 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeeLasmobranc Dataset: An Image Dataset for Elasmobranch Species Recognition and Biodiversity Monitoring
Mar 11, 2026Elasmobranch populations are experiencing significant global declines, and several species are currently classified as threatened. Reliable monitoring and species-level identification are essential to support conservation and spatial planning initiatives such as Important Shark and Ray Areas (ISRAs). However, existing visual datasets are predominantly detection-oriented, underwater-acquired, or limited to coarse-grained categories, restricting their applicability to fine-grained morphological classification. We present the eLasmobranc Dataset, a curated and publicly available image collection from seven ecologically relevant elasmobranch species inhabiting the eastern Spanish Mediterranean coast, a region where two ISRAs have been identified. Images were obtained through dedicated data collection, including field campaigns and collaborations with local fish markets and projects, as well as from open-access public sources. The dataset was constructed predominantly from images acquired outside the aquatic environment under standardized protocols to ensure clear visualization of diagnostic morphological traits. It integrates expert-validated species annotations, structured spatial and temporal metadata, and complementary species-level information. The eLasmobranc Dataset is specifically designed to support supervised species-level classification, population studies, and the development of artificial intelligence systems for biodiversity monitoring. By combining morphological clarity, taxonomic reliability, and public accessibility, the dataset addresses a critical gap in fine-grained elasmobranch identification and promotes reproducible research in conservation-oriented computer vision. The dataset is publicly available at https://zenodo.org/records/18549737.
Global Point Cloud Registration Network for Large Transformations
Mar 26, 2024Three-dimensional data registration is an established yet challenging problem that is key in many different applications, such as mapping the environment for autonomous vehicles, and modeling objects and people for avatar creation, among many others. Registration refers to the process of mapping multiple data into the same coordinate system by means of matching correspondences and transformation estimation. Novel proposals exploit the benefits of deep learning architectures for this purpose, as they learn the best features for the data, providing better matches and hence results. However, the state of the art is usually focused on cases of relatively small transformations, although in certain applications and in a real and practical environment, large transformations are very common. In this paper, we present ReLaTo (Registration for Large Transformations), an architecture that faces the cases where large transformations happen while maintaining good performance for local transformations. This proposal uses a novel Softmax pooling layer to find correspondences in a bilateral consensus manner between two point sets, sampling the most confident matches. These matches are used to estimate a coarse and global registration using weighted Singular Value Decomposition (SVD). A target-guided denoising step is then applied to both the obtained matches and latent features, estimating the final fine registration considering the local geometry. All these steps are carried out following an end-to-end approach, which has been shown to improve 10 state-of-the-art registration methods in two datasets commonly used for this task (ModelNet40 and KITTI), especially in the case of large transformations.
Few-shot learning for COVID-19 Chest X-Ray Classification with Imbalanced Data: An Inter vs. Intra Domain Study
Jan 18, 2024Medical image datasets are essential for training models used in computer-aided diagnosis, treatment planning, and medical research. However, some challenges are associated with these datasets, including variability in data distribution, data scarcity, and transfer learning issues when using models pre-trained from generic images. This work studies the effect of these challenges at the intra- and inter-domain level in few-shot learning scenarios with severe data imbalance. For this, we propose a methodology based on Siamese neural networks in which a series of techniques are integrated to mitigate the effects of data scarcity and distribution imbalance. Specifically, different initialization and data augmentation methods are analyzed, and four adaptations to Siamese networks of solutions to deal with imbalanced data are introduced, including data balancing and weighted loss, both separately and combined, and with a different balance of pairing ratios. Moreover, we also assess the inference process considering four classifiers, namely Histogram, $k$NN, SVM, and Random Forest. Evaluation is performed on three chest X-ray datasets with annotated cases of both positive and negative COVID-19 diagnoses. The accuracy of each technique proposed for the Siamese architecture is analyzed separately and their results are compared to those obtained using equivalent methods on a state-of-the-art CNN. We conclude that the introduced techniques offer promising improvements over the baseline in almost all cases, and that the selection of the technique may vary depending on the amount of data available and the level of imbalance.
RGB-D-based Framework to Acquire, Visualize and Measure the Human Body for Dietetic Treatments
Jul 02, 2020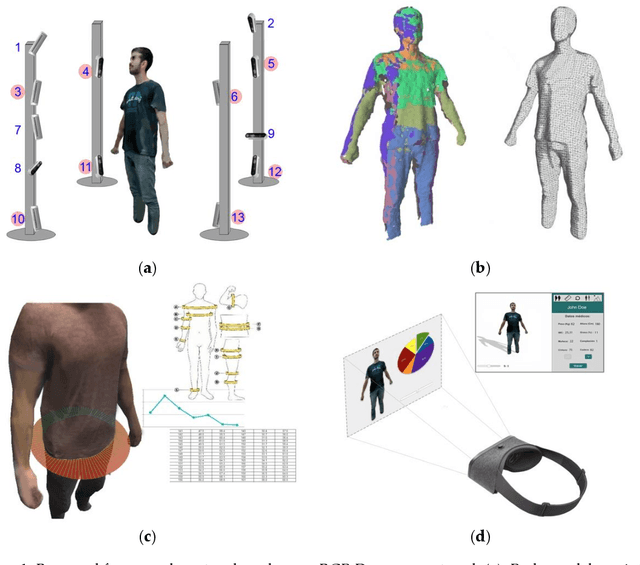

This research aims to improve dietetic-nutritional treatment using state-of-the-art RGB-D sensors and virtual reality (VR) technology. Recent studies show that adherence to treatment can be improved using multimedia technologies. However, there are few studies using 3D data and VR technologies for this purpose. On the other hand, obtaining 3D measurements of the human body and analyzing them over time (4D) in patients undergoing dietary treatment is a challenging field. The main contribution of the work is to provide a framework to study the effect of 4D body model visualization on adherence to obesity treatment. The system can obtain a complete 3D model of a body using low-cost technology, allowing future straightforward transference with sufficient accuracy and realistic visualization, enabling the analysis of the evolution (4D) of the shape during the treatment of obesity. The 3D body models will be used for studying the effect of visualization on adherence to obesity treatment using 2D and VR devices. Moreover, we will use the acquired 3D models to obtain measurements of the body. An analysis of the accuracy of the proposed methods for obtaining measurements with both synthetic and real objects has been carried out.
When Deep Learning Meets Data Alignment: A Review on Deep Registration Networks
Mar 06, 2020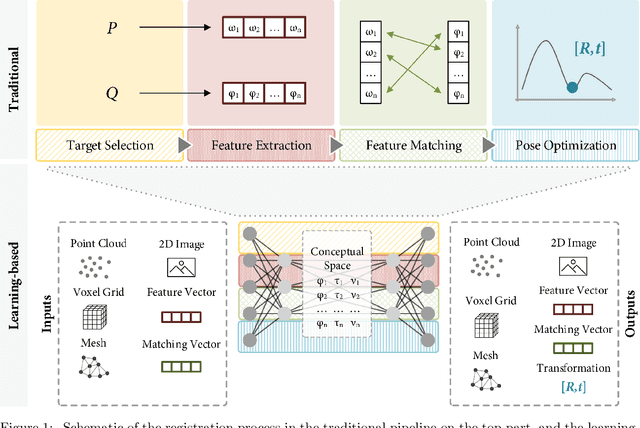
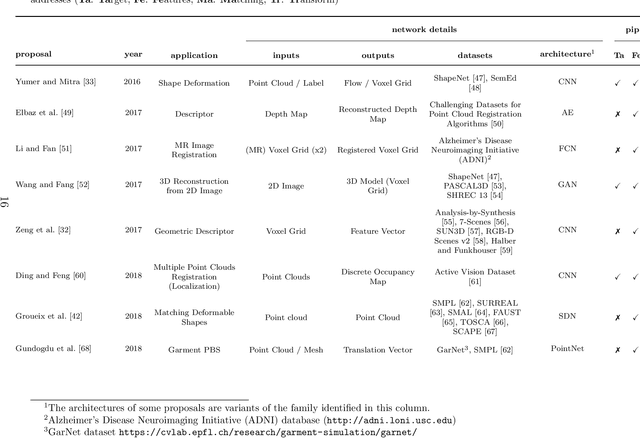
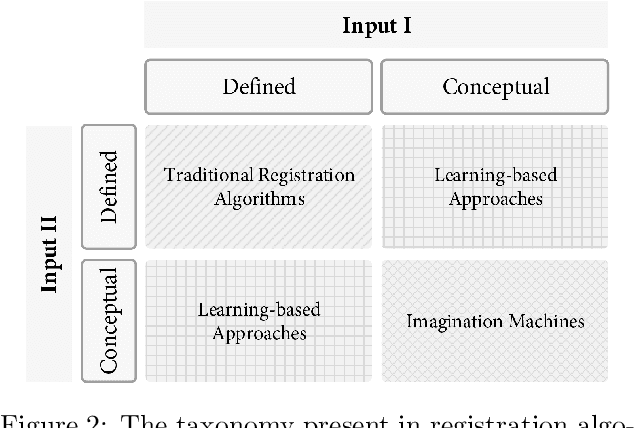
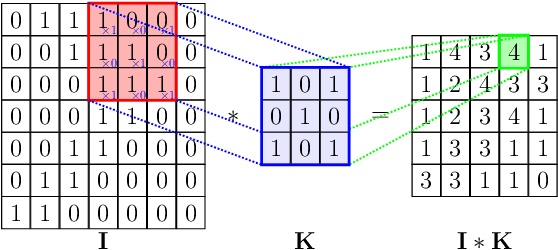
Registration is the process that computes the transformation that aligns sets of data. Commonly, a registration process can be divided into four main steps: target selection, feature extraction, feature matching, and transform computation for the alignment. The accuracy of the result depends on multiple factors, the most significant are the quantity of input data, the presence of noise, outliers and occlusions, the quality of the extracted features, real-time requirements and the type of transformation, especially those ones defined by multiple parameters, like non-rigid deformations. Recent advancements in machine learning could be a turning point in these issues, particularly with the development of deep learning (DL) techniques, which are helping to improve multiple computer vision problems through an abstract understanding of the input data. In this paper, a review of deep learning-based registration methods is presented. We classify the different papers proposing a framework extracted from the traditional registration pipeline to analyse the new learning-based proposal strengths. Deep Registration Networks (DRNs) try to solve the alignment task either replacing part of the traditional pipeline with a network or fully solving the registration problem. The main conclusions extracted are, on the one hand, 1) learning-based registration techniques cannot always be clearly classified in the traditional pipeline. 2) These approaches allow more complex inputs like conceptual models as well as the traditional 3D datasets. 3) In spite of the generality of learning, the current proposals are still ad hoc solutions. Finally, 4) this is a young topic that still requires a large effort to reach general solutions able to cope with the problems that affect traditional approaches.
Hybrid Multi-camera Visual Servoing to Moving Target
Aug 02, 2018
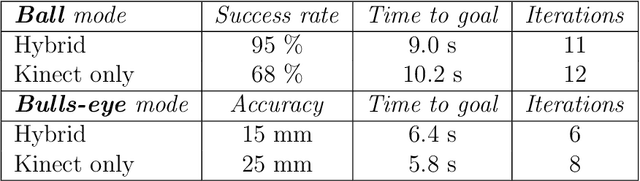
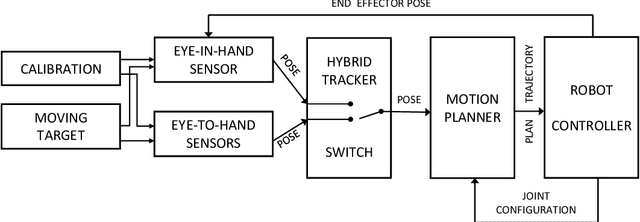
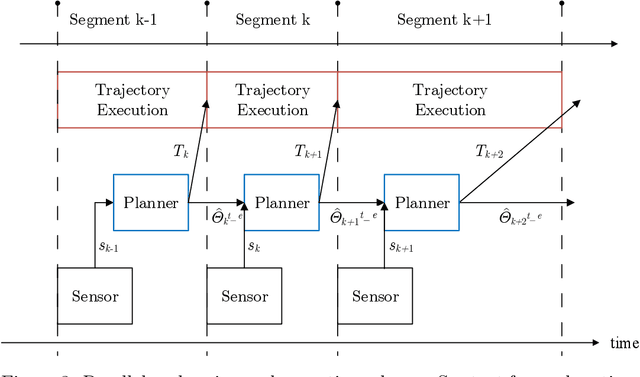
Visual servoing is a well-known task in robotics. However, there are still challenges when multiple visual sources are combined to accurately guide the robot or occlusions appear. In this paper we present a novel visual servoing approach using hybrid multi-camera input data to lead a robot arm accurately to dynamically moving target points in the presence of partial occlusions. The approach uses four RGBD sensors as Eye-to-Hand (EtoH) visual input, and an arm-mounted stereo camera as Eye-in-Hand (EinH). A Master supervisor task selects between using the EtoH or the EinH, depending on the distance between the robot and target. The Master also selects the subset of EtoH cameras that best perceive the target. When the EinH sensor is used, if the target becomes occluded or goes out of the sensor's view-frustum, the Master switches back to the EtoH sensors to re-track the object. Using this adaptive visual input data, the robot is then controlled using an iterative planner that uses position, orientation and joint configuration to estimate the trajectory. Since the target is dynamic, this trajectory is updated every time-step. Experiments show good performance in four different situations: tracking a ball, targeting a bulls-eye, guiding a straw to a mouth and delivering an item to a moving hand. The experiments cover both simple situations such as a ball that is mostly visible from all cameras, and more complex situations such as the mouth which is partially occluded from some of the sensors.
3D non-rigid registration using color: Color Coherent Point Drift
Feb 05, 2018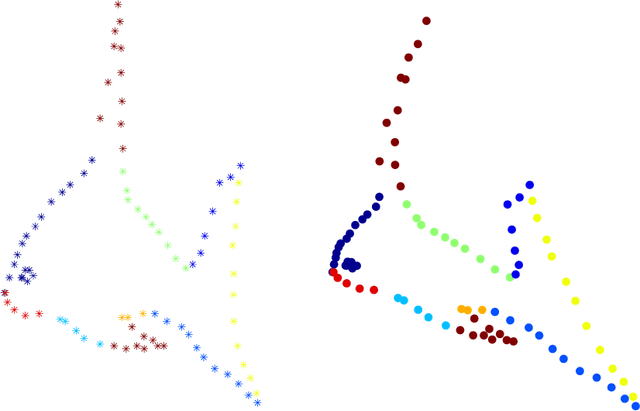
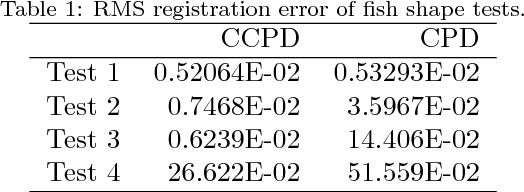

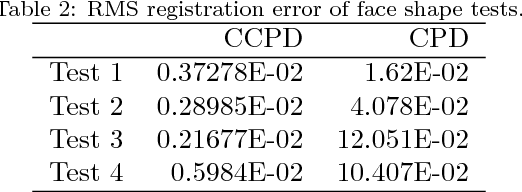
Research into object deformations using computer vision techniques has been under intense study in recent years. A widely used technique is 3D non-rigid registration to estimate the transformation between two instances of a deforming structure. Despite many previous developments on this topic, it remains a challenging problem. In this paper we propose a novel approach to non-rigid registration combining two data spaces in order to robustly calculate the correspondences and transformation between two data sets. In particular, we use point color as well as 3D location as these are the common outputs of RGB-D cameras. We have propose the Color Coherent Point Drift (CCPD) algorithm (an extension of the CPD method [1]). Evaluation is performed using synthetic and real data. The synthetic data includes easy shapes that allow evaluation of the effect of noise, outliers and missing data. Moreover, an evaluation of realistic figures obtained using Blensor is carried out. Real data acquired using a general purpose Primesense Carmine sensor is used to validate the CCPD for real shapes. For all tests, the proposed method is compared to the original CPD showing better results in registration accuracy in most cases.
Best Viewpoint Tracking for Camera Mounted on Robotic Arm with Dynamic Obstacles
Oct 17, 2017
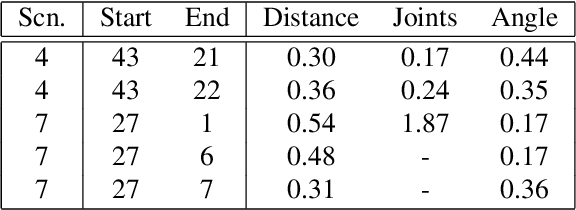
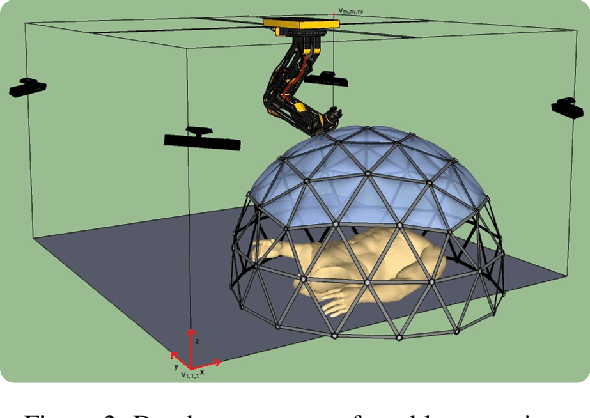
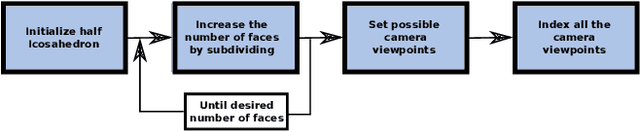
The problem of finding a next best viewpoint for 3D modeling or scene mapping has been explored in computer vision over the last decade. This paper tackles a similar problem, but with different characteristics. It proposes a method for dynamic next best viewpoint recovery of a target point while avoiding possible occlusions. Since the environment can change, the method has to iteratively find the next best view with a global understanding of the free and occupied parts. We model the problem as a set of possible viewpoints which correspond to the centers of the facets of a virtual tessellated hemisphere covering the scene. Taking into account occlusions, distances between current and future viewpoints, quality of the viewpoint and joint constraints (robot arm joint distances or limits), we evaluate the next best viewpoint. The proposal has been evaluated on 8 different scenarios with different occlusions and a short 3D video sequence to validate its dynamic performance.
μ-MAR: Multiplane 3D Marker based Registration for Depth-sensing Cameras
Aug 04, 2017

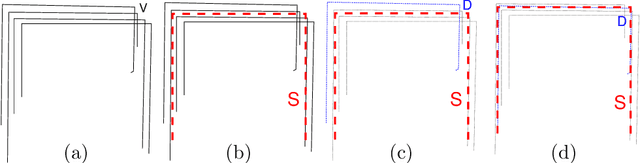

Many applications including object reconstruction, robot guidance, and scene mapping require the registration of multiple views from a scene to generate a complete geometric and appearance model of it. In real situations, transformations between views are unknown an it is necessary to apply expert inference to estimate them. In the last few years, the emergence of low-cost depth-sensing cameras has strengthened the research on this topic, motivating a plethora of new applications. Although they have enough resolution and accuracy for many applications, some situations may not be solved with general state-of-the-art registration methods due to the Signal-to-Noise ratio (SNR) and the resolution of the data provided. The problem of working with low SNR data, in general terms, may appear in any 3D system, then it is necessary to propose novel solutions in this aspect. In this paper, we propose a method, {\mu}-MAR, able to both coarse and fine register sets of 3D points provided by low-cost depth-sensing cameras, despite it is not restricted to these sensors, into a common coordinate system. The method is able to overcome the noisy data problem by means of using a model-based solution of multiplane registration. Specifically, it iteratively registers 3D markers composed by multiple planes extracted from points of multiple views of the scene. As the markers and the object of interest are static in the scenario, the transformations obtained for the markers are applied to the object in order to reconstruct it. Experiments have been performed using synthetic and real data. The synthetic data allows a qualitative and quantitative evaluation by means of visual inspection and Hausdorff distance respectively. The real data experiments show the performance of the proposal using data acquired by a Primesense Carmine RGB-D sensor. The method has been compared to several state-of-the-art methods. The ...
Three-dimensional planar model estimation using multi-constraint knowledge based on k-means and RANSAC
Aug 03, 2017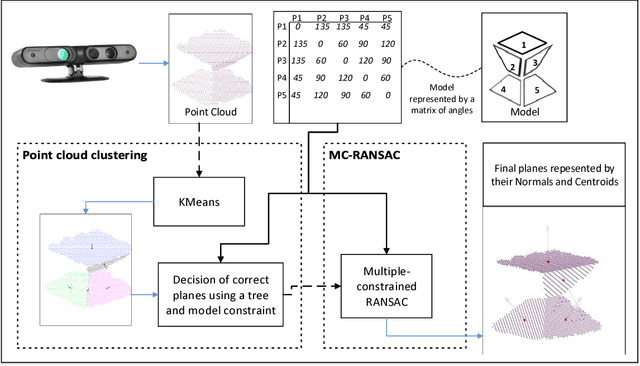


Plane model extraction from three-dimensional point clouds is a necessary step in many different applications such as planar object reconstruction, indoor mapping and indoor localization. Different RANdom SAmple Consensus (RANSAC)-based methods have been proposed for this purpose in recent years. In this study, we propose a novel method-based on RANSAC called Multiplane Model Estimation, which can estimate multiple plane models simultaneously from a noisy point cloud using the knowledge extracted from a scene (or an object) in order to reconstruct it accurately. This method comprises two steps: first, it clusters the data into planar faces that preserve some constraints defined by knowledge related to the object (e.g., the angles between faces); and second, the models of the planes are estimated based on these data using a novel multi-constraint RANSAC. We performed experiments in the clustering and RANSAC stages, which showed that the proposed method performed better than state-of-the-art methods.