 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Multi-Scale Attention Framework for Real-Time Spinal Endoscopic Instance Segmentation
Dec 26, 2025Real-time instance segmentation for spinal endoscopy is important for identifying and protecting critical anatomy during surgery, but it is difficult because of the narrow field of view, specular highlights, smoke/bleeding, unclear boundaries, and large scale changes. Deployment is also constrained by limited surgical hardware, so the model must balance accuracy and speed and remain stable under small-batch (even batch-1) training. We propose LMSF-A, a lightweight multi-scale attention framework co-designed across backbone, neck, and head. The backbone uses a C2f-Pro module that combines RepViT-style re-parameterized convolution (RVB) with efficient multi-scale attention (EMA), enabling multi-branch training while collapsing into a single fast path for inference. The neck improves cross-scale consistency and boundary detail using Scale-Sequence Feature Fusion (SSFF) and Triple Feature Encoding (TFE), which strengthens high-resolution features. The head adopts a Lightweight Multi-task Shared Head (LMSH) with shared convolutions and GroupNorm to reduce parameters and support batch-1 stability. We also release the clinically reviewed PELD dataset (61 patients, 610 images) with instance masks for adipose tissue, bone, ligamentum flavum, and nerve. Experiments show that LMSF-A is highly competitive (or even better than) in all evaluation metrics and much lighter than most instance segmentation methods requiring only 1.8M parameters and 8.8 GFLOPs, and it generalizes well to a public teeth benchmark. Code and dataset: https://github.com/hhwmortal/PELD-Instance-segmentation.
Modified EDAS Method Based on Cumulative Prospect Theory for Multiple Attributes Group Decision Making with Interval-valued Intuitionistic Fuzzy Information
Nov 05, 2022



The Interval-valued intuitionistic fuzzy sets (IVIFSs) based on the intuitionistic fuzzy sets combines the classical decision method is in its research and application is attracting attention. After comparative analysis, there are multiple classical methods with IVIFSs information have been applied into many practical issues. In this paper, we extended the classical EDAS method based on cumulative prospect theory (CPT) considering the decision makers (DMs) psychological factor under IVIFSs. Taking the fuzzy and uncertain character of the IVIFSs and the psychological preference into consideration, the original EDAS method based on the CPT under IVIFSs (IVIF-CPT-MABAC) method is built for MAGDM issues. Meanwhile, information entropy method is used to evaluate the attribute weight. Finally, a numerical example for project selection of green technology venture capital has been given and some comparisons is used to illustrate advantages of IVIF-CPT-MABAC method and some comparison analysis and sensitivity analysis are applied to prove this new methods effectiveness and stability.
Hierarchical and Progressive Image Matting
Oct 13, 2022
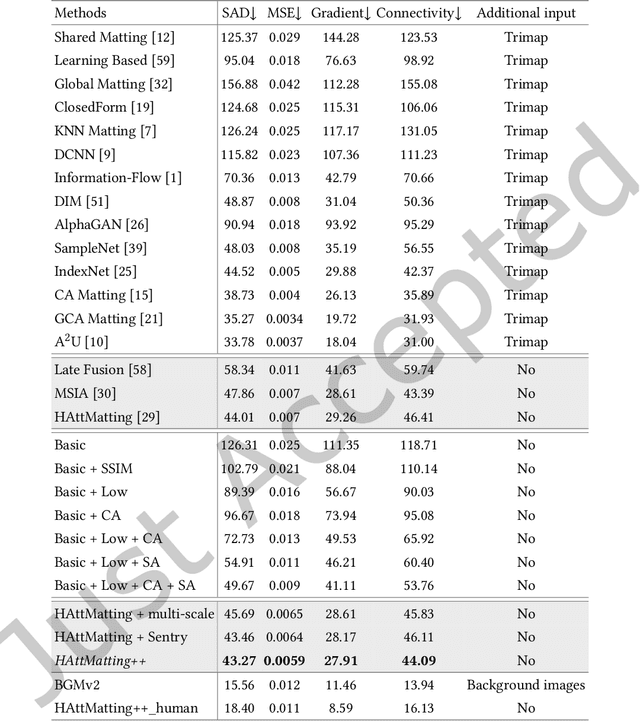
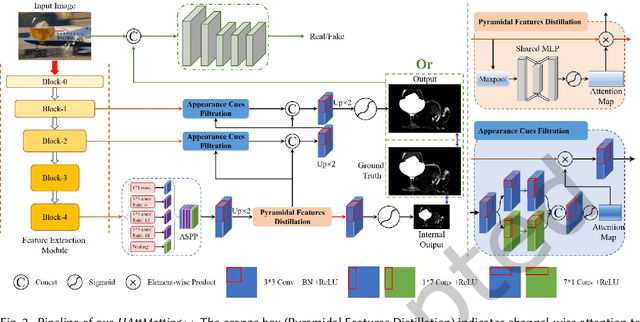
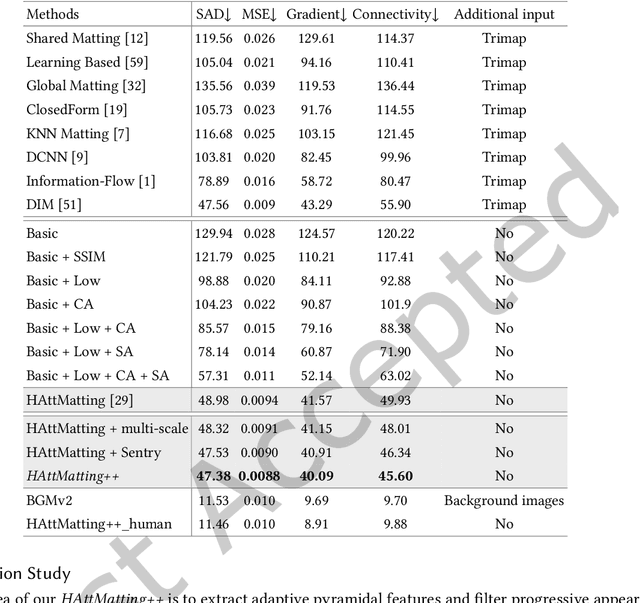
Most matting researches resort to advanced semantics to achieve high-quality alpha mattes, and direct low-level features combination is usually explored to complement alpha details. However, we argue that appearance-agnostic integration can only provide biased foreground details and alpha mattes require different-level feature aggregation for better pixel-wise opacity perception. In this paper, we propose an end-to-end Hierarchical and Progressive Attention Matting Network (HAttMatting++), which can better predict the opacity of the foreground from single RGB images without additional input. Specifically, we utilize channel-wise attention to distill pyramidal features and employ spatial attention at different levels to filter appearance cues. This progressive attention mechanism can estimate alpha mattes from adaptive semantics and semantics-indicated boundaries. We also introduce a hybrid loss function fusing Structural SIMilarity (SSIM), Mean Square Error (MSE), Adversarial loss, and sentry supervision to guide the network to further improve the overall foreground structure. Besides, we construct a large-scale and challenging image matting dataset comprised of 59, 600 training images and 1000 test images (a total of 646 distinct foreground alpha mattes), which can further improve the robustness of our hierarchical and progressive aggregation model. Extensive experiments demonstrate that the proposed HAttMatting++ can capture sophisticated foreground structures and achieve state-of-the-art performance with single RGB images as input.