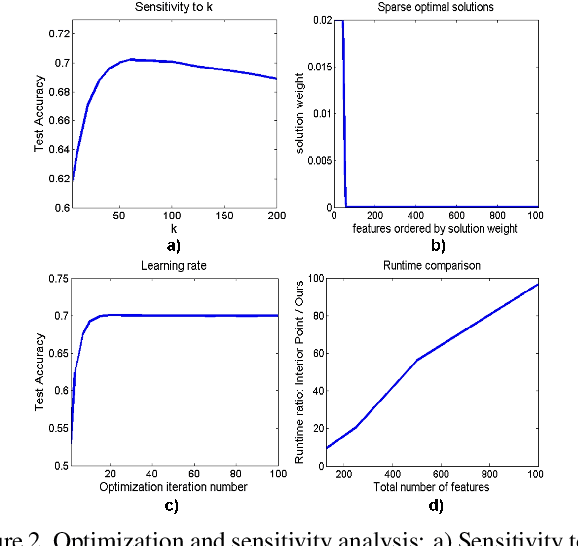

Feature selection is an essential problem in computer vision, important for category learning and recognition. Along with the rapid development of a wide variety of visual features and classifiers, there is a growing need for efficient feature selection and combination methods, to construct powerful classifiers for more complex and higher-level recognition tasks. We propose an algorithm that efficiently discovers sparse, compact representations of input features or classifiers, from a vast sea of candidates, with important optimality properties, low computational cost and excellent accuracy in practice. Different from boosting, we start with a discriminant linear classification formulation that encourages sparse solutions. Then we obtain an equivalent unsupervised clustering problem that jointly discovers ensembles of diverse features. They are independently valuable but even more powerful when united in a cluster of classifiers. We evaluate our method on the task of large-scale recognition in video and show that it significantly outperforms classical selection approaches, such as AdaBoost and greedy forward-backward selection, and powerful classifiers such as SVMs, in speed of training and performance, especially in the case of limited training data.
Thoughts on a Recursive Classifier Graph: a Multiclass Network for Deep Object Recognition
Apr 02, 2014
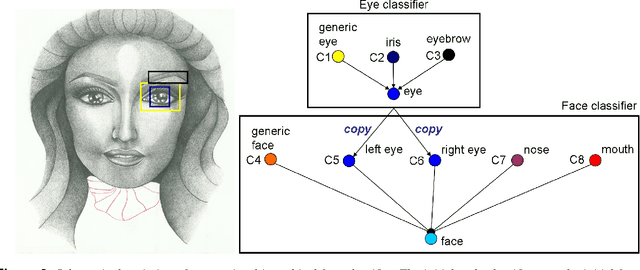
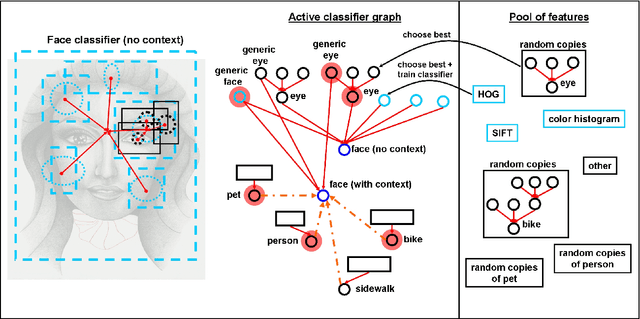
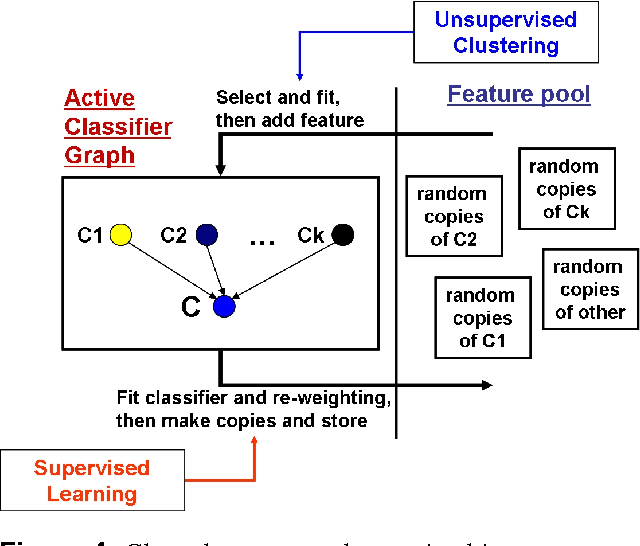
We propose a general multi-class visual recognition model, termed the Classifier Graph, which aims to generalize and integrate ideas from many of today's successful hierarchical recognition approaches. Our graph-based model has the advantage of enabling rich interactions between classes from different levels of interpretation and abstraction. The proposed multi-class system is efficiently learned using step by step updates. The structure consists of simple logistic linear layers with inputs from features that are automatically selected from a large pool. Each newly learned classifier becomes a potential new feature. Thus, our feature pool can consist both of initial manually designed features as well as learned classifiers from previous steps (graph nodes), each copied many times at different scales and locations. In this manner we can learn and grow both a deep, complex graph of classifiers and a rich pool of features at different levels of abstraction and interpretation. Our proposed graph of classifiers becomes a multi-class system with a recursive structure, suitable for deep detection and recognition of several classes simultaneously.
Bayesian Active Distance Metric Learning
Jun 20, 2012



Distance metric learning is an important component for many tasks, such as statistical classification and content-based image retrieval. Existing approaches for learning distance metrics from pairwise constraints typically suffer from two major problems. First, most algorithms only offer point estimation of the distance metric and can therefore be unreliable when the number of training examples is small. Second, since these algorithms generally select their training examples at random, they can be inefficient if labeling effort is limited. This paper presents a Bayesian framework for distance metric learning that estimates a posterior distribution for the distance metric from labeled pairwise constraints. We describe an efficient algorithm based on the variational method for the proposed Bayesian approach. Furthermore, we apply the proposed Bayesian framework to active distance metric learning by selecting those unlabeled example pairs with the greatest uncertainty in relative distance. Experiments in classification demonstrate that the proposed framework achieves higher classification accuracy and identifies more informative training examples than the non-Bayesian approach and state-of-the-art distance metric learning algorithms.
Generalized Boundaries from Multiple Image Interpretations
Feb 16, 2012

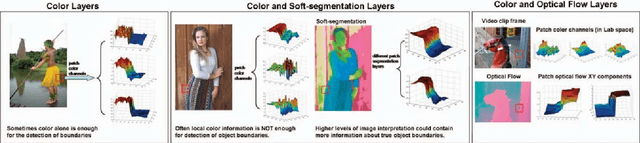

Boundary detection is essential for a variety of computer vision tasks such as segmentation and recognition. In this paper we propose a unified formulation and a novel algorithm that are applicable to the detection of different types of boundaries, such as intensity edges, occlusion boundaries or object category specific boundaries. Our formulation leads to a simple method with state-of-the-art performance and significantly lower computational cost than existing methods. We evaluate our algorithm on different types of boundaries, from low-level boundaries extracted in natural images, to occlusion boundaries obtained using motion cues and RGB-D cameras, to boundaries from soft-segmentation. We also propose a novel method for figure/ground soft-segmentation that can be used in conjunction with our boundary detection method and improve its accuracy at almost no extra computational cost.