 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Diverse Risk Preferences in Population-based Self-play
May 19, 2023



Among the great successes of Reinforcement Learning (RL), self-play algorithms play an essential role in solving competitive games. Current self-play algorithms optimize the agent to maximize expected win-rates against its current or historical copies, making it often stuck in the local optimum and its strategy style simple and homogeneous. A possible solution is to improve the diversity of policies, which helps the agent break the stalemate and enhances its robustness when facing different opponents. However, enhancing diversity in the self-play algorithms is not trivial. In this paper, we aim to introduce diversity from the perspective that agents could have diverse risk preferences in the face of uncertainty. Specifically, we design a novel reinforcement learning algorithm called Risk-sensitive Proximal Policy Optimization (RPPO), which smoothly interpolates between worst-case and best-case policy learning and allows for policy learning with desired risk preferences. Seamlessly integrating RPPO with population-based self-play, agents in the population optimize dynamic risk-sensitive objectives with experiences from playing against diverse opponents. Empirical results show that our method achieves comparable or superior performance in competitive games and that diverse modes of behaviors emerge. Our code is public online at \url{https://github.com/Jackory/RPBT}.
The Provable Benefits of Unsupervised Data Sharing for Offline Reinforcement Learning
Feb 27, 2023



Self-supervised methods have become crucial for advancing deep learning by leveraging data itself to reduce the need for expensive annotations. However, the question of how to conduct self-supervised offline reinforcement learning (RL) in a principled way remains unclear. In this paper, we address this issue by investigating the theoretical benefits of utilizing reward-free data in linear Markov Decision Processes (MDPs) within a semi-supervised setting. Further, we propose a novel, Provable Data Sharing algorithm (PDS) to utilize such reward-free data for offline RL. PDS uses additional penalties on the reward function learned from labeled data to prevent overestimation, ensuring a conservative algorithm. Our results on various offline RL tasks demonstrate that PDS significantly improves the performance of offline RL algorithms with reward-free data. Overall, our work provides a promising approach to leveraging the benefits of unlabeled data in offline RL while maintaining theoretical guarantees. We believe our findings will contribute to developing more robust self-supervised RL methods.
Flow to Control: Offline Reinforcement Learning with Lossless Primitive Discovery
Dec 02, 2022



Offline reinforcement learning (RL) enables the agent to effectively learn from logged data, which significantly extends the applicability of RL algorithms in real-world scenarios where exploration can be expensive or unsafe. Previous works have shown that extracting primitive skills from the recurring and temporally extended structures in the logged data yields better learning. However, these methods suffer greatly when the primitives have limited representation ability to recover the original policy space, especially in offline settings. In this paper, we give a quantitative characterization of the performance of offline hierarchical learning and highlight the importance of learning lossless primitives. To this end, we propose to use a \emph{flow}-based structure as the representation for low-level policies. This allows us to represent the behaviors in the dataset faithfully while keeping the expression ability to recover the whole policy space. We show that such lossless primitives can drastically improve the performance of hierarchical policies. The experimental results and extensive ablation studies on the standard D4RL benchmark show that our method has a good representation ability for policies and achieves superior performance in most tasks.
* 13pages
Distributionally Robust Offline Reinforcement Learning with Linear Function Approximation
Sep 29, 2022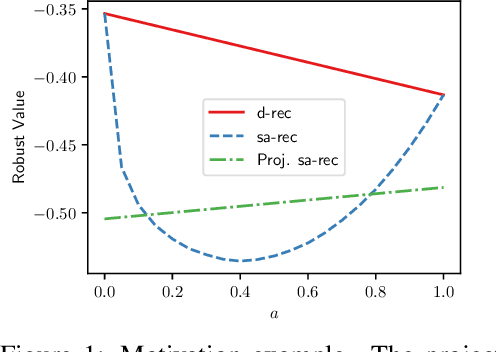
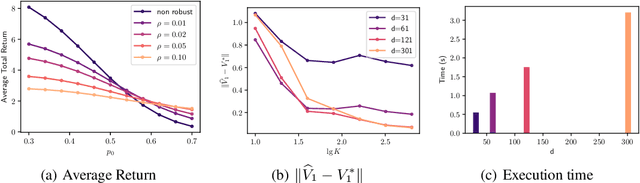
Among the reasons hindering reinforcement learning (RL) applications to real-world problems, two factors are critical: limited data and the mismatch between the testing environment (real environment in which the policy is deployed) and the training environment (e.g., a simulator). This paper attempts to address these issues simultaneously with distributionally robust offline RL, where we learn a distributionally robust policy using historical data obtained from the source environment by optimizing against a worst-case perturbation thereof. In particular, we move beyond tabular settings and consider linear function approximation. More specifically, we consider two settings, one where the dataset is well-explored and the other where the dataset has sufficient coverage. We propose two algorithms -- one for each of the two settings -- that achieve error bounds $\tilde{O}(d^{1/2}/N^{1/2})$ and $\tilde{O}(d^{3/2}/N^{1/2})$ respectively, where $d$ is the dimension in the linear function approximation and $N$ is the number of trajectories in the dataset. To the best of our knowledge, they provide the first non-asymptotic results of the sample complexity in this setting. Diverse experiments are conducted to demonstrate our theoretical findings, showing the superiority of our algorithm against the non-robust one.
Mean-Semivariance Policy Optimization via Risk-Averse Reinforcement Learning
Jun 15, 2022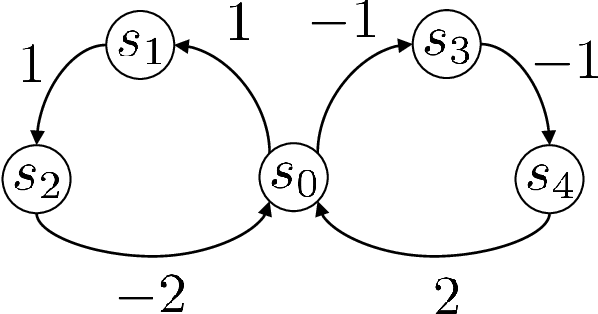
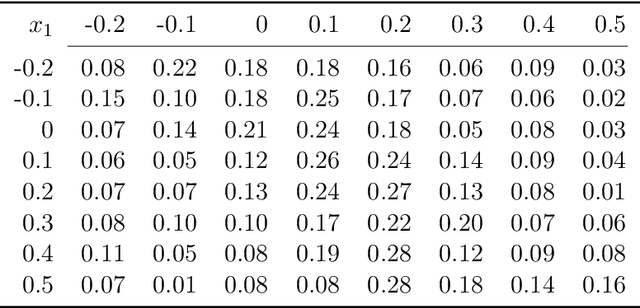
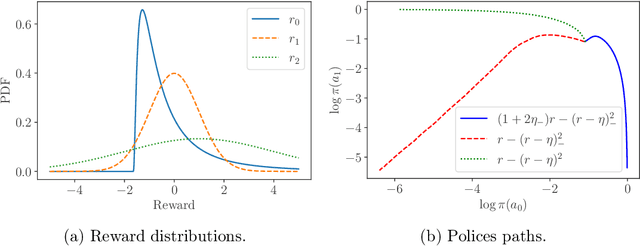
Keeping risk under control is often more crucial than maximizing expected reward in real-world decision-making situations, such as finance, robotics, autonomous driving, etc. The most natural choice of risk measures is variance, while it penalizes the upside volatility as much as the downside part. Instead, the (downside) semivariance, which captures negative deviation of a random variable under its mean, is more suitable for risk-averse proposes. This paper aims at optimizing the mean-semivariance (MSV) criterion in reinforcement learning w.r.t. steady rewards. Since semivariance is time-inconsistent and does not satisfy the standard Bellman equation, the traditional dynamic programming methods are inapplicable to MSV problems directly. To tackle this challenge, we resort to the Perturbation Analysis (PA) theory and establish the performance difference formula for MSV. We reveal that the MSV problem can be solved by iteratively solving a sequence of RL problems with a policy-dependent reward function. Further, we propose two on-policy algorithms based on the policy gradient theory and the trust region method. Finally, we conduct diverse experiments from simple bandit problems to continuous control tasks in MuJoCo, which demonstrate the effectiveness of our proposed methods.
On the Role of Discount Factor in Offline Reinforcement Learning
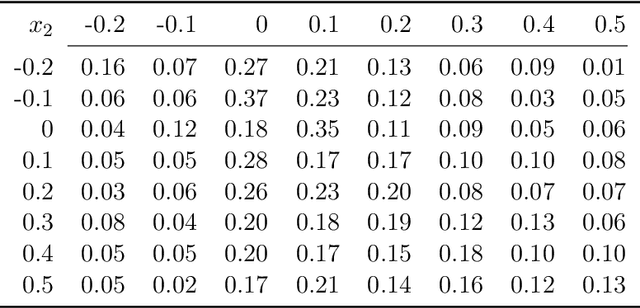
Jun 15, 2022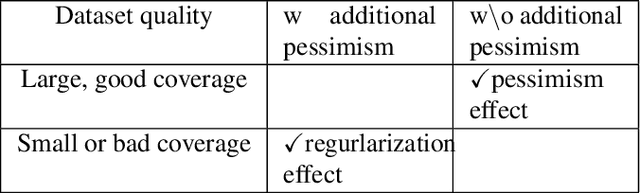
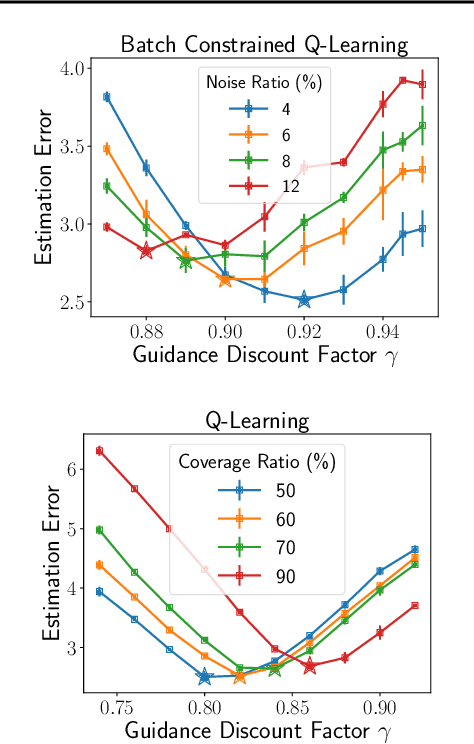
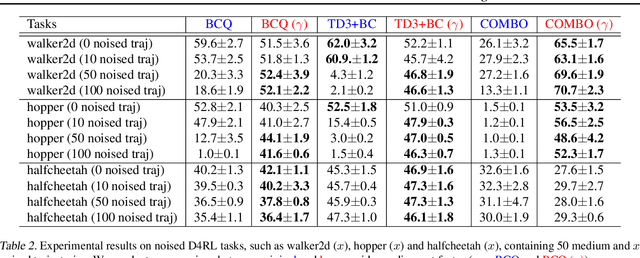
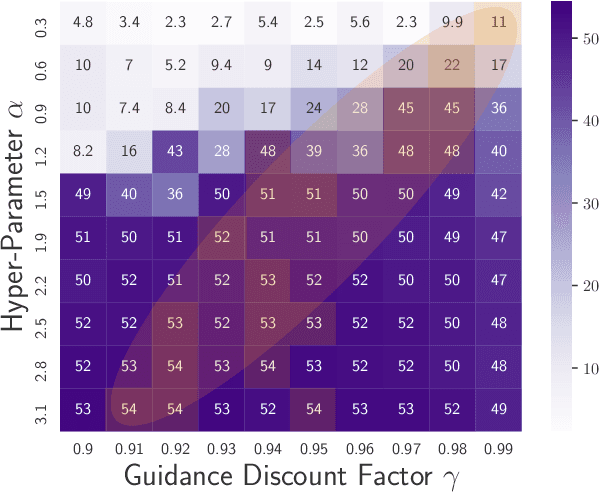
Offline reinforcement learning (RL) enables effective learning from previously collected data without exploration, which shows great promise in real-world applications when exploration is expensive or even infeasible. The discount factor, $\gamma$, plays a vital role in improving online RL sample efficiency and estimation accuracy, but the role of the discount factor in offline RL is not well explored. This paper examines two distinct effects of $\gamma$ in offline RL with theoretical analysis, namely the regularization effect and the pessimism effect. On the one hand, $\gamma$ is a regulator to trade-off optimality with sample efficiency upon existing offline techniques. On the other hand, lower guidance $\gamma$ can also be seen as a way of pessimism where we optimize the policy's performance in the worst possible models. We empirically verify the above theoretical observation with tabular MDPs and standard D4RL tasks. The results show that the discount factor plays an essential role in the performance of offline RL algorithms, both under small data regimes upon existing offline methods and in large data regimes without other conservative methods.
Offline Reinforcement Learning with Value-based Episodic Memory
Oct 19, 2021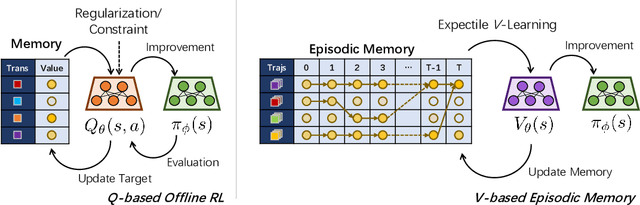
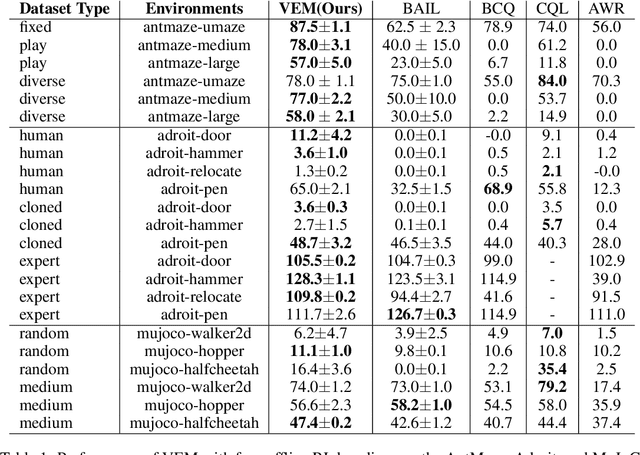
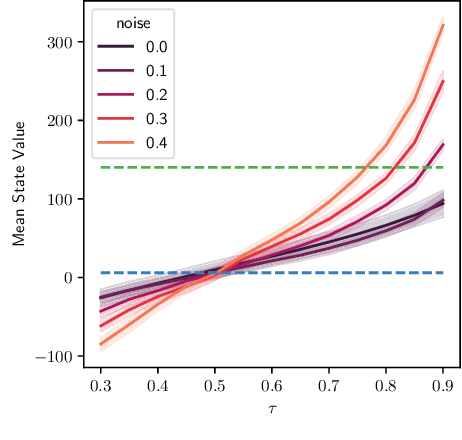
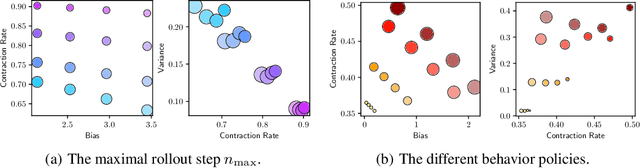
Offline reinforcement learning (RL) shows promise of applying RL to real-world problems by effectively utilizing previously collected data. Most existing offline RL algorithms use regularization or constraints to suppress extrapolation error for actions outside the dataset. In this paper, we adopt a different framework, which learns the V-function instead of the Q-function to naturally keep the learning procedure within the support of an offline dataset. To enable effective generalization while maintaining proper conservatism in offline learning, we propose Expectile V-Learning (EVL), which smoothly interpolates between the optimal value learning and behavior cloning. Further, we introduce implicit planning along offline trajectories to enhance learned V-values and accelerate convergence. Together, we present a new offline method called Value-based Episodic Memory (VEM). We provide theoretical analysis for the convergence properties of our proposed VEM method, and empirical results in the D4RL benchmark show that our method achieves superior performance in most tasks, particularly in sparse-reward tasks.
MGPSN: Motion-Guided Pseudo Siamese Network for Indoor Video Head Detection
Oct 07, 2021
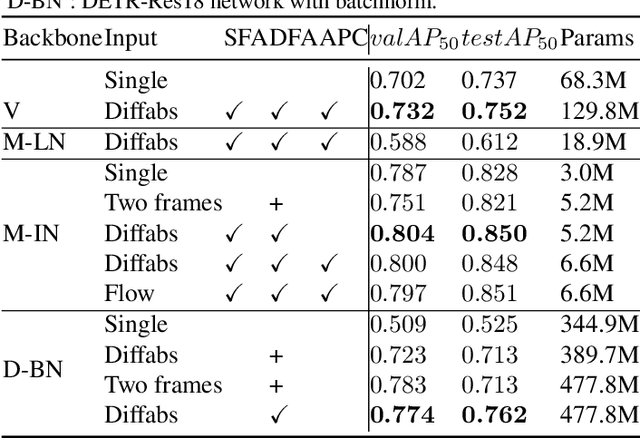
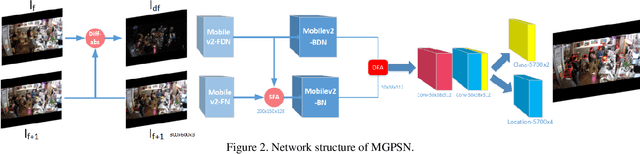
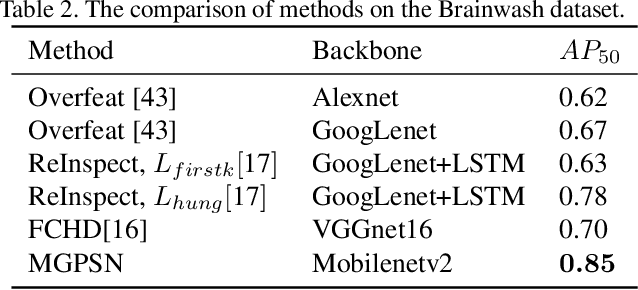
Head detection in real-world videos is an important research topic in computer vision. However, existing studies face some challenges in complex scenes. The performance of head detectors deteriorates when objects which have similar head appearance exist for indoor videos. Moreover, heads have small scales and diverse poses, which increases the difficulty in detection. To handle these issues, we propose Motion-Guided Pseudo Siamese Network for Indoor Video Head Detection (MGPSN), an end-to-end model to learn the robust head motion features. MGPSN integrates spatial-temporal information on pixel level, guiding the model to extract effective head features. Experiments show that MGPSN is able to suppress static objects and enhance motion instances. Compared with previous methods, it achieves state-of-the-art performance on the crowd Brainwash dataset. Different backbone networks and detectors are evaluated to verify the flexibility and generality of MGPSN.
Average-Reward Reinforcement Learning with Trust Region Methods
Jun 07, 2021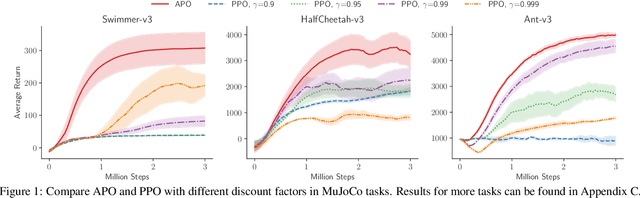
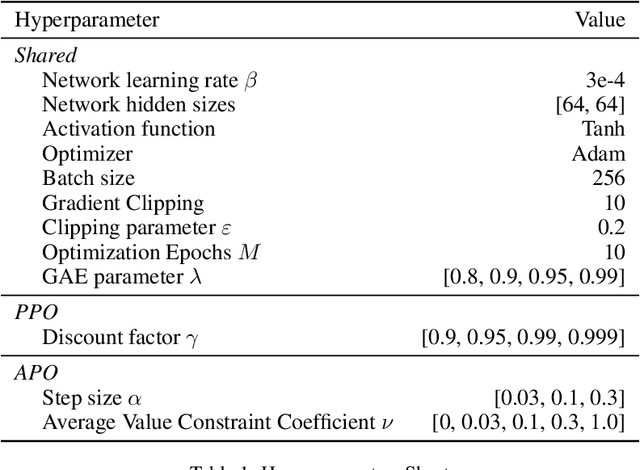
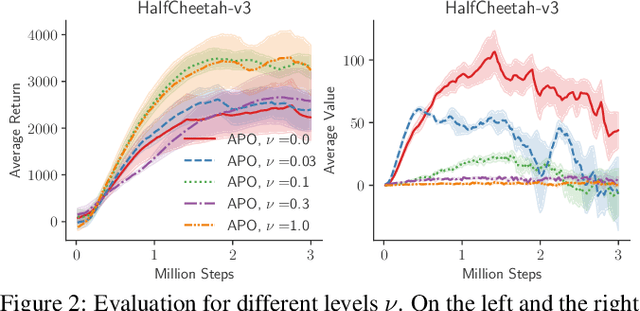
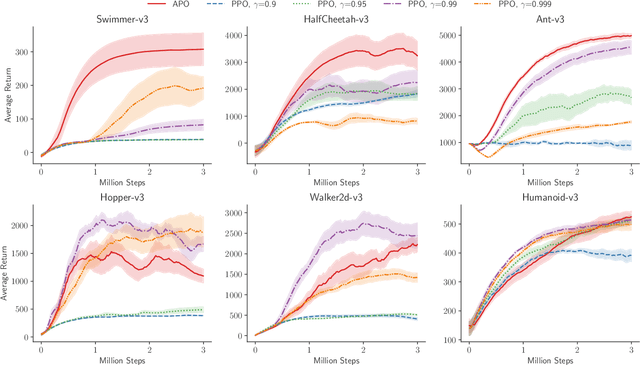
Most of reinforcement learning algorithms optimize the discounted criterion which is beneficial to accelerate the convergence and reduce the variance of estimates. Although the discounted criterion is appropriate for certain tasks such as financial related problems, many engineering problems treat future rewards equally and prefer a long-run average criterion. In this paper, we study the reinforcement learning problem with the long-run average criterion. Firstly, we develop a unified trust region theory with discounted and average criteria. With the average criterion, a novel performance bound within the trust region is derived with the Perturbation Analysis (PA) theory. Secondly, we propose a practical algorithm named Average Policy Optimization (APO), which improves the value estimation with a novel technique named Average Value Constraint. To the best of our knowledge, our work is the first one to study the trust region approach with the average criterion and it complements the framework of reinforcement learning beyond the discounted criterion. Finally, experiments are conducted in the continuous control environment MuJoCo. In most tasks, APO performs better than the discounted PPO, which demonstrates the effectiveness of our approach.
Believe What You See: Implicit Constraint Approach for Offline Multi-Agent Reinforcement Learning
Jun 07, 2021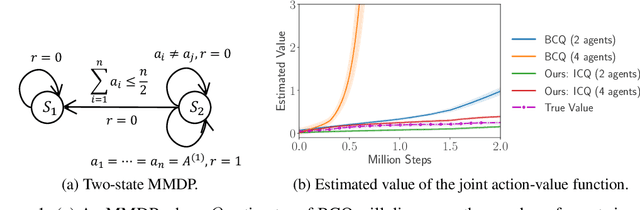
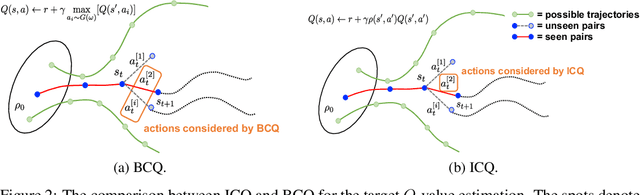
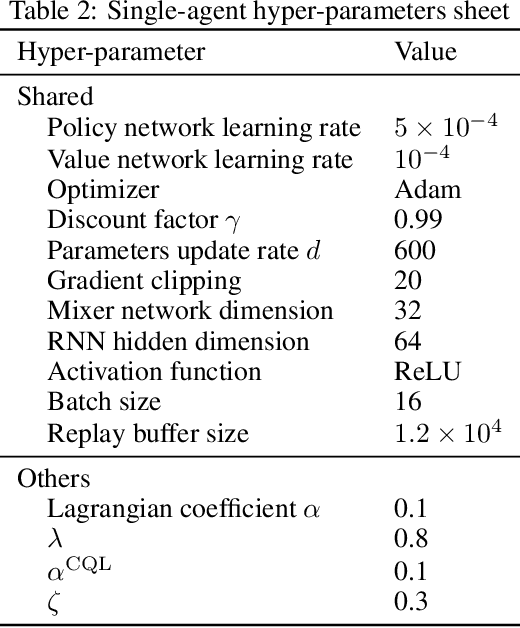
Learning from datasets without interaction with environments (Offline Learning) is an essential step to apply Reinforcement Learning (RL) algorithms in real-world scenarios. However, compared with the single-agent counterpart, offline multi-agent RL introduces more agents with the larger state and action space, which is more challenging but attracts little attention. We demonstrate current offline RL algorithms are ineffective in multi-agent systems due to the accumulated extrapolation error. In this paper, we propose a novel offline RL algorithm, named Implicit Constraint Q-learning (ICQ), which effectively alleviates the extrapolation error by only trusting the state-action pairs given in the dataset for value estimation. Moreover, we extend ICQ to multi-agent tasks by decomposing the joint-policy under the implicit constraint. Experimental results demonstrate that the extrapolation error is reduced to almost zero and insensitive to the number of agents. We further show that ICQ achieves the state-of-the-art performance in the challenging multi-agent offline tasks (StarCraft II).