 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-modal Garden Dataset and Hybrid 3D Dense Reconstruction Framework Based on Panoramic Stereo Images for a Trimming Robot
May 10, 2023



Recovering an outdoor environment's surface mesh is vital for an agricultural robot during task planning and remote visualization. Our proposed solution is based on a newly-designed panoramic stereo camera along with a hybrid novel software framework that consists of three fusion modules. The panoramic stereo camera with a pentagon shape consists of 5 stereo vision camera pairs to stream synchronized panoramic stereo images for the following three fusion modules. In the disparity fusion module, rectified stereo images produce the initial disparity maps using multiple stereo vision algorithms. Then, these initial disparity maps, along with the intensity images, are input into a disparity fusion network to produce refined disparity maps. Next, the refined disparity maps are converted into full-view point clouds or single-view point clouds for the pose fusion module. The pose fusion module adopts a two-stage global-coarse-to-local-fine strategy. In the first stage, each pair of full-view point clouds is registered by a global point cloud matching algorithm to estimate the transformation for a global pose graph's edge, which effectively implements loop closure. In the second stage, a local point cloud matching algorithm is used to match single-view point clouds in different nodes. Next, we locally refine the poses of all corresponding edges in the global pose graph using three proposed rules, thus constructing a refined pose graph. The refined pose graph is optimized to produce a global pose trajectory for volumetric fusion. In the volumetric fusion module, the global poses of all the nodes are used to integrate the single-view point clouds into the volume to produce the mesh of the whole garden. The proposed framework and its three fusion modules are tested on a real outdoor garden dataset to show the superiority of the performance.
DUGMA: Dynamic Uncertainty-Based Gaussian Mixture Alignment
Aug 02, 2018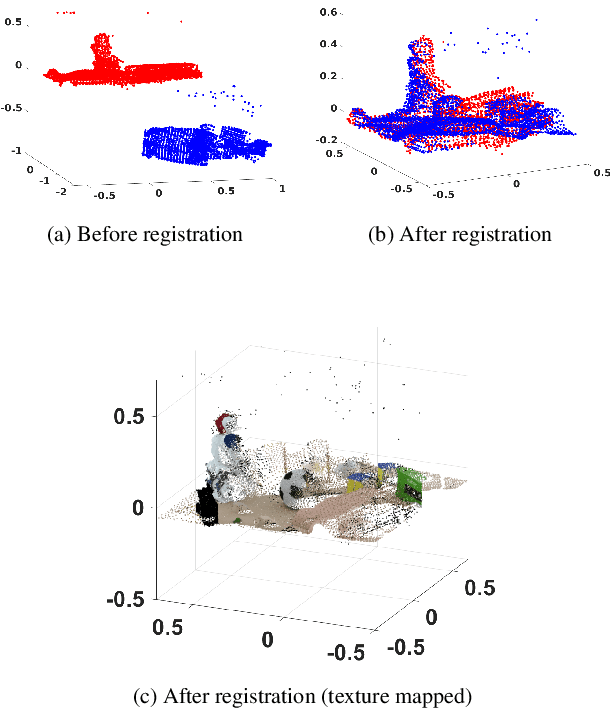


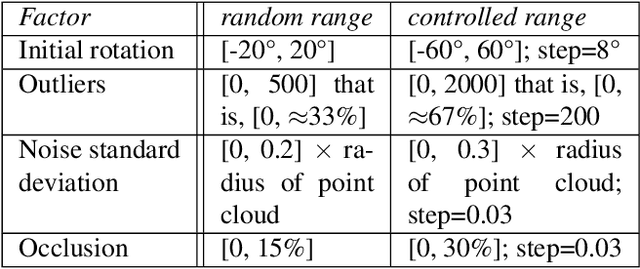
Registering accurately point clouds from a cheap low-resolution sensor is a challenging task. Existing rigid registration methods failed to use the physical 3D uncertainty distribution of each point from a real sensor in the dynamic alignment process mainly because the uncertainty model for a point is static and invariant and it is hard to describe the change of these physical uncertainty models in the registration process. Additionally, the existing Gaussian mixture alignment architecture cannot be efficiently implement these dynamic changes. This paper proposes a simple architecture combining error estimation from sample covariances and dual dynamic global probability alignment using the convolution of uncertainty-based Gaussian Mixture Models (GMM) from point clouds. Firstly, we propose an efficient way to describe the change of each 3D uncertainty model, which represents the structure of the point cloud much better. Unlike the invariant GMM (representing a fixed point cloud) in traditional Gaussian mixture alignment, we use two uncertainty-based GMMs that change and interact with each other in each iteration. In order to have a wider basin of convergence than other local algorithms, we design a more robust energy function by convolving efficiently the two GMMs over the whole 3D space. Tens of thousands of trials have been conducted on hundreds of models from multiple datasets to demonstrate the proposed method's superior performance compared with the current state-of-the-art methods. The new dataset and code is available from https://github.com/Canpu999
Hybrid Multi-camera Visual Servoing to Moving Target
Aug 02, 2018
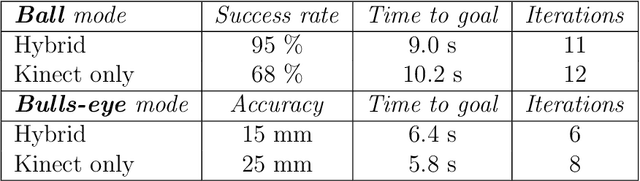
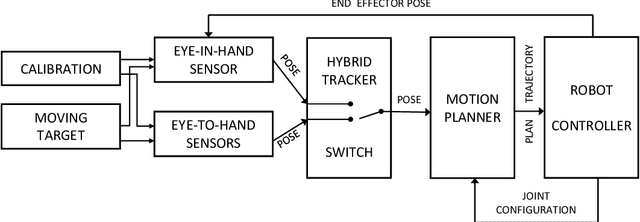
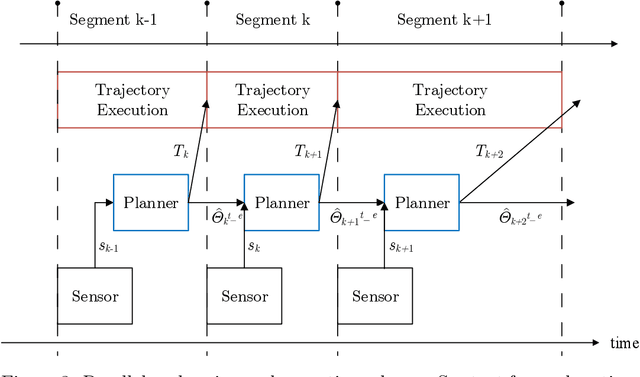
Visual servoing is a well-known task in robotics. However, there are still challenges when multiple visual sources are combined to accurately guide the robot or occlusions appear. In this paper we present a novel visual servoing approach using hybrid multi-camera input data to lead a robot arm accurately to dynamically moving target points in the presence of partial occlusions. The approach uses four RGBD sensors as Eye-to-Hand (EtoH) visual input, and an arm-mounted stereo camera as Eye-in-Hand (EinH). A Master supervisor task selects between using the EtoH or the EinH, depending on the distance between the robot and target. The Master also selects the subset of EtoH cameras that best perceive the target. When the EinH sensor is used, if the target becomes occluded or goes out of the sensor's view-frustum, the Master switches back to the EtoH sensors to re-track the object. Using this adaptive visual input data, the robot is then controlled using an iterative planner that uses position, orientation and joint configuration to estimate the trajectory. Since the target is dynamic, this trajectory is updated every time-step. Experiments show good performance in four different situations: tracking a ball, targeting a bulls-eye, guiding a straw to a mouth and delivering an item to a moving hand. The experiments cover both simple situations such as a ball that is mostly visible from all cameras, and more complex situations such as the mouth which is partially occluded from some of the sensors.
TrimBot2020: an outdoor robot for automatic gardening
May 15, 2018
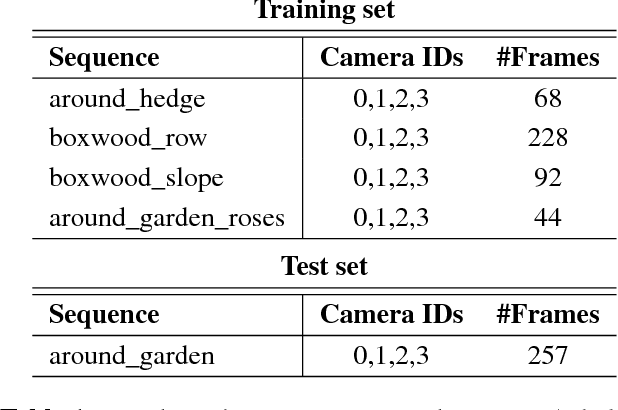

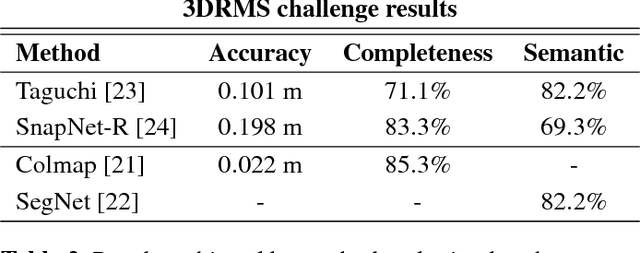
Robots are increasingly present in modern industry and also in everyday life. Their applications range from health-related situations, for assistance to elderly people or in surgical operations, to automatic and driver-less vehicles (on wheels or flying) or for driving assistance. Recently, an interest towards robotics applied in agriculture and gardening has arisen, with applications to automatic seeding and cropping or to plant disease control, etc. Autonomous lawn mowers are succesful market applications of gardening robotics. In this paper, we present a novel robot that is developed within the TrimBot2020 project, funded by the EU H2020 program. The project aims at prototyping the first outdoor robot for automatic bush trimming and rose pruning.
Best Viewpoint Tracking for Camera Mounted on Robotic Arm with Dynamic Obstacles
Oct 17, 2017
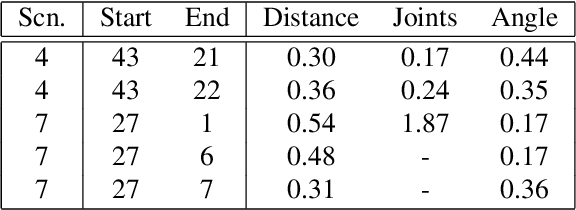
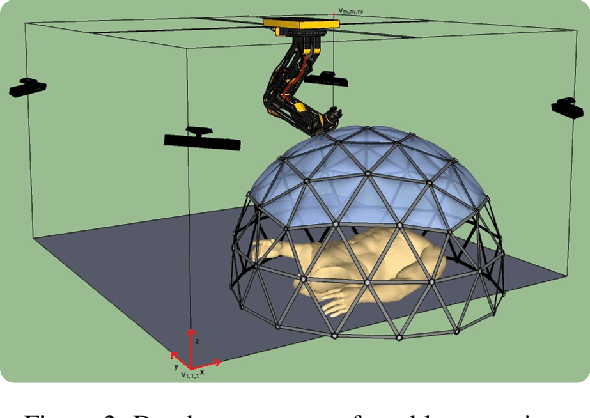
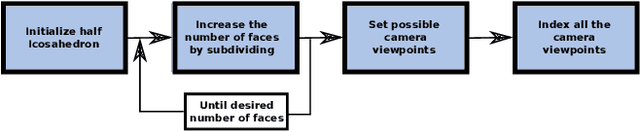
The problem of finding a next best viewpoint for 3D modeling or scene mapping has been explored in computer vision over the last decade. This paper tackles a similar problem, but with different characteristics. It proposes a method for dynamic next best viewpoint recovery of a target point while avoiding possible occlusions. Since the environment can change, the method has to iteratively find the next best view with a global understanding of the free and occupied parts. We model the problem as a set of possible viewpoints which correspond to the centers of the facets of a virtual tessellated hemisphere covering the scene. Taking into account occlusions, distances between current and future viewpoints, quality of the viewpoint and joint constraints (robot arm joint distances or limits), we evaluate the next best viewpoint. The proposal has been evaluated on 8 different scenarios with different occlusions and a short 3D video sequence to validate its dynamic performance.