 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVS2D: Efficient Multi-view Stereo via Attention-Driven 2D Convolutions
Apr 27, 2021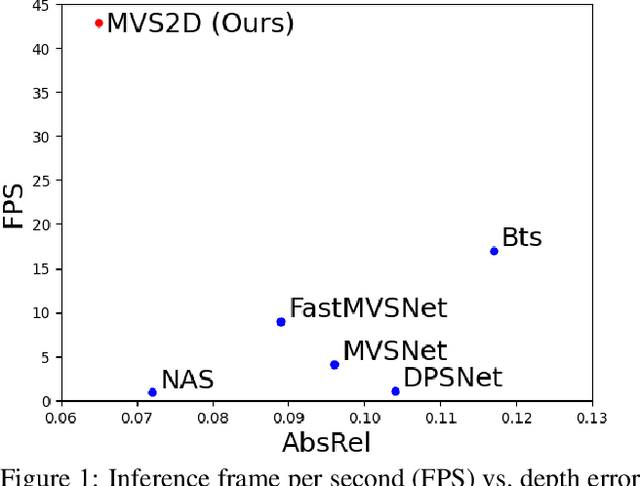
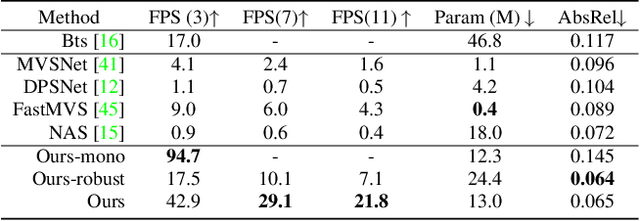
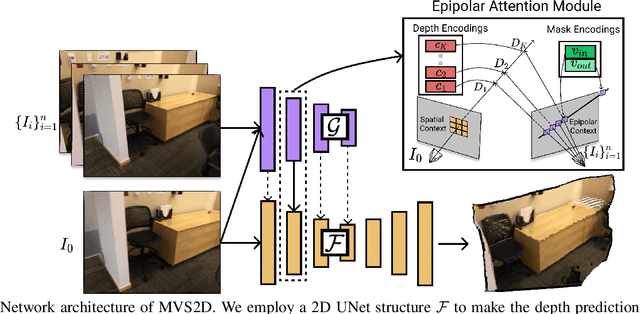
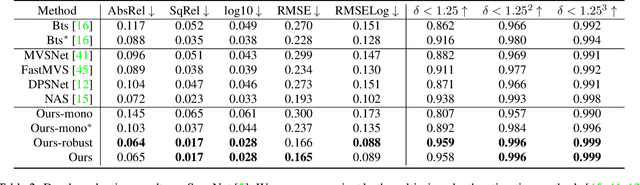
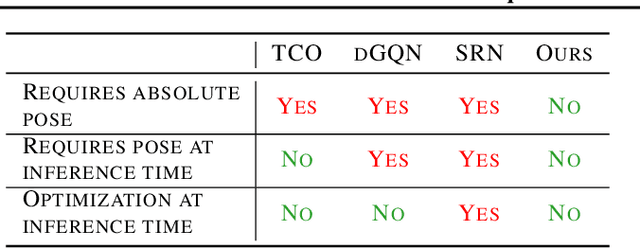
Deep learning has made significant impacts on multi-view stereo systems. State-of-the-art approaches typically involve building a cost volume, followed by multiple 3D convolution operations to recover the input image's pixel-wise depth. While such end-to-end learning of plane-sweeping stereo advances public benchmarks' accuracy, they are typically very slow to compute. We present MVS2D, a highly efficient multi-view stereo algorithm that seamlessly integrates multi-view constraints into single-view networks via an attention mechanism. Since MVS2D only builds on 2D convolutions, it is at least 4x faster than all the notable counterparts. Moreover, our algorithm produces precise depth estimations, achieving state-of-the-art results on challenging benchmarks ScanNet, SUN3D, and RGBD. Even under inexact camera poses, our algorithm still out-performs all other algorithms. Supplementary materials and code will be available at the project page: https://zhenpeiyang.github.io/MVS2D
RetrievalFuse: Neural 3D Scene Reconstruction with a Database
Mar 31, 2021
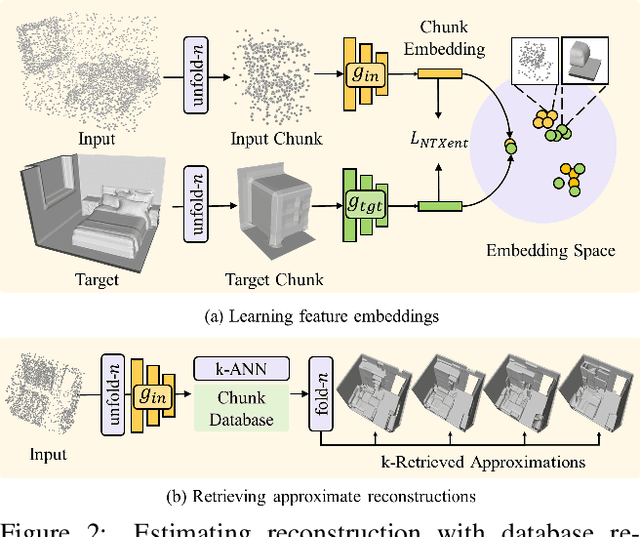
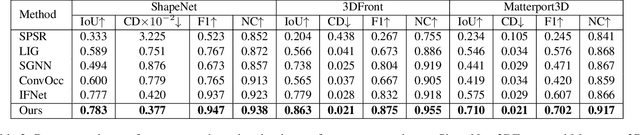
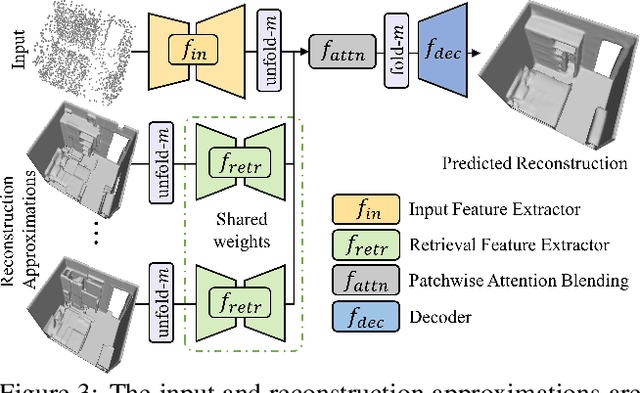
3D reconstruction of large scenes is a challenging problem due to the high-complexity nature of the solution space, in particular for generative neural networks. In contrast to traditional generative learned models which encode the full generative process into a neural network and can struggle with maintaining local details at the scene level, we introduce a new method that directly leverages scene geometry from the training database. First, we learn to synthesize an initial estimate for a 3D scene, constructed by retrieving a top-k set of volumetric chunks from the scene database. These candidates are then refined to a final scene generation with an attention-based refinement that can effectively select the most consistent set of geometry from the candidates and combine them together to create an output scene, facilitating transfer of coherent structures and local detail from train scene geometry. We demonstrate our neural scene reconstruction with a database for the tasks of 3D super resolution and surface reconstruction from sparse point clouds, showing that our approach enables generation of more coherent, accurate 3D scenes, improving on average by over 8% in IoU over state-of-the-art scene reconstruction.
Equivariant Neural Rendering
Jun 13, 2020

We propose a framework for learning neural scene representations directly from images, without 3D supervision. Our key insight is that 3D structure can be imposed by ensuring that the learned representation transforms like a real 3D scene. Specifically, we introduce a loss which enforces equivariance of the scene representation with respect to 3D transformations. Our formulation allows us to infer and render scenes in real time while achieving comparable results to models requiring minutes for inference. In addition, we introduce two challenging new datasets for scene representation and neural rendering, including scenes with complex lighting and backgrounds. Through experiments, we show that our model achieves compelling results on these datasets as well as on standard ShapeNet benchmarks.
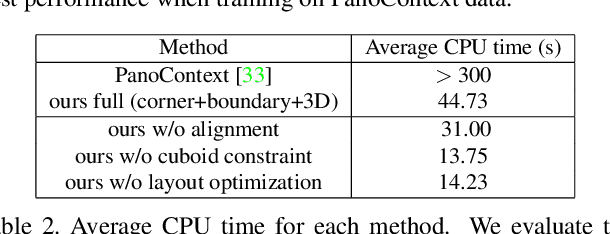
3D Manhattan Room Layout Reconstruction from a Single 360 Image
Oct 24, 2019


Recent approaches for predicting layouts from 360 panoramas produce excellent results. These approaches build on a common framework consisting of three steps: a pre-processing step based on edge-based alignment, prediction of layout elements, and a post-processing step by fitting a 3D layout to the layout elements. Until now, it has been difficult to compare the methods due to multiple different design decisions, such as the encoding network (e.g. SegNet or ResNet), type of elements predicted (e.g. corners, wall/floor boundaries, or semantic segmentation), or method of fitting the 3D layout. To address this challenge, we summarize and describe the common framework, the variants, and the impact of the design decisions. For a complete evaluation, we also propose extended annotations for the Matterport3D dataset, and introduce two depth-based evaluation metrics.
LayoutNet: Reconstructing the 3D Room Layout from a Single RGB Image
Mar 23, 2018
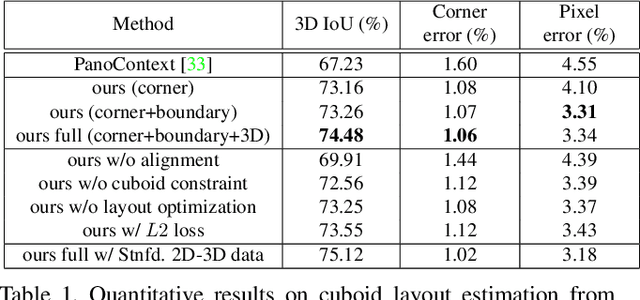
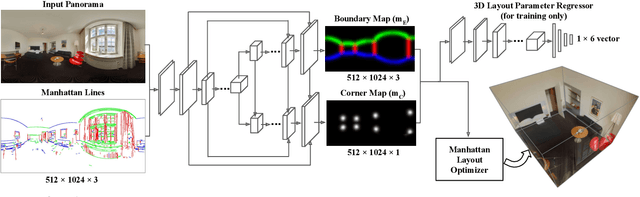
We propose an algorithm to predict room layout from a single image that generalizes across panoramas and perspective images, cuboid layouts and more general layouts (e.g. L-shape room). Our method operates directly on the panoramic image, rather than decomposing into perspective images as do recent works. Our network architecture is similar to that of RoomNet, but we show improvements due to aligning the image based on vanishing points, predicting multiple layout elements (corners, boundaries, size and translation), and fitting a constrained Manhattan layout to the resulting predictions. Our method compares well in speed and accuracy to other existing work on panoramas, achieves among the best accuracy for perspective images, and can handle both cuboid-shaped and more general Manhattan layouts.
RIDI: Robust IMU Double Integration
Dec 31, 2017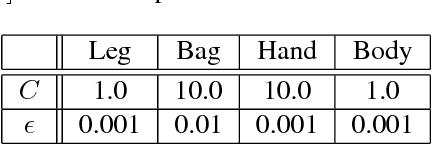

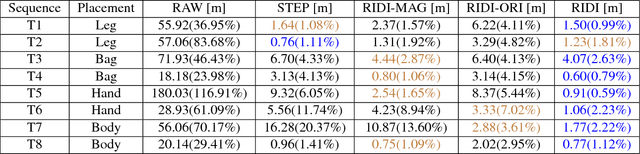
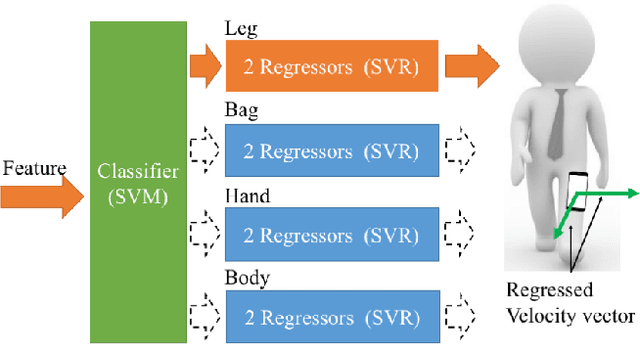
This paper proposes a novel data-driven approach for inertial navigation, which learns to estimate trajectories of natural human motions just from an inertial measurement unit (IMU) in every smartphone. The key observation is that human motions are repetitive and consist of a few major modes (e.g., standing, walking, or turning). Our algorithm regresses a velocity vector from the history of linear accelerations and angular velocities, then corrects low-frequency bias in the linear accelerations, which are integrated twice to estimate positions. We have acquired training data with ground-truth motions across multiple human subjects and multiple phone placements (e.g., in a bag or a hand). The qualitatively and quantitatively evaluations have demonstrated that our algorithm has surprisingly shown comparable results to full Visual Inertial navigation. To our knowledge, this paper is the first to integrate sophisticated machine learning techniques with inertial navigation, potentially opening up a new line of research in the domain of data-driven inertial navigation. We will publicly share our code and data to facilitate further research.
IM2CAD
Apr 24, 2017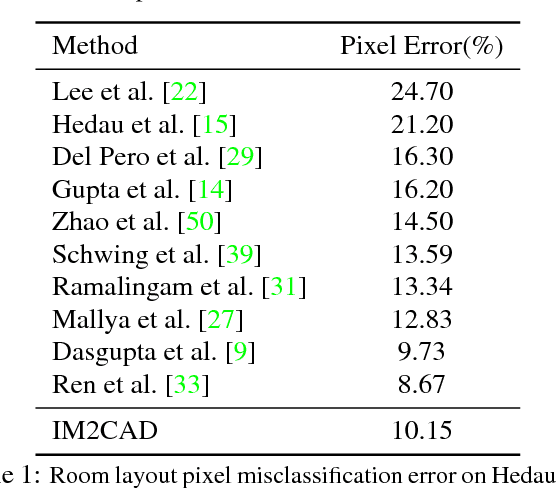

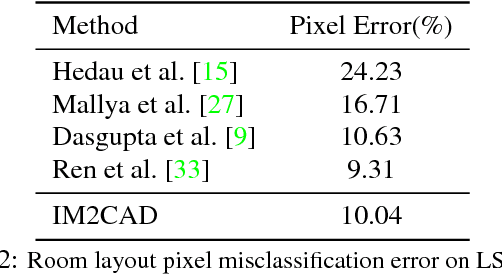
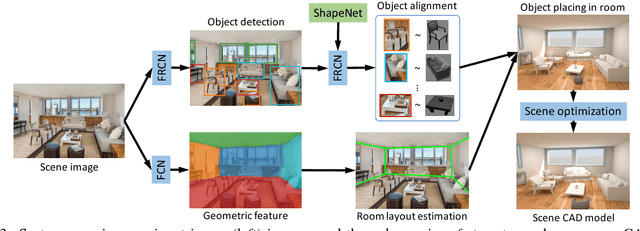
Given a single photo of a room and a large database of furniture CAD models, our goal is to reconstruct a scene that is as similar as possible to the scene depicted in the photograph, and composed of objects drawn from the database. We present a completely automatic system to address this IM2CAD problem that produces high quality results on challenging imagery from interior home design and remodeling websites. Our approach iteratively optimizes the placement and scale of objects in the room to best match scene renderings to the input photo, using image comparison metrics trained via deep convolutional neural nets. By operating jointly on the full scene at once, we account for inter-object occlusions. We also show the applicability of our method in standard scene understanding benchmarks where we obtain significant improvement.
Panoramic Structure from Motion via Geometric Relationship Detection
Dec 05, 2016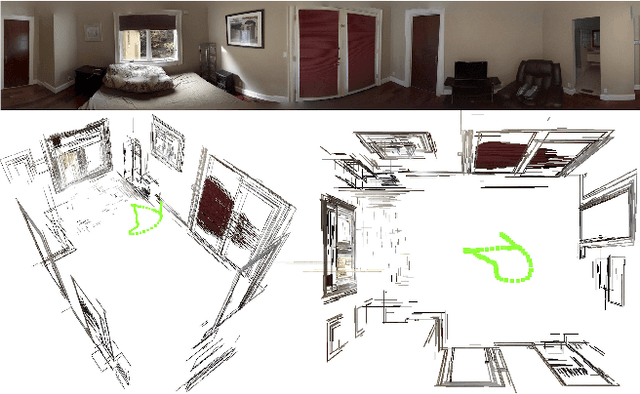
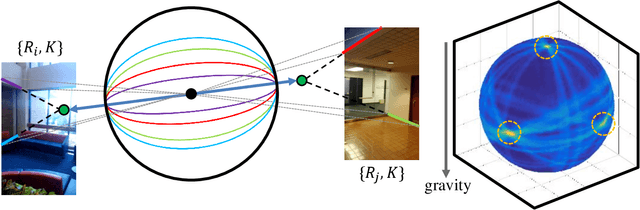

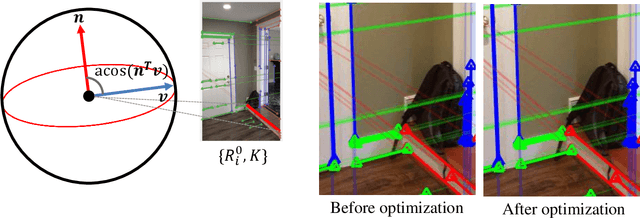
This paper addresses the problem of Structure from Motion (SfM) for indoor panoramic image streams, extremely challenging even for the state-of-the-art due to the lack of textures and minimal parallax. The key idea is the fusion of single-view and multi-view reconstruction techniques via geometric relationship detection (e.g., detecting 2D lines as coplanar in 3D). Rough geometry suffices to perform such detection, and our approach utilizes rough surface normal estimates from an image-to-normal deep network to discover geometric relationships among lines. The detected relationships provide exact geometric constraints in our line-based linear SfM formulation. A constrained linear least squares is used to reconstruct a 3D model and camera motions, followed by the bundle adjustment. We have validated our algorithm on challenging datasets, outperforming various state-of-the-art reconstruction techniques.