 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurotoxin: Durable Backdoors in Federated Learning
Jun 12, 2022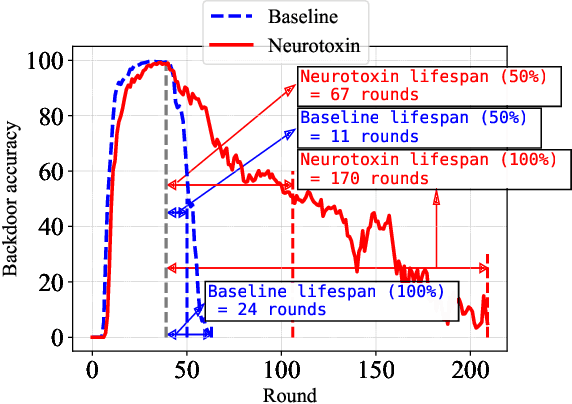

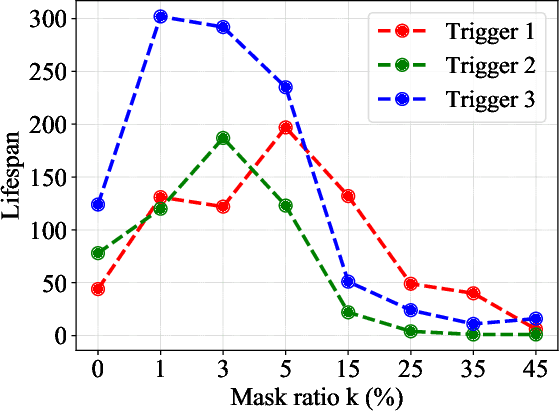
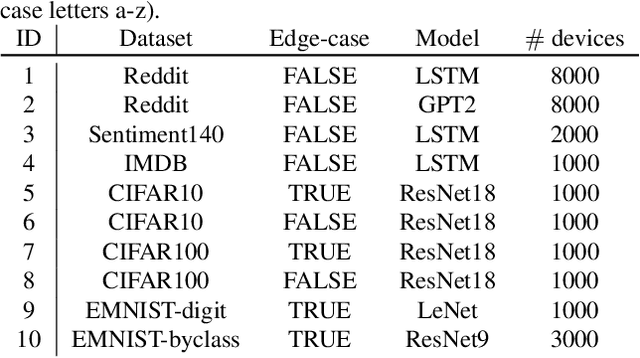
Due to their decentralized nature, federated learning (FL) systems have an inherent vulnerability during their training to adversarial backdoor attacks. In this type of attack, the goal of the attacker is to use poisoned updates to implant so-called backdoors into the learned model such that, at test time, the model's outputs can be fixed to a given target for certain inputs. (As a simple toy example, if a user types "people from New York" into a mobile keyboard app that uses a backdoored next word prediction model, then the model could autocomplete the sentence to "people from New York are rude"). Prior work has shown that backdoors can be inserted into FL models, but these backdoors are often not durable, i.e., they do not remain in the model after the attacker stops uploading poisoned updates. Thus, since training typically continues progressively in production FL systems, an inserted backdoor may not survive until deployment. Here, we propose Neurotoxin, a simple one-line modification to existing backdoor attacks that acts by attacking parameters that are changed less in magnitude during training. We conduct an exhaustive evaluation across ten natural language processing and computer vision tasks, and we find that we can double the durability of state of the art backdoors.
Fight Poison with Poison: Detecting Backdoor Poison Samples via Decoupling Benign Correlations
May 26, 2022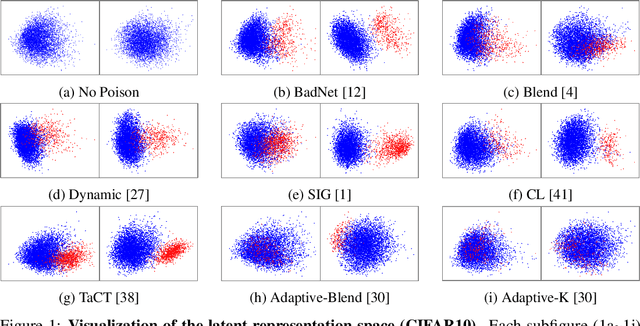
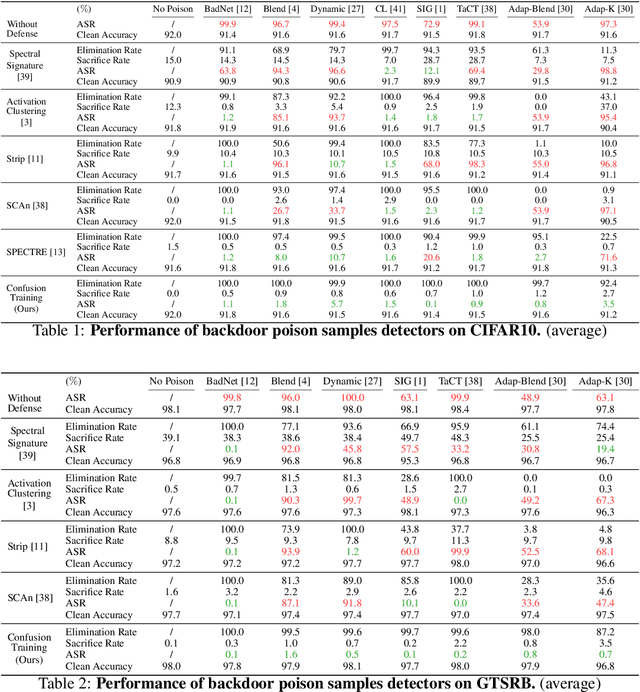
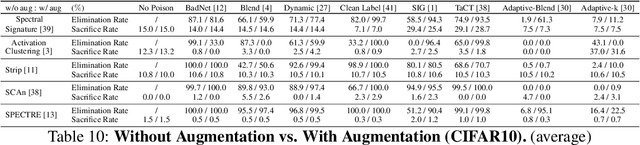
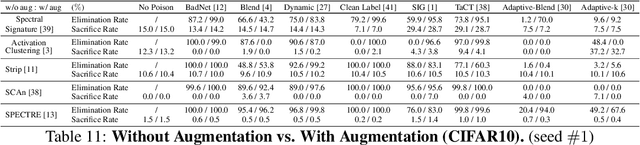
In this work, we study poison samples detection for defending against backdoor poisoning attacks on deep neural networks (DNNs). A principled idea underlying prior arts on this problem is to utilize the backdoored models' distinguishable behaviors on poison and clean populations to distinguish between these two different populations themselves and remove the identified poison. Many prior arts build their detectors upon a latent separability assumption, which states that backdoored models trained on the poisoned dataset will learn separable latent representations for backdoor and clean samples. Although such separation behaviors empirically exist for many existing attacks, there is no control on the separability and the extent of separation can vary a lot across different poison strategies, datasets, as well as the training configurations of backdoored models. Worse still, recent adaptive poison strategies can greatly reduce the "distinguishable behaviors" and consequently render most prior arts less effective (or completely fail). We point out that these limitations directly come from the passive reliance on some distinguishable behaviors that are not controlled by defenders. To mitigate such limitations, in this work, we propose the idea of active defense -- rather than passively assuming backdoored models will have certain distinguishable behaviors on poison and clean samples, we propose to actively enforce the trained models to behave differently on these two different populations. Specifically, we introduce confusion training as a concrete instance of active defense.
Circumventing Backdoor Defenses That Are Based on Latent Separability
May 26, 2022
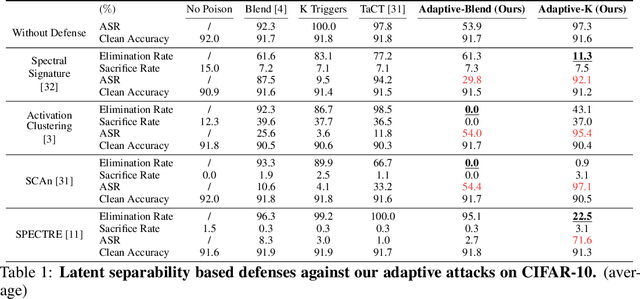
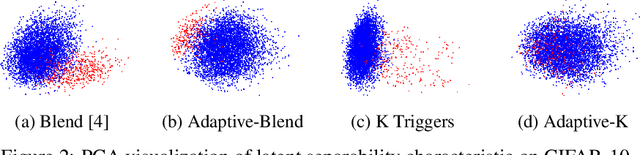
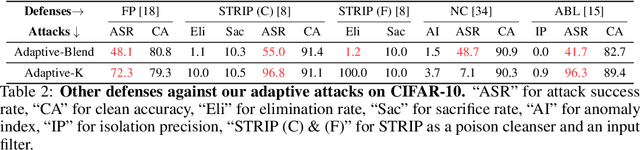
Deep learning models are vulnerable to backdoor poisoning attacks. In particular, adversaries can embed hidden backdoors into a model by only modifying a very small portion of its training data. On the other hand, it has also been commonly observed that backdoor poisoning attacks tend to leave a tangible signature in the latent space of the backdoored model i.e. poison samples and clean samples form two separable clusters in the latent space. These observations give rise to the popularity of latent separability assumption, which states that the backdoored DNN models will learn separable latent representations for poison and clean populations. A number of popular defenses (e.g. Spectral Signature, Activation Clustering, SCAn, etc.) are exactly built upon this assumption. However, in this paper, we show that the latent separation can be significantly suppressed via designing adaptive backdoor poisoning attacks with more sophisticated poison strategies, which consequently render state-of-the-art defenses based on this assumption less effective (and often completely fail). More interestingly, we find that our adaptive attacks can even evade some other typical backdoor defenses that do not explicitly build on this separability assumption. Our results show that adaptive backdoor poisoning attacks that can breach the latent separability assumption should be seriously considered for evaluating existing and future defenses.
Formulating Robustness Against Unforeseen Attacks
Apr 28, 2022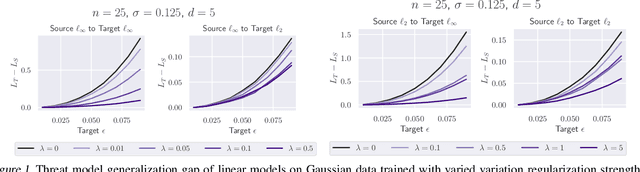
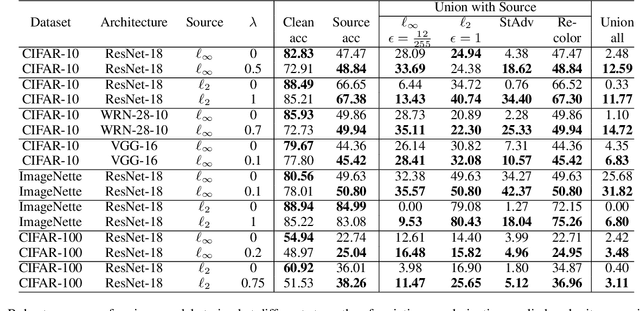
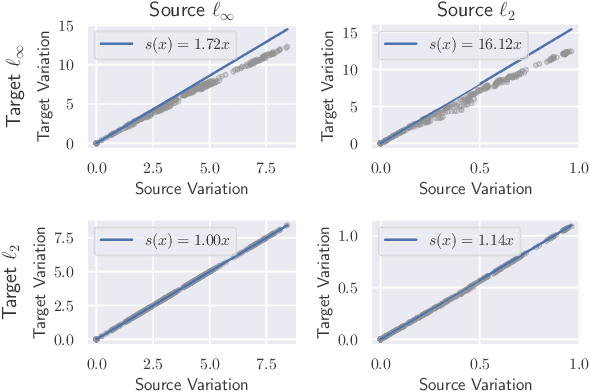
Existing defenses against adversarial examples such as adversarial training typically assume that the adversary will conform to a specific or known threat model, such as $\ell_p$ perturbations within a fixed budget. In this paper, we focus on the scenario where there is a mismatch in the threat model assumed by the defense during training, and the actual capabilities of the adversary at test time. We ask the question: if the learner trains against a specific "source" threat model, when can we expect robustness to generalize to a stronger unknown "target" threat model during test-time? Our key contribution is to formally define the problem of learning and generalization with an unforeseen adversary, which helps us reason about the increase in adversarial risk from the conventional perspective of a known adversary. Applying our framework, we derive a generalization bound which relates the generalization gap between source and target threat models to variation of the feature extractor, which measures the expected maximum difference between extracted features across a given threat model. Based on our generalization bound, we propose adversarial training with variation regularization (AT-VR) which reduces variation of the feature extractor across the source threat model during training. We empirically demonstrate that AT-VR can lead to improved generalization to unforeseen attacks during test-time compared to standard adversarial training on Gaussian and image datasets.
ObjectSeeker: Certifiably Robust Object Detection against Patch Hiding Attacks via Patch-agnostic Masking
Feb 03, 2022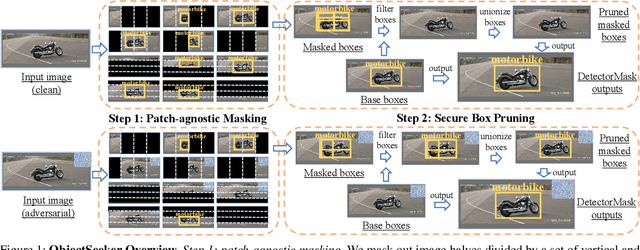
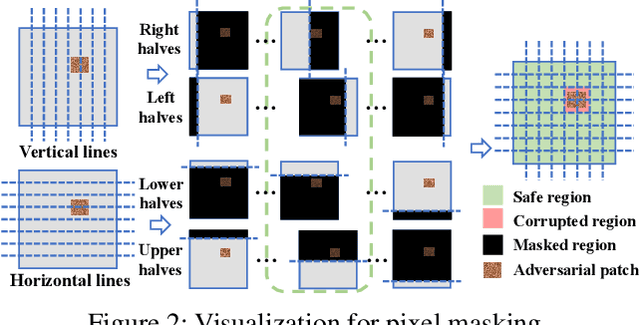
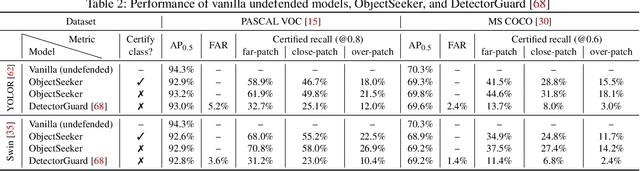
Object detectors, which are widely deployed in security-critical systems such as autonomous vehicles, have been found vulnerable to physical-world patch hiding attacks. The attacker can use a single physically-realizable adversarial patch to make the object detector miss the detection of victim objects and completely undermines the functionality of object detection applications. In this paper, we propose ObjectSeeker as a defense framework for building certifiably robust object detectors against patch hiding attacks. The core operation of ObjectSeeker is patch-agnostic masking: we aim to mask out the entire adversarial patch without any prior knowledge of the shape, size, and location of the patch. This masking operation neutralizes the adversarial effect and allows any vanilla object detector to safely detect objects on the masked images. Remarkably, we develop a certification procedure to determine if ObjectSeeker can detect certain objects with a provable guarantee against any adaptive attacker within the threat model. Our evaluation with two object detectors and three datasets demonstrates a significant (~10%-40% absolute and ~2-6x relative) improvement in certified robustness over the prior work, as well as high clean performance (~1% performance drop compared with vanilla undefended models).
SparseFed: Mitigating Model Poisoning Attacks in Federated Learning with Sparsification
Dec 12, 2021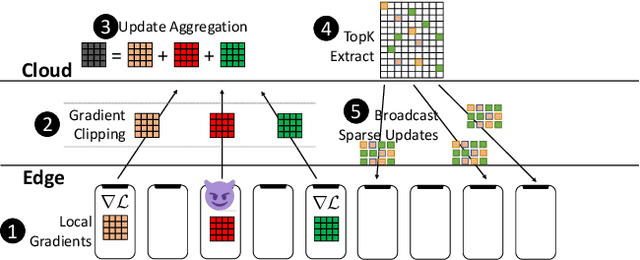
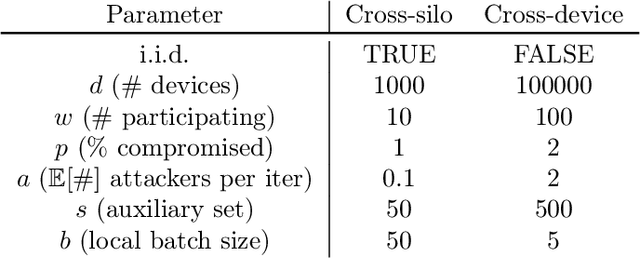
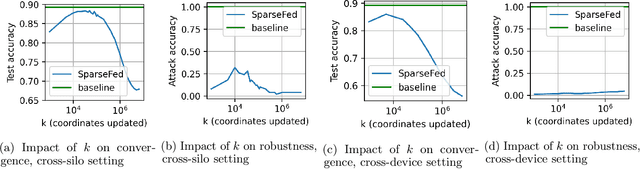

Federated learning is inherently vulnerable to model poisoning attacks because its decentralized nature allows attackers to participate with compromised devices. In model poisoning attacks, the attacker reduces the model's performance on targeted sub-tasks (e.g. classifying planes as birds) by uploading "poisoned" updates. In this report we introduce \algoname{}, a novel defense that uses global top-k update sparsification and device-level gradient clipping to mitigate model poisoning attacks. We propose a theoretical framework for analyzing the robustness of defenses against poisoning attacks, and provide robustness and convergence analysis of our algorithm. To validate its empirical efficacy we conduct an open-source evaluation at scale across multiple benchmark datasets for computer vision and federated learning.
Mitigating Membership Inference Attacks by Self-Distillation Through a Novel Ensemble Architecture
Oct 15, 2021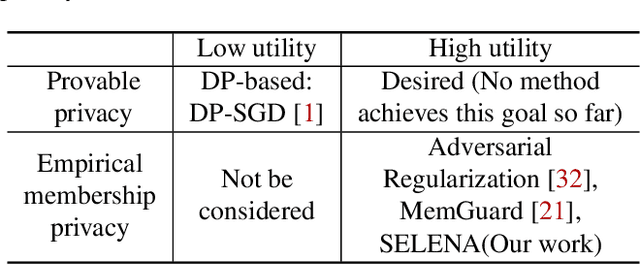

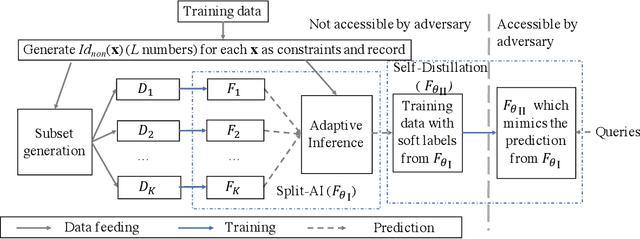
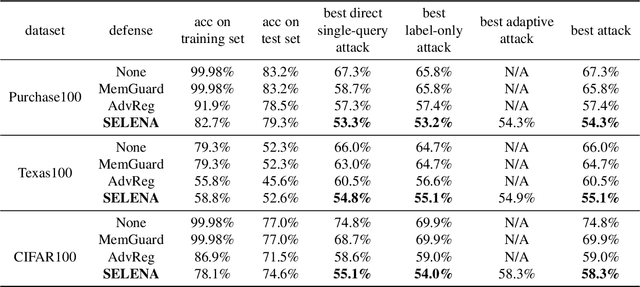
Membership inference attacks are a key measure to evaluate privacy leakage in machine learning (ML) models. These attacks aim to distinguish training members from non-members by exploiting differential behavior of the models on member and non-member inputs. The goal of this work is to train ML models that have high membership privacy while largely preserving their utility; we therefore aim for an empirical membership privacy guarantee as opposed to the provable privacy guarantees provided by techniques like differential privacy, as such techniques are shown to deteriorate model utility. Specifically, we propose a new framework to train privacy-preserving models that induces similar behavior on member and non-member inputs to mitigate membership inference attacks. Our framework, called SELENA, has two major components. The first component and the core of our defense is a novel ensemble architecture for training. This architecture, which we call Split-AI, splits the training data into random subsets, and trains a model on each subset of the data. We use an adaptive inference strategy at test time: our ensemble architecture aggregates the outputs of only those models that did not contain the input sample in their training data. We prove that our Split-AI architecture defends against a large family of membership inference attacks, however, it is susceptible to new adaptive attacks. Therefore, we use a second component in our framework called Self-Distillation to protect against such stronger attacks. The Self-Distillation component (self-)distills the training dataset through our Split-AI ensemble, without using any external public datasets. Through extensive experiments on major benchmark datasets we show that SELENA presents a superior trade-off between membership privacy and utility compared to the state of the art.
Parameterizing Activation Functions for Adversarial Robustness
Oct 11, 2021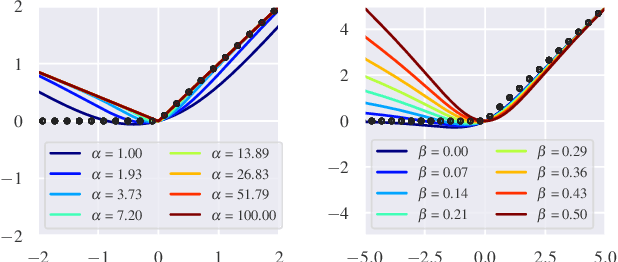
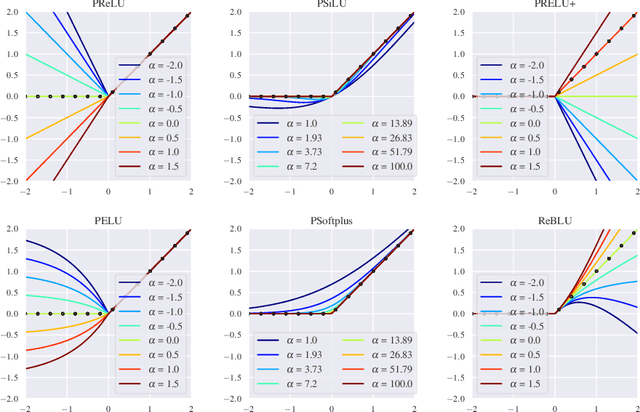
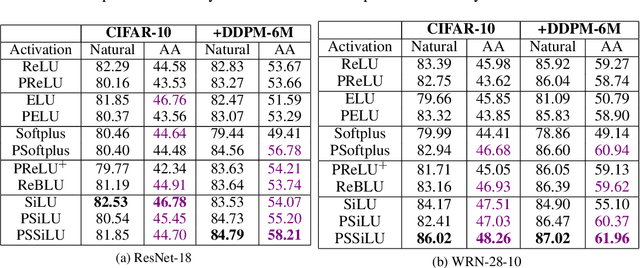
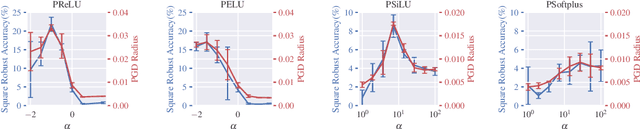
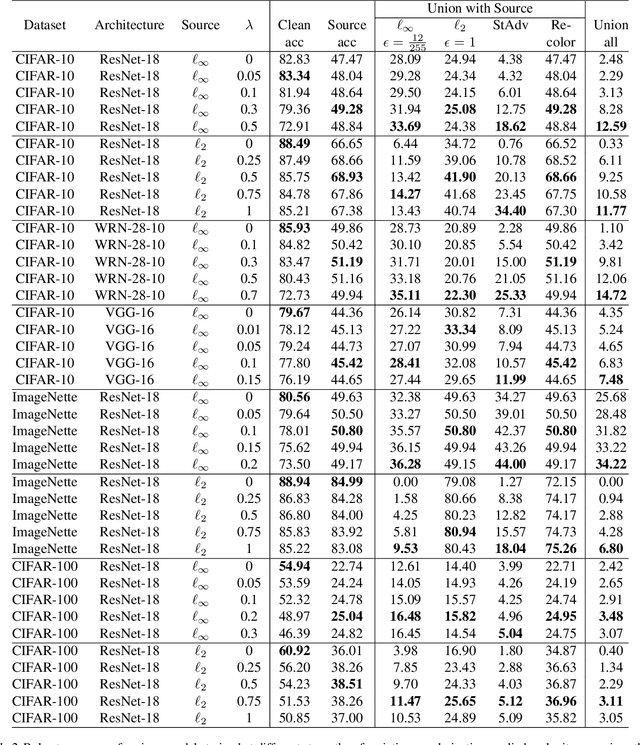
Deep neural networks are known to be vulnerable to adversarially perturbed inputs. A commonly used defense is adversarial training, whose performance is influenced by model capacity. While previous works have studied the impact of varying model width and depth on robustness, the impact of increasing capacity by using learnable parametric activation functions (PAFs) has not been studied. We study how using learnable PAFs can improve robustness in conjunction with adversarial training. We first ask the question: how should we incorporate parameters into activation functions to improve robustness? To address this, we analyze the direct impact of activation shape on robustness through PAFs and observe that activation shapes with positive outputs on negative inputs and with high finite curvature can increase robustness. We combine these properties to create a new PAF, which we call Parametric Shifted Sigmoidal Linear Unit (PSSiLU). We then combine PAFs (including PReLU, PSoftplus and PSSiLU) with adversarial training and analyze robust performance. We find that PAFs optimize towards activation shape properties found to directly affect robustness. Additionally, we find that while introducing only 1-2 learnable parameters into the network, smooth PAFs can significantly increase robustness over ReLU. For instance, when trained on CIFAR-10 with additional synthetic data, PSSiLU improves robust accuracy by 4.54% over ReLU on ResNet-18 and 2.69% over ReLU on WRN-28-10 in the $\ell_{\infty}$ threat model while adding only 2 additional parameters into the network architecture. The PSSiLU WRN-28-10 model achieves 61.96% AutoAttack accuracy, improving over the state-of-the-art robust accuracy on RobustBench (Croce et al., 2020).
PatchCleanser: Certifiably Robust Defense against Adversarial Patches for Any Image Classifier
Aug 20, 2021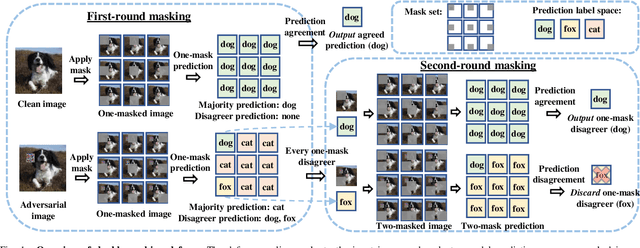
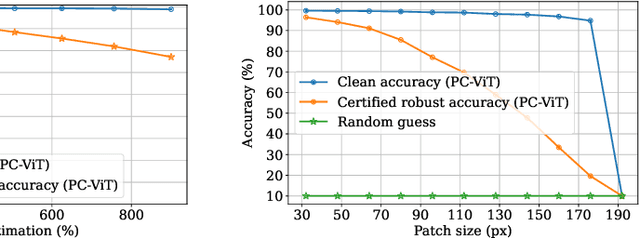
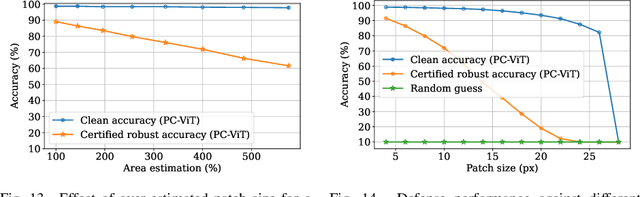
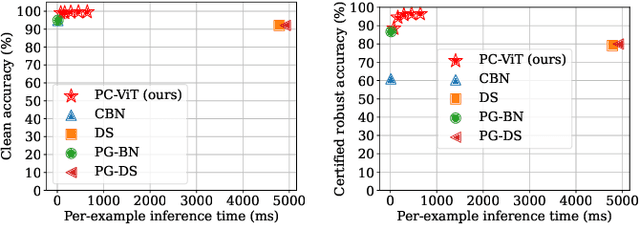
The adversarial patch attack against image classification models aims to inject adversarially crafted pixels within a localized restricted image region (i.e., a patch) for inducing model misclassification. This attack can be realized in the physical world by printing and attaching the patch to the victim object and thus imposes a real-world threat to computer vision systems. To counter this threat, we propose PatchCleanser as a certifiably robust defense against adversarial patches that is compatible with any image classifier. In PatchCleanser, we perform two rounds of pixel masking on the input image to neutralize the effect of the adversarial patch. In the first round of masking, we apply a set of carefully generated masks to the input image and evaluate the model prediction on every masked image. If model predictions on all one-masked images reach a unanimous agreement, we output the agreed prediction label. Otherwise, we perform a second round of masking to settle the disagreement, in which we evaluate model predictions on two-masked images to robustly recover the correct prediction label. Notably, we can prove that our defense will always make correct predictions on certain images against any adaptive white-box attacker within our threat model, achieving certified robustness. We extensively evaluate our defense on the ImageNet, ImageNette, CIFAR-10, CIFAR-100, SVHN, and Flowers-102 datasets and demonstrate that our defense achieves similar clean accuracy as state-of-the-art classification models and also significantly improves certified robustness from prior works. Notably, our defense can achieve 83.8% top-1 clean accuracy and 60.4% top-1 certified robust accuracy against a 2%-pixel square patch anywhere on the 1000-class ImageNet dataset.
PatchGuard++: Efficient Provable Attack Detection against Adversarial Patches
Apr 26, 2021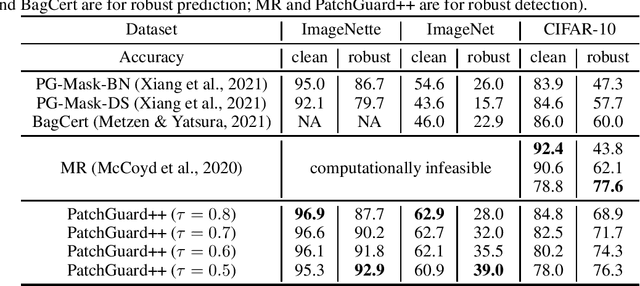
An adversarial patch can arbitrarily manipulate image pixels within a restricted region to induce model misclassification. The threat of this localized attack has gained significant attention because the adversary can mount a physically-realizable attack by attaching patches to the victim object. Recent provably robust defenses generally follow the PatchGuard framework by using CNNs with small receptive fields and secure feature aggregation for robust model predictions. In this paper, we extend PatchGuard to PatchGuard++ for provably detecting the adversarial patch attack to boost both provable robust accuracy and clean accuracy. In PatchGuard++, we first use a CNN with small receptive fields for feature extraction so that the number of features corrupted by the adversarial patch is bounded. Next, we apply masks in the feature space and evaluate predictions on all possible masked feature maps. Finally, we extract a pattern from all masked predictions to catch the adversarial patch attack. We evaluate PatchGuard++ on ImageNette (a 10-class subset of ImageNet), ImageNet, and CIFAR-10 and demonstrate that PatchGuard++ significantly improves the provable robustness and clean performance.