 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Retrieval Augmented Neural Machine Translation by Controlling Source and Fuzzy-Match Interactions
Oct 10, 2022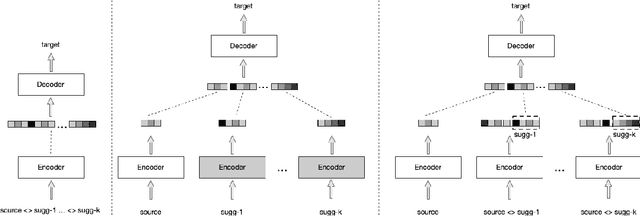
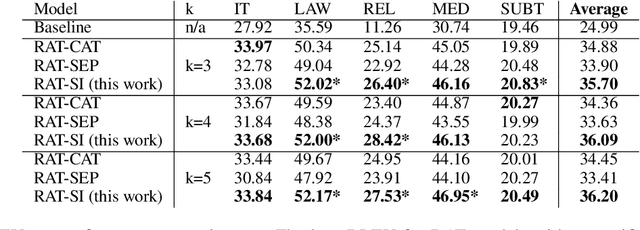
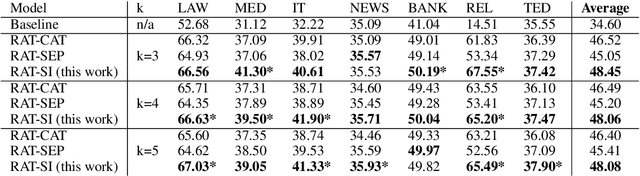
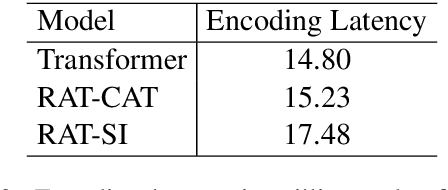
We explore zero-shot adaptation, where a general-domain model has access to customer or domain specific parallel data at inference time, but not during training. We build on the idea of Retrieval Augmented Translation (RAT) where top-k in-domain fuzzy matches are found for the source sentence, and target-language translations of those fuzzy-matched sentences are provided to the translation model at inference time. We propose a novel architecture to control interactions between a source sentence and the top-k fuzzy target-language matches, and compare it to architectures from prior work. We conduct experiments in two language pairs (En-De and En-Fr) by training models on WMT data and testing them with five and seven multi-domain datasets, respectively. Our approach consistently outperforms the alternative architectures, improving BLEU across language pair, domain, and number k of fuzzy matches.
Embarrassingly Easy Document-Level MT Metrics: How to Convert Any Pretrained Metric Into a Document-Level Metric
Sep 27, 2022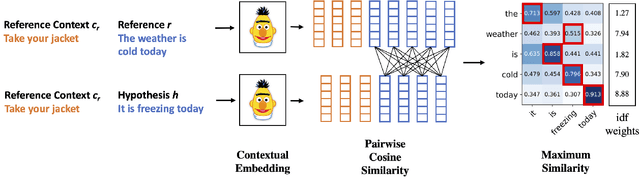
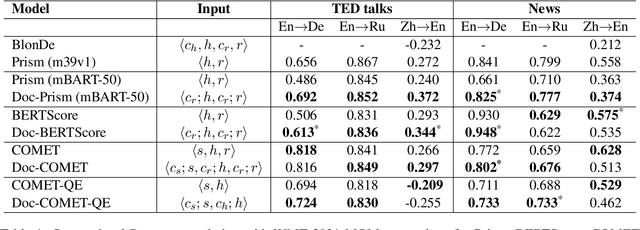


We hypothesize that existing sentence-level machine translation (MT) metrics become less effective when the human reference contains ambiguities. To verify this hypothesis, we present a very simple method for extending pretrained metrics to incorporate context at the document level. We apply our method to three popular metrics, BERTScore, Prism, and COMET, and to the reference free metric COMET-QE. We evaluate the extended metrics on the WMT 2021 metrics shared task using the provided MQM annotations. Our results show that the extended metrics outperform their sentence-level counterparts in about 85% of the tested conditions, when excluding results on low-quality human references. Additionally, we show that our document-level extension of COMET-QE dramatically improves its accuracy on discourse phenomena tasks, outperforming a dedicated baseline by up to 6.1%. Our experimental results support our initial hypothesis and show that a simple extension of the metrics permits them to take advantage of context to resolve ambiguities in the reference.
Sockeye 3: Fast Neural Machine Translation with PyTorch
Jul 12, 2022
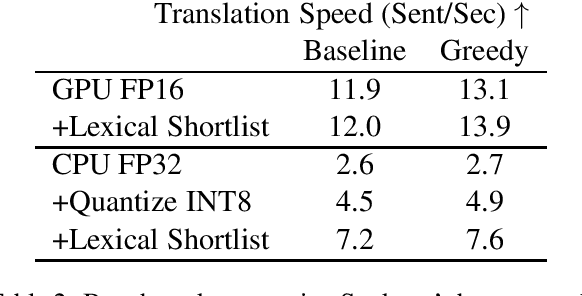
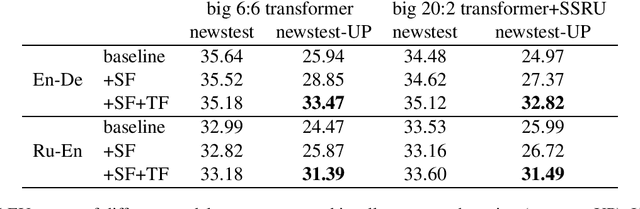

Sockeye 3 is the latest version of the Sockeye toolkit for Neural Machine Translation (NMT). Now based on PyTorch, Sockeye 3 provides faster model implementations and more advanced features with a further streamlined codebase. This enables broader experimentation with faster iteration, efficient training of stronger and faster models, and the flexibility to move new ideas quickly from research to production. When running comparable models, Sockeye 3 is up to 126% faster than other PyTorch implementations on GPUs and up to 292% faster on CPUs. Sockeye 3 is open source software released under the Apache 2.0 license.
Isometric MT: Neural Machine Translation for Automatic Dubbing
Dec 20, 2021
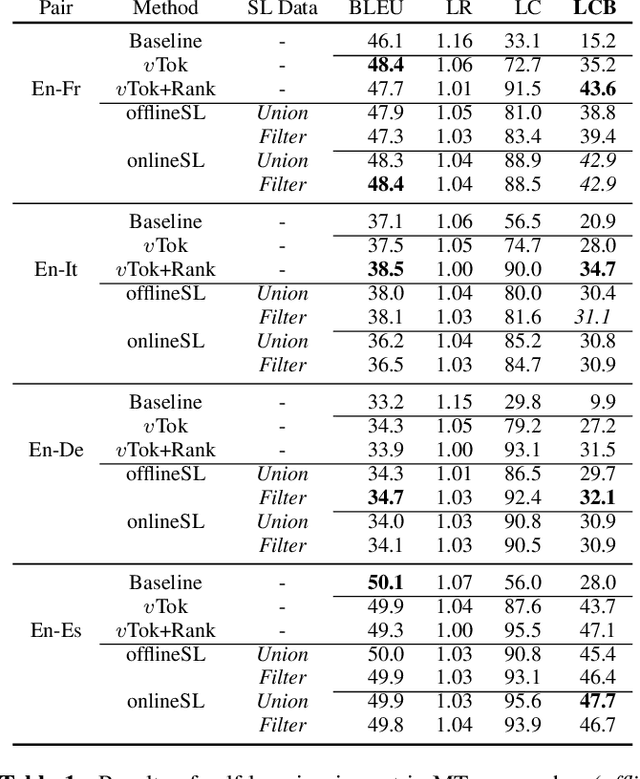
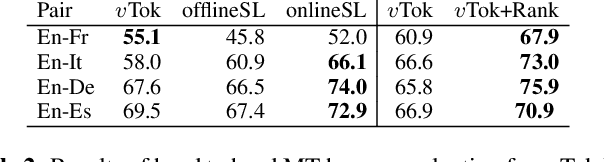
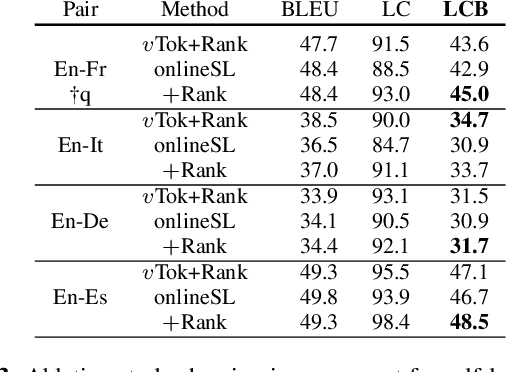
Automatic dubbing (AD) is among the use cases where translations should fit a given length template in order to achieve synchronicity between source and target speech. For neural machine translation (MT), generating translations of length close to the source length (e.g. within +-10% in character count), while preserving quality is a challenging task. Controlling NMT output length comes at a cost to translation quality which is usually mitigated with a two step approach of generation of n-best hypotheses and then re-ranking them based on length and quality. This work, introduces a self-learning approach that allows a transformer model to directly learn to generate outputs that closely match the source length, in short isometric MT. In particular, our approach for isometric MT does not require to generate multiple hypotheses nor any auxiliary scoring function. We report results on four language pairs (English - French, Italian, German, Spanish) with a publicly available benchmark based on TED Talk data. Both automatic and manual evaluations show that our self-learning approach to performs on par with more complex isometric MT approaches.
Prosody-Aware Neural Machine Translation for Dubbing
Dec 16, 2021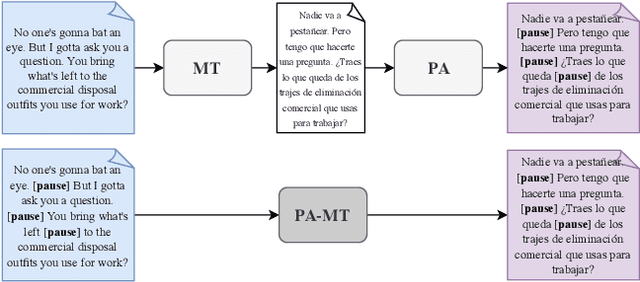
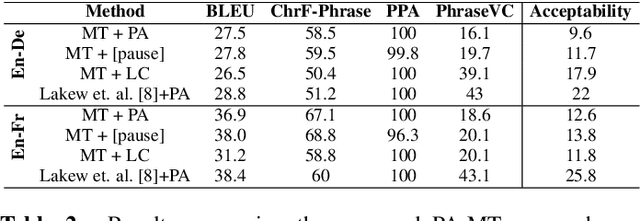
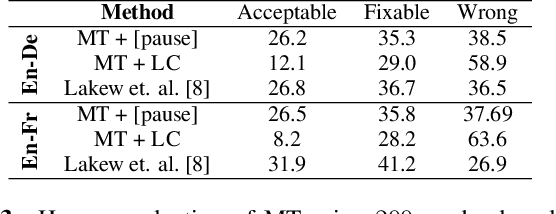

We introduce the task of prosody-aware machine translation which aims at generating translations suitable for dubbing. Dubbing of a spoken sentence requires transferring the content as well as the prosodic structure of the source into the target language to preserve timing information. Practically, this implies correctly projecting pauses from the source to the target and ensuring that target speech segments have roughly the same duration of the corresponding source segments. In this work, we propose an implicit and explicit modeling approaches to integrate prosody information into neural machine translation. Experiments on English-German/French with automatic metrics show that the simplest of the considered approaches works best. Results are confirmed by human evaluations of translations and dubbed videos.
Faithful Target Attribute Prediction in Neural Machine Translation
Sep 24, 2021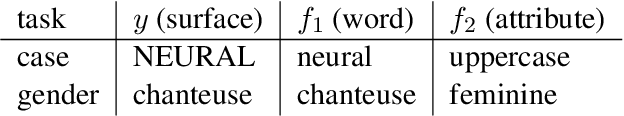
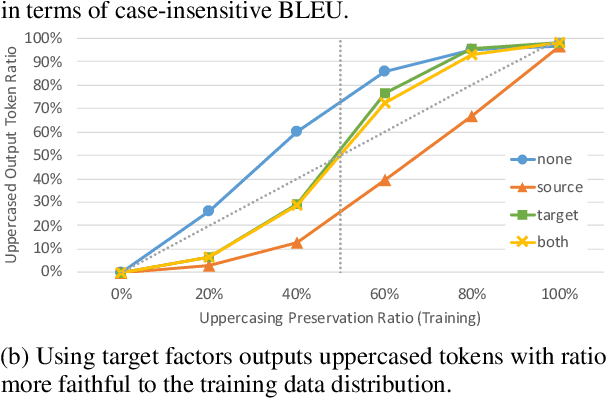
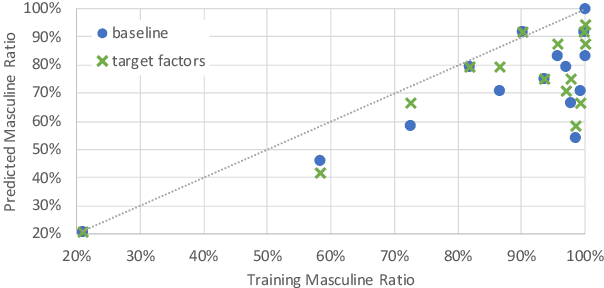
The training data used in NMT is rarely controlled with respect to specific attributes, such as word casing or gender, which can cause errors in translations. We argue that predicting the target word and attributes simultaneously is an effective way to ensure that translations are more faithful to the training data distribution with respect to these attributes. Experimental results on two tasks, uppercased input translation and gender prediction, show that this strategy helps mirror the training data distribution in testing. It also facilitates data augmentation on the task of uppercased input translation.
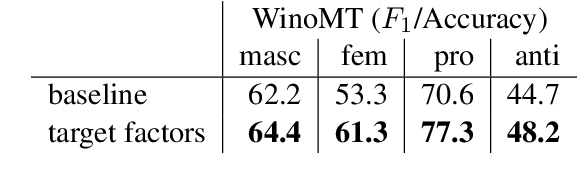
Improving Gender Translation Accuracy with Filtered Self-Training
Apr 15, 2021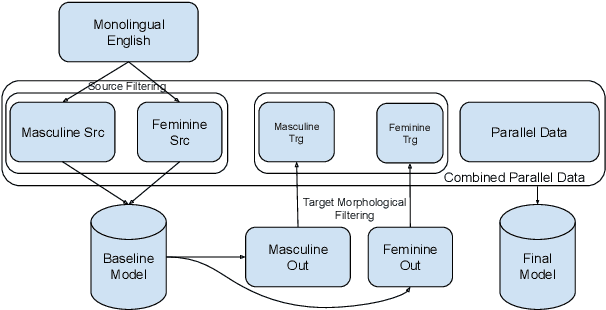
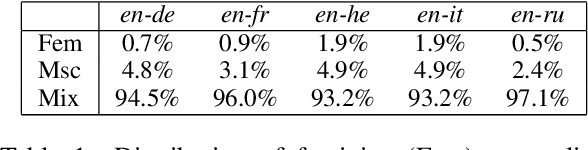
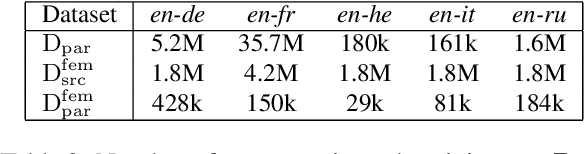
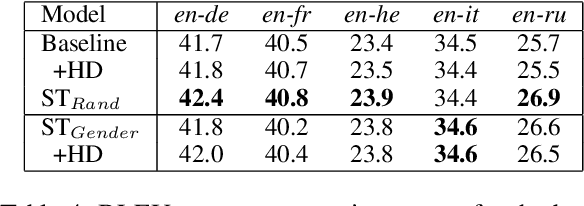
Targeted evaluations have found that machine translation systems often output incorrect gender, even when the gender is clear from context. Furthermore, these incorrectly gendered translations have the potential to reflect or amplify social biases. We propose a gender-filtered self-training technique to improve gender translation accuracy on unambiguously gendered inputs. This approach uses a source monolingual corpus and an initial model to generate gender-specific pseudo-parallel corpora which are then added to the training data. We filter the gender-specific corpora on the source and target sides to ensure that sentence pairs contain and correctly translate the specified gender. We evaluate our approach on translation from English into five languages, finding that our models improve gender translation accuracy without any cost to generic translation quality. In addition, we show the viability of our approach on several settings, including re-training from scratch, fine-tuning, controlling the balance of the training data, forward translation, and back-translation.
Evaluating Robustness to Input Perturbations for Neural Machine Translation
May 01, 2020
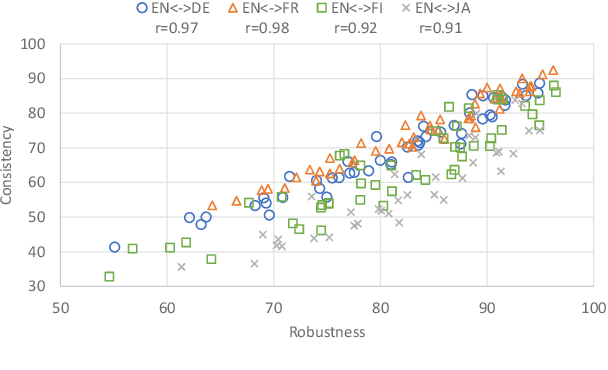
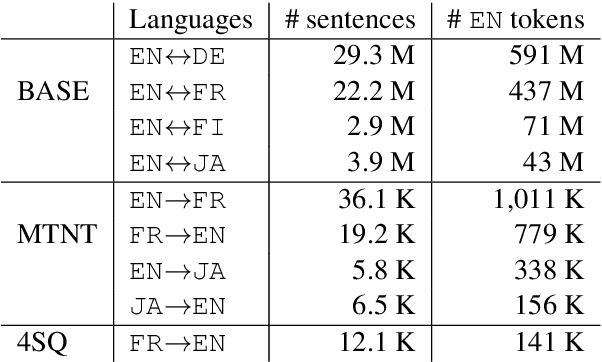
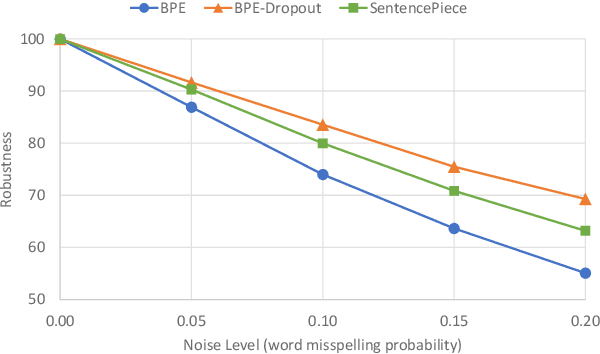
Neural Machine Translation (NMT) models are sensitive to small perturbations in the input. Robustness to such perturbations is typically measured using translation quality metrics such as BLEU on the noisy input. This paper proposes additional metrics which measure the relative degradation and changes in translation when small perturbations are added to the input. We focus on a class of models employing subword regularization to address robustness and perform extensive evaluations of these models using the robustness measures proposed. Results show that our proposed metrics reveal a clear trend of improved robustness to perturbations when subword regularization methods are used.
Joint translation and unit conversion for end-to-end localization
Apr 10, 2020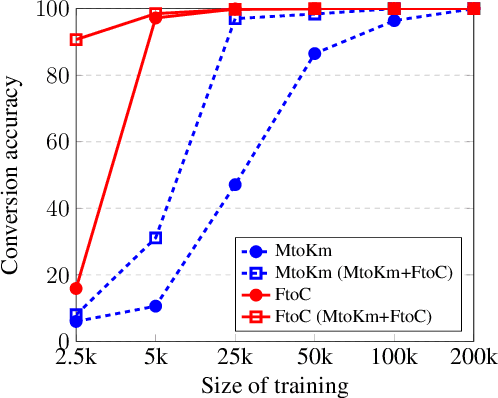

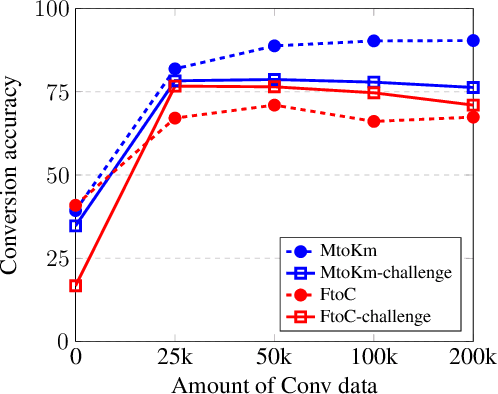
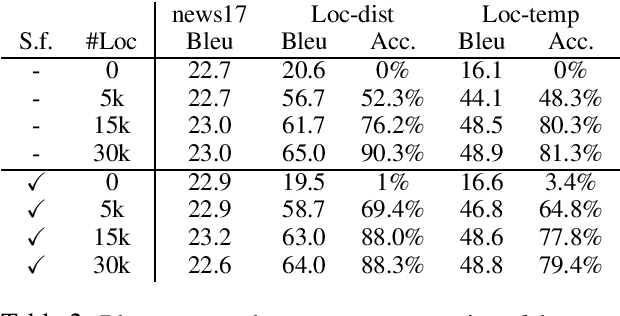
A variety of natural language tasks require processing of textual data which contains a mix of natural language and formal languages such as mathematical expressions. In this paper, we take unit conversions as an example and propose a data augmentation technique which leads to models learning both translation and conversion tasks as well as how to adequately switch between them for end-to-end localization.
Training Neural Machine Translation To Apply Terminology Constraints
Jun 03, 2019
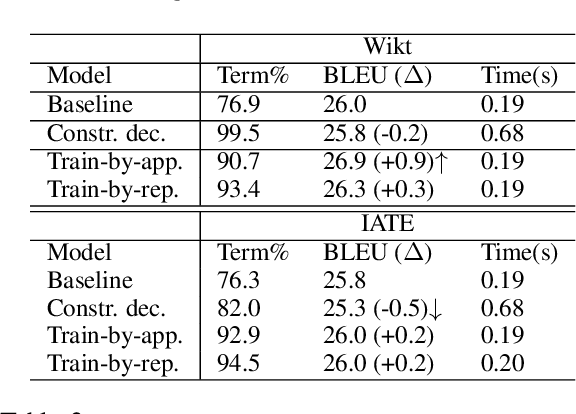

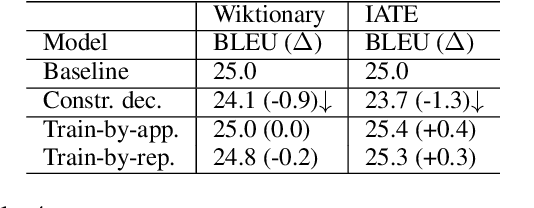
This paper proposes a novel method to inject custom terminology into neural machine translation at run time. Previous works have mainly proposed modifications to the decoding algorithm in order to constrain the output to include run-time-provided target terms. While being effective, these constrained decoding methods add, however, significant computational overhead to the inference step, and, as we show in this paper, can be brittle when tested in realistic conditions. In this paper we approach the problem by training a neural MT system to learn how to use custom terminology when provided with the input. Comparative experiments show that our method is not only more effective than a state-of-the-art implementation of constrained decoding, but is also as fast as constraint-free decoding.