 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD2CoPlan: A Differentiable Decentralized Planner for Multi-Robot Coverage
Sep 19, 2022
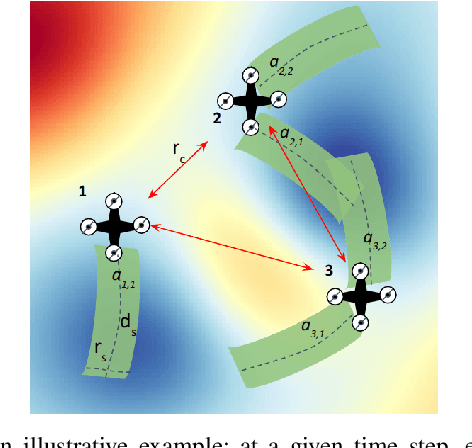
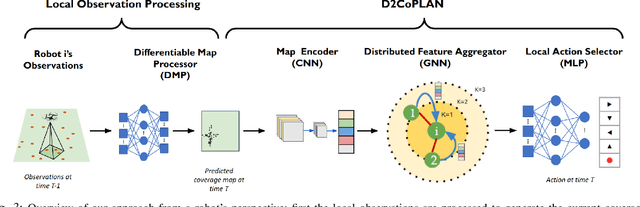
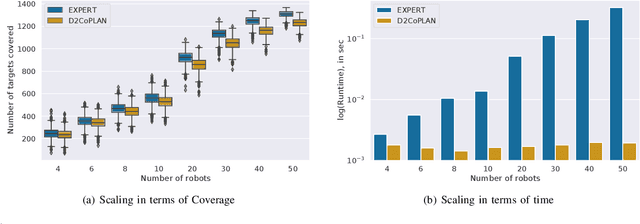
Centralized approaches for multi-robot coverage planning problems suffer from the lack of scalability. Learning-based distributed algorithms provide a scalable avenue in addition to bringing data-oriented feature generation capabilities to the table, allowing integration with other learning-based approaches. To this end, we present a learning-based, differentiable distributed coverage planner (D2COPL A N) which scales efficiently in runtime and number of agents compared to the expert algorithm, and performs on par with the classical distributed algorithm. In addition, we show that D2COPlan can be seamlessly combined with other learning methods to learn end-to-end, resulting in a better solution than the individually trained modules, opening doors to further research for tasks that remain elusive with classical methods.
Risk-aware Resource Allocation for Multiple UAVs-UGVs Recharging Rendezvous
Sep 13, 2022
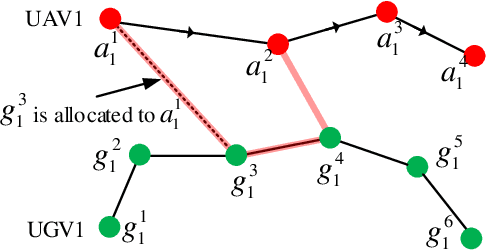
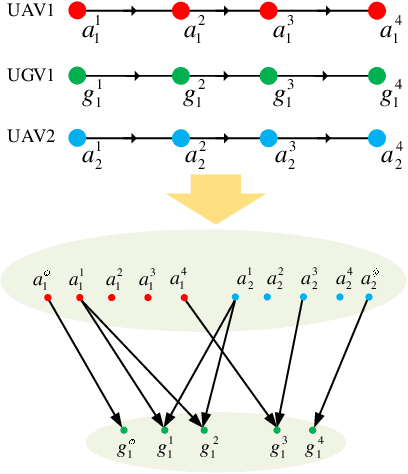
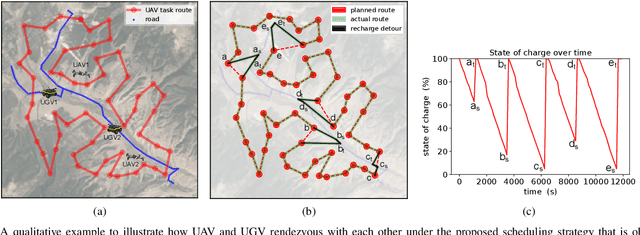
We study a resource allocation problem for the cooperative aerial-ground vehicle routing application, in which multiple Unmanned Aerial Vehicles (UAVs) with limited battery capacity and multiple Unmanned Ground Vehicles (UGVs) that can also act as a mobile recharging stations need to jointly accomplish a mission such as persistently monitoring a set of points. Due to the limited battery capacity of the UAVs, they sometimes have to deviate from their task to rendezvous with the UGVs and get recharged. Each UGV can serve a limited number of UAVs at a time. In contrast to prior work on deterministic multi-robot scheduling, we consider the challenge imposed by the stochasticity of the energy consumption of the UAV. We are interested in finding the optimal recharging schedule of the UAVs such that the travel cost is minimized and the probability that no UAV runs out of charge within the planning horizon is greater than a user-defined tolerance. We formulate this problem ({Risk-aware Recharging Rendezvous Problem (RRRP))} as an Integer Linear Program (ILP), in which the matching constraint captures the resource availability constraints and the knapsack constraint captures the success probability constraints. We propose a bicriteria approximation algorithm to solve RRRP. We demonstrate the effectiveness of our formulation and algorithm in the context of one persistent monitoring mission.
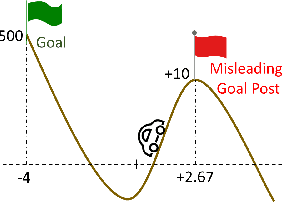
Dealing with Sparse Rewards in Continuous Control Robotics via Heavy-Tailed Policies
Jun 12, 2022
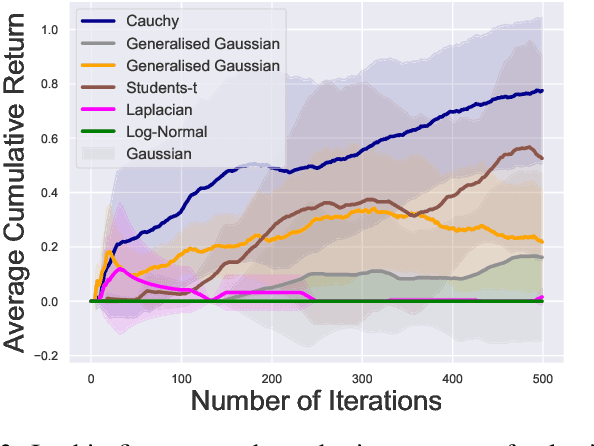
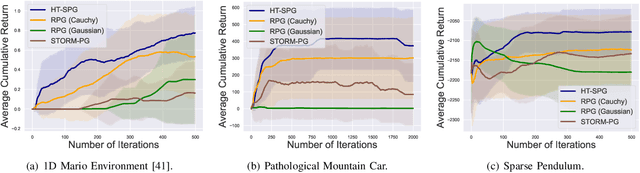
In this paper, we present a novel Heavy-Tailed Stochastic Policy Gradient (HT-PSG) algorithm to deal with the challenges of sparse rewards in continuous control problems. Sparse reward is common in continuous control robotics tasks such as manipulation and navigation, and makes the learning problem hard due to non-trivial estimation of value functions over the state space. This demands either reward shaping or expert demonstrations for the sparse reward environment. However, obtaining high-quality demonstrations is quite expensive and sometimes even impossible. We propose a heavy-tailed policy parametrization along with a modified momentum-based policy gradient tracking scheme (HT-SPG) to induce a stable exploratory behavior to the algorithm. The proposed algorithm does not require access to expert demonstrations. We test the performance of HT-SPG on various benchmark tasks of continuous control with sparse rewards such as 1D Mario, Pathological Mountain Car, Sparse Pendulum in OpenAI Gym, and Sparse MuJoCo environments (Hopper-v2). We show consistent performance improvement across all tasks in terms of high average cumulative reward. HT-SPG also demonstrates improved convergence speed with minimum samples, thereby emphasizing the sample efficiency of our proposed algorithm.
Posterior Coreset Construction with Kernelized Stein Discrepancy for Model-Based Reinforcement Learning
Jun 02, 2022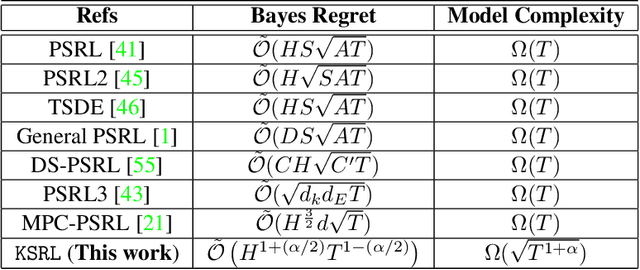
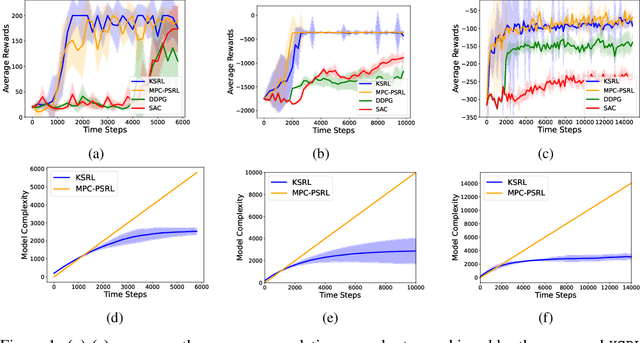
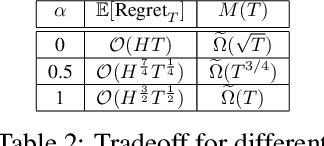
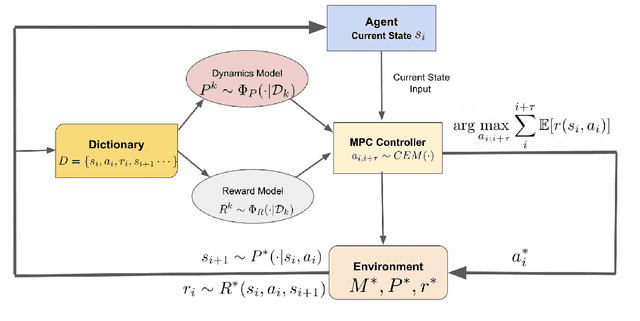
In this work, we propose a novel ${\bf K}$ernelized ${\bf S}$tein Discrepancy-based Posterior Sampling for ${\bf RL}$ algorithm (named $\texttt{KSRL}$) which extends model-based RL based upon posterior sampling (PSRL) in several ways: we (i) relax the need for any smoothness or Gaussian assumptions, allowing for complex mixture models; (ii) ensure it is applicable to large-scale training by incorporating a compression step such that the posterior consists of a \emph{Bayesian coreset} of only statistically significant past state-action pairs; and (iii) develop a novel regret analysis of PSRL based upon integral probability metrics, which, under a smoothness condition on the constructed posterior, can be evaluated in closed form as the kernelized Stein discrepancy (KSD). Consequently, we are able to improve the $\mathcal{O}(H^{3/2}d\sqrt{T})$ {regret} of PSRL to $\mathcal{O}(H^{3/2}\sqrt{T})$, where $d$ is the input dimension, $H$ is the episode length, and $T$ is the total number of episodes experienced, alleviating a linear dependence on $d$ . Moreover, we theoretically establish a trade-off between regret rate with posterior representational complexity via introducing a compression budget parameter $\epsilon$ based on KSD, and establish a lower bound on the required complexity for consistency of the model. Experimentally, we observe that this approach is competitive with several state of the art RL methodologies, with substantive improvements in computation time. Experimentally, we observe that this approach is competitive with several state of the art RL methodologies, and can achieve up-to $50\%$ reduction in wall clock time in some continuous control environments.
Risk-aware UAV-UGV Rendezvous with Chance-Constrained Markov Decision Process
Apr 10, 2022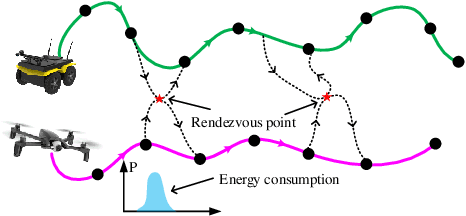
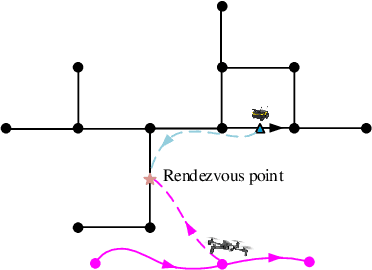
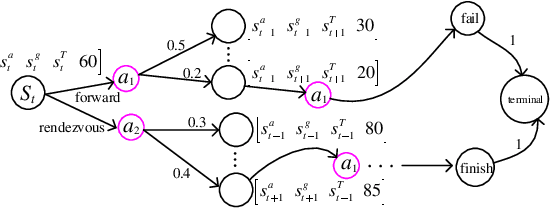
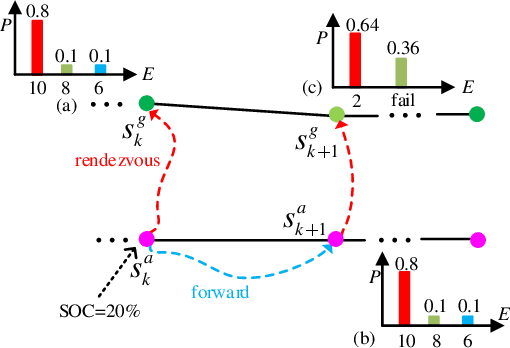
We study a chance-constrained variant of the cooperative aerial-ground vehicle routing problem, in which an Unmanned Aerial Vehicle (UAV) with limited battery capacity and an Unmanned Ground Vehicle (UGV) that can also act as a mobile recharging station need to jointly accomplish a mission such as monitoring a set of points. Due to the limited battery capacity of the UAV, two vehicles sometimes have to deviate from their task to rendezvous and recharge the UAV\@. Unlike prior work that has focused on the deterministic case, we address the challenge of stochastic energy consumption of the UAV\@. We are interested in finding the optimal policy that decides when and where to rendezvous such that the expected travel time of the UAV is minimized and the probability of running out of charge is less than a user-defined tolerance. We formulate this problem as a Chance Constrained Markov Decision Process (CCMDP). To the best knowledge of the authors, this is the first CMDP-based formulation for the UAV-UGV routing problems under power consumption uncertainty. We adopt a Linear Programming (LP) based approach to solve the problem optimally. We demonstrate the effectiveness of our formulation in the context of an Intelligence Surveillance and Reconnaissance (ISR) mission.
Occupancy Map Prediction for Improved Indoor Robot Navigation
Mar 08, 2022
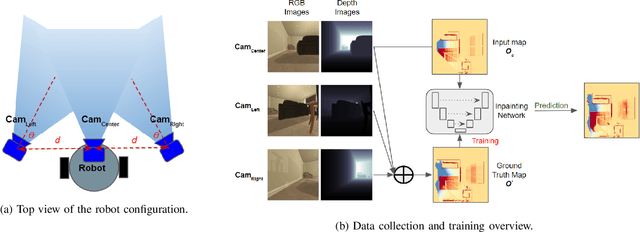
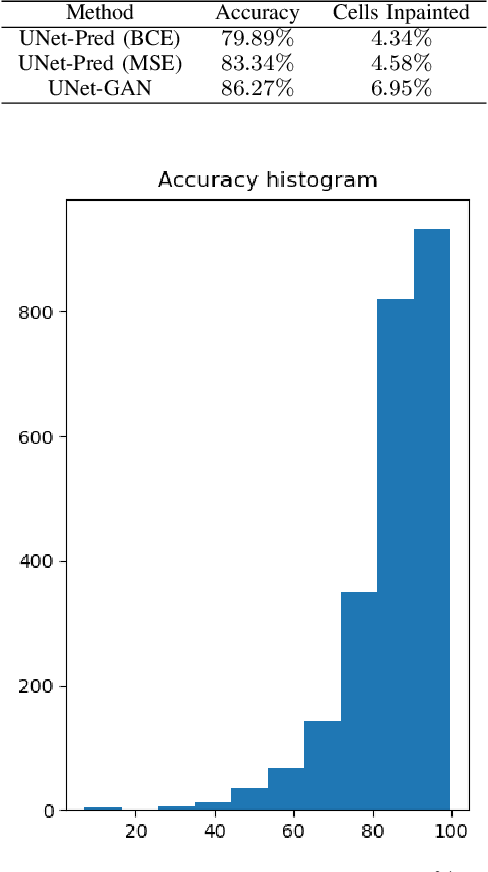
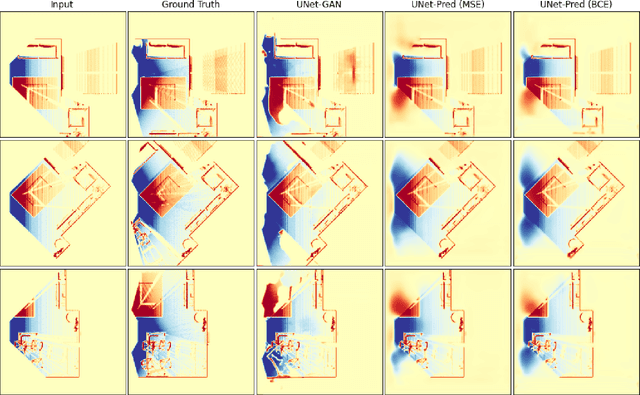
In the typical path planning pipeline for a ground robot, we build a map (e.g., an occupancy grid) of the environment as the robot moves around. While navigating indoors, a ground robot's knowledge about the environment may be limited by the occlusions in its surroundings. Therefore, the map will have many as-yet-unknown regions that may need to be avoided by a conservative planner. Instead, if a robot is able to correctly infer what its surroundings and occluded regions look like, the navigation can be further optimized. In this work, we propose an approach using pix2pix and UNet to infer the occupancy grid in unseen areas near the robot as an image-to-image translation task. Our approach simplifies the task of occupancy map prediction for the deep learning network and reduces the amount of data required compared to similar existing methods. We show that the predicted map improves the navigation time in simulations over the existing approaches.
On the Hidden Biases of Policy Mirror Ascent in Continuous Action Spaces
Jan 31, 2022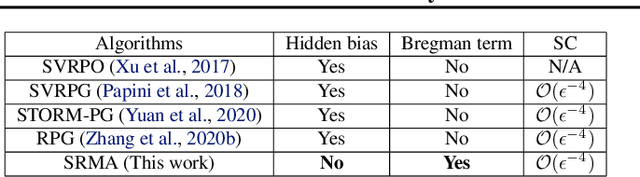

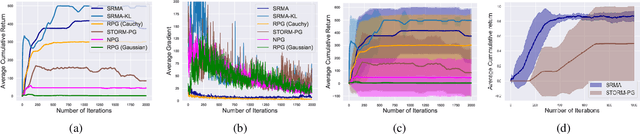
We focus on parameterized policy search for reinforcement learning over continuous action spaces. Typically, one assumes the score function associated with a policy is bounded, which fails to hold even for Gaussian policies. To properly address this issue, one must introduce an exploration tolerance parameter to quantify the region in which it is bounded. Doing so incurs a persistent bias that appears in the attenuation rate of the expected policy gradient norm, which is inversely proportional to the radius of the action space. To mitigate this hidden bias, heavy-tailed policy parameterizations may be used, which exhibit a bounded score function, but doing so can cause instability in algorithmic updates. To address these issues, in this work, we study the convergence of policy gradient algorithms under heavy-tailed parameterizations, which we propose to stabilize with a combination of mirror ascent-type updates and gradient tracking. Our main theoretical contribution is the establishment that this scheme converges with constant step and batch sizes, whereas prior works require these parameters to respectively shrink to null or grow to infinity. Experimentally, this scheme under a heavy-tailed policy parameterization yields improved reward accumulation across a variety of settings as compared with standard benchmarks.
Intermittent Deployment for Large-Scale Multi-Robot Forage Perception: Data Synthesis, Prediction, and Planning
Dec 16, 2021
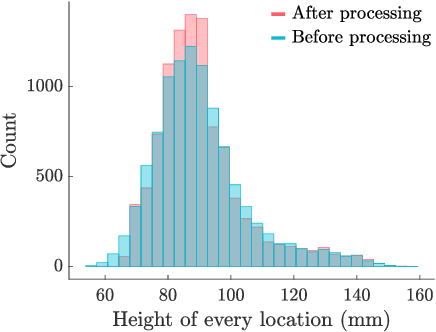
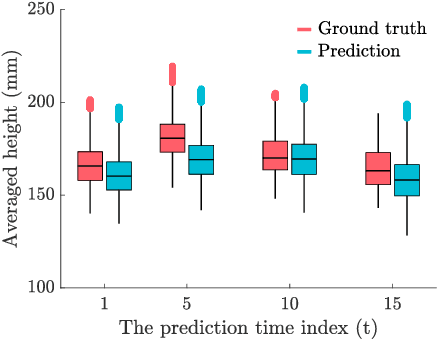
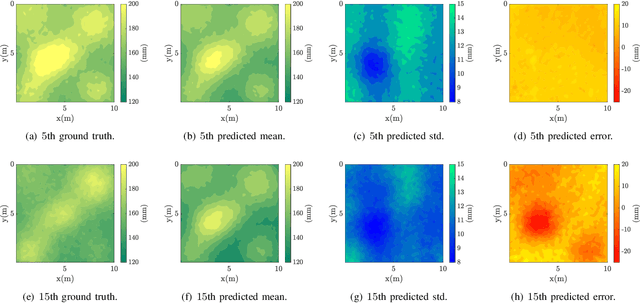
Monitoring the health and vigor of grasslands is vital for informing management decisions to optimize rotational grazing in agriculture applications. To take advantage of forage resources and improve land productivity, we require knowledge of pastureland growth patterns that is simply unavailable at state of the art. In this paper, we propose to deploy a team of robots to monitor the evolution of an unknown pastureland environment to fulfill the above goal. To monitor such an environment, which usually evolves slowly, we need to design a strategy for rapid assessment of the environment over large areas at a low cost. Thus, we propose an integrated pipeline comprising of data synthesis, deep neural network training and prediction along with a multi-robot deployment algorithm that monitors pasturelands intermittently. Specifically, using expert-informed agricultural data coupled with novel data synthesis in ROS Gazebo, we first propose a new neural network architecture to learn the spatiotemporal dynamics of the environment. Such predictions help us to understand pastureland growth patterns on large scales and make appropriate monitoring decisions for the future. Based on our predictions, we then design an intermittent multi-robot deployment policy for low-cost monitoring. Finally, we compare the proposed pipeline with other methods, from data synthesis to prediction and planning, to corroborate our pipeline's performance.
GALOPP: Multi-Agent Deep Reinforcement Learning For Persistent Monitoring With Localization Constraints
Sep 22, 2021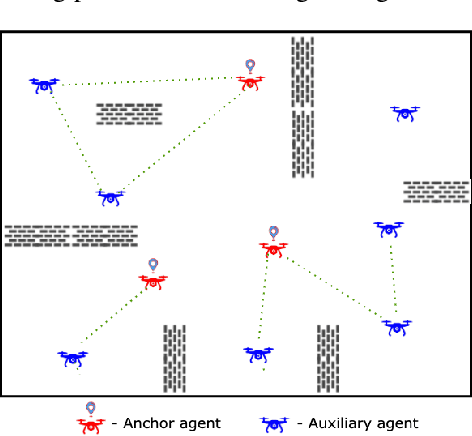
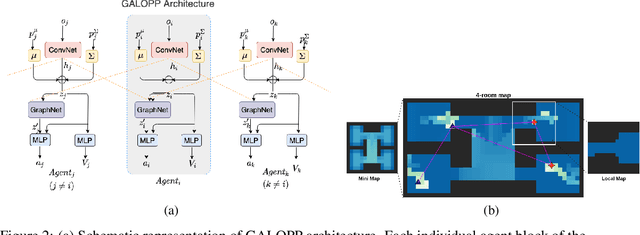
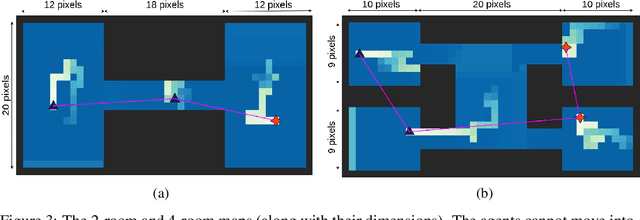
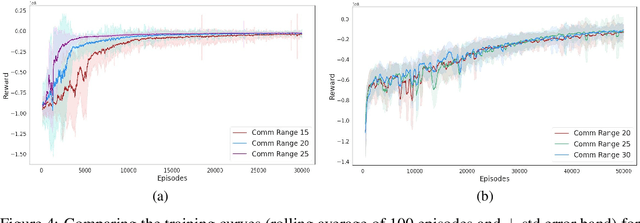
Persistently monitoring a region under localization and communication constraints is a challenging problem. In this paper, we consider a heterogenous robotic system consisting of two types of agents -- anchor agents that have accurate localization capability, and auxiliary agents that have low localization accuracy. The auxiliary agents must be within the communication range of an {anchor}, directly or indirectly to localize itself. The objective of the robotic team is to minimize the uncertainty in the environment through persistent monitoring. We propose a multi-agent deep reinforcement learning (MADRL) based architecture with graph attention called Graph Localized Proximal Policy Optimization (GALLOP), which incorporates the localization and communication constraints of the agents along with persistent monitoring objective to determine motion policies for each agent. We evaluate the performance of GALLOP on three different custom-built environments. The results show the agents are able to learn a stable policy and outperform greedy and random search baseline approaches.
Distributed Resilient Submodular Action Selection in Adversarial Environments
May 15, 2021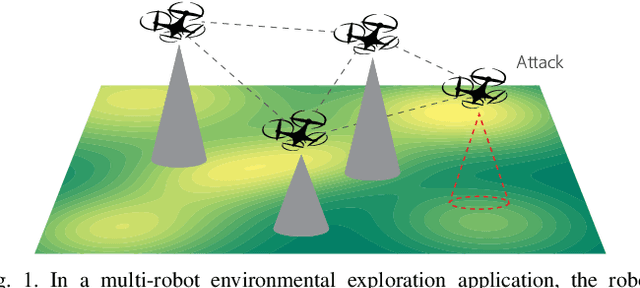
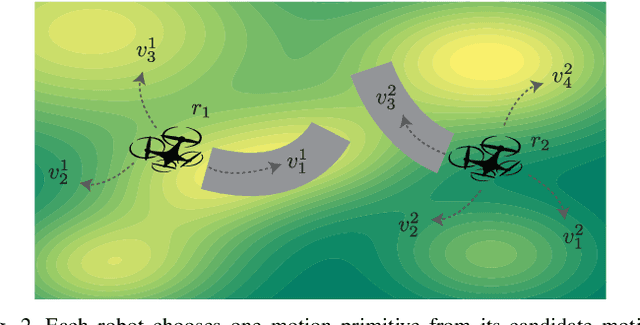
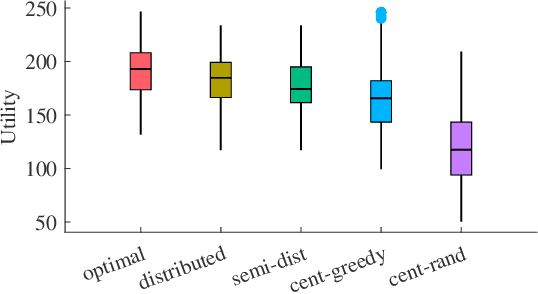
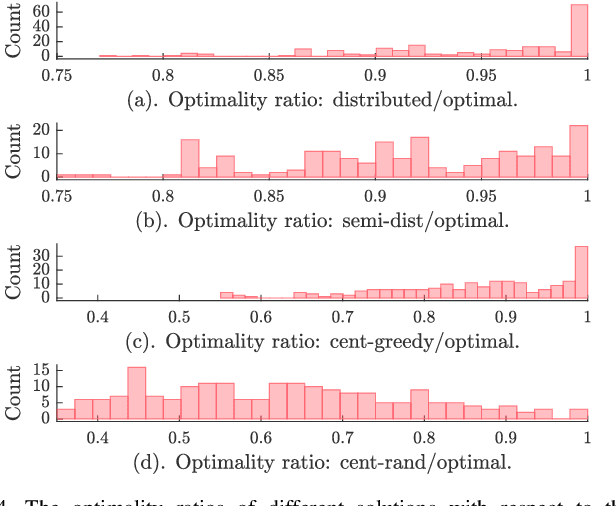
In this letter, we consider a distributed submodular maximization problem for multi-robot systems when attacked by adversaries. One of the major challenges for multi-robot systems is to increase resilience against failures or attacks. This is particularly important for distributed systems under attack as there is no central point of command that can detect, mitigate, and recover from attacks. Instead, a distributed multi-robot system must coordinate effectively to overcome adversarial attacks. In this work, our distributed submodular action selection problem models a broad set of scenarios where each robot in a multi-robot system has multiple action selections that may fulfill a global objective, such as exploration or target tracking. To increase resilience in this context, we propose a fully distributed algorithm to guide each robot's action selection when the system is attacked. The proposed algorithm guarantees performance in a worst-case scenario where up to a portion of the robots malfunction due to attacks. Importantly, the proposed algorithm is also consistent, as it is shown to converge to the same solution as a centralized method. Finally, a distributed resilient multi-robot exploration problem is presented to confirm the performance of the proposed algorithm.