 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-assisted Learning for Electronic Engineering Courses in High Education
Nov 02, 2023This study evaluates the efficacy of ChatGPT as an AI teaching and learning support tool in an integrated circuit systems course at a higher education institution in an Asian country. Various question types were completed, and ChatGPT responses were assessed to gain valuable insights for further investigation. The objective is to assess ChatGPT's ability to provide insights, personalized support, and interactive learning experiences in engineering education. The study includes the evaluation and reflection of different stakeholders: students, lecturers, and engineers. The findings of this study shed light on the benefits and limitations of ChatGPT as an AI tool, paving the way for innovative learning approaches in technical disciplines. Furthermore, the study contributes to our understanding of how digital transformation is likely to unfold in the education sector.
Multi-dimensional data refining strategy for effective fine-tuning LLMs
Nov 02, 2023Data is a cornerstone for fine-tuning large language models, yet acquiring suitable data remains challenging. Challenges encompassed data scarcity, linguistic diversity, and domain-specific content. This paper presents lessons learned while crawling and refining data tailored for fine-tuning Vietnamese language models. Crafting such a dataset, while accounting for linguistic intricacies and striking a balance between inclusivity and accuracy, demands meticulous planning. Our paper presents a multidimensional strategy including leveraging existing datasets in the English language and developing customized data-crawling scripts with the assistance of generative AI tools. A fine-tuned LLM model for the Vietnamese language, which was produced using resultant datasets, demonstrated good performance while generating Vietnamese news articles from prompts. The study offers practical solutions and guidance for future fine-tuning models in languages like Vietnamese.
Measuring Sample Efficiency and Generalization in Reinforcement Learning Benchmarks: NeurIPS 2020 Procgen Benchmark
Mar 29, 2021
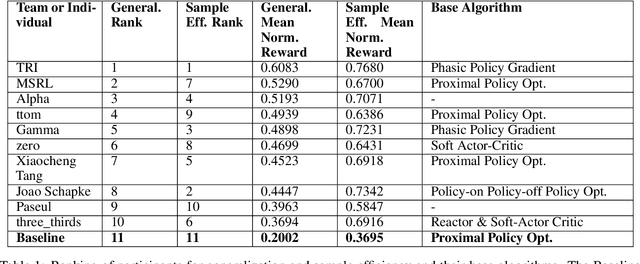
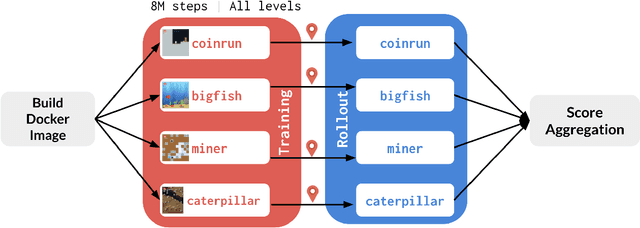
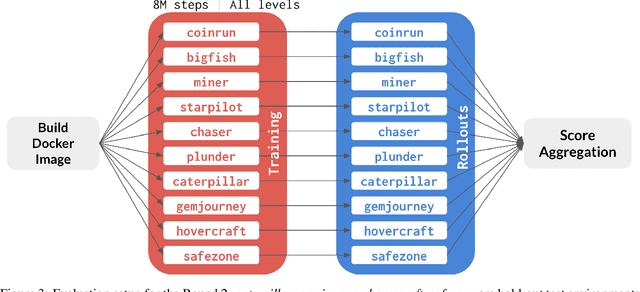
The NeurIPS 2020 Procgen Competition was designed as a centralized benchmark with clearly defined tasks for measuring Sample Efficiency and Generalization in Reinforcement Learning. Generalization remains one of the most fundamental challenges in deep reinforcement learning, and yet we do not have enough benchmarks to measure the progress of the community on Generalization in Reinforcement Learning. We present the design of a centralized benchmark for Reinforcement Learning which can help measure Sample Efficiency and Generalization in Reinforcement Learning by doing end to end evaluation of the training and rollout phases of thousands of user submitted code bases in a scalable way. We designed the benchmark on top of the already existing Procgen Benchmark by defining clear tasks and standardizing the end to end evaluation setups. The design aims to maximize the flexibility available for researchers who wish to design future iterations of such benchmarks, and yet imposes necessary practical constraints to allow for a system like this to scale. This paper presents the competition setup and the details and analysis of the top solutions identified through this setup in context of 2020 iteration of the competition at NeurIPS.