 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction of Tourism Flow with Sparse Geolocation Data
Aug 28, 2023Modern tourism in the 21st century is facing numerous challenges. Among these the rapidly growing number of tourists visiting space-limited regions like historical cities, museums and bottlenecks such as bridges is one of the biggest. In this context, a proper and accurate prediction of tourism volume and tourism flow within a certain area is important and critical for visitor management tasks such as sustainable treatment of the environment and prevention of overcrowding. Static flow control methods like conventional low-level controllers or limiting access to overcrowded venues could not solve the problem yet. In this paper, we empirically evaluate the performance of state-of-the-art deep-learning methods such as RNNs, GNNs, and Transformers as well as the classic statistical ARIMA method. Granular limited data supplied by a tourism region is extended by exogenous data such as geolocation trajectories of individual tourists, weather and holidays. In the field of visitor flow prediction with sparse data, we are thereby capable of increasing the accuracy of our predictions, incorporating modern input feature handling as well as mapping geolocation data on top of discrete POI data.
Robustness Analysis of Continuous-Depth Models with Lagrangian Techniques
Aug 23, 2023This paper presents, in a unified fashion, deterministic as well as statistical Lagrangian-verification techniques. They formally quantify the behavioral robustness of any time-continuous process, formulated as a continuous-depth model. To this end, we review LRT-NG, SLR, and GoTube, algorithms for constructing a tight reachtube, that is, an over-approximation of the set of states reachable within a given time-horizon, and provide guarantees for the reachtube bounds. We compare the usage of the variational equations, associated to the system equations, the mean value theorem, and the Lipschitz constants, in achieving deterministic and statistical guarantees. In LRT-NG, the Lipschitz constant is used as a bloating factor of the initial perturbation, to compute the radius of an ellipsoid in an optimal metric, which over-approximates the set of reachable states. In SLR and GoTube, we get statistical guarantees, by using the Lipschitz constants to compute local balls around samples. These are needed to calculate the probability of having found an upper bound, of the true maximum perturbation at every timestep. Our experiments demonstrate the superior performance of Lagrangian techniques, when compared to LRT, Flow*, and CAPD, and illustrate their use in the robustness analysis of various continuous-depth models.
* arXiv admin note: text overlap with arXiv:2107.08467
On the Benefits of Biophysical Synapses
Mar 08, 2023The approximation capability of ANNs and their RNN instantiations, is strongly correlated with the number of parameters packed into these networks. However, the complexity barrier for human understanding, is arguably related to the number of neurons and synapses in the networks, and to the associated nonlinear transformations. In this paper we show that the use of biophysical synapses, as found in LTCs, have two main benefits. First, they allow to pack more parameters for a given number of neurons and synapses. Second, they allow to formulate the nonlinear-network transformation, as a linear system with state-dependent coefficients. Both increase interpretability, as for a given task, they allow to learn a system linear in its input features, that is smaller in size compared to the state of the art. We substantiate the above claims on various time-series prediction tasks, but we believe that our results are applicable to any feedforward or recurrent ANN.
IB-U-Nets: Improving medical image segmentation tasks with 3D Inductive Biased kernels
Oct 28, 2022



Despite the success of convolutional neural networks for 3D medical-image segmentation, the architectures currently used are still not robust enough to the protocols of different scanners, and the variety of image properties they produce. Moreover, access to large-scale datasets with annotated regions of interest is scarce, and obtaining good results is thus difficult. To overcome these challenges, we introduce IB-U-Nets, a novel architecture with inductive bias, inspired by the visual processing in vertebrates. With the 3D U-Net as the base, we add two 3D residual components to the second encoder blocks. They provide an inductive bias, helping U-Nets to segment anatomical structures from 3D images with increased robustness and accuracy. We compared IB-U-Nets with state-of-the-art 3D U-Nets on multiple modalities and organs, such as the prostate and spleen, using the same training and testing pipeline, including data processing, augmentation and cross-validation. Our results demonstrate the superior robustness and accuracy of IB-U-Nets, especially on small datasets, as is typically the case in medical-image analysis. IB-U-Nets source code and models are publicly available.
Safe Policy Improvement in Constrained Markov Decision Processes
Oct 20, 2022The automatic synthesis of a policy through reinforcement learning (RL) from a given set of formal requirements depends on the construction of a reward signal and consists of the iterative application of many policy-improvement steps. The synthesis algorithm has to balance target, safety, and comfort requirements in a single objective and to guarantee that the policy improvement does not increase the number of safety-requirements violations, especially for safety-critical applications. In this work, we present a solution to the synthesis problem by solving its two main challenges: reward-shaping from a set of formal requirements and safe policy update. For the former, we propose an automatic reward-shaping procedure, defining a scalar reward signal compliant with the task specification. For the latter, we introduce an algorithm ensuring that the policy is improved in a safe fashion with high-confidence guarantees. We also discuss the adoption of a model-based RL algorithm to efficiently use the collected data and train a model-free agent on the predicted trajectories, where the safety violation does not have the same impact as in the real world. Finally, we demonstrate in standard control benchmarks that the resulting learning procedure is effective and robust even under heavy perturbations of the hyperparameters.
* Accepted for presentation at the International Symposium on Leveraging Applications of Formal Methods (ISoLA, 2022)
Deep-Learning vs Regression: Prediction of Tourism Flow with Limited Data
Jun 27, 2022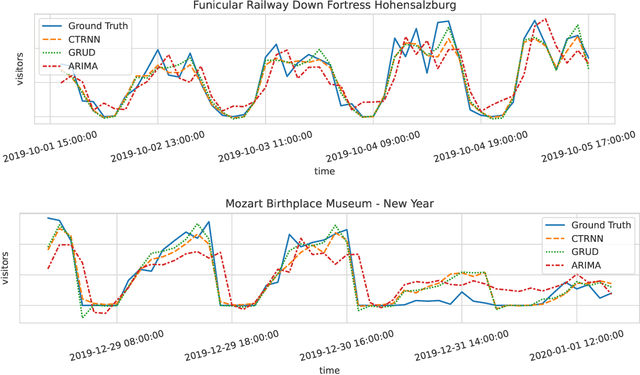

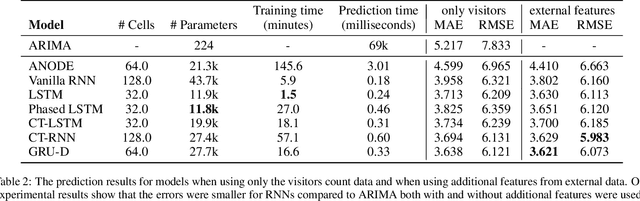
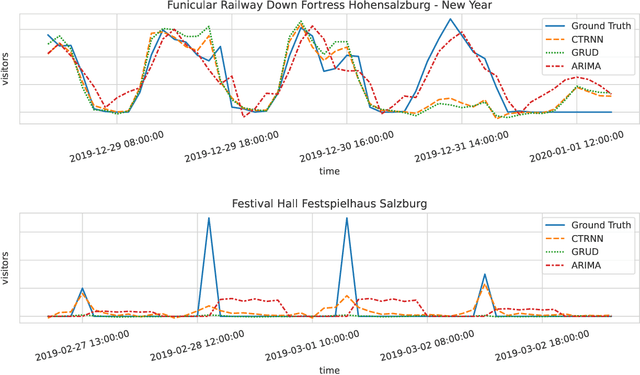
Modern tourism in the 21st century is facing numerous challenges. One of these challenges is the rapidly growing number of tourists in space limited regions such as historical city centers, museums or geographical bottlenecks like narrow valleys. In this context, a proper and accurate prediction of tourism volume and tourism flow within a certain area is important and critical for visitor management tasks such as visitor flow control and prevention of overcrowding. Static flow control methods like limiting access to hotspots or using conventional low level controllers could not solve the problem yet. In this paper, we empirically evaluate the performance of several state-of-the-art deep-learning methods in the field of visitor flow prediction with limited data by using available granular data supplied by a tourism region and comparing the results to ARIMA, a classical statistical method. Our results show that deep-learning models yield better predictions compared to the ARIMA method, while both featuring faster inference times and being able to incorporate additional input features.
Entangled Residual Mappings
Jun 02, 2022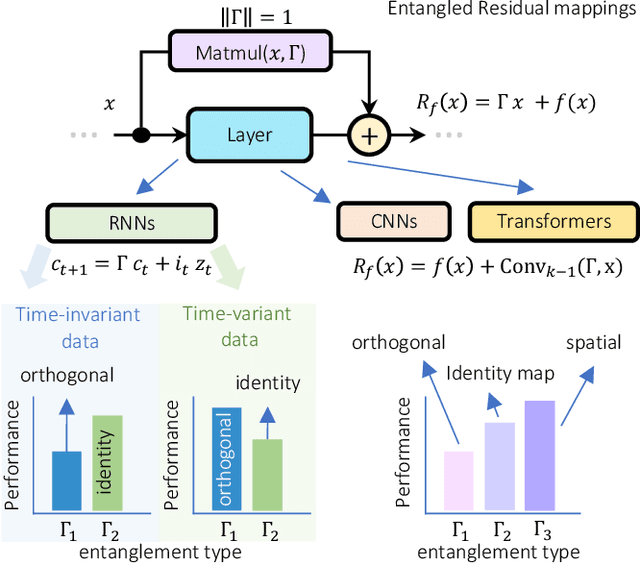
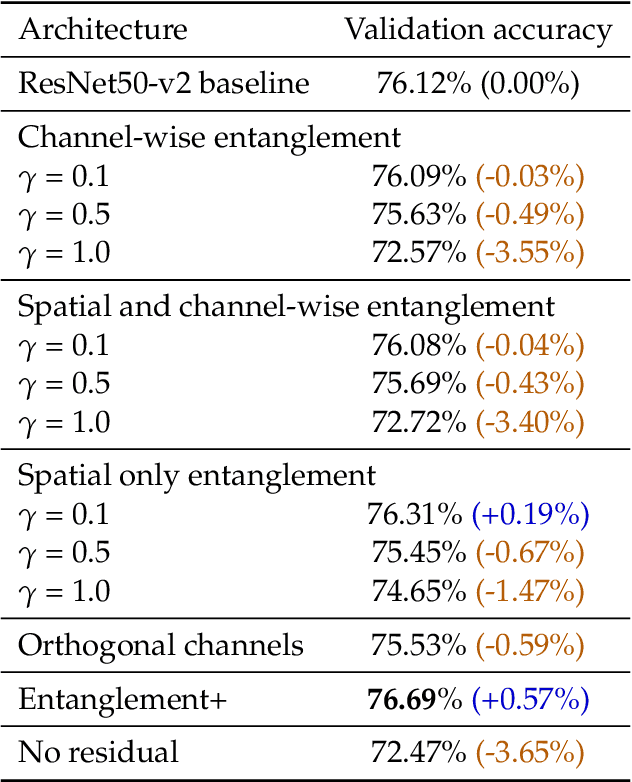
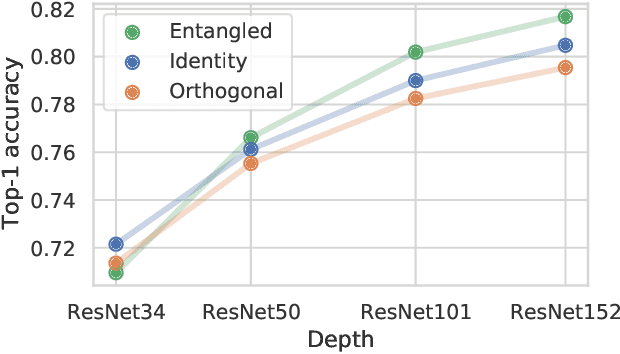
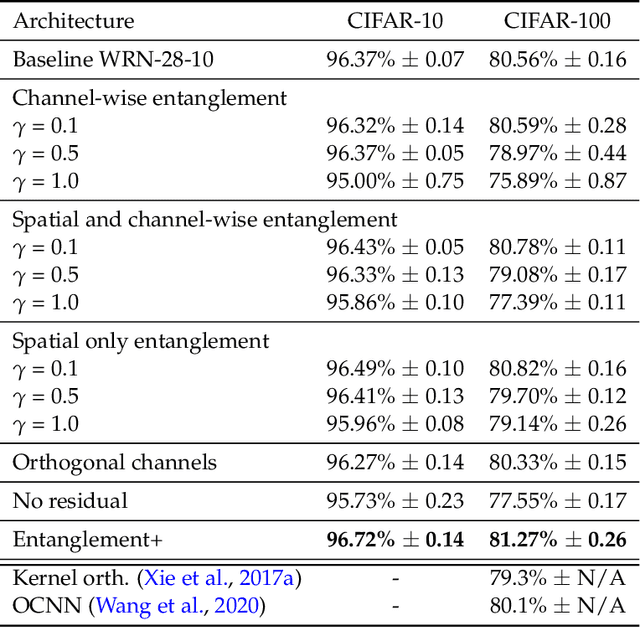
Residual mappings have been shown to perform representation learning in the first layers and iterative feature refinement in higher layers. This interplay, combined with their stabilizing effect on the gradient norms, enables them to train very deep networks. In this paper, we take a step further and introduce entangled residual mappings to generalize the structure of the residual connections and evaluate their role in iterative learning representations. An entangled residual mapping replaces the identity skip connections with specialized entangled mappings such as orthogonal, sparse, and structural correlation matrices that share key attributes (eigenvalues, structure, and Jacobian norm) with identity mappings. We show that while entangled mappings can preserve the iterative refinement of features across various deep models, they influence the representation learning process in convolutional networks differently than attention-based models and recurrent neural networks. In general, we find that for CNNs and Vision Transformers entangled sparse mapping can help generalization while orthogonal mappings hurt performance. For recurrent networks, orthogonal residual mappings form an inductive bias for time-variant sequences, which degrades accuracy on time-invariant tasks.
End-to-End Sensitivity-Based Filter Pruning
Apr 15, 2022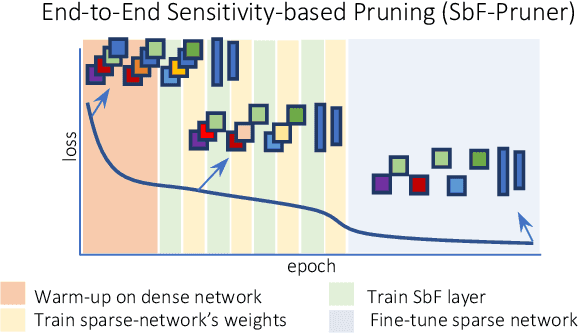
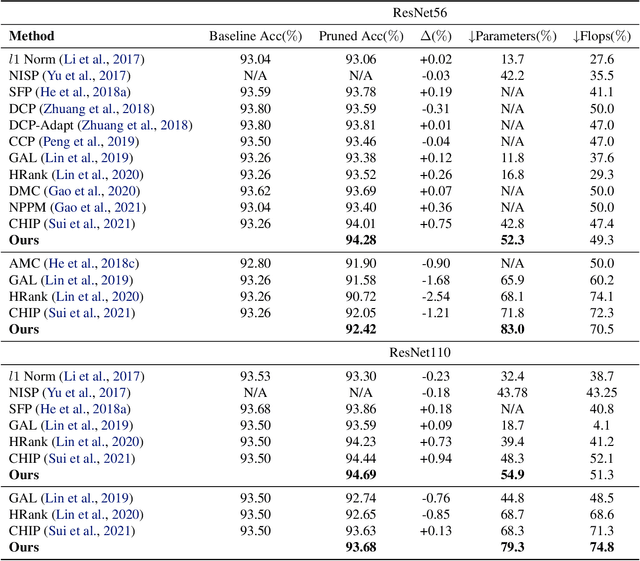
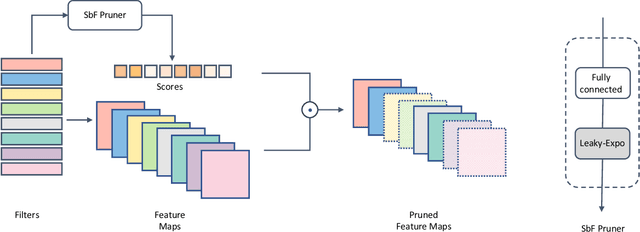
In this paper, we present a novel sensitivity-based filter pruning algorithm (SbF-Pruner) to learn the importance scores of filters of each layer end-to-end. Our method learns the scores from the filter weights, enabling it to account for the correlations between the filters of each layer. Moreover, by training the pruning scores of all layers simultaneously our method can account for layer interdependencies, which is essential to find a performant sparse sub-network. Our proposed method can train and generate a pruned network from scratch in a straightforward, one-stage training process without requiring a pretrained network. Ultimately, we do not need layer-specific hyperparameters and pre-defined layer budgets, since SbF-Pruner can implicitly determine the appropriate number of channels in each layer. Our experimental results on different network architectures suggest that SbF-Pruner outperforms advanced pruning methods. Notably, on CIFAR-10, without requiring a pretrained baseline network, we obtain 1.02% and 1.19% accuracy gain on ResNet56 and ResNet110, compared to the baseline reported for state-of-the-art pruning algorithms. This is while SbF-Pruner reduces parameter-count by 52.3% (for ResNet56) and 54% (for ResNet101), which is better than the state-of-the-art pruning algorithms with a high margin of 9.5% and 6.6%.
Multi-Agent Spatial Predictive Control with Application to Drone Flocking (Extended Version)
Mar 31, 2022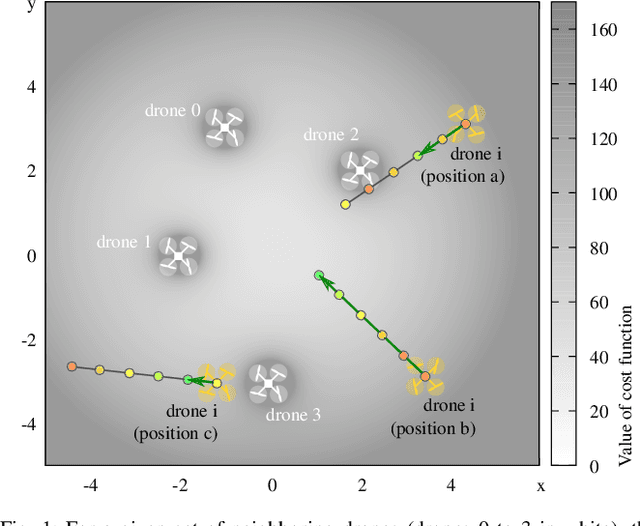
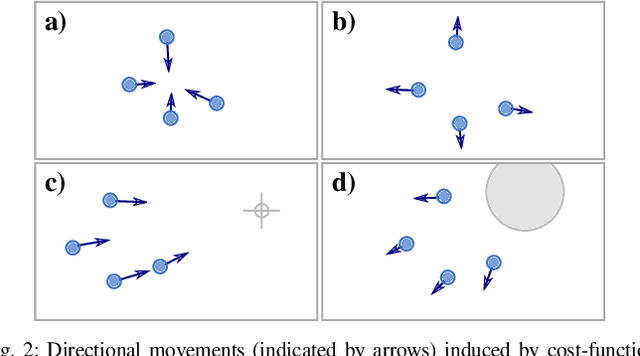
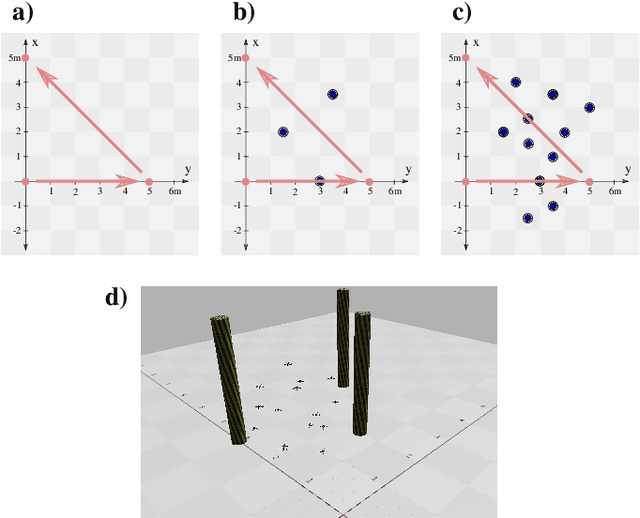
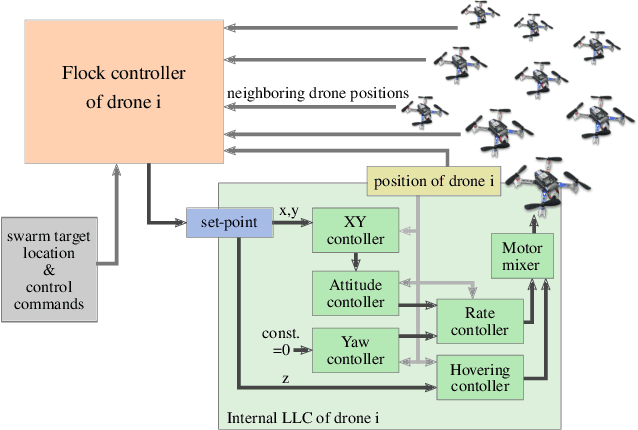
We introduce the novel concept of Spatial Predictive Control (SPC) to solve the following problem: given a collection of agents (e.g., drones) with positional low-level controllers (LLCs) and a mission-specific distributed cost function, how can a distributed controller achieve and maintain cost-function minimization without a plant model and only positional observations of the environment? Our fully distributed SPC controller is based strictly on the position of the agent itself and on those of its neighboring agents. This information is used in every time-step to compute the gradient of the cost function and to perform a spatial look-ahead to predict the best next target position for the LLC. Using a high-fidelity simulation environment, we show that SPC outperforms the most closely related class of controllers, Potential Field Controllers, on the drone flocking problem. We also show that SPC is able to cope with a potential sim-to-real transfer gap by demonstrating its performance on real hardware, namely our implementation of flocking using nine Crazyflie 2.1 drones.
3D-OOCS: Learning Prostate Segmentation with Inductive Bias
Oct 29, 2021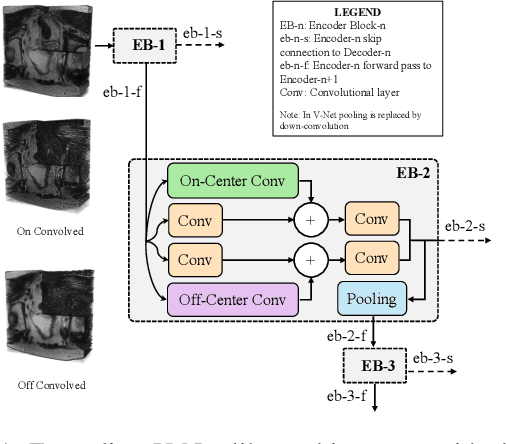
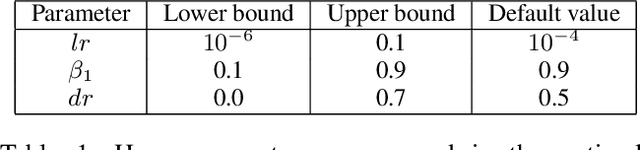
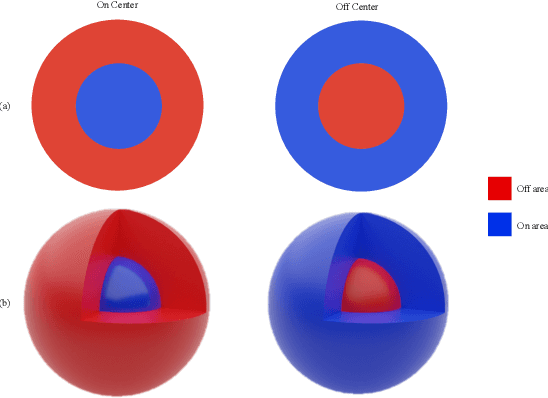
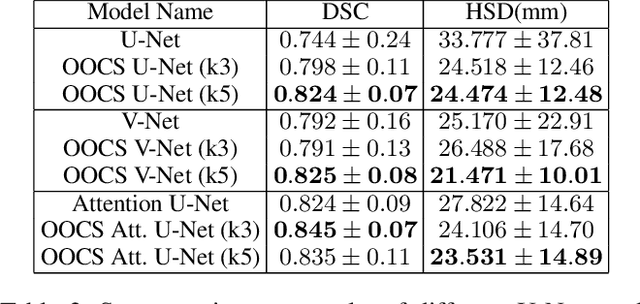
Despite the great success of convolutional neural networks (CNN) in 3D medical image segmentation tasks, the methods currently in use are still not robust enough to the different protocols utilized by different scanners, and to the variety of image properties or artefacts they produce. To this end, we introduce OOCS-enhanced networks, a novel architecture inspired by the innate nature of visual processing in the vertebrates. With different 3D U-Net variants as the base, we add two 3D residual components to the second encoder blocks: on and off center-surround (OOCS). They generalise the ganglion pathways in the retina to a 3D setting. The use of 2D-OOCS in any standard CNN network complements the feedforward framework with sharp edge-detection inductive biases. The use of 3D-OOCS also helps 3D U-Nets to scrutinise and delineate anatomical structures present in 3D images with increased accuracy.We compared the state-of-the-art 3D U-Nets with their 3D-OOCS extensions and showed the superior accuracy and robustness of the latter in automatic prostate segmentation from 3D Magnetic Resonance Images (MRIs). For a fair comparison, we trained and tested all the investigated 3D U-Nets with the same pipeline, including automatic hyperparameter optimisation and data augmentation.