 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Inductive Biases in Transformers without Message Passing
May 27, 2023



Transformers for graph data are increasingly widely studied and successful in numerous learning tasks. Graph inductive biases are crucial for Graph Transformers, and previous works incorporate them using message-passing modules and/or positional encodings. However, Graph Transformers that use message-passing inherit known issues of message-passing, and differ significantly from Transformers used in other domains, thus making transfer of research advances more difficult. On the other hand, Graph Transformers without message-passing often perform poorly on smaller datasets, where inductive biases are more crucial. To bridge this gap, we propose the Graph Inductive bias Transformer (GRIT) -- a new Graph Transformer that incorporates graph inductive biases without using message passing. GRIT is based on several architectural changes that are each theoretically and empirically justified, including: learned relative positional encodings initialized with random walk probabilities, a flexible attention mechanism that updates node and node-pair representations, and injection of degree information in each layer. We prove that GRIT is expressive -- it can express shortest path distances and various graph propagation matrices. GRIT achieves state-of-the-art empirical performance across a variety of graph datasets, thus showing the power that Graph Transformers without message-passing can deliver.
Raising the Bar on the Evaluation of Out-of-Distribution Detection
Sep 24, 2022
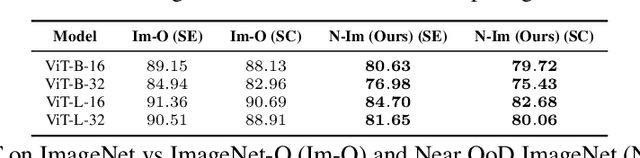
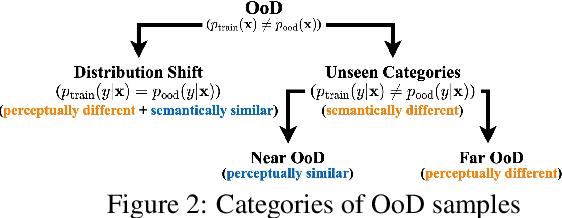
In image classification, a lot of development has happened in detecting out-of-distribution (OoD) data. However, most OoD detection methods are evaluated on a standard set of datasets, arbitrarily different from training data. There is no clear definition of what forms a ``good" OoD dataset. Furthermore, the state-of-the-art OoD detection methods already achieve near perfect results on these standard benchmarks. In this paper, we define 2 categories of OoD data using the subtly different concepts of perceptual/visual and semantic similarity to in-distribution (iD) data. We define Near OoD samples as perceptually similar but semantically different from iD samples, and Shifted samples as points which are visually different but semantically akin to iD data. We then propose a GAN based framework for generating OoD samples from each of these 2 categories, given an iD dataset. Through extensive experiments on MNIST, CIFAR-10/100 and ImageNet, we show that a) state-of-the-art OoD detection methods which perform exceedingly well on conventional benchmarks are significantly less robust to our proposed benchmark. Moreover, b) models performing well on our setup also perform well on conventional real-world OoD detection benchmarks and vice versa, thereby indicating that one might not even need a separate OoD set, to reliably evaluate performance in OoD detection.
Query-based Hard-Image Retrieval for Object Detection at Test Time
Sep 23, 2022
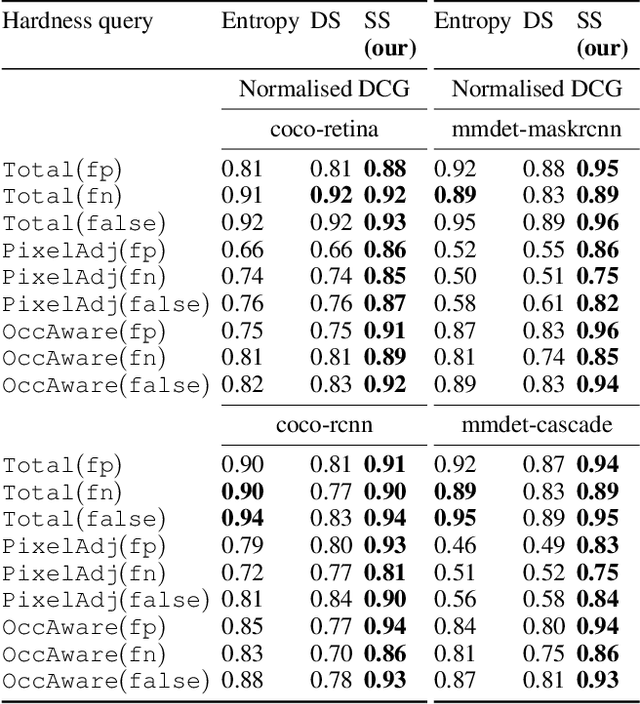
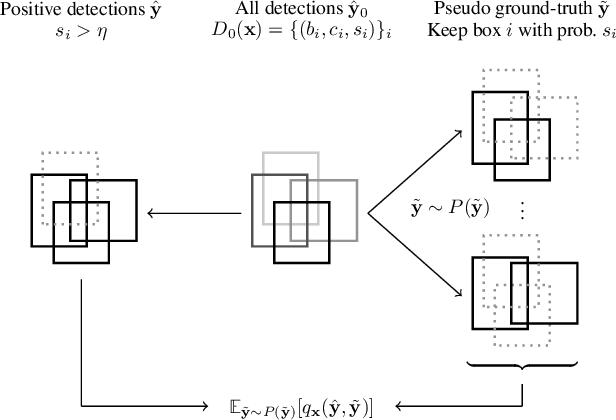
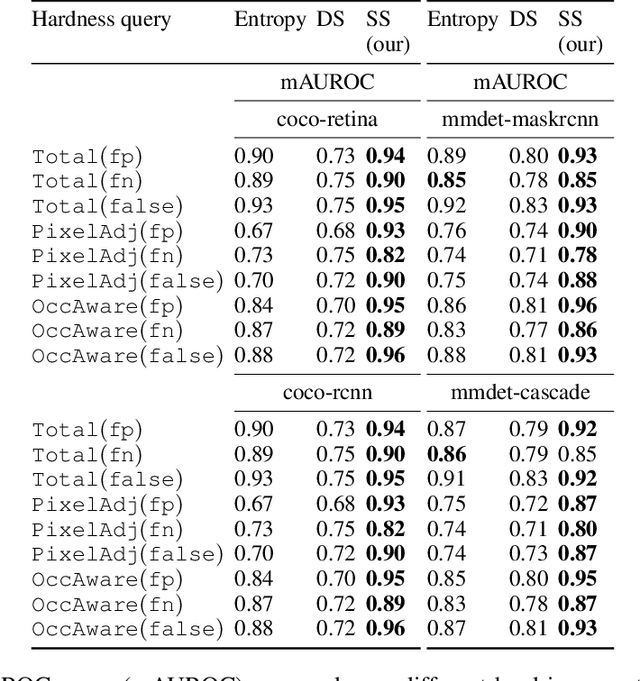
There is a longstanding interest in capturing the error behaviour of object detectors by finding images where their performance is likely to be unsatisfactory. In real-world applications such as autonomous driving, it is also crucial to characterise potential failures beyond simple requirements of detection performance. For example, a missed detection of a pedestrian close to an ego vehicle will generally require closer inspection than a missed detection of a car in the distance. The problem of predicting such potential failures at test time has largely been overlooked in the literature and conventional approaches based on detection uncertainty fall short in that they are agnostic to such fine-grained characterisation of errors. In this work, we propose to reformulate the problem of finding "hard" images as a query-based hard image retrieval task, where queries are specific definitions of "hardness", and offer a simple and intuitive method that can solve this task for a large family of queries. Our method is entirely post-hoc, does not require ground-truth annotations, is independent of the choice of a detector, and relies on an efficient Monte Carlo estimation that uses a simple stochastic model in place of the ground-truth. We show experimentally that it can be applied successfully to a wide variety of queries for which it can reliably identify hard images for a given detector without any labelled data. We provide results on ranking and classification tasks using the widely used RetinaNet, Faster-RCNN, Mask-RCNN, and Cascade Mask-RCNN object detectors.
An Impartial Take to the CNN vs Transformer Robustness Contest
Jul 22, 2022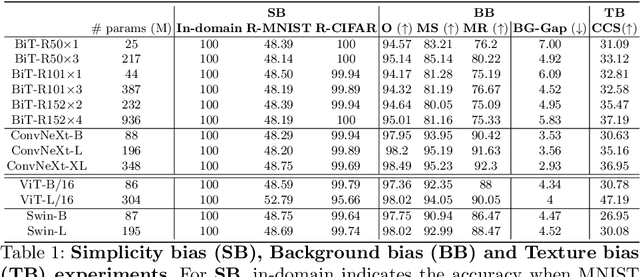

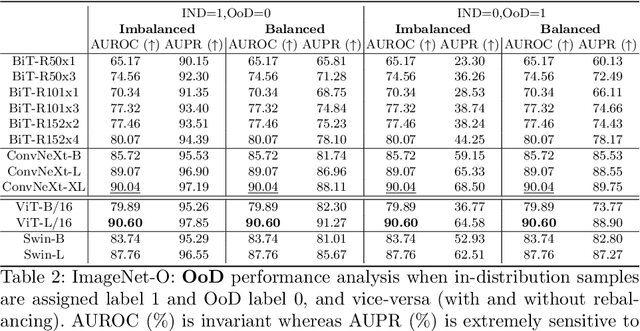
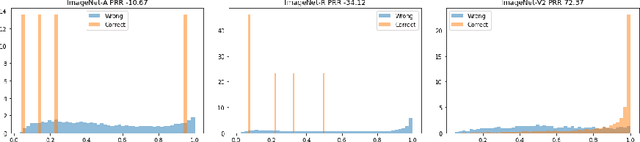
Following the surge of popularity of Transformers in Computer Vision, several studies have attempted to determine whether they could be more robust to distribution shifts and provide better uncertainty estimates than Convolutional Neural Networks (CNNs). The almost unanimous conclusion is that they are, and it is often conjectured more or less explicitly that the reason of this supposed superiority is to be attributed to the self-attention mechanism. In this paper we perform extensive empirical analyses showing that recent state-of-the-art CNNs (particularly, ConvNeXt) can be as robust and reliable or even sometimes more than the current state-of-the-art Transformers. However, there is no clear winner. Therefore, although it is tempting to state the definitive superiority of one family of architectures over another, they seem to enjoy similar extraordinary performances on a variety of tasks while also suffering from similar vulnerabilities such as texture, background, and simplicity biases.
Sample-dependent Adaptive Temperature Scaling for Improved Calibration
Jul 22, 2022
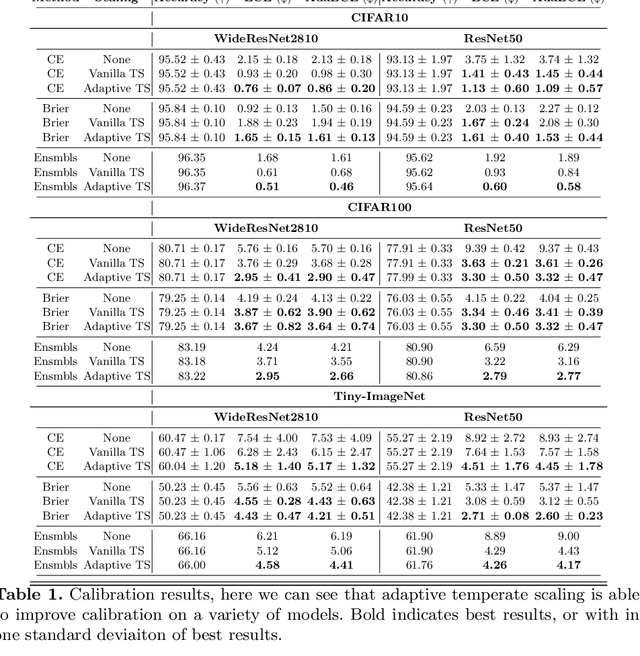
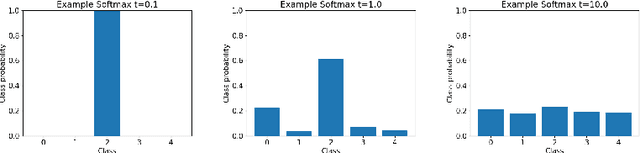
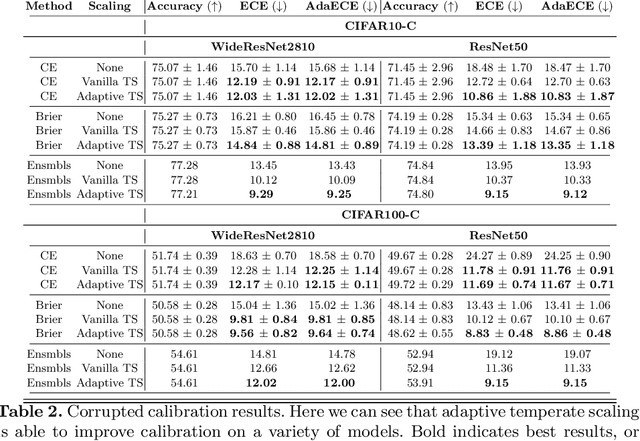
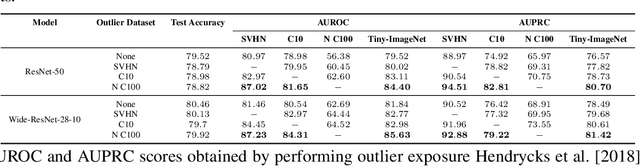
It is now well known that neural networks can be wrong with high confidence in their predictions, leading to poor calibration. The most common post-hoc approach to compensate for this is to perform temperature scaling, which adjusts the confidences of the predictions on any input by scaling the logits by a fixed value. Whilst this approach typically improves the average calibration across the whole test dataset, this improvement typically reduces the individual confidences of the predictions irrespective of whether the classification of a given input is correct or incorrect. With this insight, we base our method on the observation that different samples contribute to the calibration error by varying amounts, with some needing to increase their confidence and others needing to decrease it. Therefore, for each input, we propose to predict a different temperature value, allowing us to adjust the mismatch between confidence and accuracy at a finer granularity. Furthermore, we observe improved results on OOD detection and can also extract a notion of hardness for the data-points. Our method is applied post-hoc, consequently using very little computation time and with a negligible memory footprint and is applied to off-the-shelf pre-trained classifiers. We test our method on the ResNet50 and WideResNet28-10 architectures using the CIFAR10/100 and Tiny-ImageNet datasets, showing that producing per-data-point temperatures is beneficial also for the expected calibration error across the whole test set. Code is available at: https://github.com/thwjoy/adats.
RegMixup: Mixup as a Regularizer Can Surprisingly Improve Accuracy and Out Distribution Robustness
Jun 29, 2022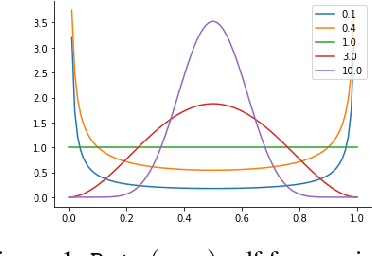

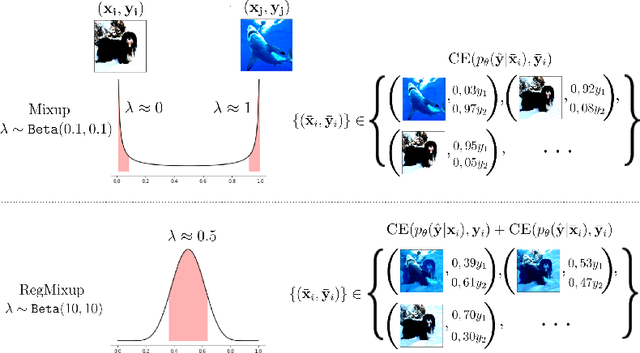
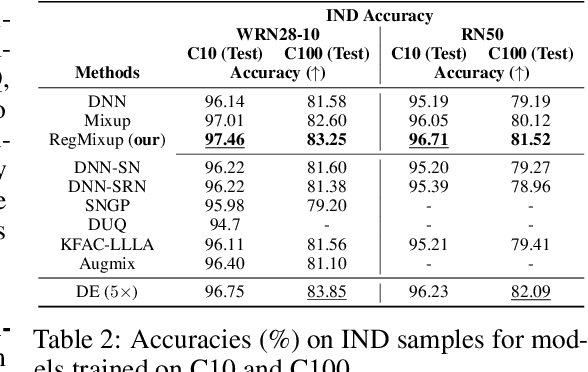
We show that the effectiveness of the well celebrated Mixup [Zhang et al., 2018] can be further improved if instead of using it as the sole learning objective, it is utilized as an additional regularizer to the standard cross-entropy loss. This simple change not only provides much improved accuracy but also significantly improves the quality of the predictive uncertainty estimation of Mixup in most cases under various forms of covariate shifts and out-of-distribution detection experiments. In fact, we observe that Mixup yields much degraded performance on detecting out-of-distribution samples possibly, as we show empirically, because of its tendency to learn models that exhibit high-entropy throughout; making it difficult to differentiate in-distribution samples from out-distribution ones. To show the efficacy of our approach (RegMixup), we provide thorough analyses and experiments on vision datasets (ImageNet & CIFAR-10/100) and compare it with a suite of recent approaches for reliable uncertainty estimation.
Catastrophic overfitting is a bug but also a feature
Jun 16, 2022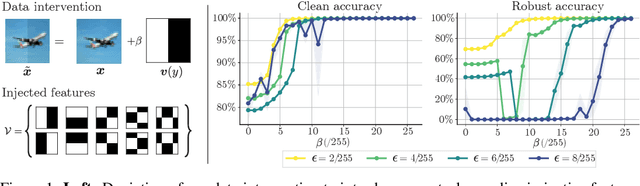
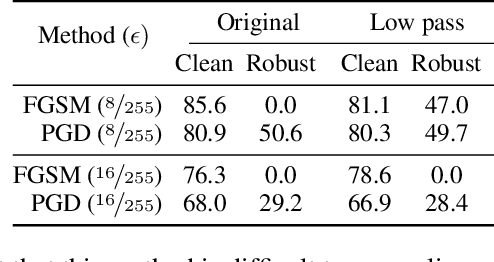
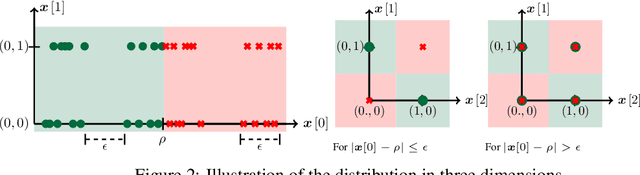

Despite clear computational advantages in building robust neural networks, adversarial training (AT) using single-step methods is unstable as it suffers from catastrophic overfitting (CO): Networks gain non-trivial robustness during the first stages of adversarial training, but suddenly reach a breaking point where they quickly lose all robustness in just a few iterations. Although some works have succeeded at preventing CO, the different mechanisms that lead to this remarkable failure mode are still poorly understood. In this work, however, we find that the interplay between the structure of the data and the dynamics of AT plays a fundamental role in CO. Specifically, through active interventions on typical datasets of natural images, we establish a causal link between the structure of the data and the onset of CO in single-step AT methods. This new perspective provides important insights into the mechanisms that lead to CO and paves the way towards a better understanding of the general dynamics of robust model construction. The code to reproduce the experiments of this paper can be found at https://github.com/gortizji/co_features .
Make Some Noise: Reliable and Efficient Single-Step Adversarial Training
Feb 02, 2022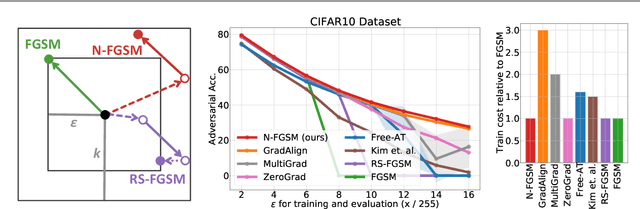
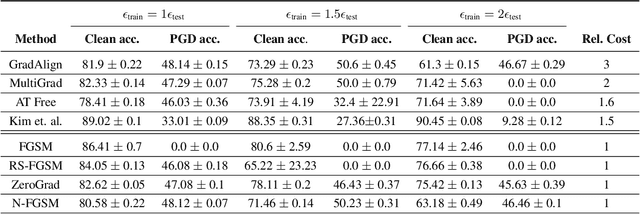
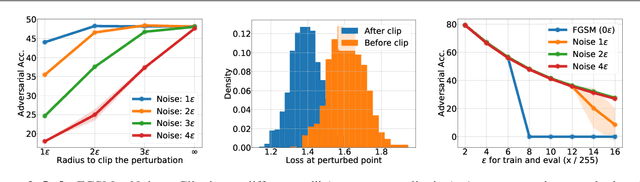
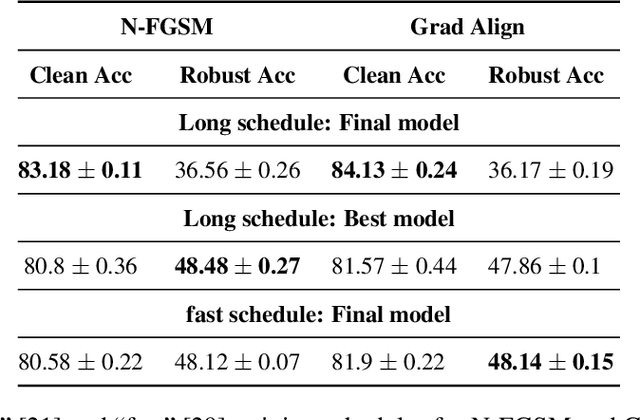
Recently, Wong et al. showed that adversarial training with single-step FGSM leads to a characteristic failure mode named catastrophic overfitting (CO), in which a model becomes suddenly vulnerable to multi-step attacks. They showed that adding a random perturbation prior to FGSM (RS-FGSM) seemed to be sufficient to prevent CO. However, Andriushchenko and Flammarion observed that RS-FGSM still leads to CO for larger perturbations, and proposed an expensive regularizer (GradAlign) to avoid CO. In this work, we methodically revisit the role of noise and clipping in single-step adversarial training. Contrary to previous intuitions, we find that using a stronger noise around the clean sample combined with not clipping is highly effective in avoiding CO for large perturbation radii. Based on these observations, we then propose Noise-FGSM (N-FGSM) that, while providing the benefits of single-step adversarial training, does not suffer from CO. Empirical analyses on a large suite of experiments show that N-FGSM is able to match or surpass the performance of previous single-step methods while achieving a 3$\times$ speed-up.
ANCER: Anisotropic Certification via Sample-wise Volume Maximization
Jul 20, 2021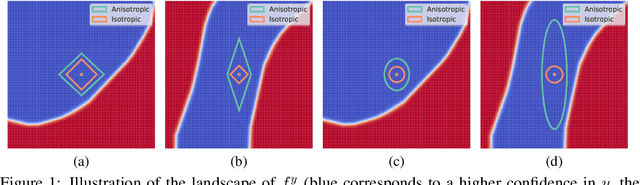
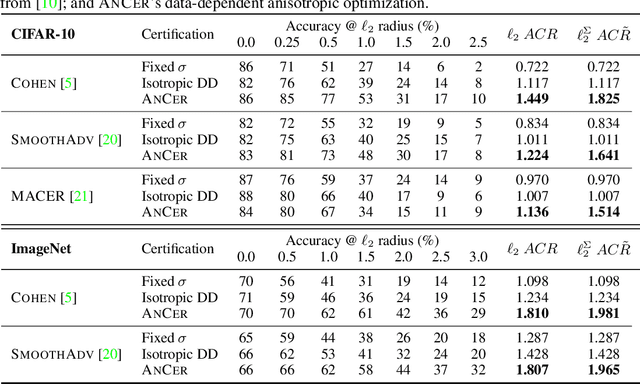

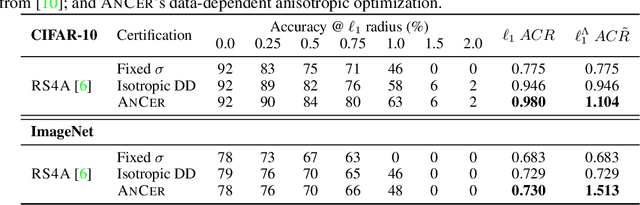
Randomized smoothing has recently emerged as an effective tool that enables certification of deep neural network classifiers at scale. All prior art on randomized smoothing has focused on isotropic $\ell_p$ certification, which has the advantage of yielding certificates that can be easily compared among isotropic methods via $\ell_p$-norm radius. However, isotropic certification limits the region that can be certified around an input to worst-case adversaries, i.e., it cannot reason about other "close", potentially large, constant prediction safe regions. To alleviate this issue, (i) we theoretically extend the isotropic randomized smoothing $\ell_1$ and $\ell_2$ certificates to their generalized anisotropic counterparts following a simplified analysis. Moreover, (ii) we propose evaluation metrics allowing for the comparison of general certificates - a certificate is superior to another if it certifies a superset region - with the quantification of each certificate through the volume of the certified region. We introduce ANCER, a practical framework for obtaining anisotropic certificates for a given test set sample via volume maximization. Our empirical results demonstrate that ANCER achieves state-of-the-art $\ell_1$ and $\ell_2$ certified accuracy on both CIFAR-10 and ImageNet at multiple radii, while certifying substantially larger regions in terms of volume, thus highlighting the benefits of moving away from isotropic analysis. Code used in our experiments is available in https://github.com/MotasemAlfarra/ANCER.
No Cost Likelihood Manipulation at Test Time for Making Better Mistakes in Deep Networks
Apr 01, 2021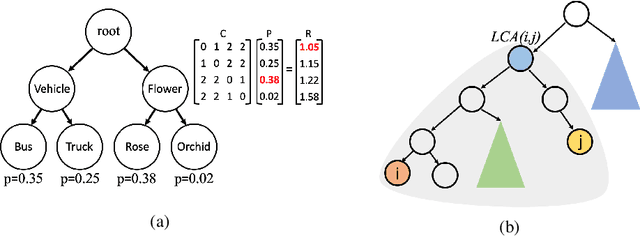


There has been increasing interest in building deep hierarchy-aware classifiers that aim to quantify and reduce the severity of mistakes, and not just reduce the number of errors. The idea is to exploit the label hierarchy (e.g., the WordNet ontology) and consider graph distances as a proxy for mistake severity. Surprisingly, on examining mistake-severity distributions of the top-1 prediction, we find that current state-of-the-art hierarchy-aware deep classifiers do not always show practical improvement over the standard cross-entropy baseline in making better mistakes. The reason for the reduction in average mistake-severity can be attributed to the increase in low-severity mistakes, which may also explain the noticeable drop in their accuracy. To this end, we use the classical Conditional Risk Minimization (CRM) framework for hierarchy-aware classification. Given a cost matrix and a reliable estimate of likelihoods (obtained from a trained network), CRM simply amends mistakes at inference time; it needs no extra hyperparameters and requires adding just a few lines of code to the standard cross-entropy baseline. It significantly outperforms the state-of-the-art and consistently obtains large reductions in the average hierarchical distance of top-$k$ predictions across datasets, with very little loss in accuracy. CRM, because of its simplicity, can be used with any off-the-shelf trained model that provides reliable likelihood estimates.