 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Quantum Algorithms for Chemical Simulation and Drug Discovery
Nov 15, 2022



Quantum computing has gained a lot of attention recently, and scientists have seen potential applications in this field using quantum computing for Cryptography and Communication to Machine Learning and Healthcare. Protein folding has been one of the most interesting areas to study, and it is also one of the biggest problems of biochemistry. Each protein folds distinctively, and the difficulty of finding its stable shape rapidly increases with an increase in the number of amino acids in the chain. A moderate protein has about 100 amino acids, and the number of combinations one needs to verify to find the stable structure is enormous. At some point, the number of these combinations will be so vast that classical computers cannot even attempt to solve them. In this paper, we examine how this problem can be solved with the help of quantum computing using two different algorithms, Variational Quantum Eigensolver (VQE) and Quantum Approximate Optimization Algorithm (QAOA), using Qiskit Nature. We compare the results of different quantum hardware and simulators and check how error mitigation affects the performance. Further, we make comparisons with SoTA algorithms and evaluate the reliability of the method.
Multi-User Reinforcement Learning with Low Rank Rewards
Oct 11, 2022In this work, we consider the problem of collaborative multi-user reinforcement learning. In this setting there are multiple users with the same state-action space and transition probabilities but with different rewards. Under the assumption that the reward matrix of the $N$ users has a low-rank structure -- a standard and practically successful assumption in the offline collaborative filtering setting -- the question is can we design algorithms with significantly lower sample complexity compared to the ones that learn the MDP individually for each user. Our main contribution is an algorithm which explores rewards collaboratively with $N$ user-specific MDPs and can learn rewards efficiently in two key settings: tabular MDPs and linear MDPs. When $N$ is large and the rank is constant, the sample complexity per MDP depends logarithmically over the size of the state-space, which represents an exponential reduction (in the state-space size) when compared to the standard ``non-collaborative'' algorithms.
Private and Efficient Meta-Learning with Low Rank and Sparse Decomposition
Oct 07, 2022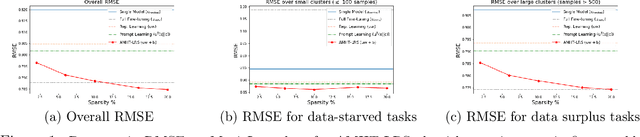
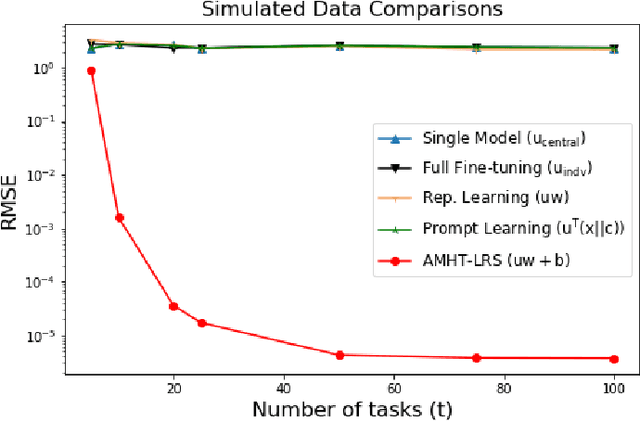
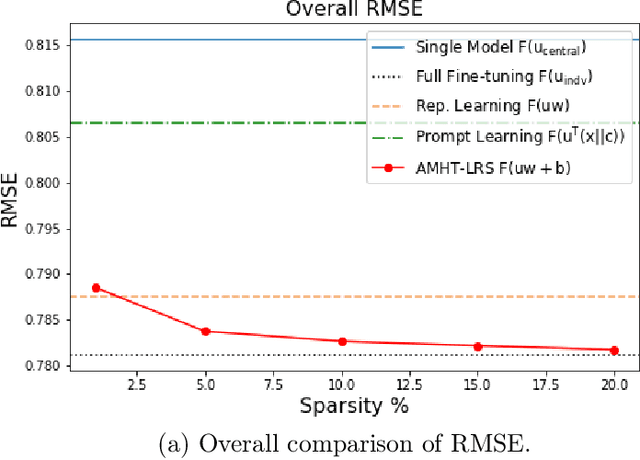
Meta-learning is critical for a variety of practical ML systems -- like personalized recommendations systems -- that are required to generalize to new tasks despite a small number of task-specific training points. Existing meta-learning techniques use two complementary approaches of either learning a low-dimensional representation of points for all tasks, or task-specific fine-tuning of a global model trained using all the tasks. In this work, we propose a novel meta-learning framework that combines both the techniques to enable handling of a large number of data-starved tasks. Our framework models network weights as a sum of low-rank and sparse matrices. This allows us to capture information from multiple domains together in the low-rank part while still allowing task specific personalization using the sparse part. We instantiate and study the framework in the linear setting, where the problem reduces to that of estimating the sum of a rank-$r$ and a $k$-column sparse matrix using a small number of linear measurements. We propose an alternating minimization method with hard thresholding -- AMHT-LRS -- to learn the low-rank and sparse part effectively and efficiently. For the realizable, Gaussian data setting, we show that AMHT-LRS indeed solves the problem efficiently with nearly optimal samples. We extend AMHT-LRS to ensure that it preserves privacy of each individual user in the dataset, while still ensuring strong generalization with nearly optimal number of samples. Finally, on multiple datasets, we demonstrate that the framework allows personalized models to obtain superior performance in the data-scarce regime.
Learning an Invertible Output Mapping Can Mitigate Simplicity Bias in Neural Networks
Oct 04, 2022
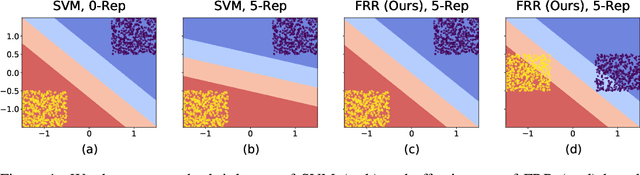
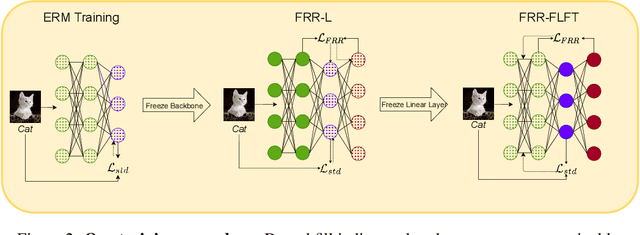
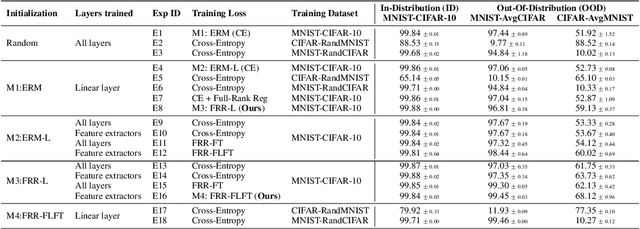
Deep Neural Networks are known to be brittle to even minor distribution shifts compared to the training distribution. While one line of work has demonstrated that Simplicity Bias (SB) of DNNs - bias towards learning only the simplest features - is a key reason for this brittleness, another recent line of work has surprisingly found that diverse/ complex features are indeed learned by the backbone, and their brittleness is due to the linear classification head relying primarily on the simplest features. To bridge the gap between these two lines of work, we first hypothesize and verify that while SB may not altogether preclude learning complex features, it amplifies simpler features over complex ones. Namely, simple features are replicated several times in the learned representations while complex features might not be replicated. This phenomenon, we term Feature Replication Hypothesis, coupled with the Implicit Bias of SGD to converge to maximum margin solutions in the feature space, leads the models to rely mostly on the simple features for classification. To mitigate this bias, we propose Feature Reconstruction Regularizer (FRR) to ensure that the learned features can be reconstructed back from the logits. The use of {\em FRR} in linear layer training (FRR-L) encourages the use of more diverse features for classification. We further propose to finetune the full network by freezing the weights of the linear layer trained using FRR-L, to refine the learned features, making them more suitable for classification. Using this simple solution, we demonstrate up to 15% gains in OOD accuracy on the recently introduced semi-synthetic datasets with extreme distribution shifts. Moreover, we demonstrate noteworthy gains over existing SOTA methods on the standard OOD benchmark DomainBed as well.
Online Low Rank Matrix Completion
Sep 08, 2022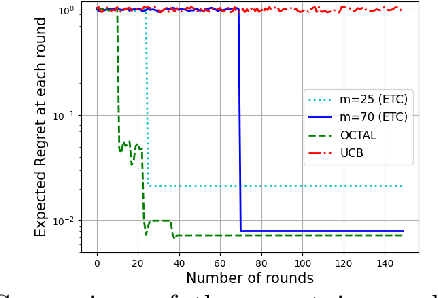
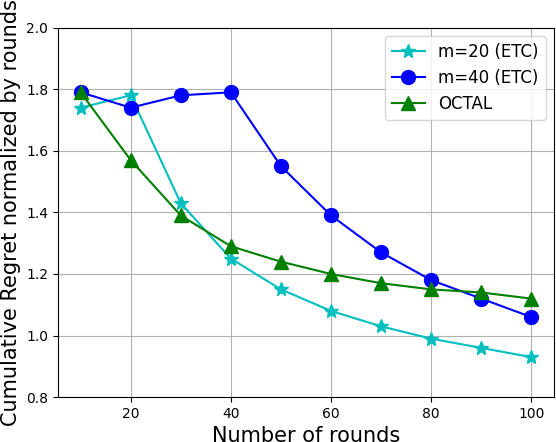
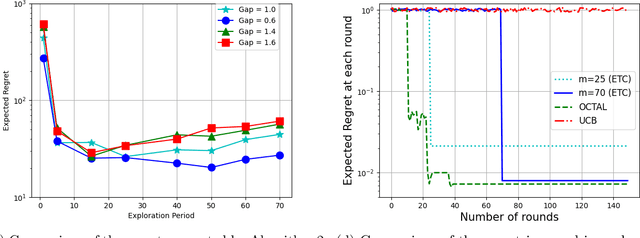
We study the problem of \textit{online} low-rank matrix completion with $\mathsf{M}$ users, $\mathsf{N}$ items and $\mathsf{T}$ rounds. In each round, we recommend one item per user. For each recommendation, we obtain a (noisy) reward sampled from a low-rank user-item reward matrix. The goal is to design an online method with sub-linear regret (in $\mathsf{T}$). While the problem can be mapped to the standard multi-armed bandit problem where each item is an \textit{independent} arm, it leads to poor regret as the correlation between arms and users is not exploited. In contrast, exploiting the low-rank structure of reward matrix is challenging due to non-convexity of low-rank manifold. We overcome this challenge using an explore-then-commit (ETC) approach that ensures a regret of $O(\mathsf{polylog} (\mathsf{M}+\mathsf{N}) \mathsf{T}^{2/3})$. That is, roughly only $\mathsf{polylog} (\mathsf{M}+\mathsf{N})$ item recommendations are required per user to get non-trivial solution. We further improve our result for the rank-$1$ setting. Here, we propose a novel algorithm OCTAL (Online Collaborative filTering using iterAtive user cLustering) that ensures nearly optimal regret bound of $O(\mathsf{polylog} (\mathsf{M}+\mathsf{N}) \mathsf{T}^{1/2})$. Our algorithm uses a novel technique of clustering users and eliminating items jointly and iteratively, which allows us to obtain nearly minimax optimal rate in $\mathsf{T}$.
Surya Namaskar: real-time advanced yoga pose recognition and correction for smart healthcare
Sep 06, 2022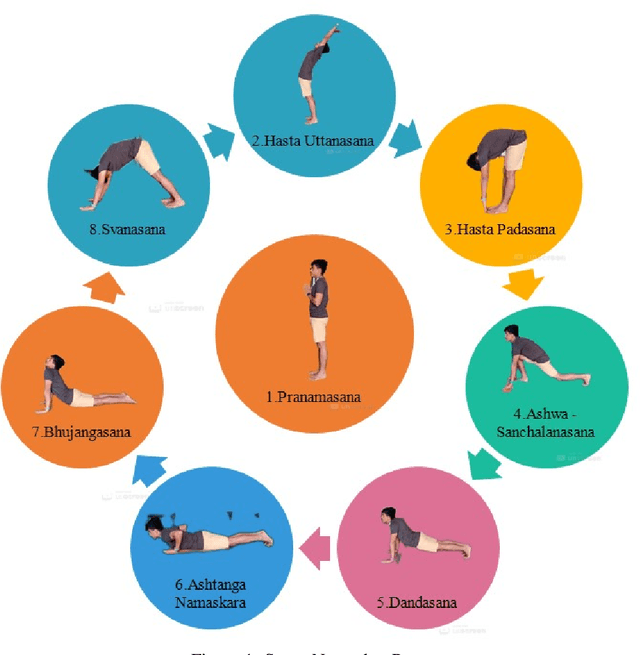
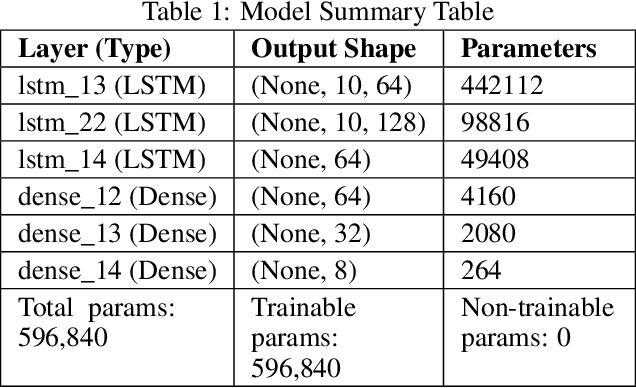
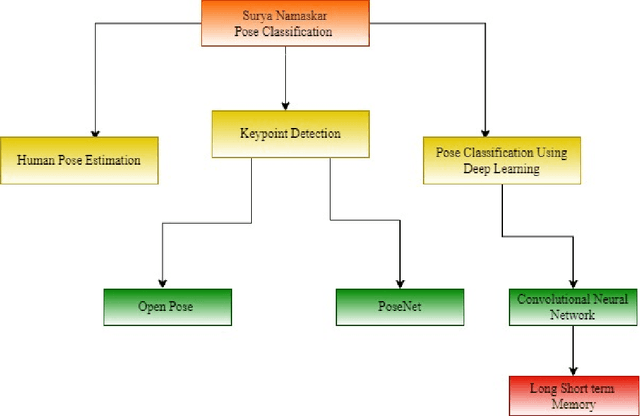
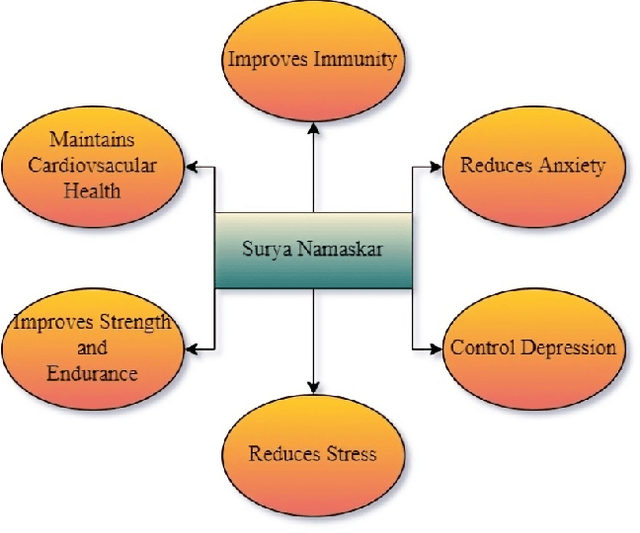
Nowadays, yoga has gained worldwide attention because of increasing levels of stress in the modern way of life, and there are many ways or resources to learn yoga. The word yoga means a deep connection between the mind and body. Today there is substantial Medical and scientific evidence to show that the very fundamentals of the activity of our brain, our chemistry even our genetic content can be changed by practicing different systems of yoga. Suryanamaskar, also known as salute to the sun, is a yoga practice that combines eight different forms and 12 asanas(4 asana get repeated) devoted to the Hindu Sun God, Surya. Suryanamaskar offers a number of health benefits such as strengthening muscles and helping to control blood sugar levels. Here the Mediapipe Library is used to analyze Surya namaskar situations. Standing is detected in real time with advanced software, as one performs Surya namaskar in front of the camera. The class divider identifies the form as one of the following: Pranamasana, Hasta Padasana, Hasta Uttanasana, Ashwa - Sanchalan asana, Ashtanga Namaskar, Dandasana, or Bhujangasana and Svanasana. Deep learning-based techniques(CNN) are used to develop this model with model accuracy of 98.68 percent and an accuracy score of 0.75 to detect correct yoga (Surya Namaskar ) posture. With this method, the users can practice the desired pose and can check if the pose that the person is doing is correct or not. It will help in doing all the different poses of surya namaskar correctly and increase the efficiency of the yoga practitioner. This paper describes the whole framework which is to be implemented in the model.
DAFT: Distilling Adversarially Fine-tuned Models for Better OOD Generalization
Aug 19, 2022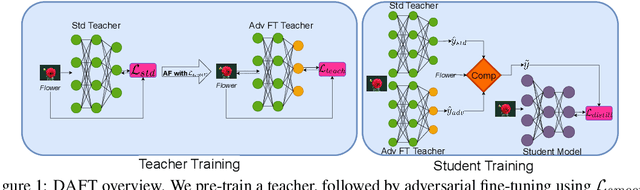
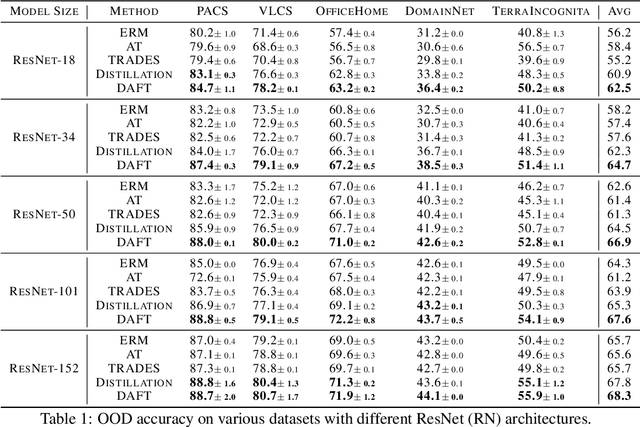
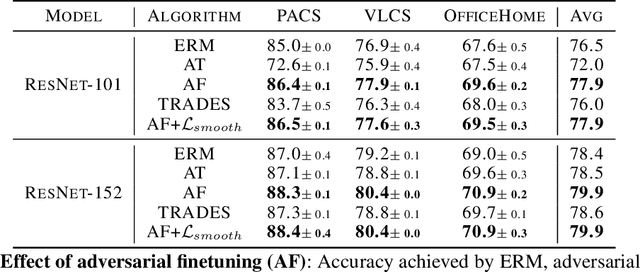
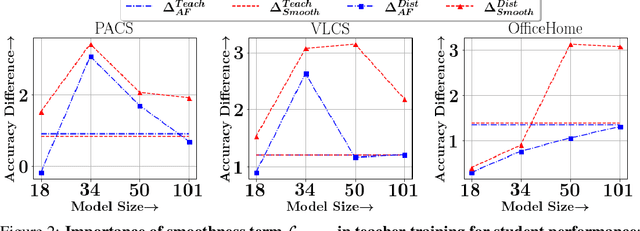
We consider the problem of OOD generalization, where the goal is to train a model that performs well on test distributions that are different from the training distribution. Deep learning models are known to be fragile to such shifts and can suffer large accuracy drops even for slightly different test distributions. We propose a new method - DAFT - based on the intuition that adversarially robust combination of a large number of rich features should provide OOD robustness. Our method carefully distills the knowledge from a powerful teacher that learns several discriminative features using standard training while combining them using adversarial training. The standard adversarial training procedure is modified to produce teachers which can guide the student better. We evaluate DAFT on standard benchmarks in the DomainBed framework, and demonstrate that DAFT achieves significant improvements over the current state-of-the-art OOD generalization methods. DAFT consistently out-performs well-tuned ERM and distillation baselines by up to 6%, with more pronounced gains for smaller networks.
Treeformer: Dense Gradient Trees for Efficient Attention Computation
Aug 18, 2022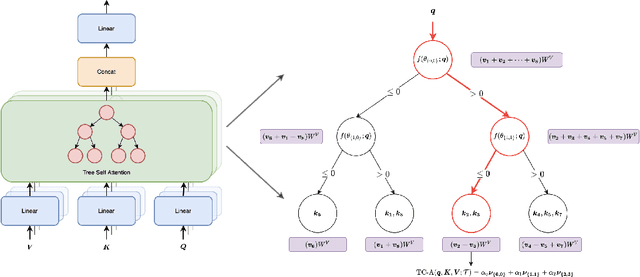
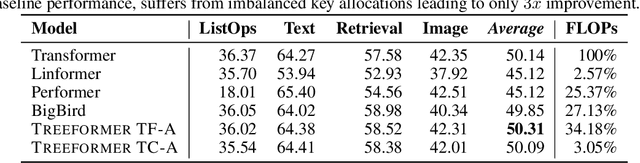
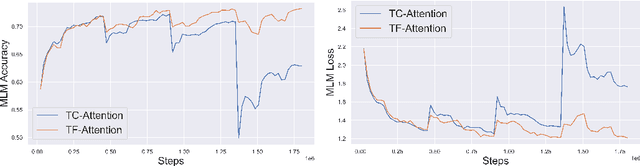
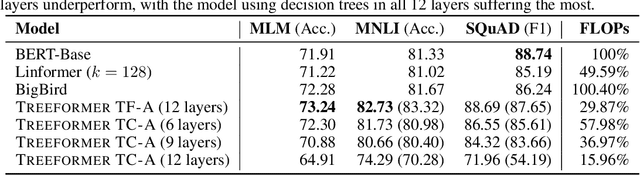
Standard inference and training with transformer based architectures scale quadratically with input sequence length. This is prohibitively large for a variety of applications especially in web-page translation, query-answering etc. Consequently, several approaches have been developed recently to speedup attention computation by enforcing different attention structures such as sparsity, low-rank, approximating attention using kernels. In this work, we view attention computation as that of nearest neighbor retrieval, and use decision tree based hierarchical navigation to reduce the retrieval cost per query token from linear in sequence length to nearly logarithmic. Based on such hierarchical navigation, we design Treeformer which can use one of two efficient attention layers -- TF-Attention and TC-Attention. TF-Attention computes the attention in a fine-grained style, while TC-Attention is a coarse attention layer which also ensures that the gradients are "dense". To optimize such challenging discrete layers, we propose a two-level bootstrapped training method. Using extensive experiments on standard NLP benchmarks, especially for long-sequences, we demonstrate that our Treeformer architecture can be almost as accurate as baseline Transformer while using 30x lesser FLOPs in the attention layer. Compared to Linformer, the accuracy can be as much as 12% higher while using similar FLOPs in the attention layer.
(Nearly) Optimal Private Linear Regression via Adaptive Clipping
Jul 12, 2022We study the problem of differentially private linear regression where each data point is sampled from a fixed sub-Gaussian style distribution. We propose and analyze a one-pass mini-batch stochastic gradient descent method (DP-AMBSSGD) where points in each iteration are sampled without replacement. Noise is added for DP but the noise standard deviation is estimated online. Compared to existing $(\epsilon, \delta)$-DP techniques which have sub-optimal error bounds, DP-AMBSSGD is able to provide nearly optimal error bounds in terms of key parameters like dimensionality $d$, number of points $N$, and the standard deviation $\sigma$ of the noise in observations. For example, when the $d$-dimensional covariates are sampled i.i.d. from the normal distribution, then the excess error of DP-AMBSSGD due to privacy is $\frac{\sigma^2 d}{N}(1+\frac{d}{\epsilon^2 N})$, i.e., the error is meaningful when number of samples $N= \Omega(d \log d)$ which is the standard operative regime for linear regression. In contrast, error bounds for existing efficient methods in this setting are: $\mathcal{O}\big(\frac{d^3}{\epsilon^2 N^2}\big)$, even for $\sigma=0$. That is, for constant $\epsilon$, the existing techniques require $N=\Omega(d\sqrt{d})$ to provide a non-trivial result.
MET: Masked Encoding for Tabular Data
Jun 17, 2022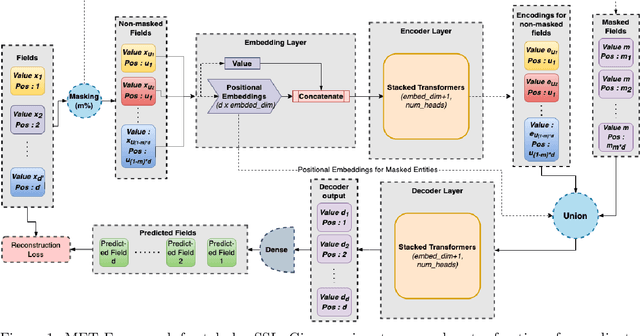
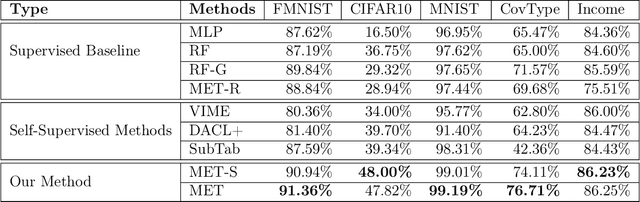
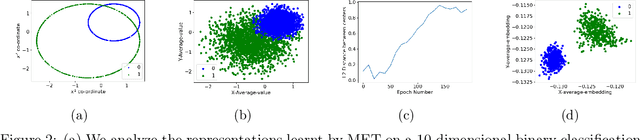

We consider the task of self-supervised representation learning (SSL) for tabular data: tabular-SSL. Typical contrastive learning based SSL methods require instance-wise data augmentations which are difficult to design for unstructured tabular data. Existing tabular-SSL methods design such augmentations in a relatively ad-hoc fashion and can fail to capture the underlying data manifold. Instead of augmentations based approaches for tabular-SSL, we propose a new reconstruction based method, called Masked Encoding for Tabular Data (MET), that does not require augmentations. MET is based on the popular MAE approach for vision-SSL [He et al., 2021] and uses two key ideas: (i) since each coordinate in a tabular dataset has a distinct meaning, we need to use separate representations for all coordinates, and (ii) using an adversarial reconstruction loss in addition to the standard one. Empirical results on five diverse tabular datasets show that MET achieves a new state of the art (SOTA) on all of these datasets and improves up to 9% over current SOTA methods. We shed more light on the working of MET via experiments on carefully designed simple datasets.