 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmplitude Prediction from Uplink to Downlink CSI against Receiver Distortion in FDD Systems
Aug 31, 2023



In frequency division duplex (FDD) massive multiple-input multiple-output (mMIMO) systems, the reciprocity mismatch caused by receiver distortion seriously degrades the amplitude prediction performance of channel state information (CSI). To tackle this issue, from the perspective of distortion suppression and reciprocity calibration, a lightweight neural network-based amplitude prediction method is proposed in this paper. Specifically, with the receiver distortion at the base station (BS), conventional methods are employed to extract the amplitude feature of uplink CSI. Then, learning along the direction of the uplink wireless propagation channel, a dedicated and lightweight distortion-learning network (Dist-LeaNet) is designed to restrain the receiver distortion and calibrate the amplitude reciprocity between the uplink and downlink CSI. Subsequently, by cascading, a single hidden layer-based amplitude-prediction network (Amp-PreNet) is developed to accomplish amplitude prediction of downlink CSI based on the strong amplitude reciprocity. Simulation results show that, considering the receiver distortion in FDD systems, the proposed scheme effectively improves the amplitude prediction accuracy of downlink CSI while reducing the transmission and processing delay.
Communication-efficient Federated Learning with Single-Step Synthetic Features Compressor for Faster Convergence
Mar 19, 2023



Reducing communication overhead in federated learning (FL) is challenging but crucial for large-scale distributed privacy-preserving machine learning. While methods utilizing sparsification or others can largely lower the communication overhead, the convergence rate is also greatly compromised. In this paper, we propose a novel method, named single-step synthetic features compressor (3SFC), to achieve communication-efficient FL by directly constructing a tiny synthetic dataset based on raw gradients. Thus, 3SFC can achieve an extremely low compression rate when the constructed dataset contains only one data sample. Moreover, 3SFC's compressing phase utilizes a similarity-based objective function so that it can be optimized with just one step, thereby considerably improving its performance and robustness. In addition, to minimize the compressing error, error feedback (EF) is also incorporated into 3SFC. Experiments on multiple datasets and models suggest that 3SFC owns significantly better convergence rates compared to competing methods with lower compression rates (up to 0.02%). Furthermore, ablation studies and visualizations show that 3SFC can carry more information than competing methods for every communication round, further validating its effectiveness.
LoS sensing-based superimposed CSI feedback for UAV-Assisted mmWave systems
Feb 21, 2023



In unmanned aerial vehicle (UAV)-assisted millimeter wave (mmWave) systems, channel state information (CSI) feedback is critical for the selection of modulation schemes, resource management, beamforming, etc. However, traditional CSI feedback methods lead to significant feedback overhead and energy consumption of the UAV transmitter, therefore shortening the system operation time. To tackle these issues, inspired by superimposed feedback and integrated sensing and communications (ISAC), a line of sight (LoS) sensing-based superimposed CSI feedback scheme is proposed. Specifically, on the UAV transmitter side, the ground-to-UAV (G2U) CSI is superimposed on the UAVto-ground (U2G) data to feed back to the ground base station (gBS). At the gBS, the dedicated LoS sensing network (LoSSenNet) is designed to sense the U2G CSI in LoS and NLoS scenarios. With the sensed result of LoS-SenNet, the determined G2U CSI from the initial feature extraction will work as the priori information to guide the subsequent operation. Specifically, for the G2U CSI in NLoS, a CSI recovery network (CSI-RecNet) and superimposed interference cancellation are developed to recover the G2U CSI and U2G data. As for the LoS scenario, a dedicated LoS aid network (LoS-AidNet) is embedded before the CSI-RecNet and the block of superimposed interference cancellation to highlight the feature of the G2U CSI. Compared with other methods of superimposed CSI feedback, simulation results demonstrate that the proposed feedback scheme effectively improves the recovery accuracy of the G2U CSI and U2G data. Besides, against parameter variations, the proposed feedback scheme presents its robustness.
Personalized Federated Learning with Hidden Information on Personalized Prior
Nov 24, 2022Federated learning (FL for simplification) is a distributed machine learning technique that utilizes global servers and collaborative clients to achieve privacy-preserving global model training without direct data sharing. However, heterogeneous data problem, as one of FL's main problems, makes it difficult for the global model to perform effectively on each client's local data. Thus, personalized federated learning (PFL for simplification) aims to improve the performance of the model on local data as much as possible. Bayesian learning, where the parameters of the model are seen as random variables with a prior assumption, is a feasible solution to the heterogeneous data problem due to the tendency that the more local data the model use, the more it focuses on the local data, otherwise focuses on the prior. When Bayesian learning is applied to PFL, the global model provides global knowledge as a prior to the local training process. In this paper, we employ Bayesian learning to model PFL by assuming a prior in the scaled exponential family, and therefore propose pFedBreD, a framework to solve the problem we model using Bregman divergence regularization. Empirically, our experiments show that, under the prior assumption of the spherical Gaussian and the first order strategy of mean selection, our proposal significantly outcompetes other PFL algorithms on multiple public benchmarks.
DeFTA: A Plug-and-Play Decentralized Replacement for FedAvg
Apr 06, 2022
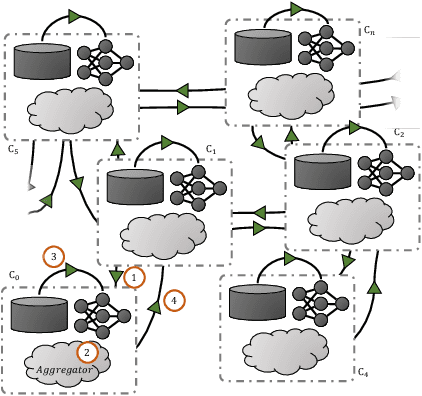
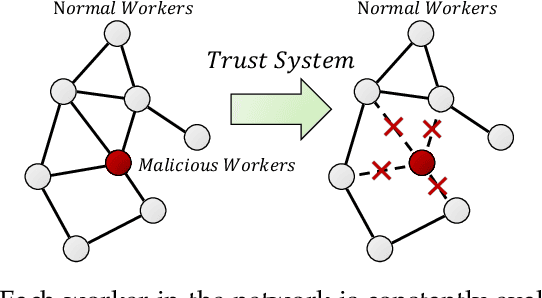
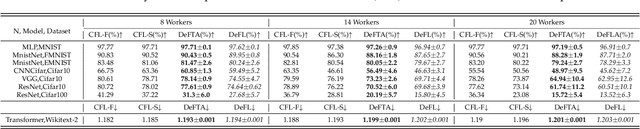
Federated learning (FL) is identified as a crucial enabler for large-scale distributed machine learning (ML) without the need for local raw dataset sharing, substantially reducing privacy concerns and alleviating the isolated data problem. In reality, the prosperity of FL is largely due to a centralized framework called FedAvg, in which workers are in charge of model training and servers are in control of model aggregation. However, FedAvg's centralized worker-server architecture has raised new concerns, be it the low scalability of the cluster, the risk of data leakage, and the failure or even defection of the central server. To overcome these problems, we propose Decentralized Federated Trusted Averaging (DeFTA), a decentralized FL framework that serves as a plug-and-play replacement for FedAvg, instantly bringing better security, scalability, and fault-tolerance to the federated learning process after installation. In principle, it fundamentally resolves the above-mentioned issues from an architectural perspective without compromises or tradeoffs, primarily consisting of a new model aggregating formula with theoretical performance analysis, and a decentralized trust system (DTS) to greatly improve system robustness. Note that since DeFTA is an alternative to FedAvg at the framework level, \textit{prevalent algorithms published for FedAvg can be also utilized in DeFTA with ease}. Extensive experiments on six datasets and six basic models suggest that DeFTA not only has comparable performance with FedAvg in a more realistic setting, but also achieves great resilience even when 66% of workers are malicious. Furthermore, we also present an asynchronous variant of DeFTA to endow it with more powerful usability.
Deep Learning for 1-Bit Compressed Sensing-based Superimposed CSI Feedback
Mar 13, 2022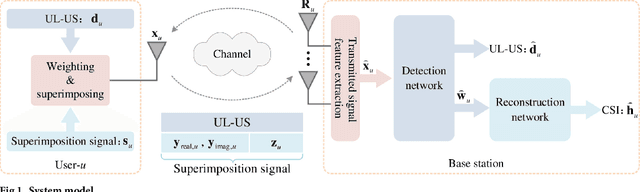

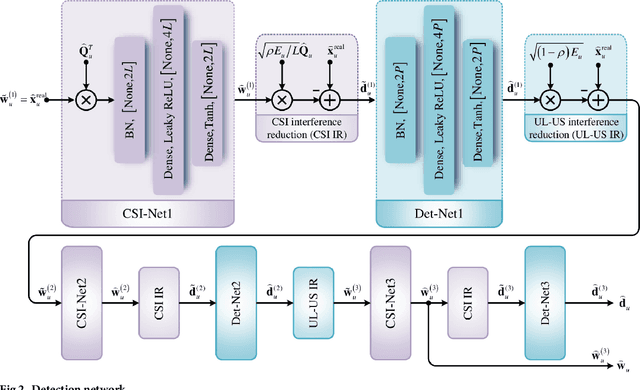

In frequency-division duplexing (FDD) massive multiple-input multiple-output (MIMO) systems, 1-bit compressed sensing (CS)-based superimposed channel state information (CSI) feedback has shown many advantages, while still faces many challenges, such as low accuracy of the downlink CSI recovery and large processing delays. To overcome these drawbacks, this paper proposes a deep learning (DL) scheme to improve the 1-bit compressed sensing-based superimposed CSI feedback. On the user side, the downlink CSI is compressed with the 1-bit CS technique, superimposed on the uplink user data sequences (UL-US), and then sent back to the base station (BS). At the BS, based on the model-driven approach and assisted by the superimposition-interference cancellation technology, a multi-task detection network is first constructed for detecting both the UL-US and downlink CSI. In particular, this detection network is jointly trained to detect the UL-US and downlink CSI simultaneously, capturing a globally optimized network parameter. Then, with the recovered bits for the downlink CSI, a lightweight reconstruction scheme, which consists of an initial feature extraction of the downlink CSI with the simplified traditional method and a single hidden layer network, is utilized to reconstruct the downlink CSI with low processing delay. Compared with the 1-bit CS-based superimposed CSI feedback scheme, the proposed scheme improves the recovery accuracy of the UL-US and downlink CSI with lower processing delay and possesses robustness against parameter variations.
Fusion Learning for 1-Bit CS-based Superimposed CSI Feedback with Bi-Directional Channel Reciprocity
Jan 20, 2022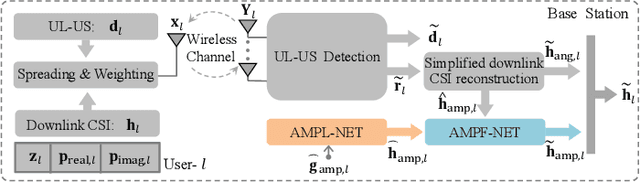
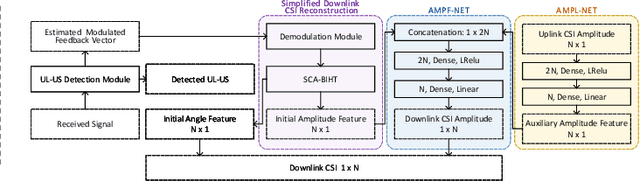
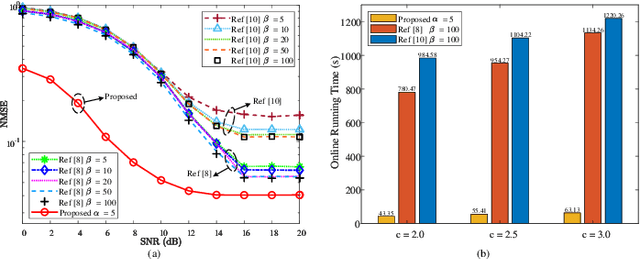
Due to the discarding of downlink channel state information (CSI) amplitude and the employing of iteration reconstruction algorithms, 1-bit compressed sensing (CS)-based superimposed CSI feedback is challenged by low recovery accuracy and large processing delay. To overcome these drawbacks, this letter proposes a fusion learning scheme by exploiting the bi-directional channel reciprocity. Specifically, a simplified version of the conventional downlink CSI reconstruction is utilized to extract the initial feature of downlink CSI, and a single hidden layer-based amplitude-learning network (AMPL-NET) is designed to learn the auxiliary feature of the downlink CSI amplitude. Then, based on the extracted and learned amplitude features, a simple but effective amplitude-fusion network (AMPF-NET) is developed to perform the amplitude fusion of downlink CSI and thus improves the reconstruction accuracy for 1-bit CS-based superimposed CSI feedback while reducing the processing delay. Simulation results show the effectiveness of the proposed feedback scheme and the robustness against parameter variations.
Label Design-based ELM Network for Timing Synchronization in OFDM Systems with Nonlinear Distortion
Jul 28, 2021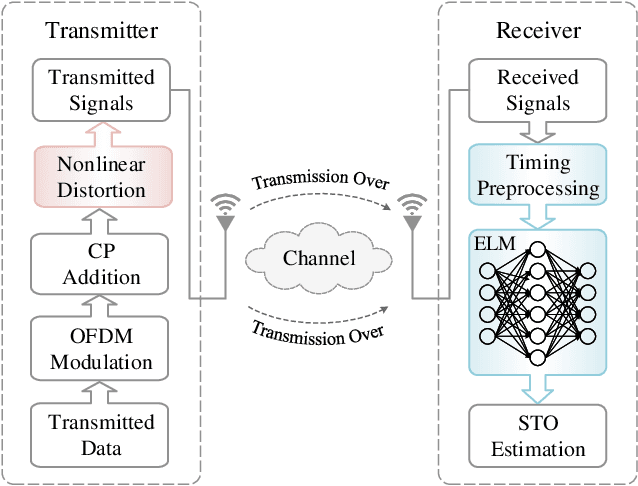
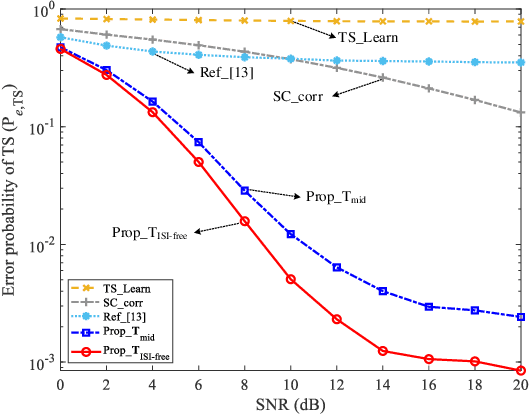
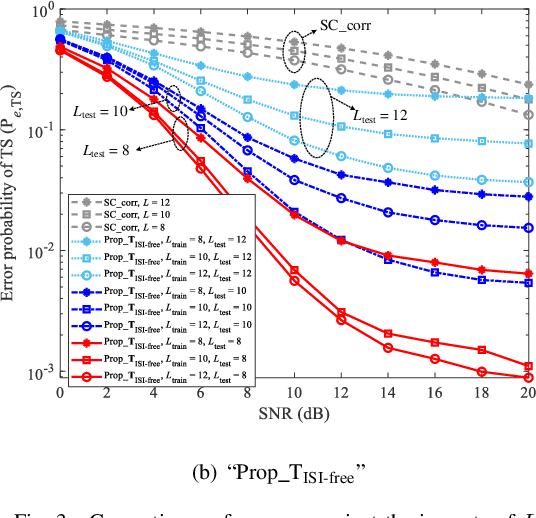
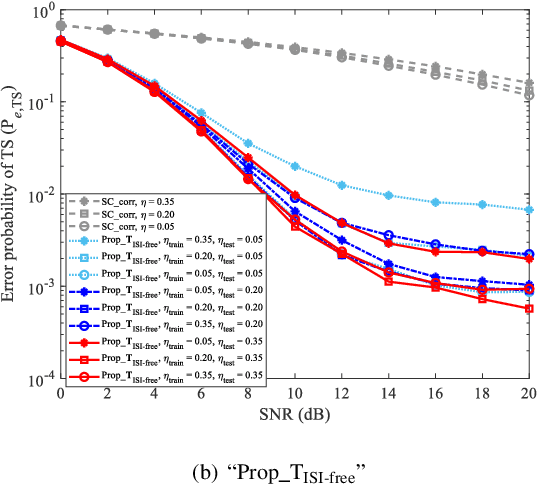
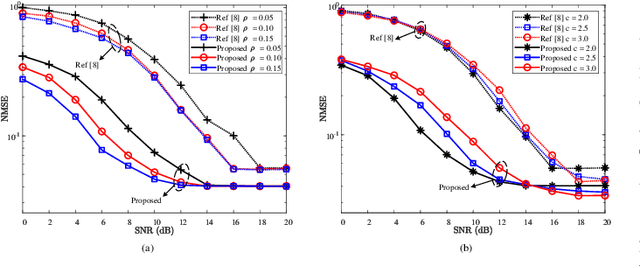
Due to the nonlinear distortion in Orthogonal frequency division multiplexing (OFDM) systems, the timing synchronization (TS) performance is inevitably degraded at the receiver. To relieve this issue, an extreme learning machine (ELM)-based network with a novel learning label is proposed to the TS of OFDM system in our work and increases the possibility of symbol timing offset (STO) estimation residing in inter-symbol interference (ISI)-free region. Especially, by exploiting the prior information of the ISI-free region, two types of learning labels are developed to facilitate the ELM-based TS network. With designed learning labels, a timing-processing by classic TS scheme is first executed to capture the coarse timing metric (TM) and then followed by an ELM network to refine the TM. According to experiments and analysis, our scheme shows its effectiveness in the improvement of TS performance and reveals its generalization performance in different training and testing channel scenarios.
MRC-LSTM: A Hybrid Approach of Multi-scale Residual CNN and LSTM to Predict Bitcoin Price
May 03, 2021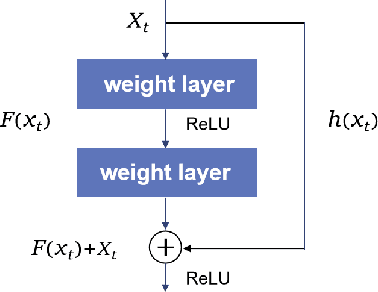
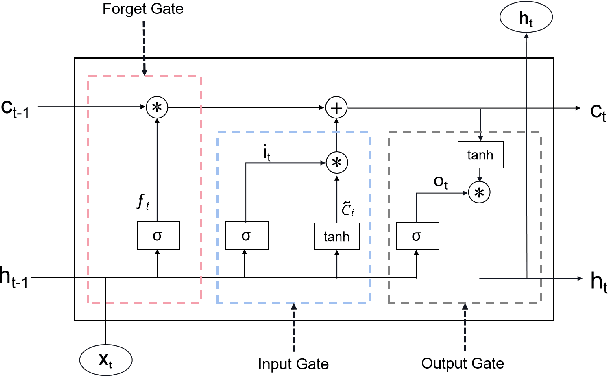
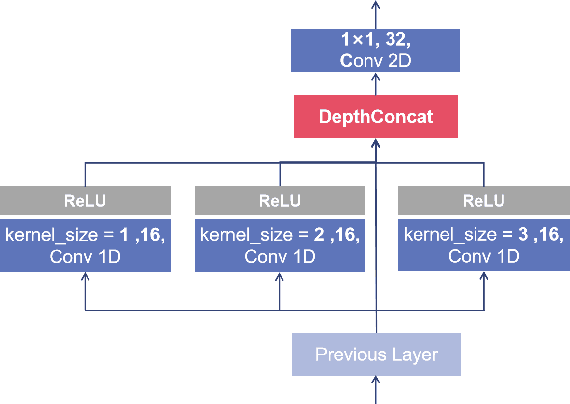
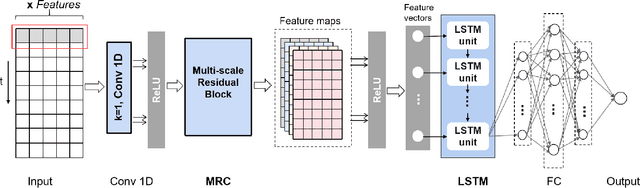
Bitcoin, one of the major cryptocurrencies, presents great opportunities and challenges with its tremendous potential returns accompanying high risks. The high volatility of Bitcoin and the complex factors affecting them make the study of effective price forecasting methods of great practical importance to financial investors and researchers worldwide. In this paper, we propose a novel approach called MRC-LSTM, which combines a Multi-scale Residual Convolutional neural network (MRC) and a Long Short-Term Memory (LSTM) to implement Bitcoin closing price prediction. Specifically, the Multi-scale residual module is based on one-dimensional convolution, which is not only capable of adaptive detecting features of different time scales in multivariate time series, but also enables the fusion of these features. LSTM has the ability to learn long-term dependencies in series, which is widely used in financial time series forecasting. By mixing these two methods, the model is able to obtain highly expressive features and efficiently learn trends and interactions of multivariate time series. In the study, the impact of external factors such as macroeconomic variables and investor attention on the Bitcoin price is considered in addition to the trading information of the Bitcoin market. We performed experiments to predict the daily closing price of Bitcoin (USD), and the experimental results show that MRC-LSTM significantly outperforms a variety of other network structures. Furthermore, we conduct additional experiments on two other cryptocurrencies, Ethereum and Litecoin, to further confirm the effectiveness of the MRC-LSTM in short-term forecasting for multivariate time series of cryptocurrencies.
Heart-Darts: Classification of Heartbeats Using Differentiable Architecture Search
May 03, 2021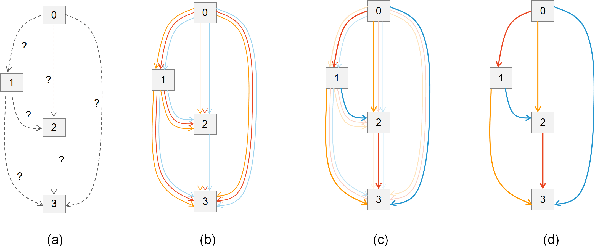
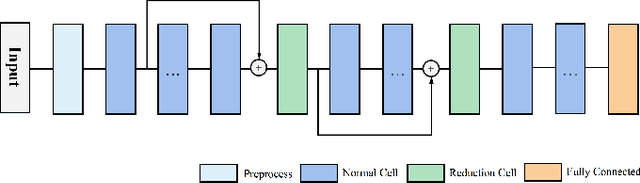
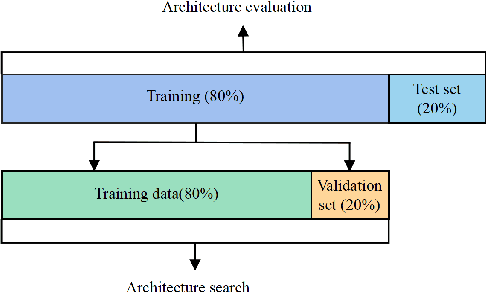
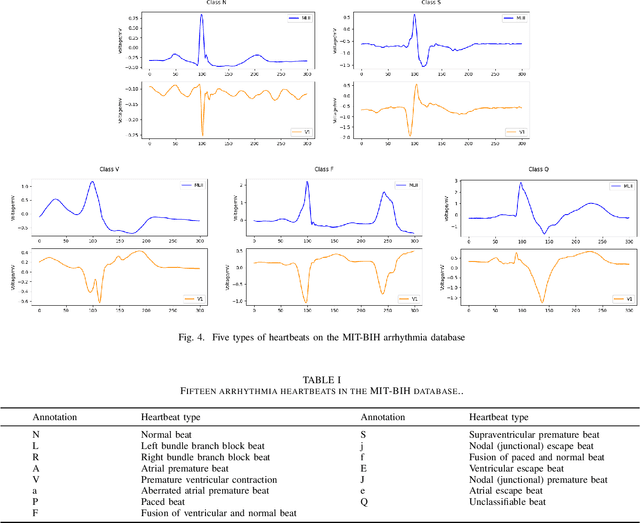
Arrhythmia is a cardiovascular disease that manifests irregular heartbeats. In arrhythmia detection, the electrocardiogram (ECG) signal is an important diagnostic technique. However, manually evaluating ECG signals is a complicated and time-consuming task. With the application of convolutional neural networks (CNNs), the evaluation process has been accelerated and the performance is improved. It is noteworthy that the performance of CNNs heavily depends on their architecture design, which is a complex process grounded on expert experience and trial-and-error. In this paper, we propose a novel approach, Heart-Darts, to efficiently classify the ECG signals by automatically designing the CNN model with the differentiable architecture search (i.e., Darts, a cell-based neural architecture search method). Specifically, we initially search a cell architecture by Darts and then customize a novel CNN model for ECG classification based on the obtained cells. To investigate the efficiency of the proposed method, we evaluate the constructed model on the MIT-BIH arrhythmia database. Additionally, the extensibility of the proposed CNN model is validated on two other new databases. Extensive experimental results demonstrate that the proposed method outperforms several state-of-the-art CNN models in ECG classification in terms of both performance and generalization capability.