 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Randomized Approach for Tight Privacy Accounting
Apr 17, 2023



Bounding privacy leakage over compositions, i.e., privacy accounting, is a key challenge in differential privacy (DP). However, the privacy parameter ($\varepsilon$ or $\delta$) is often easy to estimate but hard to bound. In this paper, we propose a new differential privacy paradigm called estimate-verify-release (EVR), which addresses the challenges of providing a strict upper bound for privacy parameter in DP compositions by converting an estimate of privacy parameter into a formal guarantee. The EVR paradigm first estimates the privacy parameter of a mechanism, then verifies whether it meets this guarantee, and finally releases the query output based on the verification result. The core component of the EVR is privacy verification. We develop a randomized privacy verifier using Monte Carlo (MC) technique. Furthermore, we propose an MC-based DP accountant that outperforms existing DP accounting techniques in terms of accuracy and efficiency. Our empirical evaluation shows the newly proposed EVR paradigm improves the utility-privacy tradeoff for privacy-preserving machine learning.
Characterizing the Optimal 0-1 Loss for Multi-class Classification with a Test-time Attacker
Feb 21, 2023



Finding classifiers robust to adversarial examples is critical for their safe deployment. Determining the robustness of the best possible classifier under a given threat model for a given data distribution and comparing it to that achieved by state-of-the-art training methods is thus an important diagnostic tool. In this paper, we find achievable information-theoretic lower bounds on loss in the presence of a test-time attacker for multi-class classifiers on any discrete dataset. We provide a general framework for finding the optimal 0-1 loss that revolves around the construction of a conflict hypergraph from the data and adversarial constraints. We further define other variants of the attacker-classifier game that determine the range of the optimal loss more efficiently than the full-fledged hypergraph construction. Our evaluation shows, for the first time, an analysis of the gap to optimal robustness for classifiers in the multi-class setting on benchmark datasets.
MultiRobustBench: Benchmarking Robustness Against Multiple Attacks
Feb 21, 2023



The bulk of existing research in defending against adversarial examples focuses on defending against a single (typically bounded Lp-norm) attack, but for a practical setting, machine learning (ML) models should be robust to a wide variety of attacks. In this paper, we present the first unified framework for considering multiple attacks against ML models. Our framework is able to model different levels of learner's knowledge about the test-time adversary, allowing us to model robustness against unforeseen attacks and robustness against unions of attacks. Using our framework, we present the first leaderboard, MultiRobustBench, for benchmarking multiattack evaluation which captures performance across attack types and attack strengths. We evaluate the performance of 16 defended models for robustness against a set of 9 different attack types, including Lp-based threat models, spatial transformations, and color changes, at 20 different attack strengths (180 attacks total). Additionally, we analyze the state of current defenses against multiple attacks. Our analysis shows that while existing defenses have made progress in terms of average robustness across the set of attacks used, robustness against the worst-case attack is still a big open problem as all existing models perform worse than random guessing.
Uncovering Adversarial Risks of Test-Time Adaptation
Feb 04, 2023



Recently, test-time adaptation (TTA) has been proposed as a promising solution for addressing distribution shifts. It allows a base model to adapt to an unforeseen distribution during inference by leveraging the information from the batch of (unlabeled) test data. However, we uncover a novel security vulnerability of TTA based on the insight that predictions on benign samples can be impacted by malicious samples in the same batch. To exploit this vulnerability, we propose Distribution Invading Attack (DIA), which injects a small fraction of malicious data into the test batch. DIA causes models using TTA to misclassify benign and unperturbed test data, providing an entirely new capability for adversaries that is infeasible in canonical machine learning pipelines. Through comprehensive evaluations, we demonstrate the high effectiveness of our attack on multiple benchmarks across six TTA methods. In response, we investigate two countermeasures to robustify the existing insecure TTA implementations, following the principle of "security by design". Together, we hope our findings can make the community aware of the utility-security tradeoffs in deploying TTA and provide valuable insights for developing robust TTA approaches.
Augmenting Rule-based DNS Censorship Detection at Scale with Machine Learning
Feb 03, 2023



The proliferation of global censorship has led to the development of a plethora of measurement platforms to monitor and expose it. Censorship of the domain name system (DNS) is a key mechanism used across different countries. It is currently detected by applying heuristics to samples of DNS queries and responses (probes) for specific destinations. These heuristics, however, are both platform-specific and have been found to be brittle when censors change their blocking behavior, necessitating a more reliable automated process for detecting censorship. In this paper, we explore how machine learning (ML) models can (1) help streamline the detection process, (2) improve the usability of large-scale datasets for censorship detection, and (3) discover new censorship instances and blocking signatures missed by existing heuristic methods. Our study shows that supervised models, trained using expert-derived labels on instances of known anomalies and possible censorship, can learn the detection heuristics employed by different measurement platforms. More crucially, we find that unsupervised models, trained solely on uncensored instances, can identify new instances and variations of censorship missed by existing heuristics. Moreover, both methods demonstrate the capability to uncover a substantial number of new DNS blocking signatures, i.e., injected fake IP addresses overlooked by existing heuristics. These results are underpinned by an important methodological finding: comparing the outputs of models trained using the same probes but with labels arising from independent processes allows us to more reliably detect cases of censorship in the absence of ground-truth labels of censorship.
DP-RAFT: A Differentially Private Recipe for Accelerated Fine-Tuning
Dec 15, 2022A major direction in differentially private machine learning is differentially private fine-tuning: pretraining a model on a source of "public data" and transferring the extracted features to downstream tasks. This is an important setting because many industry deployments fine-tune publicly available feature extractors on proprietary data for downstream tasks. In this paper, we carefully integrate techniques, both new and from prior work, to solve benchmark tasks in computer vision and natural language processing using differentially private fine-tuning. Our key insight is that by accelerating training with the choice of key hyperparameters, we can quickly drive the model parameters to regions in parameter space where the impact of noise is minimized. We obtain new state-of-the art performance on CIFAR10, CIFAR100, FashionMNIST, STL10, and PersonaChat, including $99 \%$ on CIFAR10 for $\varepsilon=1, \delta=1e-5$-DP.
Renyi Differential Privacy of Propose-Test-Release and Applications to Private and Robust Machine Learning
Sep 16, 2022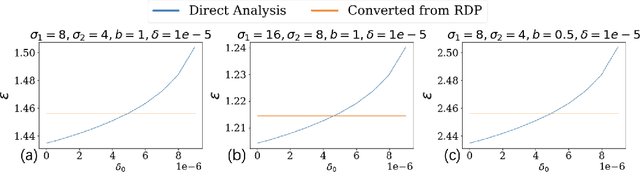
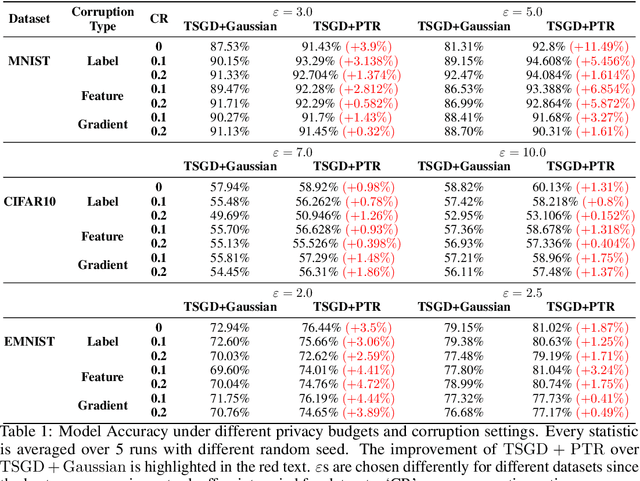
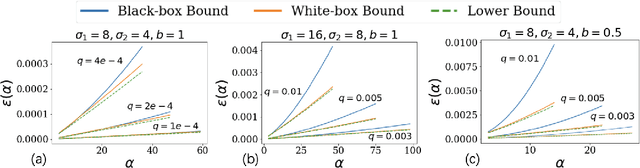
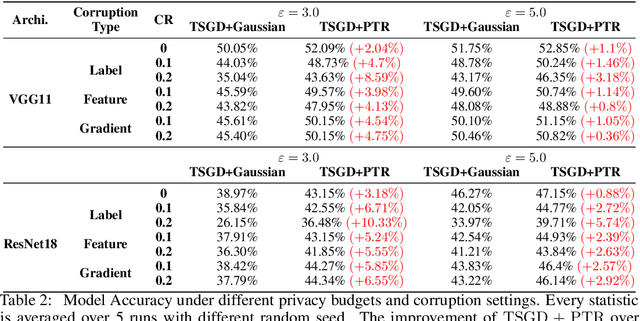
Propose-Test-Release (PTR) is a differential privacy framework that works with local sensitivity of functions, instead of their global sensitivity. This framework is typically used for releasing robust statistics such as median or trimmed mean in a differentially private manner. While PTR is a common framework introduced over a decade ago, using it in applications such as robust SGD where we need many adaptive robust queries is challenging. This is mainly due to the lack of Renyi Differential Privacy (RDP) analysis, an essential ingredient underlying the moments accountant approach for differentially private deep learning. In this work, we generalize the standard PTR and derive the first RDP bound for it when the target function has bounded global sensitivity. We show that our RDP bound for PTR yields tighter DP guarantees than the directly analyzed $(\eps, \delta)$-DP. We also derive the algorithm-specific privacy amplification bound of PTR under subsampling. We show that our bound is much tighter than the general upper bound and close to the lower bound. Our RDP bounds enable tighter privacy loss calculation for the composition of many adaptive runs of PTR. As an application of our analysis, we show that PTR and our theoretical results can be used to design differentially private variants for byzantine robust training algorithms that use robust statistics for gradients aggregation. We conduct experiments on the settings of label, feature, and gradient corruption across different datasets and architectures. We show that PTR-based private and robust training algorithm significantly improves the utility compared with the baseline.
A Light Recipe to Train Robust Vision Transformers
Sep 15, 2022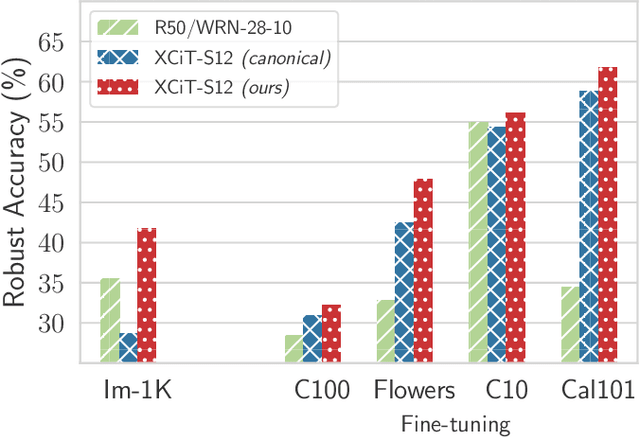


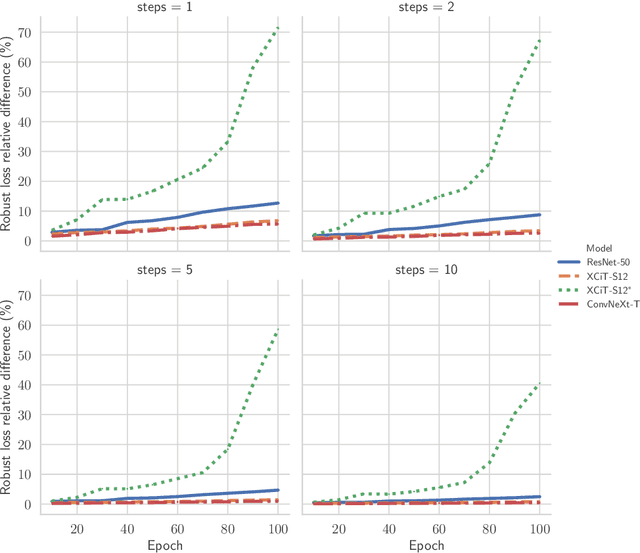
In this paper, we ask whether Vision Transformers (ViTs) can serve as an underlying architecture for improving the adversarial robustness of machine learning models against evasion attacks. While earlier works have focused on improving Convolutional Neural Networks, we show that also ViTs are highly suitable for adversarial training to achieve competitive performance. We achieve this objective using a custom adversarial training recipe, discovered using rigorous ablation studies on a subset of the ImageNet dataset. The canonical training recipe for ViTs recommends strong data augmentation, in part to compensate for the lack of vision inductive bias of attention modules, when compared to convolutions. We show that this recipe achieves suboptimal performance when used for adversarial training. In contrast, we find that omitting all heavy data augmentation, and adding some additional bag-of-tricks ($\varepsilon$-warmup and larger weight decay), significantly boosts the performance of robust ViTs. We show that our recipe generalizes to different classes of ViT architectures and large-scale models on full ImageNet-1k. Additionally, investigating the reasons for the robustness of our models, we show that it is easier to generate strong attacks during training when using our recipe and that this leads to better robustness at test time. Finally, we further study one consequence of adversarial training by proposing a way to quantify the semantic nature of adversarial perturbations and highlight its correlation with the robustness of the model. Overall, we recommend that the community should avoid translating the canonical training recipes in ViTs to robust training and rethink common training choices in the context of adversarial training.
Just Rotate it: Deploying Backdoor Attacks via Rotation Transformation
Jul 22, 2022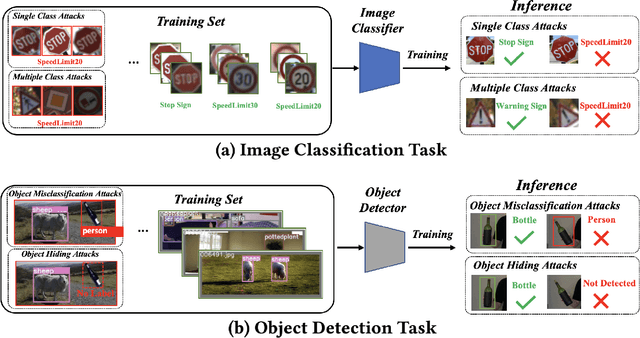
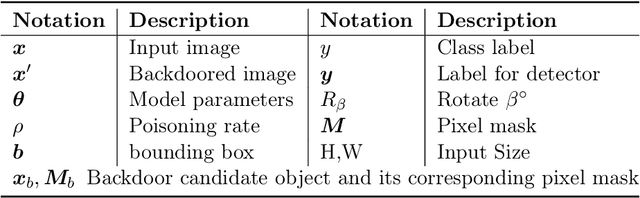
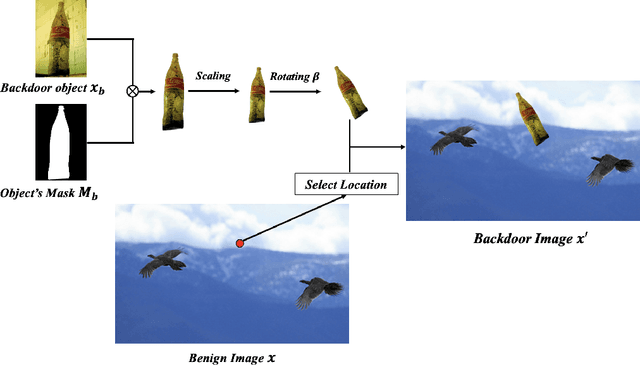
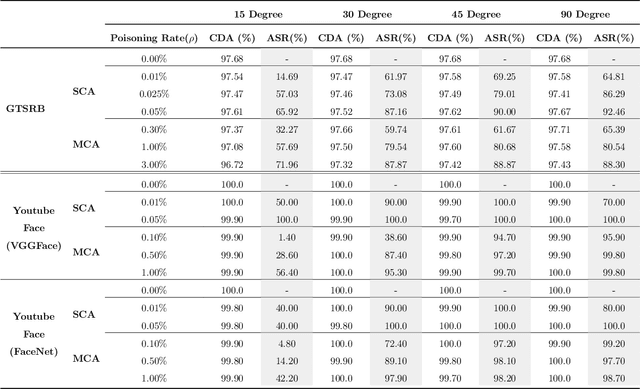
Recent works have demonstrated that deep learning models are vulnerable to backdoor poisoning attacks, where these attacks instill spurious correlations to external trigger patterns or objects (e.g., stickers, sunglasses, etc.). We find that such external trigger signals are unnecessary, as highly effective backdoors can be easily inserted using rotation-based image transformation. Our method constructs the poisoned dataset by rotating a limited amount of objects and labeling them incorrectly; once trained with it, the victim's model will make undesirable predictions during run-time inference. It exhibits a significantly high attack success rate while maintaining clean performance through comprehensive empirical studies on image classification and object detection tasks. Furthermore, we evaluate standard data augmentation techniques and four different backdoor defenses against our attack and find that none of them can serve as a consistent mitigation approach. Our attack can be easily deployed in the real world since it only requires rotating the object, as we show in both image classification and object detection applications. Overall, our work highlights a new, simple, physically realizable, and highly effective vector for backdoor attacks. Our video demo is available at https://youtu.be/6JIF8wnX34M.
Understanding Robust Learning through the Lens of Representation Similarities
Jun 20, 2022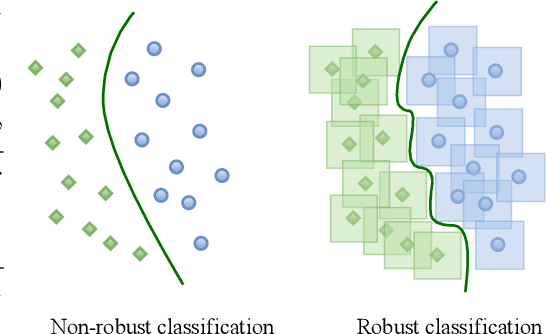
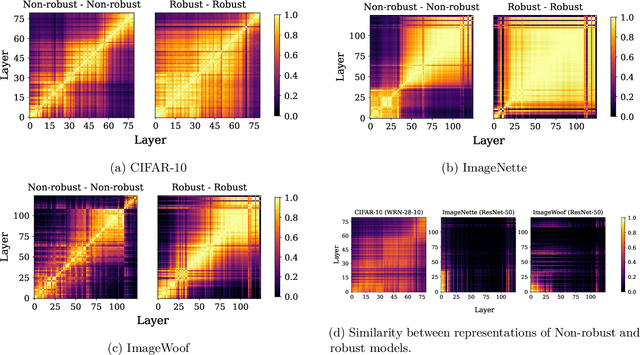
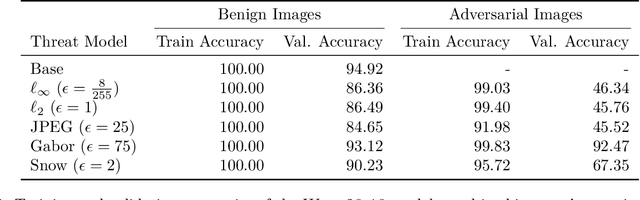
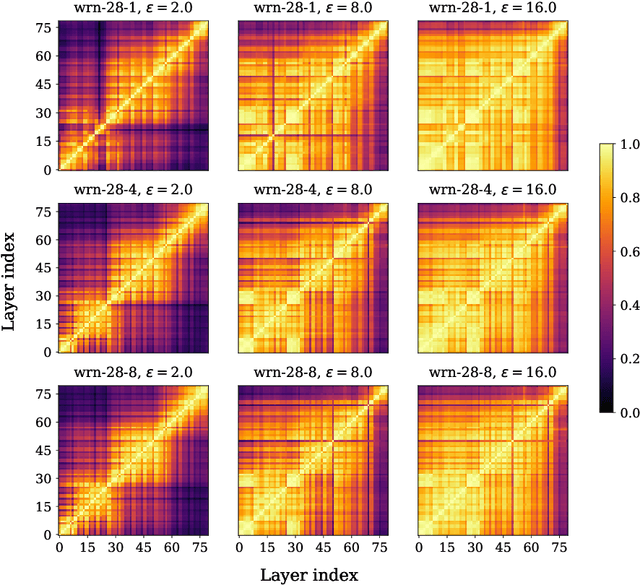
Representation learning, i.e. the generation of representations useful for downstream applications, is a task of fundamental importance that underlies much of the success of deep neural networks (DNNs). Recently, robustness to adversarial examples has emerged as a desirable property for DNNs, spurring the development of robust training methods that account for adversarial examples. In this paper, we aim to understand how the properties of representations learned by robust training differ from those obtained from standard, non-robust training. This is critical to diagnosing numerous salient pitfalls in robust networks, such as, degradation of performance on benign inputs, poor generalization of robustness, and increase in over-fitting. We utilize a powerful set of tools known as representation similarity metrics, across three vision datasets, to obtain layer-wise comparisons between robust and non-robust DNNs with different architectures, training procedures and adversarial constraints. Our experiments highlight hitherto unseen properties of robust representations that we posit underlie the behavioral differences of robust networks. We discover a lack of specialization in robust networks' representations along with a disappearance of `block structure'. We also find overfitting during robust training largely impacts deeper layers. These, along with other findings, suggest ways forward for the design and training of better robust networks.