 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrower-in-the-Loop Interactive Reinforcement Learning for Greenhouse Climate Control
May 29, 2025Climate control is crucial for greenhouse production as it directly affects crop growth and resource use. Reinforcement learning (RL) has received increasing attention in this field, but still faces challenges, including limited training efficiency and high reliance on initial learning conditions. Interactive RL, which combines human (grower) input with the RL agent's learning, offers a potential solution to overcome these challenges. However, interactive RL has not yet been applied to greenhouse climate control and may face challenges related to imperfect inputs. Therefore, this paper aims to explore the possibility and performance of applying interactive RL with imperfect inputs into greenhouse climate control, by: (1) developing three representative interactive RL algorithms tailored for greenhouse climate control (reward shaping, policy shaping and control sharing); (2) analyzing how input characteristics are often contradicting, and how the trade-offs between them make grower's inputs difficult to perfect; (3) proposing a neural network-based approach to enhance the robustness of interactive RL agents under limited input availability; (4) conducting a comprehensive evaluation of the three interactive RL algorithms with imperfect inputs in a simulated greenhouse environment. The demonstration shows that interactive RL incorporating imperfect grower inputs has the potential to improve the performance of the RL agent. RL algorithms that influence action selection, such as policy shaping and control sharing, perform better when dealing with imperfect inputs, achieving 8.4% and 6.8% improvement in profit, respectively. In contrast, reward shaping, an algorithm that manipulates the reward function, is sensitive to imperfect inputs and leads to a 9.4% decrease in profit. This highlights the importance of selecting an appropriate mechanism when incorporating imperfect inputs.
Adaptive path planning for efficient object search by UAVs in agricultural fields
Apr 03, 2025



This paper presents an adaptive path planner for object search in agricultural fields using UAVs. The path planner uses a high-altitude coverage flight path and plans additional low-altitude inspections when the detection network is uncertain. The path planner was evaluated in an offline simulation environment containing real-world images. We trained a YOLOv8 detection network to detect artificial plants placed in grass fields to showcase the potential of our path planner. We evaluated the effect of different detection certainty measures, optimized the path planning parameters, investigated the effects of localization errors and different numbers of objects in the field. The YOLOv8 detection confidence worked best to differentiate between true and false positive detections and was therefore used in the adaptive planner. The optimal parameters of the path planner depended on the distribution of objects in the field, when the objects were uniformly distributed, more low-altitude inspections were needed compared to a non-uniform distribution of objects, resulting in a longer path length. The adaptive planner proved to be robust against localization uncertainty. When increasing the number of objects, the flight path length increased, especially when the objects were uniformly distributed. When the objects were non-uniformly distributed, the adaptive path planner yielded a shorter path than a low-altitude coverage path, even with high number of objects. Overall, the presented adaptive path planner allowed to find non-uniformly distributed objects in a field faster than a coverage path planner and resulted in a compatible detection accuracy. The path planner is made available at https://github.com/wur-abe/uav_adaptive_planner.
Learning UAV-based path planning for efficient localization of objects using prior knowledge
Dec 16, 2024



UAV's are becoming popular for various object search applications in agriculture, however they usually use time-consuming row-by-row flight paths. This paper presents a deep-reinforcement-learning method for path planning to efficiently localize objects of interest using UAVs with a minimal flight-path length. The method uses some global prior knowledge with uncertain object locations and limited resolution in combination with a local object map created using the output of an object detection network. The search policy could be learned using deep Q-learning. We trained the agent in simulation, allowing thorough evaluation of the object distribution, typical errors in the perception system and prior knowledge, and different stopping criteria. When objects were non-uniformly distributed over the field, the agent found the objects quicker than a row-by-row flight path, showing that it learns to exploit the distribution of objects. Detection errors and quality of prior knowledge had only minor effect on the performance, indicating that the learned search policy was robust to errors in the perception system and did not need detailed prior knowledge. Without prior knowledge, the learned policy was still comparable in performance to a row-by-row flight path. Finally, we demonstrated that it is possible to learn the appropriate moment to end the search task. The applicability of the approach for object search on a real drone was comprehensively discussed and evaluated. Overall, we conclude that the learned search policy increased the efficiency of finding objects using a UAV, and can be applied in real-world conditions when the specified assumptions are met.
TrimBot2020: an outdoor robot for automatic gardening
May 15, 2018

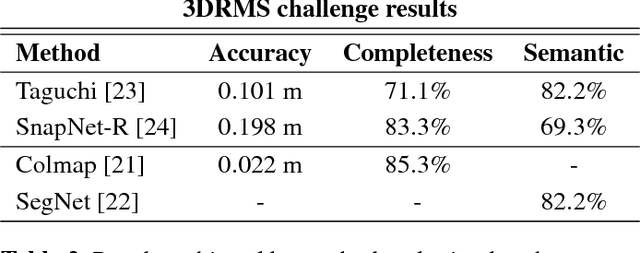
Robots are increasingly present in modern industry and also in everyday life. Their applications range from health-related situations, for assistance to elderly people or in surgical operations, to automatic and driver-less vehicles (on wheels or flying) or for driving assistance. Recently, an interest towards robotics applied in agriculture and gardening has arisen, with applications to automatic seeding and cropping or to plant disease control, etc. Autonomous lawn mowers are succesful market applications of gardening robotics. In this paper, we present a novel robot that is developed within the TrimBot2020 project, funded by the EU H2020 program. The project aims at prototyping the first outdoor robot for automatic bush trimming and rose pruning.