 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Guided Image Captioning Performance across Domains
Dec 04, 2020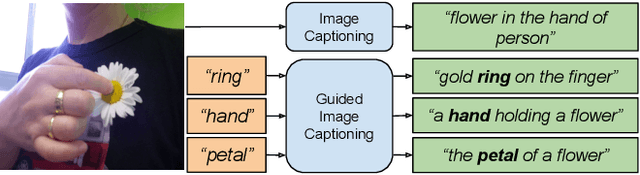

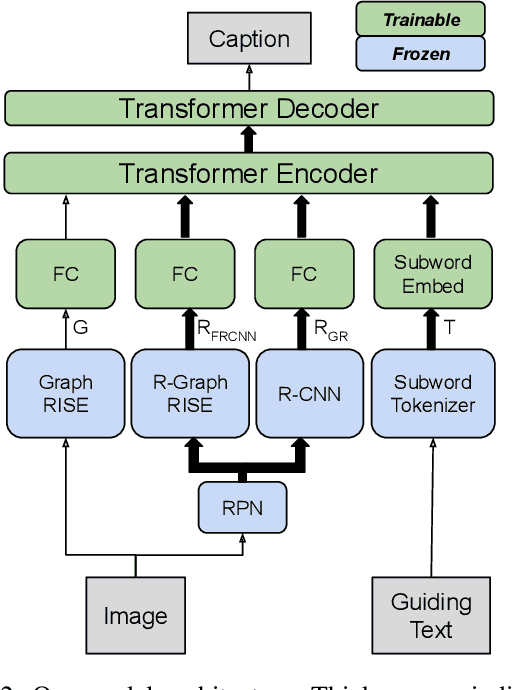
Image captioning models generally lack the capability to take into account user interest, and usually default to global descriptions that try to balance readability, informativeness, and information overload. On the other hand, VQA models generally lack the ability to provide long descriptive answers, while expecting the textual question to be quite precise. We present a method to control the concepts that an image caption should focus on, using an additional input called the guiding text that refers to either groundable or ungroundable concepts in the image. Our model consists of a Transformer-based multimodal encoder that uses the guiding text together with global and object-level image features to derive early-fusion representations used to generate the guided caption. While models trained on Visual Genome data have an in-domain advantage of fitting well when guided with automatic object labels, we find that guided captioning models trained on Conceptual Captions generalize better on out-of-domain images and guiding texts. Our human-evaluation results indicate that attempting in-the-wild guided image captioning requires access to large, unrestricted-domain training datasets, and that increased style diversity (even without increasing vocabulary size) is a key factor for improved performance.
Improving Text Generation Evaluation with Batch Centering and Tempered Word Mover Distance
Oct 13, 2020



Recent advances in automatic evaluation metrics for text have shown that deep contextualized word representations, such as those generated by BERT encoders, are helpful for designing metrics that correlate well with human judgements. At the same time, it has been argued that contextualized word representations exhibit sub-optimal statistical properties for encoding the true similarity between words or sentences. In this paper, we present two techniques for improving encoding representations for similarity metrics: a batch-mean centering strategy that improves statistical properties; and a computationally efficient tempered Word Mover Distance, for better fusion of the information in the contextualized word representations. We conduct numerical experiments that demonstrate the robustness of our techniques, reporting results over various BERT-backbone learned metrics and achieving state of the art correlation with human ratings on several benchmarks.
TeaForN: Teacher-Forcing with N-grams
Oct 09, 2020



Sequence generation models trained with teacher-forcing suffer from issues related to exposure bias and lack of differentiability across timesteps. Our proposed method, Teacher-Forcing with N-grams (TeaForN), addresses both these problems directly, through the use of a stack of N decoders trained to decode along a secondary time axis that allows model parameter updates based on N prediction steps. TeaForN can be used with a wide class of decoder architectures and requires minimal modifications from a standard teacher-forcing setup. Empirically, we show that TeaForN boosts generation quality on one Machine Translation benchmark, WMT 2014 English-French, and two News Summarization benchmarks, CNN/Dailymail and Gigaword.
Attention that does not Explain Away
Sep 29, 2020

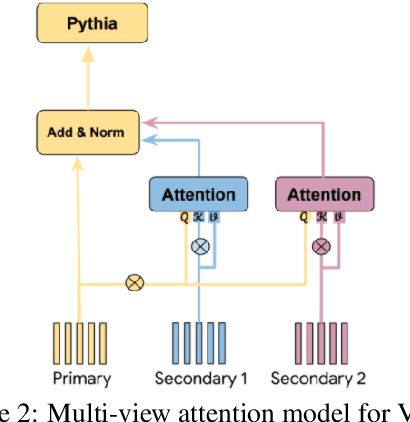

Models based on the Transformer architecture have achieved better accuracy than the ones based on competing architectures for a large set of tasks. A unique feature of the Transformer is its universal application of a self-attention mechanism, which allows for free information flow at arbitrary distances. Following a probabilistic view of the attention via the Gaussian mixture model, we find empirical evidence that the Transformer attention tends to "explain away" certain input neurons. To compensate for this, we propose a doubly-normalized attention scheme that is simple to implement and provides theoretical guarantees for avoiding the "explaining away" effect without introducing significant computational or memory cost. Empirically, we show that the new attention schemes result in improved performance on several well-known benchmarks.
Weakly Supervised Content Selection for Improved Image Captioning
Sep 10, 2020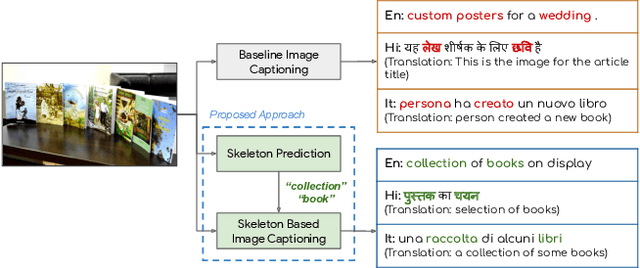
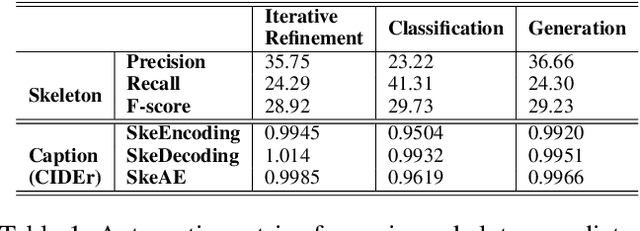
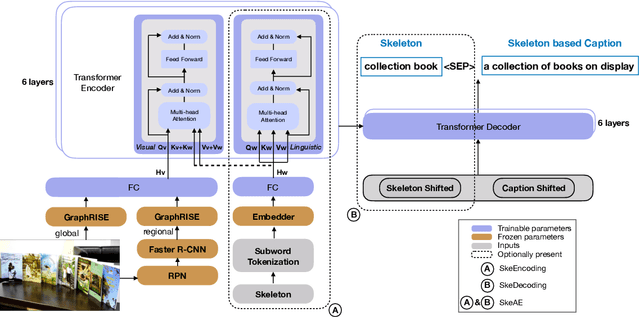
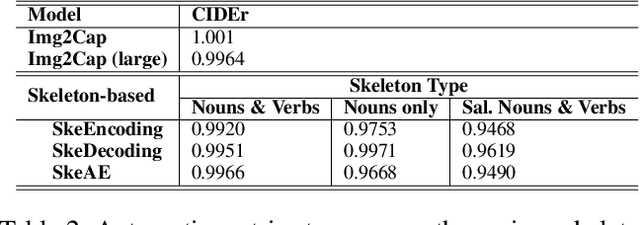
Image captioning involves identifying semantic concepts in the scene and describing them in fluent natural language. Recent approaches do not explicitly model the semantic concepts and train the model only for the end goal of caption generation. Such models lack interpretability and controllability, primarily due to sub-optimal content selection. We address this problem by breaking down the captioning task into two simpler, manageable and more controllable tasks -- skeleton prediction and skeleton-based caption generation. We approach the former as a weakly supervised task, using a simple off-the-shelf language syntax parser and avoiding the need for additional human annotations; the latter uses a supervised-learning approach. We investigate three methods of conditioning the caption on skeleton in the encoder, decoder and both. Our compositional model generates significantly better quality captions on out of domain test images, as judged by human annotators. Additionally, we demonstrate the cross-language effectiveness of the English skeleton to other languages including French, Italian, German, Spanish and Hindi. This compositional nature of captioning exhibits the potential of unpaired image captioning, thereby reducing the dependence on expensive image-caption pairs. Furthermore, we investigate the use of skeletons as a knob to control certain properties of the generated image caption, such as length, content, and gender expression.
Multi-Image Summarization: Textual Summary from a Set of Cohesive Images
Jun 15, 2020

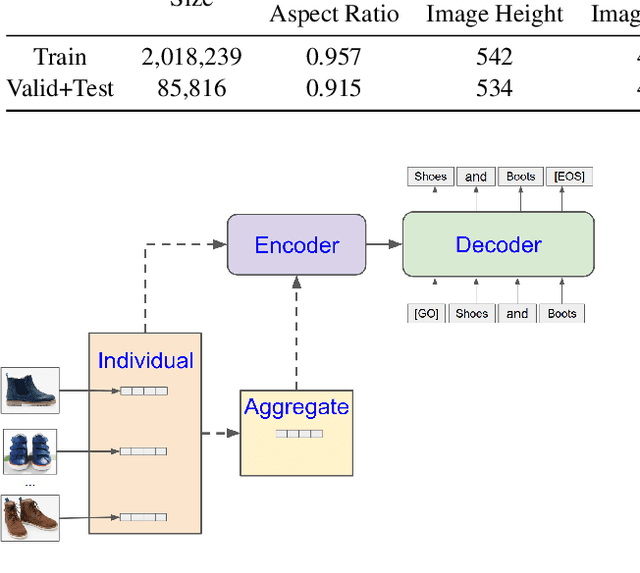
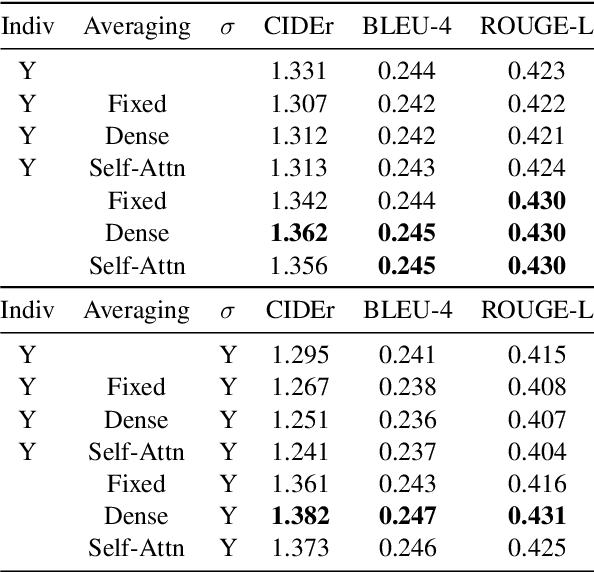
Multi-sentence summarization is a well studied problem in NLP, while generating image descriptions for a single image is a well studied problem in Computer Vision. However, for applications such as image cluster labeling or web page summarization, summarizing a set of images is also a useful and challenging task. This paper proposes the new task of multi-image summarization, which aims to generate a concise and descriptive textual summary given a coherent set of input images. We propose a model that extends the image-captioning Transformer-based architecture for single image to multi-image. A dense average image feature aggregation network allows the model to focus on a coherent subset of attributes across the input images. We explore various input representations to the Transformer network and empirically show that aggregated image features are superior to individual image embeddings. We additionally show that the performance of the model is further improved by pretraining the model parameters on a single-image captioning task, which appears to be particularly effective in eliminating hallucinations in the output.
Clue: Cross-modal Coherence Modeling for Caption Generation
May 02, 2020


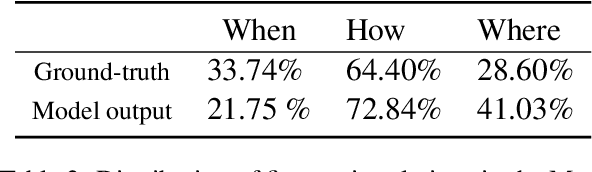
We use coherence relations inspired by computational models of discourse to study the information needs and goals of image captioning. Using an annotation protocol specifically devised for capturing image--caption coherence relations, we annotate 10,000 instances from publicly-available image--caption pairs. We introduce a new task for learning inferences in imagery and text, coherence relation prediction, and show that these coherence annotations can be exploited to learn relation classifiers as an intermediary step, and also train coherence-aware, controllable image captioning models. The results show a dramatic improvement in the consistency and quality of the generated captions with respect to information needs specified via coherence relations.
Cross-modal Language Generation using Pivot Stabilization for Web-scale Language Coverage
May 01, 2020
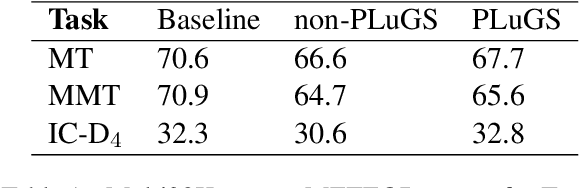
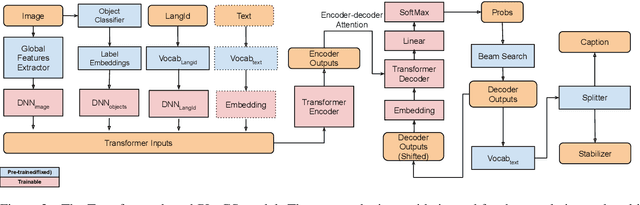
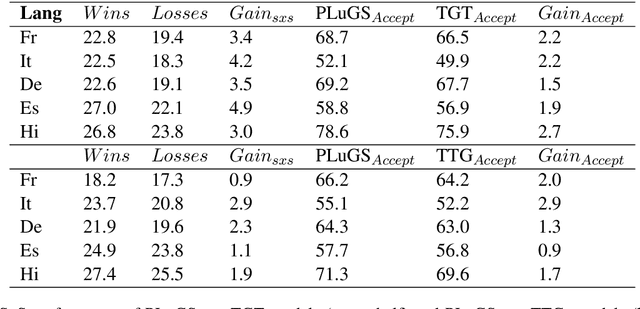
Cross-modal language generation tasks such as image captioning are directly hurt in their ability to support non-English languages by the trend of data-hungry models combined with the lack of non-English annotations. We investigate potential solutions for combining existing language-generation annotations in English with translation capabilities in order to create solutions at web-scale in both domain and language coverage. We describe an approach called Pivot-Language Generation Stabilization (PLuGS), which leverages directly at training time both existing English annotations (gold data) as well as their machine-translated versions (silver data); at run-time, it generates first an English caption and then a corresponding target-language caption. We show that PLuGS models outperform other candidate solutions in evaluations performed over 5 different target languages, under a large-domain testset using images from the Open Images dataset. Furthermore, we find an interesting effect where the English captions generated by the PLuGS models are better than the captions generated by the original, monolingual English model.
Beyond Instructional Videos: Probing for More Diverse Visual-Textual Grounding on YouTube
Apr 29, 2020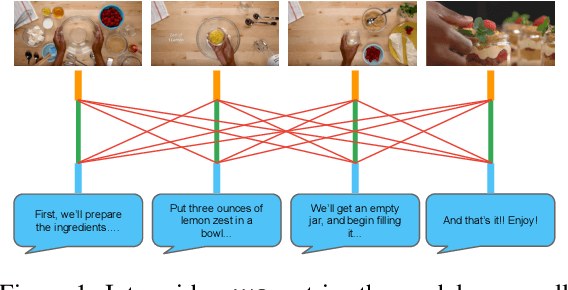
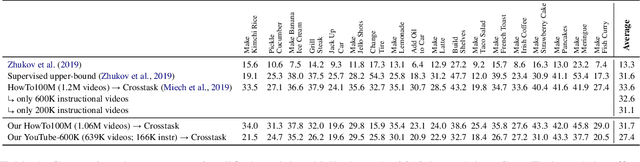
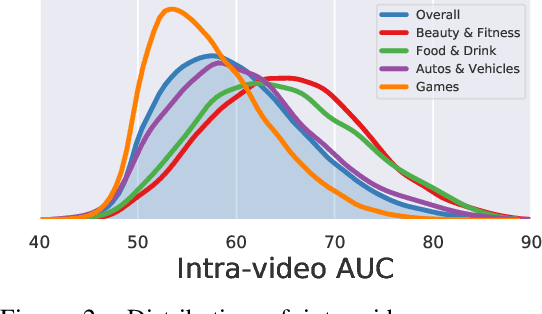
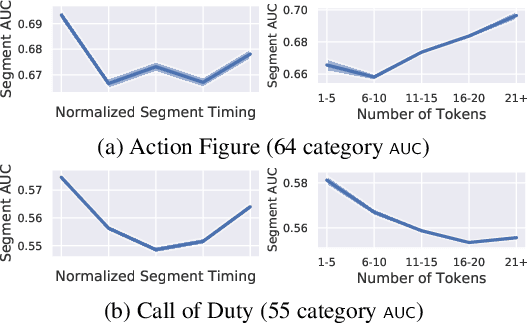
Pretraining from unlabelled web videos has quickly become the de-facto means of achieving high performance on many video understanding tasks. Features are learned via prediction of grounded relationships between visual content and automatic speech recognition (ASR) tokens. However, prior pretraining work has been limited to only instructional videos, a domain that, a priori, we expect to be relatively "easy:" speakers in instructional videos will often reference the literal objects/actions being depicted. Because instructional videos make up only a fraction of the web's diverse video content, we ask: can similar models be trained on broader corpora? And, if so, what types of videos are "grounded" and what types are not? We examine the diverse YouTube8M corpus, first verifying that it contains many non-instructional videos via crowd labeling. We pretrain a representative model on YouTube8M and study its success and failure cases. We find that visual-textual grounding is indeed possible across previously unexplored video categories, and that pretraining on a more diverse set still results in representations that generalize to both non-instructional and instructional domains.
Connecting Vision and Language with Localized Narratives
Dec 06, 2019

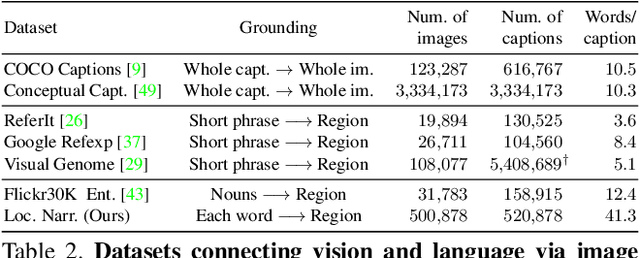
We propose Localized Narratives, an efficient way to collect image captions with dense visual grounding. We ask annotators to describe an image with their voice while simultaneously hovering their mouse over the region they are describing. Since the voice and the mouse pointer are synchronized, we can localize every single word in the description. This dense visual grounding takes the form of a mouse trace segment per word and is unique to our data. We annotate 500k images with Localized Narratives: the whole COCO dataset and 380k images of the Open Images dataset. We provide an extensive analysis of these annotations, which we will release early 2020. Moreover, we demonstrate the utility of our data on two applications which benefit from our mouse trace: controlled image captioning and image generation.